P 0
S *.\.^ K'Ti 1 ïAt*A4ifL,
- e > ^ , - V L l\(c.,, Z : . l
Im proyijig-^he P e rfo r m a n ce
'’"Archijtéctures cp n faitlin g
R a ifd o m A ccess-fcist S tr u c tu r e d M em o r y
J e n s-U w e D zik o w sk i
M arch, 1995
D e p a r t m e n t o f C o m p u t e r Sc i e n c e
U n i v e r s i t y C o l l e g e Lo n d o n
U n i v e r s i t y o f Lo n d o n
T his thesis is s u b m itte d to th e U n iv e rsity of L ondon in
p a rtia l fulfilm ent of th e req u ire m e n ts for th e degree of
ProQuest Number: 10017310
All rights reserved
INFORMATION TO ALL USERS
The quality of this reproduction is dependent upon the quality of the copy submitted. In the unlikely event that the author did not send a complete manuscript and there are missing pages, these will be noted. Also, if material had to be removed,
a note will indicate the deletion.
uest.
ProQuest 10017310
Published by ProQuest LLC(2016). Copyright of the Dissertation is held by the Author. All rights reserved.
This work is protected against unauthorized copying under Title 17, United States Code. Microform Edition © ProQuest LLC.
ProQuest LLC
789 East Eisenhower Parkway P.O. Box 1346
A B S T R A C T
The work presented in this thesis investigates how existing and fu tu re com puter architectures can be enhanced to exploit th e po ten tial of R andom Access List Struc tu re d Memory.
W hile m ost existing m em ory architectures can only offer a Hmited choice of pos sible d a ta access mechanisms, R andom Access List S tru ctu red Memory, as a new m em ory architecture, offers good support in b o th num erical and symboHc com put ing. A fast random access m echanism allows th e m anipulation of d a ta elem ents stored in array structures, while th e dimensions of these arrays can be dynamically modified. At th e same tim e array elem ents can hold different d a ta types and th ere fore allow th e user to store complex d a ta stru ctures on th e basic array structure. This way of expressing complex d a ta stru ctu res as arrays can be used to avoid the use of conventional hnked Hsts and their insufficient random access facihties.
T he regular d a ta stru ctu re of th e arrays used in this m em ory concept offers new, elegant, ways to stru ctu re th e d ata of common appHcations and should simpHfy m any algorithm s m anipulating other large d a ta structures. Any CPU designed to operate on a R andom Access List S tru ctu red M emory architecture needs to achieve good results when m anipulating individual d a ta elem ents of these structures. However a general purpose processor can not be expected to achieve an optim al perform ance when m anipulating large complex d a ta structures. T he requirem ent for high system perform ance, in a system architecture using complex Hst m anipulations on a frequent basis, provided th e m otivation to investigate th e potential of co-processors for these hst m anipulations.
T he developm ent of such a co-processor is reported in this thesis. Starting with an explanation of th e R andom Access List S tructured Memory concept, and the way it can be used in a com puter architecture, th e n ature of complex hst m anipulations is explained. It is th en indicated how a co-processor can be used to accelerate complex Hst m anipulations as well as com munication and memory m anagem ent tasks. These general concepts are then appHed to the tree shaped concept of Random Access List S tru ctu red M emory used in th e experim ental SPRIN T architecture. Various hardw are alternatives for the integration of such a co-processor, operating on R andom Access List S tructu red Memory, are considered.
A c k n o w le d g m e n ts
I would like to th an k my supervisor Dr. P e te r Rounce for his advice, th e useful com m ents on my work and his availability whenever I needed help. Furtherm ore I w ant to credit his effort in reading various drafts. Also m any thanks to my second supervisor Dr. A ndy B etts for his opinions and th e com m ents he m ade whenever I went to see him for advice.
My friends and form er fellow-sufferers Dr. Ja n Purchase and Dr. W anderley Lobianco also deserve praise for reading drafts of this thesis and giving me useful rem arks.
M any thanks to my girl-friend Kay K anayam a, for her encouragem ent, her p a tience and for being a perm anent source of m otivation. T here are also credits for Angela Sasse and JuHa Schnabel who, during th e last th ree years, did their best to ensure I do not forget my native language. T hanks to Joh n Pearce for several pleasant hours spent together on th e golf course.
C o n ten ts
1 I n tr o d u c tio n 19
1.1 Trends in C om puter S c ie n c e ...20
1.1.1 H a r d w a r e ... 21
1.1.2 S o ftw a re ...23
1.1.3 M emory S y s t e m s ... 24
1.2 W hy R andom Access List S tru ctu red M emory ? ...26
1.2.1 Existing Memory M o d e ls ...27
1.2.2 Prerequisites for a List S tru ctu red M e m o ry ...29
1.2.3 The Page-based, T ree-structured M o d e l... 30
1.3 Background: SPAN and S P R I N T ... 32
1.3.1 T he SPAN project ...33
1.3.2 The SPR IN T Processor ... 35
1.3.3 Support for M odern Program m ing P a r a d i g m s ... 36
1.4 A lternative Hardware A rchitectures ... 39
1.4.1 Access Rights and P r o t e c t i o n ... 39
1.4.2 List Structured M emory as Extension ... 40
1.5 P ure List Structured M emory A r c h i t e c t u r e s ...41
1.6 S tru ctu re of th e T h e s i s ... 43
8 C o n ten ts
2 M a n ip u la tin g L ist S tr u c tu r e d M e m o r y 47
2.1 Frequent Load-intensive F u n c tio n s ... 48
2.2 Analysing th e Functional R e q u ire m e n ts... 51
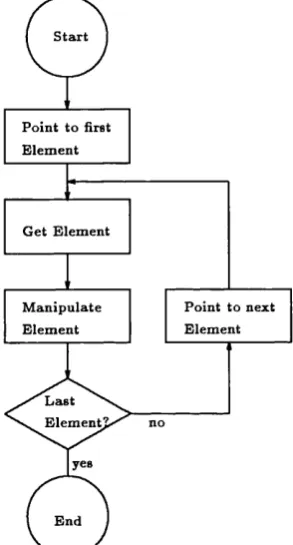
2.2.1 List T r a v e r s a l... 51
2.2.2 M emory M an a g e m en t...56
2.3 Sum m ary ... 57
3 H ard w are A lte r n a tiv e s 59 3.1 Enhancing Existing A r c h ite c tu r e s ... 60
3.1.1 S tru ctu re ...60
3.1.2 List M emory Access ...62
3.1.3 Complex List O p e ra tio n s ... 64
3.2 New A rchitectures based on List S tructured M e m o r y ...65
3.3 Co-processor Design C o n sid e ra tio n s ... 67
3.3.1 In stru ctio n Set and Controller S t r u c t u r e ...67
3.3.2 A c tiv a tio n ...68
3.3.3 Direct Com m unication S u p p o r t ...69
3.3.4 Indirect Com m unication S u p p o r t ... 73
3.3.5 Enhanced Bus S y s te m s ... 74
3.4 Sum m ary of possible A r c h i t e c t u r e s ... 74
C o n te n ts 9
4 A lg o r ith m s 79
4.1 M emory M an a g e m en t... 79
4.1.1 Aspects of Free Page L i s t s ... 80
4.1.2 Page D em and and A v a ila b ility ...83
4.1.3 Garbage Collection S u p p o r t ... 87
4.2 E rror H a n d l i n g ... 88
4.3 Possible V a r i a t i o n s ... 88
4.3.1 Homogeneous A r r a y s ... 89
4.3.2 Page Allocation S tr a t e g y ...89
4.4 A lgorithms for a SP R IN T C o -p ro c e sso r... 90
4.4.1 Special A s p e c t s ...90
4.4.2 Im plem ented F u n c tio n s ... 91
4.5 S u m m a r y ... 94
5 D a ta p a th A r c h ite c tu r e 97 5.1 Fast List A c c e s s ...99
5.2 R egister P la c e m e n t ... 100
5.3 Stack Im plem entation ... 101
5.3.1 Paged Model ... 101
5.3.2 Element S e le c tio n ... 103
5.3.3 Page T r a n s f e r ... 105
5.3.4 Stacked Inform ation ...106
5.3.5 O ptional Stack Size R e d u c tio n ...108
10 C o n ten ts
5.5 D ata M anipulation - A rithm etic and S h i f t s ... 110
5.6 Details of th e Co-processor D a t a p a t h ... 113
5.6.1 List Structure Registers ... 113
5.6.2 S t a c k ... 115
5.6.3 Buses ... 115
5.6.4 M emory M an a g e m en t... 117
5.6.5 Processor S tatus W o r d ...118
5.6.6 C o m m u n ic a tio n ... 119
5.6.7 B u ffe rs ... 121
5.6.8 SPR IN T In te rfa c e ... 121
5.7 Sum m ary ...124
6 D e v e lo p m e n t o f th e C o -p r o c esso r 127 6.1 High-level S im u la tio n ...128
6.1.1 Sim ulated List T r a v e r s a l ...130
6.1.2 Sim ulated M emory M an a g e m en t... 130
6.1.3 Sim ulation O u t c o m e ... 132
6.2 Design M ethodology ...133
6.2.1 Microcode G eneration ... 134
C o n te n ts 11
6.3 Behavioural S im u la tio n ... 146
6.3.1 E xtracting D atabase I n f o r m a t i o n ... 147
6.3.2 Joining th e C o m p o n e n ts ...150
6.3.3 Scale of S im u la ti o n ... 151
6.3.4 M icro-program O p tim is a tio n ... 153
6.4 Controller D e s i g n ... 155
6.4.1 Microcode Im p le m e n ta tio n ...155
6.4.2 E xtraction P r o c e s s ... 165
6.4.3 Gate-level S im u la tio n ...168
6.4.4 Micro-code R e p la c e m e n t... 170
6.4.5 O peration Mode of th e Co-processor ... 171
6.5 Sum m ary ...172
7 C o -p r o c e sso r E v a lu a tio n 175 7.1 P e rfo rm a n c e ...175
7.1.1 Basic List C o p y ... 176
7.1.2 List Shcing ...181
7.1.3 List Deletion ... 182
7.1.4 List F lattenin g and List R e - c o n s tr u c tio n ...183
7.1.5 O ther List M anipulations ...185
7.2 P r a c t i c a l i t y ...186
7.2.1 General Connectivity of Co-processors ... 186
7.2.2 Co-processor S i z e ...187
12 C o n ten ts
8 C o n c lu sio n s 193
8.1 R e v ie w ... 193
8.2 A c h ie v e m e n ts ... 194
8.3 O u t l o o k ...197
A P o ssib le C o -p r o c e sso r In stru ctio n s 199 B D e sc r ip tio n o f th e H ig h L evel S im u la tio n E n v ir o n m e n t 205 B .l List T r a v e r s a l ... 205
B.1.1 Basic D e f i n it io n s ...205
B.1.2 R egister M a n ip u l a tio n ... 208
B.1.3 Stack M o d e l...210
B.2 Sim ulation E n v ir o n m e n t... 211
B.2.1 C reating L i s t s ... 212
B.2.2 T a s k s ... 213
B .2.3 M anipulating L i s t s ...214
C P r o to c o l o f a H ig h -le v e l S im u lation 215
D D e sc r ip tio n o f th e M icro c o d e E x tr a ctio n 219
G lo ssa r y 233
List o f F igu res
1.1 Exam ple of a List S tru ctu red M emory ...26
1.2 Classification of M emory A r c h ite c tu r e s ...28
1.3 Exam ple of a 3-level page s t r u c t u r e ... 32
1.4 Overview of th e SPAN p r o j e c t ...34
1.5 S tru ctu re of a SPR IN T List P o i n t e r ... 36
1.6 One-dimensional A r r a y ...37
1.7 Two-dimensional A r r a y ...37
1.8 Exam ple C-program S t r u c t u r e ... 38
2.1 Basic Hst traversal a lg o rith m ...52
2.2 Basic Traversal algorithm for 3-level page s t r u c t u r e ... 55
3.1 Basic stru c tu re for added List M e m o r y ...60
3.2 Address stru ctu re for an added Hst m em ory ... 61
3.3 A dvanced stru ctu re for added List M e m o ry ...65
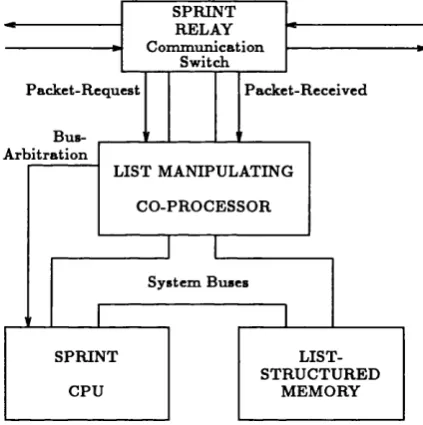
3.4 Node w ith one CP for direct c o m m u n ic a tio n ...69
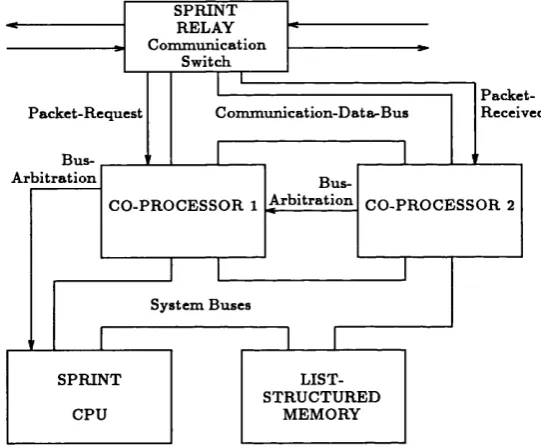
3.5 Node w ith two CPs for direct com m unication ... 70
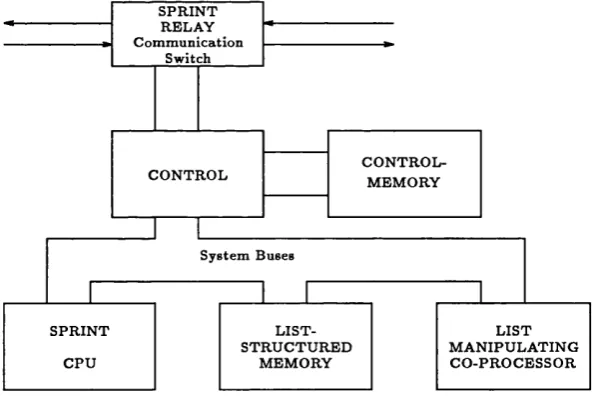
3.6 Node w ith CP and com m unication c o n tro U e r... 73
14 L ist o f F ig u res
4.1 Problem w ith a stru ctu red free page Hst ...82
5.1 Integer d a ta form at in S P R I N T ... 100
5.2 M odel of a paged s t a c k ...103
5.3 Bottom -level stack-word in SPR IN T ... 107
5.4 Second stack-word in S P R I N T ... 107
5.5 T hird stack-word in SPR IN T ... 108
5.6 Shift register value and in c r e m e n t ...I l l 5.7 Raise carry signal during in c r e m e n t... 112
5.8 A dd register value to identical aHgned 1 112 5.9 Shifting by alternative interconnection ...113
5.10 Suggested stack im p le m e n ta tio n ... 116
5.11 Form at of 21 bit Free Page P o i n t e r ...118
5.12 Form at of 24 bit Free Page P o i n t e r ...118
5.13 Functional Registers in th e D a t a p a t h ... 122
5.14 P aram eter word f o r m a t ...124
6.1 D ata M o d e l ... 139
6.2 Level 2 F lo w c h a r t...143
6.3 Activations for com ponent 1 2 1 ... 148
6.4 Com ponents executed during step 526 149 6.5 E x tract of function activating individual s t e p s ... 149
6.6 E x tract of sequencing f u n c tio n ... 150
L ist o f F ig u res 15
6.8 Allocation of microcode w o r d s ... 169
7.1 R untim e Comparison for L i s t - C o p y ...178
7.2 Speed-up for a L is t-C o p y ... 178
7.3 D etailed speed-up for copying a 2-level L i s t ... 179
7.4 Speed-up list slice 2 -le v e l... 182
7.5 Speed-up Hst sHce 3 -le v e l... 182
7.6 Speed-up Hst d e le tio n ... 184
B .l C representation of a Hst-pointer ... 206
B.2 C D ata Fram e for SPR IN T w o r d s ...206
B.3 C representation of SPR IN T w o r d s ...207
B.4 C registers to hold a Hst s t r u c t u r e ...207
B.5 C procedures for registers m a n ip u la tio n ...209
B.6 Skeleton for th e Hst traversal a lg o r ith m ...210
B.7 PreHminary C Definition of th e Processor S tatu s W o r d ... 211
List o f T ables
1.1 Tag values in S P R I N T ... 35
4.1 Comparison of page m anagem ent m e t h o d s ... 86
5.1 Stack dem and for a SPR IN T list ... 107
5.2 Flags of the Processor S tatus W o r d ...120
6.1 A ttrib u tes of th e STEPS r e l a t i o n ... 144
6.2 A ttrib u tes of th e FOLLOW r e la tio n ...145
6.3 A ttrib u tes of th e CONSISTS r e l a t i o n ... 145
6.4 A ttribu tes of th e CO M PO N EN TS r e l a t i o n ... 145
6.5 A ttrib u tes of th e LINES relation ... 146
6.6 A ttrib u tes of the ACTIVATES r e l a t i o n ... 146
6.7 Encoding of branches in th e experim ental co-processor ... 162
6.8 Cycle C ount for experim ental A lg o rith m s ...164
7.1 Tim e dem and for a Hst copy in S P R I N T ...177
7.2 Tim e dem and for a Hst copy in th e c o -p ro c e s s o r ... 177
7.3 Tim e dem and for a nested Hst c o p y ... 180
18 L ist o f T ables
C h ap ter 1
In tro d u ctio n
C om puter Science is a fast developing subject. T here is a continuous development of new fields of application for com puters w ith a perm anently growing variety of requirem ents. In th e early days of com puting th e few existing machines were mainly used as calculators to autom ate large scale num eric processing. Since th en th e area of apphcation has developed via th e processing of business d a ta towards general inform ation and knowledge processing, covering, am ongst others, subjects such as
C om puter Integrated M anufacturing, Image Processing and Artificial InteUigence.
To allow this expansion into such a wide field of apphcations, both software and hardw are technologies had to undergo constant developm ent. Together w ith th e expansion of com puting into new apphcation areas, th e complexity of com puter program s has been growing constantly. Program m ing languages based on more and m ore sophisticated concepts have been developed and have replaced assembly lan guage and early high level program m ing languages. Different areas of apphcation dem and a range of properties from program m ing languages to express th e algo rithm s, m ainly in th e way d a ta is stored and m anipulated. Therefore a rich variety of program m ing languages aimed at different problem areas have been developed. As m ost of these new program m ing languages dem anded a lot m ore support from th e executing hardw are th an th eir predecessors did, there is a perm anent effort to improve hardw are architectures in order to offer this additional support.
20 Chapter 1. Introduction
List S tru ctu red M emory was suggested as one way of supporting m odern pro gram m ing languages using complex d ata structures to represent the inform ation to be processed. This new m em ory model could be a way to overcome the lim itations the stan d ard ‘von N eum ann’ Hnear memory stru ctu re imposes on the im plem enta tion of some program m ing languages.
This thesis is an investigation of how th e perform ance of com puter architectures based on R andom Access List Structured Memory can be improved. It is neither intended to give a detailed justification of the R andom Access List Structured M em ory concept, nor to provide a comparison w ith other m em ory concepts. B ut bo th these areas can be considered in more detail once the architectural potentials of architectures w ith List S tru ctu red M emory are b e tte r understood.
This chapter wiU first indicate th e place of this work in general trends of com puter science. A fterw ards th e ideas of List S tructured Memory are introduced together w ith an overview of SPR IN T, an example architecture using this memory concept. An analysis of the prerequisites for List S tructured M emory will lead to a first exam ination of alternative hardw are architectures based on this concept. Finally an overview of th e whole thesis is given.
1.1
T ren d s in C o m p u te r S c ie n c e
As already stated , there is a rapid development in general com puter science, b u t not all involved subjects progress at the same rate. One of the m ajor influences on new developm ents in com puter science during th e last decades was, as for m any other scientific subjects, th e dem and for increased performance^. O ther im p o rtan t areas such as fault tolerance, software refiabifity and verifiabihty are frequently still considered as minor aspects. B etter system perform ance can be achieved w ith bo th improved hardw are and more sophisticated software.
1.1. Trends in C omputer Science 21
1 .1 .1
H a r d w a r e
T he m ost common, trad itio n al m ethod of increasing hardw are perform ance is based on exploiting the technological advances in electrical engineering. As th e dimensions of transistors in integrated circuits get smaller and smaller, integration density rises and signal runtim es are reduced, enabHng higher operation frequencies resulting in faster machines. As this process seems to reach its physical Hmits w ithin an affordable technology, alternative ways of perform ance im provem ent become more im p o rtan t.
One of the m ain objectives in alternative hardw are developm ent is to exploit th e potentials of parallel execution. This can be done at various levels from having m ul tiple functional units in a processor to m ulticom puters [Hwa93]. T here are strong argum ents about design styles for individual processing units and w hat th e in stru c tion sets of these units should be Hke. W hile th e RISC versus CISC conflict [HP90] is still discussed in academic environm ents, it seems th a t th e m arkets have, at least for th e m om ent, decided in favour of th e RISC approach. The developm ent of CISC processors, such as Intel 80486 and Pentium , and their use in Personal C om puters (PC s) can be seen as an exception caused by com patibihty requirem ents of existing architectures.
T he reasons for this decision in favour of RISC processors m ight be:
1. Basic RISC processors ten d to be smaller and have simpler designs, and th e re fore require less developm ent tim e. This enables shorter product cycles, which again makes it easier to com pete in th e continuing com petition for higher pro cessing power. The shorter design tim e m eans, th a t th e designer can exploit m ore recent and faster process technology, giving a speed advantage over oth er designs w ith longer developm ent times.
22 Chapter 1. Introduction
3. The simple instruction set of RISC processors together with frequently used instruction pipeHnes allows higher clock frequencies and higher instruction exe cution rates. These high clock rates and MIPS^ numbers are popular m arketing factors. A careful instruction set design can also improve pipehne perform ance, e.g. DEC ALPHA.
4. As a consequence of their general low level instruction set several common RISC processors have a wide appHcabihty, even if not always the m ost efficient. This allows high production num bers combined w ith reasonable prices, which again promises th e required profit to th e m anufacturers.
In addition to the commercial processor im plem entations, there is also a growing num ber of experim ental RISC processors, such as Pegasus [SY90], SOAR [UBF"'"84] and SPU R [H‘*‘86], for m odern programming languages. This trend towards build ing RISC processors is probably also a consequence of shorter development times in com bination w ith lower hardw are expenditure. Shorter development times, of course, also m ean lower staffing costs for th e developing team .
The above m entioned processors offer good perform ance for their specific pro gram m ing language, whereas most other languages are supported unsatisfactorily. As a consequence, this ty p e of language oriented RISC processor can either be used to im plem ent single language machines, or as co-processor within a more general architecture.
Single language machines tend to be forced into a niche existence as m ost com p u ter users do not want to be fixed to one program m ing language. A typical example are LISP machines [Ung89] which acquired a small m arket segment of users in the Artificial Intelligence area. A nother m ajor problem of single language machines is the fact th a t even the perform ance of sophisticated architectures built for a p artic ular language can, after a short period, be easily m atched by much faster hardw are running a software im plem entation of th e particular programming language. To
1.1. Trends in Com puter Science 23
avoid this, it would be necessary to continuously enhance th e hardw are of th e single language architectures which is not very economic since th e m arket share is hm ited.
T he idea of using m ultiple speciahsed language co-processors w ithin a more gen eral architecture leads towards heterogeneous m ultiprocessor system s. The complex ity of such a system can be expected to be high, while an efhcient use of th e individual co-processors is unhkely to happen. T he m ajor problem of an efficient utihsation of m ultiple language co-processors derives from th e fact th a t this would require a bal anced load for ah co-processors. F u rth er problems such as process scheduhng would add to th e com plexity of a system using m ultiple speciahsed language co-processors.
1 .1 .2
S o ftw a r e
As a consequence of th e steadily growing hardw are perform ance, software developers can create m ore and more complex apphcations. This growing software complexity also creates new requirem ents for program m ing languages and software developm ent tools.
As software developm ent is very cost intensive, there is a strong interest to reduce th e expense in this area. O bject-oriented program m ing languages w ith their paradigm based on abstraction, encapsulation, m odularity, hierarchy, typing and concurrency [Boo91] offer re-usabihty of program code which increases efficiency, together w ith a b e tte r support for m aintenance and testing. A nother im p o rtan t point is th e fact th a t th e concurrency of O bject-oriented languages m atches the n a tu ra l concurrency of m any apphcations and therefore frees th e software developer from exphcitly stating program sections to be executed in parallel.
24 Chapter 1. Introduction
In general th ere is a tren d towards O bject-oriented and functional languages and away from im perative (von Neum ann) languages to meet the requirem ents of m odern software developm ent.
As applications differ in their requirem ents for programming paradigm s, and software developers have their own preferences for programming languages, general purpose com puter architectures need to support a broad spectrum of program m ing languages and underlying paradigms.
1 .1 .3
M e m o r y S y s t e m s
The mem ory system is one of th e points where th e interests of hardware and software development intersect. It is necessary for hardw are to implement a memory struc tu re th a t allows fast and simple access to th e d a ta structures of the software being executed. On th e oth er hand, effective software development depends on a m em ory stru ctu re th a t supports the requirem ents of th e apphed programming paradigm . Recent developm ents in th e area of memory systems seem to concentrate on mem ory hierarchies and how to increase the bandw idth between CPU and memory.
Several language specific architectures [Ung89] implement individual m em ory concepts, as th e stan d ard , ‘von N eum ann’, Hnear memory concept does not offer the best support. T he ‘von N eum ann’ architecture [BGvN73] was one of th e first com puter and m em ory architectures, developed almost 50 years ago when hardw are was the m ajor cost factor for com puter users. Therefore a simple hardw are con cept offering ju st th e basic functionaHty was appropriate at th a t time. Since then, hardw are costs have dropped faster th an software costs. The la tte r tend to be the m ajor cost factor in m odern systems. W ith this different cost situation and newer mem ory concepts available, it is questionable w hether th e ‘von N eum ann’ mem ory architecture is th e best design for many m odern computers.
1.1. Trends in Com puter Science 25
program m ing paradigm s, might be desirable for general purpose com puter architec tures, especially when the new m em ory concept expands th e possibiHties of stan d ard memory.
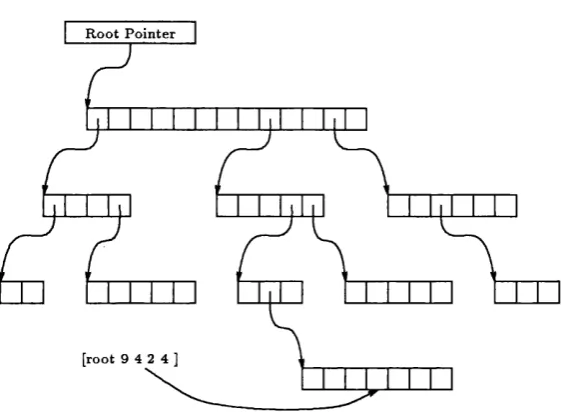
The ‘R andom Access List S tru ctu red M em ory’ approach^ seems to offer this kind of support to existing program m ing paradigm s and therefore could be used as common basis for future architectures intended for general com puting. Its m em ory stru ctu re is th a t of a group of Hsts, where each Hst can be dynam ically extended. T he individual elem ents of a Hst can be either of atom ic d a ta ty pe or a pointer to another Hst. Using this concept, a m em ory stru c tu re can be a Hnear Hst of atom ic d a ta elem ents or a complex form ation w ith tree or graph stru ctu re. Figure 1.1 gives an example for a tree shaped Hst structure. T he whole d a ta stru ctu re consists of a num ber of Hsts, combining atom ic d a ta types w ith pointers to sub-Hsts. Such a d a ta stru ctu re is dynam ic in two ways, firstly in th a t th e length of each Hst can be modified according to dem and, and secondly th a t com plete sub-structures can be added or removed when required.
The length of individual Hsts and th e depth of trees expressed in this way are logically unHmited. However, th ere wiU be physical Hmitations depending on th e system im plem entation.
Dynam ic re-sizable arrays in such a Hst stru ctu red m em ory w ith direct access offer an exceUent extension to num eric appHcations w ith unknow n array sizes. T he possibiHty to grow a n d /o r shrink arrays at runtim e helps th e software designer to avoid ‘worst case’ dimensions for arrays or even th e use of Hnear Hnked Hsts. Similar advantages exist for large scale d a ta processing, extensive coUections of records can be kept and m anipulated in arrays instead of complex m ultiple Hnked Hst stru c tures. T he way in which complex d a ta stru ctu res are used wiU be im plem entation dependent. W ithin an object-oriented program m ing system , for exam ple, a single Hst could be used to express an instance of an ab stract d a ta ty p e, w ith individual sub-Hsts for code and data.
26 Chapter 1. Introduction
R o o t P o in te r
[root 9 4 2 4 ]
Figure 1.1: Exam ple of a List S tructured Memory
T he fact th a t th e organisation of d ata in th e Ust stru ctu red mem ory (Figure 1.1) m atches th e required m em ory model of m any applications in symboHc comput- ing(e.g. M IRANDA) suggests th e suitabihty of hst stru ctu red mem ory for symboHc processing.
T he tree shaped organisation shown in Figure 1.1 is only one way of building a List S tru ctu red Memory, it is chosen for this example because it is used in this thesis. O ther, more sophisticated m em ory organisations can be im plem ented to aUow the construction of graph stru ctu res and cychc mem ory references.
1.2
W h y R a n d o m A c c e ss L ist S tr u c tu r e d
M e m o r y ?
So far it has only been stated th a t many m odern program m ing languages face dif ficulties when im plem ented on a ‘von N eum ann’ memory architecture. B ut w hat are th e exact problems and how could a new memory concept improve on these shortcomings?
1.2. Why Random Access L ist Structured M em ory ? 27
not be predicted before the program is executed. Dynamic mem ory is normally supplied, by the operating system , out of a special m emory area called ‘heap ’. In a regular memory architecture th e managem ent of this heap can easily become a complex task, whereas it is a minor task in an architecture w ith Random Access List S tructured Memory.
W hen user d a ta of an initially specified size has to be expanded {e.g. growing an array beyond its current dimensions) regular memory architectures face immense difficulties. A trivial way to m anipulate the size of memory objects, such as th a t provided by R andom Access List S tructured Memory, would greatly facilitate such expansions.
A nother problem th a t becomes more im portant is the support of user d ata w ith complex relationships between various elements of completely different types (e.^. Hypergraphs and H ypem odes [L P B ^ 93]).
Combining the random access a ttrib u te of array structures used in numeric pro cessing with complex list structures used in symbolic com puting promises a system th a t can produce good results in both application areas.
1 .2 .1
E x is t in g M e m o r y M o d e ls
28 C h a p t e r 1. Int roduct ion
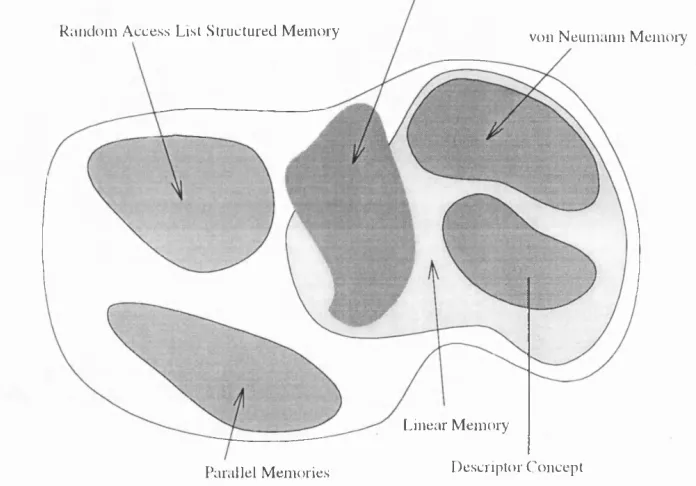
T h e co n cep t of d a ta -d e s c rip to rs [Ung89] solves th e problem of finding references
to o b jec ts, as all referencing occurs in d ire ctly via th e d e scrip to r an d only th e de
sc rip to r has to be u p d a te d w ith th e new address w hen th e o b je c t is m oved. B u t th e
m ain problem of h aving to m ove an o b je c t each tim e it grows is still not solved.
L ist Structured M e m o iy (e .g . L IS P iiia c h iiie s)
R a n d o m A c c e s s List Stru ctured M em o ry v o n N e u m a n n M e m o iy
Parallel M em o ries
L in ear M em o ry
De.scriptor C o n c e p t
F ig u re 1.2: C lassification of M em ory A rc h ite ctu res
In classic ‘von N e u m a n n ’ a rc h ite c tu re s any kind of d a ta s tru c tu rin g d isa p p e a rs
as soon as th e d a ta is sto re d in m em ory. Each m em ory value can be in te rp re te d as
any d a ta ty p e , as an ad d ress or even as code. T h e p ro p er in te rp re ta tio n of a m em ory
value has to be p e rfo rm e d by th e e x e cu te d program . C o n seq u en tly any dyn am ically
allo cated m em o ry elem en t can only be allowed to hold d a ta of a p a rtic u la r d a ta ty p e.
To enable a p ro g ra m to assign various d a ta -ty p e s to one kind of m em ory e lem en t,
softw are developers have to use com plex d a ta c o n stru c ts {e.g. unions in C). W ith in
th ese c o n stru c ts one p a rt of a know n d a ta -ty p e tells th e p ro g ram how to in te rp re t
th e rem aining p a rts of th e s tru c tu re .
To overcom e th e lim ita tio n s of u n s tru c tu re d m em ory th e co n cep t of ‘tag g ed
a rc h ite c tu re s ’ was developed in th e late 1950s [D enSl]. By giving each d a ta elem ent
1.2. W hy Random Access L ist Structured M em ory ? 29
m ethod of d a ta m anipulation. A lthough th e concept of tagged architectures offers several advantages [Feu73], it failed to have an im pact on m ainstream com puter architecture and is m ainly found in architectures for symboHc processing.
T raditional H st-structured m em ory concepts, as used in LISP machines [PT87], only offer good perform ance for Hst processing w ith m em ory access Hmited to th e Hst head. This originates in th e m em ory stru ctu re where all possible d a ta stru ctu res are built out of basic ‘cons-ceUs’, a pair of m em ory ceUs containing an atom or pointer to a subHst in th e first elem ent and a pointer to th e rest of th e d a ta stru ctu re held in th e second elem ent. W hen access to an elem ent inside th e stru c tu re is required, these pointers build a chain th a t has to be evaluated, startin g from th e head of th e Hst. NaturaUy this leads to bad perform ance for array style m em ory access as used in num eric appHcations. A significant im provem ent can be reached w ith a vector- coded [LLC90] representation of Hsts. B ut th ere is th e Hmitation th a t as soon as vector-coded Hsts are used, these Hsts wiU be fixed to a certain size resulting in th e same restrictions as arrays in regular m em ory models.
1 .2 .2
P r e r e q u is it e s for a L ist S tr u c t u r e d M e m o r y
M ost m odern program m ing paradigm s require fast dynam ic generation of new d a ta objects at ru n tim e. Heap storage m anagem ent [Pra75] is th e m ost com m on m ethod of supporting this kind of dynam ic mem ory allocation. W hen a fixed size is cho sen for all newly generated m em ory elem ents th e system wiU not produce external m em ory fragm entation and, consequently, a simple and fast storage m anagem ent is possible. Since all dynam ic allocated d a ta objects have th e same size it is easy to m aintain a perm anent flow of assigning and releasing these pages. To im plem ent an efficient m em ory architecture using a m em ory aUocation m ethod based on a fixed page size, requires th a t th e internal fragm entation is kept low. T he advantage of Hmited intern al fragm entation is th e fact th a t it only causes a Hmited m em ory over head, whereas external m em ory fragm entation requires complex and tim e intensive storage reorganisation.
30 Chapter 1. Introduction
pages, as this autom atically reduces the unused mem ory for com pact contents. At first exam ination these small fixed size pages seem to be in conflict w ith th e space requirem ents of large d a ta structures, but these large structures can be spHt over several m em ory pages as long as this sphtting is supported by th e system. To m aintain th e direct access to elements in arrays or hsts^, with these split up over multiple fixed size m em ory pages, it is necessary to determ ine the page and exact location of th e d a ta w ithin th e page at access time.
A nother common aspect of programming languages used for symbofic process ing is th e frequent use of tags to overcome th e previously m entioned problems of an u n stru ctu red memory. W hile static typed program m ing languages can five with compile-time and run-tim e checks, this is not possible for dynamically typed lan guages. As a result, any architecture intended for a machine supporting dynamic typed languages requires a tagged memory concept.
1 .2 .3
T h e P a g e - b a s e d , T r e e -s t r u c t u r e d M o d e l
The m em ory model introduced by Rounce [Rou93] was developed according to th e requirem ents outhned in th e previous section. The model takes th e idea of th e memory m anagem ent m echanism used in multi-level paged memory schemes [FM87], and applies it to build fists out of individual fixed size pages.
L ist A c c e ss
AU inform ation held in a R andom Access List S tructured Memory is stored in fists, and efficient access to these fist elements is essential. Therefore, any mem ory ac cess (instruction fetch or d a ta access) wifi involve th e addressing of a fist element. In order to address a fist elem ent, each reference wifi be kept in form of a ‘List- p o in ter’ and an element ‘Selector’. The fist-pointer indicates which fist contains
1.2. W hy Random Access L ist Structured M em ory ? 31
th e required inform ation, while th e selector references th e Hst elem ent holding the actu al inform ation.
W henever a program perform s a m em ory access, th e logical representation of ‘Hst and elem ent’ has to be transform ed into a physical m em ory address.
T ree S tr u c tu r e
As said before, a small page size allows th e intern al fragm entation to be kept low, b u t requires Hsts to be spHt over several pages, where th e system has to cover this spHtting. T he tree stru ctu re introduced here dem onstrates a m ethod by which a Hst can be m apped on to a num ber of pages and provide equal access to each element in th e Hst.
T he actual d a ta is kept in a selection of pages, w here these pages are not con strained to any locaHty w ithin th e physical address space. O n top of such a group of b o tto m level pages holding th e data, a tree-shaped hierarchy of supporting pages keeps th e order of pages a t lower levels. Each of these supporting pages contains pointers to th e pages of th e next lower level. Figure 1.3 gives an exam ple of such a tree stru ctu re including 3 levels.
T he access to th e tree stru ctu re representing a Hst is perform ed via a Hst-pointer to th e root page of th e tree. W hen addressing a d a ta elem ent th e elem ent selector is divided into a num ber of p arts equal to th e m axim um num ber of levels in th e tree stru ctu re. These p arts, each of length /o^2(page length), are th e n used to identify the pointers required for th e d a ta access. At each level of th e tree, one of these pointers is required to access th e appropriate pages a t th e nex t lower level and finally the d a ta elem ent at th e b o tto m of th e tree.
32 Chapter 1. Introduction
L istp o in ter
Selectoj
F ig u re 1.3: E x am p le of a 3-level page s tru c tu re
m em ory also enables sy stem designers to benefit from caching and v irtu a l m em ory
tech n iq u es a lre ad y developed for existing m em ory m odels.
F u rth e r details a b o u t im p le m e n ta tio n details, such as page size effects, Hst len g th
encoding an d offset tec h n iq u es are covered by R ounce [Rou93]. T h e offset tech n iq u e
of having a H m ited n u m b e r of un u sed H st-elem ents a t th e Hst head enables Hm ited
h e a d -a p p e n d in g m odifications to Hsts w ith o u t any need of d a ta m ovem ent.
1.3
B ack grou n d : S P A N and S P R IN T
So far th e th e o re tic fo u n d atio n s of R andom Access List S tru c tu re d M em ory have
been o u th n ed . T h e m em o ry concept was developed as a p a rt of th e SPA N p ro je c t.
In th is Section an overview of th is p ro je c t and th e rela te d developm ent of an arch i
1.3. Background: S P A N and S P R IN T 33
1 .3 .1
T h e S P A N p r o j e c t
W ithin th e E S P R IT research plan by th e E uropean Com munity, th e SPAN (Sym boHc Processing A nd Numeric) project was concerned w ith th e integration of nu meric and symboHc com puting. The m ain p a rt of th e project was carried out during th e period from 1987 to 1990. A good introduction into th e project and p articu larly into the VLSI research is given in [RCMS89] an off-print of which is therefore included in th e end of this thesis.
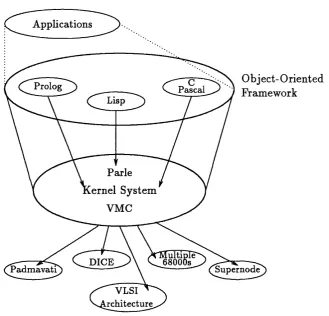
“T he activities within SP A N range from hardware to application level software, w ith one o f the principal activities being the design and im plem entation o f a common virtual architecture, the Virtual M achine or K ernel System , which provides a goal for th e high-level language and apphcation software activities, and as a starting point for the hardware workpackages. A n associated a c tiv ity around th e K ernel S ystem and language work is concerned with providing support for m ulti-style program m ing via an object-oriented program m ing environm ent. ” [RCMS89]
T he principle aim of the above m entioned object-oriented program m ing environ m ent (see Figure 1.4) was to investigate and develop an object oriented framework for integrating heterogeneous hardw are and software systems. T hus, th e environ m ent would provide for th e production of program s which had com ponents w ritten in different languages, th e language chosen being appropriate to th e task at hand, and w ith th e environm ent faciHtating th e exchange of d a ta betw een th e components.
T he K ernel System model, although an ab stract m achine model, em bodied a particu lar form of parallel architecture. This h ad a set of processors, each w ith lo cal, b u t not private, memory. T he local memories form th e logically, global shared m em ory of th e architecture. Any processor can com m unicate w ith any other pro cessor via operations on th e local m em ory of th e rem ote processor, although the com m unications m ethod was not specified.
34 Chapter 1. Introduction
Applications
V O bject-O riented ) Framework
Pascal Lisp
Parle ernel System
VMC
Multiple 68000s DICE
Supernode Padm avati
VLSI ^ rchitecture
Figure 1,4: Overview of th e SPAN project
The Kernel System (see Figure 1.4) which worked as an interface between soft ware and th e underlying hardw are, was im plem ented at two levels: a high level Language called Parle, and a low level language called th e V irtual Machine Code (VM C).
The VMC provided a full realisation of the Kernel System model at the level of a ‘machine code’ or assembler. It was intended to provide a model of the Kernel Sys tem th a t could be po rted on to a variety of parallel architectures, and was designed to be a low-level language to reduce the effort to perform th e port.
1.3. Background: S P A N and S P R IN T 35
supporting different program m ing styles, to provide an architectural environm ent suitable for a complex operating system (protection, flexible task scheduling, in ter ru p t support, etc), to provide a robust environm ent to Hmit th e effects of incorrect program s (on-the-fly bounds checks on hst accesses, type checking of instruction operands). The result of this developm ent is th e SPR IN T processor.
1 .3 .2
T h e S P R I N T P r o c e s s o r
As th e processor was designed to be functionally equivalent to th e VM C, th e com plete m em ory stru ctu re of th e parallel processor is Hst stru ctu red , using a tree shaped organisation as shown in Figure 1.1. In this im plem entation th e Hst stru ctu red m em ory is reaHsed w ith th e foUowing constraints.
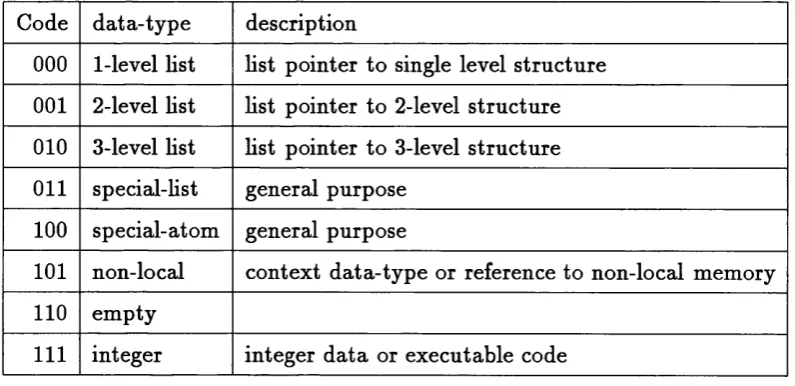
The basic tree stru ctu re used to hold Hsts is Hmited to a m axim um of three levels. Together w ith a given page size of 32 elem ents, this results in a m axim al Hst length of 32K elem ents. A Hst offset of 5 bits allows up to 32 free elem ents at th e Hst head, enabHng Hst extensions in front of th e first Hst elem ent. The actu al length of each Hst is stored in th e Hst-pointer, and can be used to verify th e elem ent selectors used to access p articu lar Hst elem ents. A 3 bit tag field offers support for th e data-types shown in Table 1.1 :
Code d a ta ty p e description
000 1-level Hst Hst pointer to single level stru ctu re 001 2-level Hst Hst pointer to 2-level stru ctu re 010 3-level Hst Hst pointer to 3-level stru ctu re O il special-Hst general purpose
100 special-atom general purpose
101 non-local context d a ta ty p e or reference to non-local memory 110 em pty
36 Chapter 1. Introduction
Most algorithm s m anipulating Hsts wiU have to distinguish the 3 basic Hst classi fication tags as weU as th e ‘integer’ and ‘em p ty ’ tags. AU five cases require different actions when encountered in a complex Hst structure. Furtherm ore the tags ‘special- Hst’ and ‘special-atom ’ are not bound to any special function and can be tre a ted to th e needs of th e user, while th e ‘non-local’ tag is used for Hst addressing purposes which are not relevant for th e evaluation of a potential co-processor.
S P R IN T is based on a 40 bit word width, aUowing th e Hst-pointers to take th e stru ctu re shown in Figure 1.5. The copy bit is a SPR IN T internal aspect and not of interest for any Hst m anipulation algorithm s. The purpose of tag field, Hst length and offset have been outhned already.
C o p y (l) Tag(3) Length(15) Page Number(16) Offset (5)
39 38 3635 2120 5 4 0
Figure 1.5: S tructure of a SPR IN T List Pointer
Since each page has a base address being a m ultiple of 32, the 16-bit Page N um ber can always be zero extended by 5 bits resulting in a basic 21-bit address space. The in term ediate page pointers in two - and three - level Hsts are not bound to these Hmitations given by th e form at of a Hst-pointer; th e SPRIN T architecture has th e option of using extended addresses for interm ediate and bottom level pages. As the address-bus of SPR IN T is 24 bits wide this is also th e Hmitation for th e extended address space.
Since SP R IN T uses a basic tree shaped version of th e Hst structured mem ory con cept, th ere is no simple way of expressing complex graph and cycHc d ata structures. Therefore this architecture is not particularly suitable for programming languages such as LISP depending on this kind of d ata structuring.
1 .3 .3
S u p p o r t for M o d e r n P r o g r a m m in g P a r a d ig m s
1.3. Background: S P A N and S P R IN T 37
to segments in m em ory architectures based on a linear m em ory organisation. The only way to address objects in m em ory is via th e list pointer and a selector. This behaviour m atches th e concept of encapsulation of th e O bject-oriented paradigm . T he same correspondence betw een th e m em ory model and O bject-oriented paradigm exists for the hierarchical stru ctu re. This hierarchical stru ctu re enables th e program m er to build complex objects consisting of subhsts representing program code, statu s and local data. This enables com plete inform ation hiding, as th e whole object is only accessible via its hst-pointer.
W hen th e Hst stru ctu red m em ory is used to im plem ent a one-dimensional array (Figure 1.6), th e access works as in a hnear m em ory w ith th e exception th a t the length of th e array can be extended on dem and,
Array Reference
tom ic Array-Data A^omi
Figure 1.6: One-dimensional A rray
W hen th e num ber of dimensions of an array is higher, the array can be expressed by an hierarchy of sub-hsts, as shown in Figure 1.7 w ith a 2-dim ensional array. W ith such an stru ctu red approach it is possible to change th e num ber of elem ents in any dimension by adjusting th e corresponding hsts.
Array Reference Row Vector
2nd Column Vector
1st Column Vector
Figure 1.7: Two-dimensional A rray
38 Chapter 1. Introduction
alternatively profit from th e Hst stru ctu red mem ory and organise different compo nents of a program in a stru ctu red way: an example is shown in Figure 1.8.
D ata Integers Program List
Stack Function Lists D ata Subhsts
Heap
Figure 1.8: Example C-program Structure
In addition to th e fact th a t th e tagged memory concept enables th e support of dynam ic ty p ed languages, it also simpHfies th e use of heterogeneous Hsts in other program m ing languages. T he availabiHty of basic types in th e form of tags also may be used to im plem ent th e ab stract d a ta types used in modern program m ing paradigm s.
Alternative Hardware Architectures 39
1 .4
A lte r n a tiv e H a r d w a r e A r c h ite c tu r e s
T he tree-based, m em ory concept introduced in th e section 1.2 and used in th e exper im ental SP R IN T architecture is a basic concept th a t can have m ultiple variations. One variable is the am ount of access privilege checking and th e creation of separate m em ory sections for individual processes. The S P R IN T architecture does not offer any d a ta protection by means of hm ited read a n d /o r w rite perm ission to individual hsts. SPR IN T also has no separation of d a ta belonging to different processes. The 3 tag bits of SPR IN T only allow a coarse grain differentiation of d a ta types. One or two additional bits in th e tag field could be used to support a wider num ber of basic d a ta types {e.g. multiple num eric types and a special indicator fo r program code).
Of course th ere exist a num ber of oth er im p o rtan t factors influencing th e whole architecture of system s containing R andom Access List S tru ctu red Memory. For exam ple, w hether th e complete system m em ory or only a p a rt of it is designed as a R andom Access List S tru ctu red Memory. A nother factor is th e support of virtual m em ory and th e m ethod of im plem entation, should one use page or hst swapping.
1 .4 .1
A c c e s s R ig h t s a n d P r o t e c t io n
The m ost elem entary version of a R andom Access List S tru ctu red M em ory does not use any additional hardw are support for hst access control. This m eans th a t the whole memory, startin g from th e m em ory root pointer, can be seen as a pool of hsts holding b o th code and data. W hen a hst elem ent refers to an o ther hst, the hst-pointer is directly included in th e elem ent. This corresponds to a single hnear address space (paged or not) in regular m em ory architectures. It represents a direct im plem entation of th e tree stru ctu red m em ory hierarchy shown in Figure 1.1.
40 Chapter 1. Introduction
W ithin each descriptor inform ation about access rights and ownership can be kept together w ith th e basic hst inform ation. W henever a reference to a new Hst is evaluated, it is necessary to verify th e access privileges of th e dem anding task. Only after this verification succeeds can access to th e requested hst element be granted. This approach is com parable to th e protection m ethods used in existing virtuad m em ory system s [Fur89]. The inform ation about hsts held in the descriptor could also include a reference counter to support Garbage Collection methods relying on this inform ation.
W ith respect to Figure 1.1, there is a level of indirection in moving from one hst to a sub-hst, and it is now possible to have m ultiple pointers to a hst and thus to adopt a graph stru ctu red ra th e r th a n tree stru ctu red memory.
Even if expressions such as pages and segments are used, the alternatives dis cussed here are purely for th e m anagem ent of th e physical level of the hst stru ctured memory. On to p of this physical mem ory m anagem ent it is stiU possible to have an additional layer im plem enting a virtual m em ory system.
1 .4 .2
L ist S tr u c tu r e d M e m o r y a s E x t e n s io n
So far hst stru ctu red m em ory has only been considered as a basic memory concept for new architectures. Adding R andom Access List S tructured Memory to exist ing architectures, based on a hnear m em ory system , is a second possibihty [RD93]. A rchitectures targ eted for numeric apphcations are th e first area of interest. In this type of architectures dynam ic arrays could replace extensive hnked hsts. How ever this kind of support could also be helpful in th e process of m anipulating d a ta where the am ount and ty p e of d a ta are not known before run-tim e {e.g. buffering polymorphic message channels).
1.5. Pure L ist Structured M em ory Architectures 41
th e controller translates w hat seems to be a Hnear address into a Hst selector and an elem ent selector, and then perform s th e requested read or w rite access inside the Hst stru ctu re. For more complex Hst m anipulations th ere are two alternatives :
a ) th e CPU m anipulates th e Hst stru ctu re while th e controUer is disabled, or
b ) a more complex controUer directly executes th e m anipulations.
1.5
P u r e L ist S tr u c tu r e d M e m o r y A r c h ite c tu r e s
W hen developing a new architecture com pletely based on R andom Access List Struc tu re d Memory, th e scalabiHty of the perform ance of such an architecture should be an im p o rtan t consideration. The scalabiHty of architectures is essential, because commercial products have to cover a range of com puting power requirem ents, which wiU aUow th e user to stay w ith the architecture when th e dem and for perform ance grows. T here are m ultiple factors of the hardw are stru ctu re influencing the perfor m ance of a com puter system. By weighing these factors carefuUy, a set of hardw are configurations representing a range of m achines w ith growing perform ance (and price) can be created. Some general scaHng elem ents for th e perform ance of com p u te r architectures are:
• CPU and m em ory speed;
• special purpose accelerating hardw are;
• degree of paraUeHsm at node level;
• num ber of com puting nodes;
• processor interconnection topology; and
42 Chapter 1. Introduction
T he basic speed of processors and m em ory is technology dependent and is beyond th e scope of this work. Anyway there is th e fact th a t developing a CPU according to RISC design philosophy will enable a shorter product cycle and, consequently, allow new versions using th e latest technology to be introduced more often. Some of the ideas for th e design of advanced processors [Hwa93] such as ‘super-scalar processors’, ‘vector u n its’ and in particular ‘instruction pipehning’ can also be appHed to CPUs operating on List S tru ctu red Memory. One m ajor elem ent of all processors will be th e support for tag analysis, and m anipulation, in parallel w ith th e regular d ata m anipulations. Perform ing th e checks and m anipulations on th e tag-held w ithin regular instructions takes a signihcant am ount of com plexity out of program s for symboHc com puting and gives additional software rehabiHty which otherwise might not be included in code. In addition to th e choices given in th e design of CPUs, there are also several techniques in th e helds of m em ory hierarchies and v irtu al memory which can be employed to vary th e perform ance of a com puter system and create a range of machines using a common concept of List S tru ctu red Memory.
W henever th e CPU spends a large am ount of its tim e on perform ing a small group of tasks, it is w orth checking if th ere is a more efficient way of performing these tasks. Normally purpose built hardw are can accelerate these tasks. Depending on th e area of apphcation and frequency of dem and, th e designer can improve the perform ance of a m achine by adding such hardw are to handle these requests. Typical examples for acceleration hardw are are: floating point units (F P U ), direct mem ory access units (DM A), graphical co-processors and digital signal processors (D SP). For architectures based on R andom Access List S tru ctu red M emory complex Hst m anipulating functions are an additional area offering th e potential for acceleration.
1.6. Structure o f the Thesis 43
memory. Such increased complexity provides a higher node perform ance, generated by allowing m ultiple mem ory transactions in parallel.
Increasing th e num ber of processing nodes norm ally can be used to scale archi tectures. There are again problems in th e areas of m em ory access organisation and in ter processor comm unication. The experim ental SPR IN T architecture [RCMS89] dem onstrates how a multi-processor system based on distributed List S tructured M emory could be designed, whereby th e existing tags are used to generate a m ech anism providing a global addressing scheme and to handle process com m unication.
1.6
S tr u c tu r e o f t h e T h e s is
A fter th e general background has been given, this thesis wiU system atically inves tig ate individual aspects related to th e enhancem ent of architectures w ith R andom Access List S tru ctu red Memory. The individual aspects introduced in th e follow ing chapters are not necessarily presented in a tem poral order, instead th e work is stru ctu red according to topics. The topics of th e chapters are as follows :
C hapter 2 will review th e ways of m anipulating d a ta stru ctu res in R andom Access List S tru ctu red Memory. Special interest will be given to load intensive functions perform ing complex Hst m anipulations. The traversing of Hst stru ctu res and memory m anagem ent are discussed as two im p o rtan t areas offering p o ten tial for hardw are to accelerate operations on d a ta structures.
C h ap ter 3 dem onstrates th e two basic concepts using R andom Access List Struc tu re d Memory. F irst it is explained how architectures using Hnear m em ory can be enhanced by adding R andom Access List S tru ctu red Memory. The functionaHty of a controUer interfacing the system buses and th e added m em ory is covered for basic re a d /w rite operations as weU as for complex Hst m anipulations.
44 Chapter 1. Introduction
to be considered in such a design are presented. Then various integration concepts for a co-processor, perform ing complex list m anipulations, are dem onstrated.
C hapter 4 covers th e developm ent of algorithm s for co-processors to perform complex Hst m anipulations. A m ajor aspect is memory m anagem ent and in p articu lar th e adm inistration of free pages. G arbage collection support, error handhng and variations of general algorithm s are discussed next. Finally these points are appHed and a set of instructions for a SPR IN T co-processor is introduced.
C hapter 5 discusses m ethods to improve th e effectiveness of th e d a tap a th in Hst m anipulating co-processors. The im plem entation of a stack mechanism and the arithm etic functionaHty are of special interest. These general techniques are then appHed for th e SPR IN T co-processor.
C hapter 6 gives an overview of th e various simulations perform ed during the developm ent of th e co-processor. A high level simulation is used to study th e stru c tu re of Hst m anipulating algorithm s and to identify th e d a ta p a th requirem ents. The fu rth er developm ent of th e algorithm s th en requires a formal description of the m icro-program. Existing micro-code developm ent techniques wiU be analysed and a new technique is introduced. A behavioural simulation of th e m icro-program is used to check th e functionaHty of th e algorithm s and th e d atap ath . Once th e char acteristics of th e m icro-program are known, it is possible to develop a stru ctu re for th e processor control p art. A controUer stru ctu re w ith reduced area requirem ents is introduced and its functionaHty proven w ith a final gate-level simulation.
C hapter 7 compares th e perform ance of th e sim ulated co-processor to software so lutions perform ing th e same Hst m anipulations. An exam ination of th e co-processor practicaHty shows th a t th e suggested co-processor could be produced using currently available technology.
1 .7
S t a te m e n t o f O r ig in a lity
1.7. Statem ent o f Originality 45
On top of these foundations th e following contributions to knowledge were achieved:
• A co-processor for Hst m anipulation has been developed. W ith this co-processor it is possible to support th e m anipulation (copy, modify, delete, of complex d a ta stru ctu res in hardw are, whereas in a conventional architecture th e same tasks have to be perform ed in software, as corresponding DMA devices only support continuous Hnear address areas.
• A new m ethodology for th e developm ent of m icrocode has been presented. T he integration of databases into th e developm ent of microcode using th e flowcharting approach offers a significant am ount of autom ation, while th e flexibihty of the design process is hardly hm ited. This new m ethodology is apphcable to processor structures where current microcode design m ethods fail to offer sufficient support.
These findings and related aspects are presented as foUows:
C h a p t e r 3 Presents different configurations of co-processor(s) connected to proces sor nodes and considers th e advantages and disadvantages of these architec tures. The SPR IN T architecture is used to iUustrate th e individual concepts. A m odel to enhance existing com puter architectures by adding R andom Ac cess List S tructured M emory is introduced. The ideas for this approach were developed jointly w ith Dr. P eter Rounce.
C h a p t e r 4 Discusses different approaches to im plem ent th e m em ory m anagem ent in an architecture w ith R andom Access List S tru ctu red Memory. Different solutions for th e adm inistration of free m em ory pages and th eir allocation are presented.
A set of possible functions for a SPR IN T co-processor are explained, consid ering general aspects as weU as special aspects related to th e architecture. C h a p t e r 5 Explains various design aspects of a d a ta p a th for a co-processor oper
46 Chapter 1. Introduction
The general ideas for th e d a ta p a th design are appHed to th e architectural guidehnes of th e SPR IN T architecture and th e d a ta p a th of th e experim ental co-processor is introduced.
C h a p ter 2
M a n ip u la tin g List S tru ctu red
M em o ry
The principal ideas behind th e R andom Access List S tru ctu red M emory concept were introduced in th e previous chapter, and this section wiU concentrate on th e m anipulation of d a ta stored in such a memory. The analysis of these m em ory m a nipulations is im p o rtan t, as th e resulting knowledge wiU be th e key for im provem ent.
T he basic ty p e of m em ory m anipulations wiU of course be form ed by elem ental operations on single m em ory words. As in a regular m em ory architecture, th ere will be operations where the processor reads or writes a d a ta value fro m /in to a given m em ory location. During such a m em ory access either th e active processor, or a special M emory M anagem ent U nit (M MU), is responsible for converting th e ad dress from a List-pointer and Selector representation into th e corresponding physical m em ory address. Depending on th e requirem ents of th e architecture more complex atom ic single word operations such as read-m odify-write cycles can be supported in th e same way as in a stan d ard memory.
W hile these stan d ard operations are ju st a basic necessity for any m em ory con cept, a real advantage of a R andom Access List S tru ctu red M emory Hes in th e area of complex Hst operations. A num ber of possible operations are introduced here. W hile some of these functions are essential, others m ight ju st be useful and could be derived from essential operations. The set of essential functions includes: Hst