*Corresponding author:Jadhav Rahul Ramesh ISSN: 0976-3031
Research Article
FOREGROUND EXTRACTION WITH VIDEO COMPRESSION BY REAL TIME APPLICATION
Jadhav Rahul Ramesh and Bodake Shekhar
Electronics & Telecommu. Engg. Department S. P. C.O. E.Otur, Pune
DOI: http://dx.doi.org/10.24327/ijrsr.2018.0907.2409
ARTICLE INFO ABSTRACT
Video analysis is large source of unstructured information today. Introduction to HEVC that is high-productivity video coding standard can possibly bring down the cost of information exchange and capacity. HEVC gives at least 40% than that of lessening in bit rate at the same visual quality. Investigating issue of constrained transmission capacity it ended up important to pack video information. to pack the information spatial and de associated information is expelled.
This makes packed information fill in as a fundamental asset for machine learning with altogether less examples for preparing. In this idea, a solid frontal area extraction is get utilizing novel spatio-worldly de-corresponded square highlights taken straightforwardly from the HEVC packed video [1].
The greater part of procedures, interestingly, take a shot at uncompressed pictures giving noteworthy stock piling and computational assets not just for the translating procedure before introduction yet in addition keeping in mind the end goal to highlight determination/extraction and foundation displaying stage tailing it. The proposed approach has been subjectively and quantitatively assessed against Gaussian blend display.
INTRODUCTION
Structure enticement is a technique in the region of picture preparing. In that a picture's closer view is separated for additionally handling (protest acknowledgment and so forth.). For the most part, a picture's areas of intrigue are questions, for example, people, autos, content and so forth in its closer view. After the phase of picture preprocessing object restriction is required which may influence utilization of this strategy. To foundation subtraction is a broadly utilized approach for identifying moving articles in recordings from static cameras [1]. The basis in the technique is that of distinguishing the moving things from the qualification between the cutting edge body and a reference outline, frequently alluded to as “Background image”, or “Background model”. Background subtraction is broadly speaking carried out if the photo in query is part of a video circulation. Ancient past subtraction gives important for countless applications in imaginative and prescient, for example surveillance tracking or human poses estimation but, background seduction is in light of a static foundation theory which isn't appropriate in genuine conditions [2]. Reflections or enlivened pictures on screen prompt foundation changes with indoor scenes. Similarly, due to
radiance, breeze, rainfall difference brought by weather, static backgrounds concept have difficulties with external scenes. In Dec.2012, Gary J. Sullivan and Thomas Wieg dreamy that "High Efficiency Video Coding (HEVC) is as of now being set up for most up to date video coding standard of the ITU-T Video Coding Experts Group and the ISO/IEC Moving Picture Experts Group [3]
In April 2014, Thanarat H. Chalidabhongse, David Harwood, Kyungnam Kim, they disconnected that "We introduce a constant calculation for foreground– foundation division [4] Sebastian Brutzer, Benjamin H¨oferlin, Gunther Heidemann Intelligent Systems Group, Universit¨at Stuttgart, Germany they disconnected that "Foundation subtraction is one of the key systems for programmed video examination, particularly in the space of video reconnaissance [5]. Indeed, even there is significance, evaluation of present foundation subtraction idea with releted to the difficulties of video reconnaissance caused from different deficiencies. "System subduction approach is utilized to distinguish the working item from foundation. Distinctive strategies have been proposed to distinguish question movement by utilizing diverse foundation subtraction procedures over late years [6]. Olivier Barnich and Marc Van Droogenbroeck, Member, IEEE they dreamy a system for
International Journal of
Recent Scientific
Research
International Journal of Recent Scientific Research
Vol. 9, Issue, 7(G), pp. 28168-28172, July, 2018
Copyright © Jadhav Rahul Ramesh and Bodake Shekhar, 2018, this is an open-access article distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use, distribution and reproduction in any medium, provided the original work is properly cited.
DOI: 10.24327/IJRSR
CODEN: IJRSFP (USA)
Article History:
Received 4th April, 2018
Received in revised form 25th
May, 2018
Accepted 18th June, 2018
Published online 28th July, 2018
Key Words:
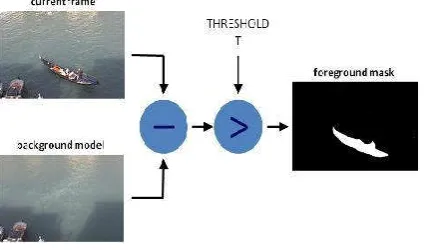
movement discovery that fuses a few imaginative instruments [7]. In November 2015 Bhaskar Dey and Malay K. Kundu utilized the developing High-Efficiency Video Coding (HEVC) [3] standard for video pressure, guarantees up to half piece rate investment funds thought about against the best of pressure plans accessible today. While the pressure productivity of HEVC offers a one of a kind chance to ease the transmission capacity crunch, new techniques for include extraction specifically from packed video must be figured into the outline of quicker calculations. Be that as it may, most best in class (SoA) calculations work on uncompressed pictures with an autonomous foundation display for every (pixel-based strategies). In this manner, packed recordings must experience computationally concentrated pre-preparing to be totally de-compacted, asserting critical time and memory before the use of such calculations. Ongoing exhibitions with precision tantamount to those of pixel-based techniques are focused on. At long last, pixel esteem is spread away from plain sight model of a neighboring pixel when the pixel is observed to be a piece of the foundation. By utilizing pseudo code and the parameter esteems, we depict our strategy in full subtle elements and contrast it with other foundation subtraction methods [8]. Moving articles are portioned from the foundation by utilizing movement location calculation. To execute this, take a picture as foundation at the time t, signified by I(t) to look at with the foundation picture indicated by B. In this, we can section out the items just by utilizing picture subtraction strategy for every pixel in I(t), take the pixel esteem indicated by P[I(t)] and subtract it with the comparing pixels on the foundation picture signified as P[B].
In scientific condition, it is composed as
P [F(t)] = P[I(t)] – P[B] (1)
The foundation is thought to be an edge at time t.This differentiation picture would show strength for the pixel locations which have changed in the two frames. Despite the fact that we have expelled the foundation, this will work for situations where all closer view pixels are moving and all foundation pixels are static [3]. Limit is put on this distinction picture to enhance the subtraction.
|P[F(t)] - P[F(t+1)] |> Threshold (2)
The differentiation of clarity of image pixels' power are 'maximum' or filtered depend on value of maximum [4]. The precision is reliant on speed of development in the scene. Speedier developments may require higher edges.
Fig 1 Foreground mask of image
Here, a viable way to deal with closer view subtraction is accepted utilizing the idea of novel spatio-fleeting square highlights which is taken straightforwardly from the HEVC strategy compacted video [5]. Most of techniques, in contrast, work on uncompressed images providing significant storage and computational resources for the decoding process prior to initialization or to feature selection/extraction and background modeling stage following it.
In this idea HEVC is the most recent video programming brilliance of the ITU-T Video Coding Experts group and the ISO/IEC Moving Picture Experts Group (MPEG) [3]. The principle point of the HEVC institutionalization exertion is to empower altogether enhanced pressure execution with respect to existing measures in the scope of half piece rate diminishment for break even with perceptual video quality. This paper gives a review of the specialized highlights and attributes of the HEVC standard. The proposed approach has been subjectively and quantitatively assessed against Gaussian blend display.
Foundation subtraction with hevc Video
Fig 2 Block diagram of background subtraction with HEVC video
HEVC Video I/P
HEVC is a video pressure chic, a successor to H.264/MPEG-4 AVC. HEVC is expressed to twofold the data pressure proportion in contrast with H.264/MPEG-4 AVC on the indistinguishable level of video high caliber at the equivalent piece rate, it might rather be utilized to offer altogether propelled video quality. It might help 8K UHD and resolutions as much as 8192×4320 Observation video is the greatest supply of unstructured expansive data nowadays. HEVC famous is ready to have a vast position in bringing down the costs identified with transmission and capacity. A few the advantages of HEVC over the inheritance MPEG-four propelled Video Coding (AVC), is an awesome forty rates or additional piece rate decrease at the equivalent noticeable quality.
Video Framing
Image division is the strategy for dividing a virtual picture into in excess of one section (sets of pixels, otherwise called super pixels) [6]. The aim of division is to clarify and trade the illustration of an picture into the concept that is very meaningful and low difficult to investigate boundaries.
Block Level Segmentation
Coding tree unit (CTU) is the principal handling unit of the High Effectiveness Video Coding (HEVC) video standard and theoretically compares in structure to large scale square gadgets that had been utilized as a part of various going before video norms. CTU is in like manner called biggest coding unit (LCU). A CTU may be between 16×16 pixels and sixty 64x64four pixels in size with a bigger size usually growing coding efficiency. Block level segmentation consists of acting a rough block-stage segmentation of each frame by way of choosing of a fixed of ability CTUs that are occupied absolutely or partly by using elements of moving objects [7].
Pixel Level Segmentation
Block level segmentation includes performing a finer pixel-degree segmentation by way of casting off image are selected CTUs which might be similar (in depth) to the corresponding background model.
Image Enhancement
To get pleasant results in image processing its miles continually necessary that input images must be of good quality. However, nearly this isn't an extraordinary arrangement simple. Because of one-of-a-kind reasons like noise, mild influences we get low or medium quality images. Consequently, it turns into important to enhance their exceptional [8]..
Current Frame
The modern frame obtained from HEVC video is now de-noised, more desirable and processed with one of a kind segmentation. This edge is utilized to find current moving item in a casing.
Background Frame
It's far reference frame of predefined region. It is considering being idle. While it is compared, and extracted from current frame output will detect shifting object in a current frame.
Foreground Frame
Foreground frame is final results of difference between current body and history version. It indicates the shifting item in a binary form.
Coding Tree Unit
A compressed HEVC video consists of a sequence of pictures or frames, every one of which is part into non-covering squares called coding tree unit (CTU). The CTU is the key unit of pressure, which keeps up data for each shading segment in structures known as the coded tree square (CTB).A luma CTB covers a rectangular picture territory of L × L tests of the luma part and the relating chroma CTBs cover L/2 × L/2 tests of every one of the two chroma segments. The estimation of L (up until now used to mean the extent of luma CTBs) for a given arrangement is settled by the encoder and motioned by a
succession parameter which might be either equivalent to 16, 32, or 64. Each CTB can be part recursively into a quadtree structure, the distance down to 8 × 8 (in units of luma tests) districts. The quad tree structure is known as the coding quad tree (CQT). In this way, for the case appeared in Fig. 1 (top), the 64 × 64 luma CTB comparing to the CTU at area 14 is appeared to comprise of two 32 × 32, six 16×16, and eight 8×8 districts. These areas are called coding squares (CBs).The spatial and the fleeting redundancies individually of a given CB are lessened by part it into hinders that were anticipated from already coded obstructs inside a similar edge (called intra-expectation), and also from the neighboring edges (called between forecast). The squares are called forecast squares (PBs). Between forecast of a PB is a fleeting de-connection strategy by which maybe a couple appropriate reference squares are chosen.
The luma CTB comparing to the 64x64 CTU at area 14 is part into the CQT structure appeared in underneath
Predicted information of the Residual information of 32x32 CB number 15 is split into 2PBs CB number 15 is split into recursively into a RQT
consisting of 13 TBs
Fig 3 A case of 256x256 picture isolate into 16 64x64 CTUs (top picture), the
luma CTB relating to CTU at area 14 is part CQT structure (center picture). The CB number 15 of the CQTis appeared to be coded utilizing anticipated data (last picture)IV. DIRICHLET PROCESS GAUSSIAN MIXTURE
(DP-GMM)
A Gaussian blend class is a measure classification that expect every one of the records factors are created from a total of a limited assortment of Gaussian appropriations with obscure parameters [9]. Exclusive classes to estimate Gaussian aggregate models, that correspond to exclusive estimation strategies, detailed under one among them is DP-GMM.
DP-GMM
A Dirichlet system is a chance distribution whose territory is itself a set of possibility distributions. it is regularly utilized in Bayesian inference to describe the prior expertise approximately the distribution of random variables, this is, how probable it is that the random factors are apportioned in accordance with some dispersion [11].
Flow Chart
Fig 4 Square graph of foundation subtraction with HEVC video by utilizing
DP-GMM..
Te nearer way to a non-parametric Bayesian method that spontaneously estimates the wide assortment of combination additives is automatically estimate via this approach to version the pixel‟s background colour distribution [12].
In DP-GMM as appeared in figure due to light effect the colour distribution preserve on converting, this will cause misguided result right here we can utilize stochastic process in the event that you need to keep in mind the all odds of trade in shade appropriation. Those adjustments in colour distribution might be updated to combination model continuously. This constant continuous technique will give refreshed enhanced photo outline. Pick up of this technique is that present edge is currently versatile to change in shading appropriation with the guide of thinking about probabilities over plausibility.
RESULTS
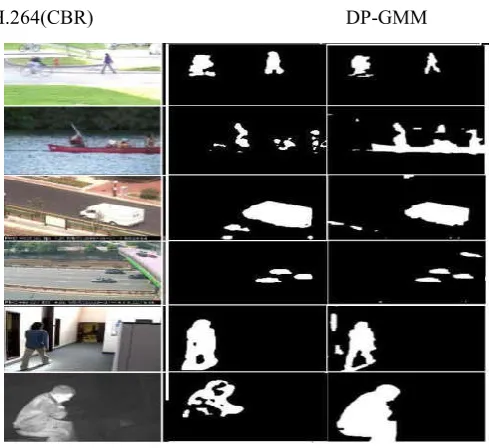
In this section is divided into two sub section. In the first section, we provide an experimental validation of the statistically predicted values of CTU feature x against its respective counterparts computed directly from the decoded bit stream shown in figure 3. In second section, we provide qualitative quantitative comparison of the H.264 (CBR) & DP-GMM shown in figure 5.
H.264(CBR) DP-GMM
Fig 5 Comparison of H.264 (CBR) & DP-GMM
CONCLUSION
According to paper, we proposed a technique for removing closer view objects utilizing CTU highlights of HEVC compacted video. We infer that Background subtraction techniques with HEVC calculation and Gaussian blend show algorithm have wide scope for analysis purpose. Hence, I have selected these techniques for comparative analysis purpose.
Acknowledgment
Author Mr.Jadhav Rahul Ramesh thanks to Prof. Bodake Shekhar, ME Coordinator of S.P.C.O.E. Otur, Pune for guiding throughout work also thanks to Dr.Kharat U.G. Principal in S.P.C.O.E.Otur, Pune for guiding throughout work.
References
1. R. J. Radke, S. Andra, O. Al-Kofahi, and B. Roysam, “Image change detection algorithms: A systematic survey,” IEEE Trans. Image Process., vol. 14, no. 3, pp. 294–307, Mar. 2005.
2. T. Huang, “Surveillance video: The biggest big data,” Comput. Now, vol. 7, no. 2, Feb. 2014. [Online].
Available: http://www.computer.
Org/portal/web/computing now/archive/february2014 3. G. J. Sullivan, J. Ohm, W.-J. Han, and T. Wiegand,
“Overview of the high efficiency video coding (HEVC) standard,” IEEE Trans. Circuits Syst. Video Technol., vol. 22, no. 12, pp. 1649–1668, Dec. 2012.
4. Kyungnam Kim, Thanarat H. Chalidabhongse, David Harwood, Larry Davis.“Real-time foreground– background segmentation using codebook model”. IEEE Transactions on Pattern Analysis and Machine Intelligence, Vol. 36, NO. 4, April 2014
5. T. Bouwmans, “Traditional and recent approaches in background modeling for foreground detection: An overview,” Comput. Sci. Rev., vols. 11–12, pp. 31–66, May 2014.
7. C. R. Wren, A. Azarbayejani, T. Darrell, and A. P. Pentland, “Pfinder: Real-time tracking of the human body,” IEEE Trans. Pattern Anal.Mach. Intell., vol. 19, no. 7, pp. 780–785, Jul. 1997.
8. Bhaskar Dey and Malay K. Kundu, Senior Member,” Efficient Foreground Extraction From HEVC Compressed Video for Application to Real-Time Analysis of Surveillance„ Big‟ Data” IEEE Transactions On Image Processing, Vol. 24, No. 11, November 2015
9. N. Friedman and S. Russell, “Image segmentation in video sequences: A probabilistic approach,” in Proc. 13th Conf. Uncertainty Artif.Intell., 1997, pp. 175–181.
10. C. Stauffer and W. E. L. Grimson, “Adaptive background mixture models for real-time tracking,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit., Jun. 1999, pp. 246– 252.
11. Z. Zivkovic, “Improved adaptive Gaussian mixture model for background subtraction,” in Proc. IEEE Int. Conf. Pattern Recognit., Aug. 2004, pp. 28–31.
12. Z. Chen and T. Ellis, “Self-adaptive Gaussian mixture model for urban traffic monitoring system,” in Proc. IEEE Int. Conf. Comput.Vis., Nov. 2011, pp. 1769–1776. 13. Y. Wang, K.-F. Loe, and J.-K. Wu, “A dynamic
conditional random field model for foreground and shadow segmentation,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 28, no. 2, pp. 279–289, Feb. 2006.
How to cite this article:
Jadhav Rahul Ramesh and Bodake Shekhar. 2018, Foreground Extraction with Video Compression by Real Time Application. Int J Recent Sci Res. 9(7), pp.28168-28172. DOI: http://dx.doi.org/10.24327/ijrsr.2018.0907.2409