Detection and Analysis of Shellcode in Malicious
Documents
1 Gladis Brinda, 2 Geogen George
1
Department of Information Technology, SRM University
SRM Nagar, Potheri, Kattankulathur-603203, Kancheepuram, Tamil Nadu 603203, India.
2
Assistant Professor, Information Security Research Center, SRM University
SRM Nagar, Potheri, Kattankulathur-603203, Kancheepuram, Tamil Nadu 603203, India.
Abstract - A Shellcode is a code snippet used as a payload in exploiting software vulnerability. In recent trends of attack, shellcode embedded in documents are one of the widely used vectors for targeted attacks. The significant aspect of these documents are dynamic content, URL access and can be camouflaged easily. Most of the security mechanisms are not accoutered to deal with these weaponised documents. In this paper, we propose a tool to detect and identify the malicious shellcode in documents such as PDF, Word, and PPTs that are readily available over the internet for exchange of data. The tool performs both static and dynamic analysis to detect and analyze the shellcode present. It extracts the features of the document which is used to categorize a malicious document and a benign document, perform code analysis on the suspicious object streams. The JavaScript is de-obfuscated and interpreted using a JavaScript engine. Finally using decision tree algorithm for machine learning, dynamic analysis is performed.
Keywords - Dynamic Analysis, Static Analysis, Machine Learning, Weaponised Documents.
1.
Introduction
Malware is a collective term, used to describe any software that damages or disrupts the system. The attackers are increasingly targeting extensively used applications such as Web Browsers, PDF and Microsoft Office suite of application for spreading malware. On successful exploitation of a vulnerability using assembly language exploit code, it spawns a shell for the attacker. Hence the name shellcode, and is the highest level of privilege obtained. The task of shellcode is to provide backdoor access or download additional malware. Remote exploits, client-side exploits, are used as cyber-attack mechanism since they are rather hard to mitigate. Therefore, attackers pay more attention to the weak
aspects of the PDF, Word, PPT formats that can be easily exploited.
Microsoft Office is the title holder of the Object Linking and Embedding Technology. It allows embedding and linking to the documents or any other objects. It primarily enables adding different data components from different sources. It creates a compound document, commonly addressed as compound binary file. Compound Binary File (CBF) stores data in multiple streams and stores these streams in different storages. The streams are like files in a real file system and the storage are like sub directories. Portable Document Format (PDF) is owned by adobe systems. It is a document format, which describes the text formatting, graphics hypertext, bookmarks and multimedia elements. It supports a clever file structure to keep the size as small as possible, with the help of an advanced compression algorithm. The dynamic data induces attackers to include shellcode into PDF which uses vulnerability to execute malicious code on the targeted system.
The remainder of the paper is constructed in the following manner, Section I explains the file format of OLE and PDF file formats. Section II emphasize the related works to identify the problem statement. Section III discusses the proposed solution and evaluates the glitches likely to be faced. Section IV deals with the scope of future works.
1.1 PDF Overview
A PDF document consists of objects, represented as sequence of bytes. Objects can either be direct or indirect. Direct objects are embedded and are independent of other objects. Indirect objects, on the other hand are numbered with an object number or generation number.
Objects are classified into eight data types:
• Boolean values
• Numbers • Strings
• Names
• Arrays • Dictionaries • Streams
• The null object
The basic PDF file structure consists of the following elements as shown in Fig 1:
• Header: It is the first line of every PDF file and
mentions the PDF version.
• Body: This is where the documents data resides.
• Xref Table: The cross-reference table contains a
reference to all the objects in the file. It specifies the reference to indirect objects and the size of the table. Each entity in the table specifies the object version, position and if the object is in use or not. Understanding the Xref table is ideal in analyzing the PDF. The number following Xref, ‘0’ indicates the counting of indexed objects beginning from 0 and specifies the number of objects indexed to Xref table.
• Trailer: The information available in the trailer section enables PDF application to identify the Xref table and the special objects of the file. All PDF readers start reading the PDF from the end of the file, that is specified by the string “%%EOF”. Before the EOF the PDF reader looks for startxref keyword followed by the pointer, which points to the cross-reference table.
Fig 1. PDF Structure
After parsing the trailer and Xref table, the PDF reader parses the dictionary to obtain the key-value pair of the objects. Keys are names that starts with “/” and values can be anything. The /root key value pair is considered to be important. The objects of the PDF are organized using the COS tree format. The /root key is used to identify the root of the tree structure. In our example the value associated is /root 1 0 R. The letter R indicates that it is references object 1.
1 0 obj
<</Type /Catalog
/Pages 3 0 R
>>
endobj
The dictionary contains the keywords of all the objects in the PDF. Processing the dictionary will help us to identify malicious objects like /OpenAction which instructs the PDF to perform an action when the document is opened. The scripts contained in these objects can then be analyzed by using JavaScript interpreters. However the PDF JavaScript engine is sandboxed, so that it cannot compromise the windows machine directly. But there are always ways to exploit the JavaScript interpreter indirectly.
1.2 CBF Format Overview
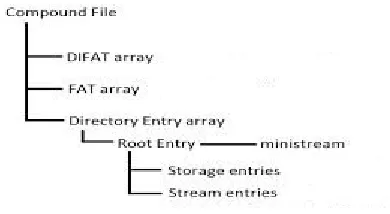
Compound Binary File contains a number of independent data streams that are organized based on the hierarchy of storage as shown in Fig 2. The direct members of all storage and streams are named differently but it is possible for the two different storages to have same stream names.
Fig 2. CBF Components
The compound document file header contains all the data required to parse the file. The first 8 bytes of the header contains the magical numbers, the Compound Document File Identifier. It bears the hex “D0 CF 11 E0 A1 B1 1A E1” used to identify a valid CBF file. Therefore in order to read data from a stream, the header is analyzed to obtain Master Sector Allocation Table (MSAT) information. The MSAT contains sector-ISD and Sector Allocation Table (SAT) and Short Sector Allocation Table (SSAT). The directory entry point and the short stream container are obtained to read data from a stream. These streams of data are then analyzed if they are candidates of shellcode.
2.
Related Work
The mere presence of the JavaScript or Macro in a document, does not classify it as a malicious content. To hinder malware analysts from analyzing the documents, attackers use obfuscation and evasion techniques. In order to double check the malicious content, the metadata of the documents was also analyzed to classify a malicious and non-malicious document. These methods share global statistics on the PDF objects and structure tree format. Maiorca et al, 2012[5], introduced a tool that classifies PDF documents based on the embedded keywords and their occurrence. The main idea was to identify malicious PDF files whether or not they contain malicious JavaScript. Srndic and Laskov in 2013 [11, 12] came up with a jazzed-up static analysis method that uses the structural property of PDF documents. The PDF documents consists of structural paths that characterize the document’s structure. This detection method was effective, however attackers came up with evasion techniques to bypass the detection of malicious JavaScript.
The entropy based detection method by Pareek et al, 2013[6] put forward that the level of ambiguity in malicious files is less than that of benign files. The evaluation results based on the Entropy calculation indicated that low entropy level is a strong indicator maliciousness.
Later, Smutz and Stavrou, 2012 [10] implemented a robust feature extractor, that extracts around 202 features, comprising of document metadata and document’s structure specific meta-features. This method created self-implemented reliable parser for feature extraction, because existing tools are unable to deal with malformed documents.
Tzermias et al., 2011[14] introduced a standalone document analyzer which performs both static and dynamic analysis on PDF documents. The MDScan statically extracts all the objects from the document body. The embedded JavaScript that is extracted is examined by
running dynamically in a JavaScript engine. However, Schmitt et al., 2012 [7] introduced PDF Scrutinizer, a tool to detect and analyze the maliciousness of documents through static and dynamic analysis. It uses JavaScript librarywhich extends existing components such as Apache PDFBox Java library, to load PDF documents.During execution, libemu library is used to analyse variable values for the existence of shellcode. PDF Scrutinizer does not use a machine learning algorithm for classification. This method was effective with 0% false positive detection rate.
To overcome the weakness of the parser in extracting JavaScript code from the file, Lu et al., 2013[4] introduced MPScan, a technique that integrated static malware detection and dynamic JavaScript de-obfuscation. It contained an embedded code extractor and a multilevel malware detection module. Static analysis is performed on the extracted embedded code, and the multilevel malware detects heap spraying with shellcode by hooking Adobe Reader’s native JavaScript engine. Malicious documents may also contain malicious URL, to drop executables in the victim’s machine. Based on a novel approach proposed by Sinha et al, 2008[9], that creates a heuristic analysis of the site content and from user feedback, a list of known bad websites called blacklisting.
The automated analysis of malware behavior by Konrad et al, 2011[3] proposed a framework for automatically identifying novel classes of malware with clustering and classification based on malware behavior. The incremental analysis significantly reduced run-time overhead of dynamic analysis method, while providing accurate discovery and discrimination of novel malware variants.
.
3.
Design and Implementation
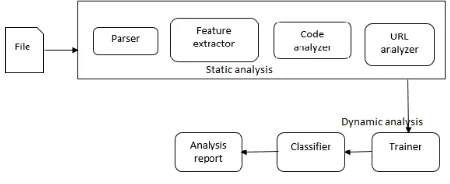
The foremost objective is to develop a tool, that detects and analyses shellcode present in malicious documents like PDF, Word, PPT. Fig 3, shows the internal components of the tool. It shows both the static and dynamic analysis. The static and dynamic analysis is implemented on Ubuntu 14.04. Dynamic analysis can be used to monitor the runtime behavior of the shellcode, while static analyzes the code without executing it.
Initially, we determine the input file, if it is a valid PDF, PPT or Word file. The files are then parsed by the respective parsers. An inbuilt python parser parses the documents and extracts the keywords namely /JavaScript, /OpenAction, /Launch, /Macro, /URI Etc. These features are used to classify a malicious and benign file. The contents of the extracted features are obtained and code analysis, URL analysis are performed. The embedded URL is queried with the blacklist maintained by uribl.com. The code is checked, if it is obfuscated, and if any evasion techniques prevail. A JavaScript engine is used to de-obfuscate the code and extract the shellcode. The obtained shellcode is emulated using the python library [1] and the raw code is obtained. The code is then interpreted and a tentative inference of the behavior of the shellcode is made. The outcome of this analysis is reported as static analysis report.
In the case of Dynamic analysis, fault-invariant classifier is implemented. The document properties are generated by an arbitrary program analysis. This technique is used to detect properties of the document that are likely to be malicious. It consists of two components, the trainer and classifier. Training is a preprocessing step that extracts features or properties known as priori. The trainer uses machine learning algorithm, decision trees to train the tool on properties of malicious and benign documents. It converts those properties into malicious code revealing properties. The classifier uses the precompiled features against documents, and it selects features of documents that are malicious. The inferences from the static analysis and observations of dynamic analysis are updated into an analysis report for future reference.
3.1 Issues To Be Addressed
• It is possible for the shellcode executing in the host machine to take complete control of the tool and hinder dynamic analysis.
• Shellcode is capable of millions of instruction
during runtime. Monitoring millions of instructions can be a tedious task.
• Evasion techniques can totally make static
analysis of code unfeasible and increase the difficulty of API tracing.
4.
Future Works
In the near future, this tool may be integrated with antivirus engine or by network administrators, to monitor the files arriving at the firewall to enter a network. Moreover, the possibility to analyse shellcode extracted from different sources has been given a forethought, and hence to extend the support for different execution contexts. We plan to implement a browser extension that is
able to use the characterization learned to proactively block drive-by-download attacks of malicious documents.
5.
Conclusion
Malicious documents remain an unaware threat, requiring robust detection and analysis techniques. In this paper, we focus on reviewing the existing tools like Wepawet [2], methods and techniques that requires our significant attention. An intrinsic component of the suggested tool makes sure that the evading detection mechanism in static analysis is significantly reduced. It is also demonstrates the ability of machine learning algorithm to select properties to expose malicious features in documents. The experimental evaluation uses Fault Invariant Classifier. For preliminary analysis that reflects the important aspects of malicious code revealing properties, that can help malware analysts for better understanding the viable threats through documents.
References
[1] Libemu [2007] http://libemu.carnivore.it [2] Wepawet [2008] http://wepawet.cs.ucsb.edu
[3] Konrad Rieck, Philipp Trinius, Carsten William, and Thorsten Holz, Automatic Analysis of Malware Behaviors using Machine Learning presented in the Journal of Computer Science, 2011.
[4] Lu,Jianwei Zhuge,Ruoyu Wang, Yan Chen, YinZhi Cao, De-obfuscation and detection of malicious PDF File with high accuracy. Presented at the 46th Hawaii International Conference on System Science, 2013. [5] Maiorca D, Giacinto G, Corona I., Looking at the bag
is not enough to find the bomb: An evasion of structural methods for malicious PDF files detection. Presented at the Proceedings of the 8th ACM SIGSAC Symposium of Information, Computer and Communications Security, 2013.
[6] Pareek H, Eashwari P, Babu NSC, Bangalore C, Entropy and n-gram analysis of malicious PDF documents, 2013.
[7] Schmitt F, Gassen J, Gerhards-Padilla E., PDF Scrutinizer: Detect JavaScript-based attacks in PDF documents. Presented at Privacy, Security and Trust (PST), Tenth Annual International Conference, 2012. [8] Schreck T, Berger S, Gobel J BISSAM: Automatic
vulnerability identification in office documents. In: Detection of intrusions and malware, and vulnerability assessment anonymous, 2013.
[9] Sinha. S, Bailey.M, Andjahanian. F .Shades of grey: On the effectiveness of reputation based blacklists. In Proceedings of the International Conference on Malicious and Unwared Software (Malware), 2008. [10] Smutz C, Stavrov A, Malicious PDF detection using
metadata and structural Features. Presented at proceedings of the 28th Annual Computer Security Applications Conference, 2012.
proceeding of the 20th Annual Network & Distributed System Security Symposium, 2013.
[12] Srndic N, Laskov P, Static detection of malicious JavaScript-bearing PDF documents, 2011.
[13] Stevens D, Malicious PDF documents explained. Secur Priv IEEE Jan –Feb 9(1):80-2, 2011.
[14] Tzermias Z, Sykiotakis G, Polychronakis M, Markatos EP, Combining Static and Dynamic analysis for the detection of malicious documents. Presented at Proceedings of the Fourth European Workshop on System Security, 2011.
[15] Ulucenk c, Varadharajan V, Tupakula U, Balakrishnan Venkat., Techniques for Analyzing PDF Malware. Presented at the Proceeding of the 18th Asia-Pacific Software Engineering Conference, 2011.