Prediction Of Dibates Malleus Using Machine
Learning Classification Techniques
Minyechil Alehegn
Abstract: Understanding of the application of Information Technology is very challengeable. It has its own role in different aspects including in the prediction of Diabetes diseases. Now a day diabetes is very dangerous throughout the world .in order to minimize the number of people who dies by this disease’s information technology has a great role to provide a solution. Technology has the power in different aspects in different industries. most of the time getting the problem indicating that half of the problem solved .in this paper four algorithm ZeroR, SVM, J48, and NB. Algorithms provides 78.26%,90.23%,88.02%, and 88.54% respectively. Support vector machine algorithm shows effective and better accuracy and ZeroR is the least one with accuracy value of 78.26%.
Index Terms: Prediction, Diabetes, support vector machine, Probabilistic model, feature selection, Machine Learning,
—————————— ——————————
1 INTRODUCTION
Now a day Information technology has the role in any fields of study including heath area. Data mining is as the name indicates mining the data from some storage for some purpose.in medical area Data mining play a great role for different diseases specially for prediction purpose. Both in developed and developing country there are in millions of people live with this disease .as most f known for one country the middle ages have great role in both standards of the country. because of this disease there are world lost the middle age peoples by this disease.by the reports of 2014, the peoples whose ages are between 18 and 18+ live with diabetic to here this very difficult as we think like [10], even if it is difficult to remove the diseases to tally it is possible to protect at early stage by making awareness and by doing research using different mechanism. Arianna et al [16] One of the extents where Artificial Intelligence is having more effect is machine learning, which develops processes able to learn patterns and decision rules from facts.
2 RELATED WORK
Ioannis et al. [1] for effective utilization of large dataset data mining technic are very important in addition to that feature selection was applied in their work. Santhanam and Padmavathi [2] reduction of large dataset in to small data by applying different mechanism helps to improve the accuracy. most of the researcher conclude that some algorithms provide better performance in small data set than large data set. Tao et al. [3] as different types of diabetes they have different effects on human being. Here new frame created in order to minimize the death of human by type II diabetes. Antti-jussi pyykkonenetal.[4] The life style of human leads
poor health. especially in African countries the life style of very poor that cases poor health. Living standard is one of the case for disease. a person who have good life style may less chance for getting diseases than poor life style. Abdullah et al [5] diabetes disease has different power based on age and sex. Vrushali and Rakhi[6]in various bodies estimation and severity of diabetes studied in different parts of bodies. Faisal Faruque et al [7] different techniques have various prediction value or power C4.5 was better. Lin [8] meta classifiers are very intelligent for prediction purpose.as the name indicates and also as in real world we seen that team work can achieve more than individuals the same to that meta classifiers are very strong and power full to get better result in prediction area. using meta method prediction can be improved. Hasan et al [9] neural network can be used in this study. Correct training was applied for forecasting. Jan Cederholm et al [11] assessing in 5 years is better than assessing in 1o years.wei yu et al [12] svm is better for binary classification. Messan Komi et al [13] using small dataset some algorithm delivers valuable results. Artificial neural network is relatively better. Prableen Kaur and Manik Sharma [14] Primary diagnosis of diabetes can idea the critical problems and help to save human life. [15] Rifat et al [17] Naïve Bayes is the superlative classifier for using the 10-fold cross-validation. Forcasting the sickness at early stage can save the valuable human resources. Foremost to timey and proper treatment of patients. mario[18] ANN based method is an outstanding analyst for gestational diabetes mallitus .A.sheik Abdullah et al[19] the variation in the gain with model improvements can be arranged for threat factor forecast in type II diabetes . Abdullah A. Aljumah et al [20] different results displayed between young and old patients .in young age it is possible to remove side effects but in old age patients they should be prescribed drug for treatment along with other treatment methods. Old patients’ needs help and assessment as well as treatment plan that suitable to their needs and lifestyle. Konstantina Kourouet et al [ 21] different techniques including ANN, SVM, DTs and BNs are wildly applicable for the purpose of forecasting in different diseases. using machine learning helps to improve understanding level in the evaluation purpose. Deepti Sisodiaa, and Dilip Singh Sisodia [22] performances of three algorithm NB, SVM, and DT are achieved and from those three algorithms and provides ground result than others the outcome are verified using ROC. Han Wu et al [23] prediction models are very important in the realistic
_______________________
3143 IJSTR©2020
www.ijstr.org health management of different diseases including
diabetes. Cass 1: Normal (500)
3 METHODOLOGY
3.1 Data collection
In real world data is very important in every aspects of research. The data may be relevant or irrelevant. most of the time the problem to do research is data. I this study the data collected from public source which is stored on public repository which helps for researchers, academicians, students and etc. PIDD data set is very popular and most researchers use this dataset. here also I applied this data from UCI repository. The class distribution of this dataset is
Class 2: Diabetic (268)
DATA PREPROCESSING
After the source or the data getting the next step is preparation of the collected data. Preprocessing is the process of making the data clean. The data should be preprocessing in order to estimate correctly. the data contains noisy data, irrelevant attributes etc., so by using different mechanism the data should be preprocess. The corrupted data should be cleaned or repair. No missing data is included in the dataset collected from online
FEATURE SELECTION
All attributes may not important for prediction .it has different advantages the first advantage is it helps to increase the accuracy and the second one is to remove .in our dataset the attribute which have less importance removed.
Table 1 PIDD attribute description Attribute
Name Description
1 Pregnancies The frequency of pregnant
2 Glucose Plasma glucose concentration a 2 hours in an oral glucose tolerance test
3 Bp The blood pressure of the patient 4 Insuline It is 2 hr. serum insulin
5 BMI Body mass index which is calculated from weight and length of the patient
6
Diabetes Pedigree Function
history of family
7 Age Age of patient Class Presence and absence
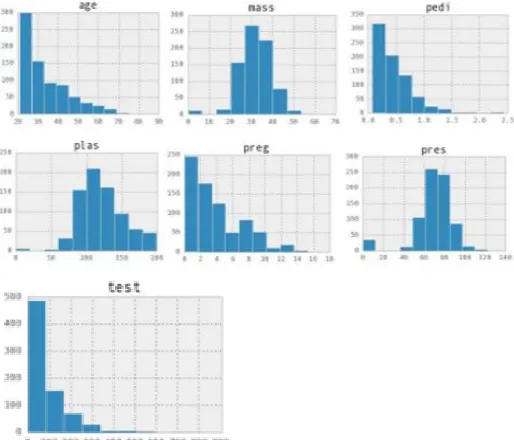
DATA DISTRIBUTION
in the distribution of data some of the data are normal distribution like Pregnancies (pres), Glucose or plasma, and body mass index (BMI) were grouped under normal
distribution. And some of them are negative Exponential distribution). pregnancy, insulin (test), Age, and pedigree function are grouped under this type of exponential.
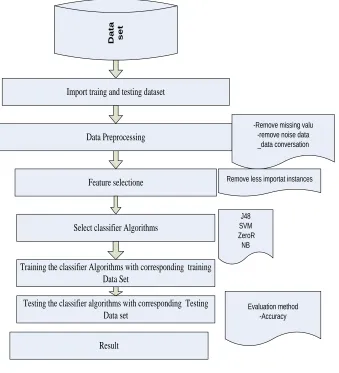
figure 1 Proposed model
Algorithms to be considered
Import traing and testing dataset
D
a
ta
s
e
t
Feature selectione Data Preprocessing
Select classifier Algorithms
-Remove missing valu -remove noise data _data conversation
Testing the classifier algorithms with corresponding Testing Data set
Training the classifier Algorithms with corresponding training Data Set
J48 SVM ZeroR
NB
Remove less importat instances
Result
Evaluation method -Accuracy
ZeroR
1.construct occurrence table
2.construct frequency table for the target
3. select the most frequent value J48 algorithm
1For i=0 to n
2 Calculate information gain
3 Let Ta=testing instances
4 n.ta=instances which have hignst info gain
5calculaclassification
Support vector machine
1. Identification of right hyper plane
2. Exploiting the spaces between neighbor data point
3. Adding a feature Z=X^2+Y^2. SVM solves such problem.
𝑝 𝐶 𝑥 =𝑃 𝑋 𝐶 𝑃 𝐶 𝑝 𝑥 Nave Bayes Algorithm
1 Prediction of naïve Bayes classifier
2. The learning Algorithm
3 Train
3145 IJSTR©2020
www.ijstr.org
RESULT
Accuracy =
---(1)
Which means that Accuracy =
Table 2 : The predictive accuracy considered algorithms
Figure 2 Accuracy OF Algorithms
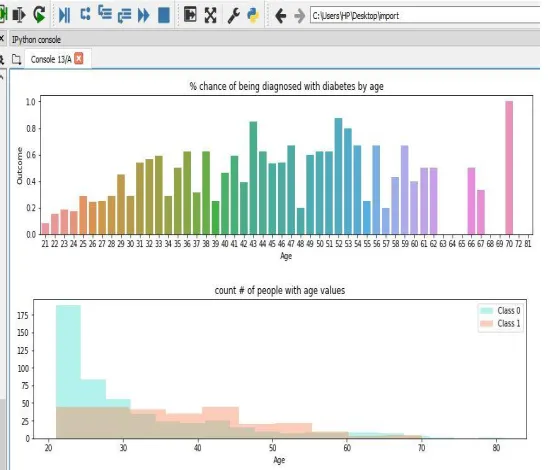
Figure 3 Chance of being diagnosed in age
Figure 4Chance of being diagnosed in pregnancies
CONCLUSION AND FUTURE WORK
Previously various classification techniques and their applications were swotted in various perspectives. Machine Learning method applied on different medical datasets including diabetes dataset the algorithms which applied on the purpose of prediction have different power depends on the size of the data that we used. In this paper, pima Indian diabetes dataset used with 768 records and 7 attributes .10K cross validation for both in single and multiple reiterations with 90 % for training and 10 % for testing considered. commonly used and well-known classification machine learning techniques are used in this study. Out of considered four methods support vector machine showed better result with accuracy of 90.23%. The current work desires to be tested with large collection of data in future and/ or by hybridizing these techniques in order to increase their forecasting result.
REFERENCES
[1] Kavakiotis, Ioannis, Olga Tsave, Athanasios Salifoglou, Nicos Maglaveras, Ioannis Vlahavas, and Ioanna Chouvarda. "Machine learning and data mining methods in diabetes research." Computational and structural biotechnology journal(2017).
[2] Santhanam, T., & Padmavathi, M. S. (2015). Application of K-means and genetic algorithms for dimension reduction by integrating SVM for diabetes diagnosis. Procedia Computer Science, 47, 76-83. [3] Zheng, Tao, Wei Xie, Liling Xu, Xiaoying He, Ya Zhang,
Mingrong You, Gong Yang, and You Chen. "A machine learning-based framework to identify type 2 diabetes through electronic health records." International journal of medical informatics 97 (2017): 120-127.
[4] Pyykkönen, A. J., Räikkönen, K., Tuomi, T., Eriksson,
J. G., Groop, L., & Isomaa, B. (2010). Stressful lifeevents and the metabolic syndrome: the prevalence,
prediction and prevention of diabetes
(PPP)-BotniaStudy. Diabetes care, 33(2), 378-384.
[5] Aljumah, Abdullah A., Mohammed Gulam Ahamad, and
Mohammad Khubeb Siddiqui. "Application of data mining: Diabetes health care in young and old patients." Journal of King Saud University-Computer and Information Sciences 25, no. 2 (2013): 127-136. 0
50 100
ZeroR SVM J48 NB
A
cc
u
ra
cy
Concidered Algorithms
performance of Algorithms
correctly class incorrecty classifed
Algorithms Accuracy of Correctly classified
Accuracy of Incorrectly classified
ZeroR 78.26% 21.74%
SVM 90.23% 9.77%
J48 88.02% 11.98%
Navie
[6] Balpande, V. R., & Wajgi, R. D. (2017, February). Prediction and severity estimation of diabetes using data mining technique. In Innovative Mechanisms for Industry Applications (ICIMIA), 2017 International Conference on (pp. 576-580). IEEE.
[7] Faruque, M., & Sarker, I. H. (2019). Performance
Analysis of Machine Learning Techniques to Predict Diabetes Mellitus. arXiv preprint arXiv:1902.10028. [8] Nai-arun, N., & Moungmai, R. (2015). Comparison of
classifiers for the risk of diabetes prediction. Procedia Computer Science, 69, 132-142.
[9] Temurtas, H., Yumusak, N., & Temurtas, F. (2009). A
comparative study on diabetes disease diagnosis using
neural networks. Expert Systems with
applications, 36(4), 8610-8615.
[10] https://www.kaggle.com/uciml/pima-indians-diabetes-database and https://cioslab.vcu.edu/
[11] Cederholm, J., Eeg-Olofsson, K., Eliasson, B.,
Zethelius, B., Nilsson, P. M., & Gudbjörnsdottir, S. (2008). Risk prediction of cardiovascular disease in type 2 diabetes: a risk equation from the Swedish National Diabetes Register. Diabetes care, 31(10), 2038-2043.
[12] Yu, W., Liu, T., Valdez, R., Gwinn, M., & Khoury, M. J.
(2010). Application of support vector machine modeling for prediction of common diseases: the case of diabetes and pre-diabetes. BMC medical informatics and decision making, 10(1), 16.
[13] Komi, M., Li, J., Zhai, Y., & Zhang, X. (2017, June).
Application of data mining methods in diabetes prediction. In 2017 2nd International Conference on Image, Vision and Computing (ICIVC) (pp. 1006-1010). IEEE.
[14] Kaur, P., & Sharma, M. (2018). Analysis of Data Mining
and Soft Computing Techniques in Prospecting Diabetes Disorder in Human Beings: A Review. Int. J. Pharm. Sci. Res, 9, 2700-2719.
[15] Data mining algorithms give an exposure to analyse, detect and predict the presence of disease and help doctors in decision-making by early detection and right management.
[16] Dagliati, A., Marini, S., Sacchi, L., Cogni, G., Teliti, M.,
Tibollo, V., ... & Bellazzi, R. (2018). Machine learning methods to predict diabetes complications. Journal of diabetes science and technology, 12(2), 295-302.
[17] Hossain, R., Mahmud, S. H., Hossin, M. A., Noori, S. R.
H., & Jahan, H. (2018). PRMT: Predicting Risk Factor of Obesity among Middle-Aged People Using Data Mining Techniques. Procedia computer science, 132, 1068-1076.
[18] Moreira, M. W., Rodrigues, J. J., Kumar, N.,
Al-Muhtadi, J., & Korotaev, V. (2018). Evolutionary radial basis function network for gestational diabetes data analytics. Journal of computational science, 27, 410-417.
[19] Kaur, P., Sharma, N., Singh, A., & Gill, B. (2018,
November). CI-DPF: A Cloud IoT based Framework for Diabetes Prediction. In 2018 IEEE 9th Annual Information Technology, Electronics and Mobile Communication Conference (IEMCON)(pp. 654-660). IEEE.
[20] Aljumah, A. A., Ahamad, M. G., & Siddiqui, M. K.
(2013). Application of data mining: Diabetes health care
in young and old patients. Journal of King Saud University-Computer and Information Sciences, 25(2), 127-136.
[21] Kourou, K., Exarchos, T. P., Exarchos, K. P.,
Karamouzis, M. V., & Fotiadis, D. I. (2015). Machine learning applications in cancer prognosis and prediction. Computational and structural biotechnology journal, 13, 8-17.
[22] Sisodia, D., & Sisodia, D. S. (2018). Prediction of
diabetes using classification algorithms. Procedia
computer science, 132, 1578-158