150
Deep Learning Based Twitter Users Classification
Using Sentiment Analysis
K. Sarvana Kumari, Dr. B. Manjula
ABSTRACT: -Sentiment analysis is essential for social alignment, especially when there are many Twitter users nowadays. In every rational sense, each of the previous works is dependent on old classification systems, for example SVM, Naïve Bayes, etc. Starting from late, fundamental learning techniques have shown promising accuracy in this space about the body of tweets in English. In this article we propose the fundamental assessment that enormous learning structures apply to gather the sense of Twitter information. There are two colossal learning methods with regard to our evaluation: short-term memory (LSTM) and dynamic convolution neural network (DCNN). A preprocessing of certifiable information has been promoted. We also investigate the impact of word management on tweets. The results show that critical learning strategies classified old style structures in all aspects: Naïve Bayes and SVM, with the exception of Maximum entropy.
Keywords: Sentiment analysis, deep neural network, convolutional neural network, deep belief network.
————————————————————
1. INTRODUCTION
A. Sentiment Analysis
The analysis of emotions suggests the relationship of emotions, opinions and exciting substance [1]. Morale analysis provides comprehensive information about open views, looking at different tweets and reviews. It is a recognized tool to verify several irreplaceable events, for example, the implementation of films for films and public elections [2]. Open surveys are used to draw a specific material, for example, an individual, a thing or a region, and can be found in different objectives, such as Amazon and Yelp. Negative, positive or unbiased opinions can be observed. The purpose of moral analysis is to determine the expressive title of client studies traditionally [3]. Energy is driven for the analysis of morals due to the urgent need to separate and manage the verified information that begins in social networks as unstructured data [4].
1) Features of Sentiment Analysis: Sentiments contain a combination of outstanding aspects such as triangular and double fine polarization and mixing systems. Therefore, emotions are examined as negative and positive edges through clear auxiliary vector machines, taking advantage of statistical preparation. Neural networks are performed in emotion analysis to choose the inscription of names. To help extract information at the configuration level, restrictive conditions between multiple edges and focusing purposes behind the non-cyclic scheme in which Bayesian networks operate are used. By simplifying words and sentences, accurate information and learning can be obtained on social networks. At the root level of the word, symbolic information is used to generate negative and positive bits of information. Disaster reduction structures are used in the analysis of morale to achieve a precise level of accuracy in social media information. [5]
2) Sentiment Analysis as multidisciplinary Field: Sentiment analysis is an interdisciplinary field where it combines different domains, for example, computational acoustics, information retrieval, semantics, basic language management, artificial twisting and AI [6]. Perceptions of moral analysis should be classified into three levels of extraction. A) characteristic or level side, b) document level, and c) sentence level [5].
3) Techniques for Sentiment Analysis: Sentiment analysis depends on two sorts of systems, i.e., vocabulary based and AI based procedures [5].
a) Machine learning based techniques: This type of system is recognized by emptying sentences and sight levels. Highlights include names of voice fragments (POS), n-gram, bi-grams, uni-gram and word bags. Artificial vision has three flavors in prayer and border, namely Nave Bayes, Vector Vector (SVM) and Maximum Entropy.
b) Lexicon based or corpus based techniques: These systems are based on selection trees, for example, the nearest neighbors (k-NN), conditional random field (CRF), hidden Markov model (HMM), one-dimensional classification (SDC) and minimum sequential improvement (SMO), defined by techniques to classify feelings. The reproduced knowledge curriculum has three classifications: 2) semi-coordinated and 3) free. This system is suitable for robots and can handle the wide variety of information and, therefore, is reasonable for analyzing emotions.
B. Deep learning
Deep learning from the beginning was proposed by G.E. Hinton in 2006 is part of the artificial intelligence framework that proposes a deep neural network [7]. The neural network is affected by the human brain and contains a series of neurons that form an incredible network. Deep learning networks are well established in the hope of supervised and free classes [8]. Deep learning creates different networks, for example, CNN (convolution neural networks), RNN (recurrent neural networks), recursive neural networks, DBN (deep belief networks) and others. Neural networks are very useful in the age of the content, the identification of vectors, the estimation of the word plot, the classification of sentences, the appearance of sentences and highlighting the introduction. [9]
151 improvement of programming construction, strengthened
learning frameworks, transparency of power knowledge and data planning [11]. They are mixed by neuroscience and have a surprising effect on the level of affiliations such as speech confirmation, NLP (natural language processing) and PC vision. One of the key issues for the evaluation of deep learning is a framework for learning the structure of the model, the grade of classes and the degree of verification segments for each layer [12]. As the learning boundaries are organized, the flow of deep learning shows the most critical inspiration movements and requires zigzag models in their entirety to obtain data by deep measurement. Deep learning networks and frameworks have been implemented in all areas considered in different areas, for example, in visual categorization, individually when walking, robot cycle of the abusive scene, object categories, standard sound tasks and test tasks. time approximation [13]. An influential understanding framework, such as language supervision, has studied that it is surprising to perform different tasks, for example, the semantic alias can work spectacularly with deep designs [13]. In terms of data, deep learning is committed to changing the reflections of the basic level through the exploitation of particular level structures. It is a promising framework that has been widely applied in modern thinking, such as PC vision, learning on the fly, linguistic analysis, standard language preparation and more. At present, deep education is flourishing due to three main reasons: better purposes to restrict chip monitoring (GPU) and all that is considered less hardware use and important updates in AI estimates. [14]
C. Combining Sentiment Analysis and Deep Learning Deep learning is incredibly important both in implementation and in empowered learning, and different specialists organize the analysis of morals through deep learning. It joins profitable fluctuations and does not exist if you obtain models, models, or models and use these models to address an appropriate problem scheme [15]. The most popular model used by Socher was the Recursive Neural Network (RNN) to film film surveys of rottentomatoes.com [16]. Through the follow-up effort [17], different examiners performed the classification of morale using neural networks. For example, Kalchbrenner [18] predicts the presence of DyCNN (Dynamic convolutional neural network) that uses progressive aggregation, that is, k-max dynamic aggregation on direct roads. Kim [19] uses CNN to learn vectors of sentences that convey emotions. In addition, Mikulov, vector paragraph, et al. [20] that performs a better analysis of morality in the word packet model and ConvNets to learn SSWE (Expression of Expression of Expression of Words). Lately [21] applied ConvNets to characters instead of a real application to word decorations. Another piece of emotion classification is LSTM, which can essentially take a sequence in a single data direction. In this article, the second section covers the review of the deceleration process, the third section shows the end and the fourth section shows that when ordering the analysis some data were obtained on how to arrive at a truly productive study. In the area of literature review, several evaluations of emotional analysis using deep learning procedures are discussed. This review is based on the latest characteristic tests in the field of emotional analysis.
2. RELATED WORK
152 slants. Word vectors before planning were correspondingly
used with CNN in sentence delineation [13] and Twitter moral evaluation [14]. There are a few conclusions of evaluation perspectives. In 2013, Wunnasri et al. Propose a philosophy subject to k Neighbor (kNN) to explain the information of conflicting suppositions on Twitter [15]. Not long after, Chirawichitchai found that SVM kNN, NB and Decision Tree butchers in the delineation of suppositions [16]. Furthermore, in 2015, SRK et al. The tilt information is tended to from the notes on YouTube using SVM, NB and the objectives tree [17]. In any case, most by a wide edge of the material, by a wide edge, get little information about the usage of the word pack model.
3. METHODOLOGY
In this idea, we present the fundamental bits of our structure. Furthermore, your tweets are encountering preprocessing and cleaning, to empty pictures and tokens. By then, the tweets are set up to be set up for the organized stage. We train two models for significant learning, CNN and LSTM. By working really to shape to set up the two models with different hyperlinks, we select the two best models that achieve the most raised score of Formula One and make a band model. We use the social issue model to envision late conclusions from near to tweets.
3.1. Data Pre processing and cleaning At this stage, we clean the tweets and change the photos obviously and unwanted. The objective of this stage is to develop the extent of words whose embellishments can be found in the Word Show structure made in advance.
The housings we are up 'til now planning to clean the Arab tweets have all the earmarks of being:
• Remove dates, times, numbers (English and Arabic), URL and fundamental Twitter pictures, for example, RT (re-tweet) and @ (see screen catch). • Replace the emojis 2 found in Tweets with emojis3,
since the word show format doesn't contain an image of emojis. To achieve everything that was considered, we made a blueprint to dole out known emojis to the pictures related to them. In this sense, don't lose the sentiments experienced by those emojis.
• Express the pictures by putting spaces between them, with the objective that each verbalization can see its own special unique wonder in the word depiction model. This helps when a social issue of pictures appears, without spaces, in a tweet, while this mix unequivocally won't have a recognizable word.
• Eliminate Arabic diacritics
• Normalize clear words and tunnel bothering enhancements and pictures
• Eliminate expanding and abuse a solitary event.
3.2. Data Preparation
3.2.1. Tweets Representation
Each tweet barges in with a lot of enunciations of variable length. In the data identified with the requesting, we dislodge each word in the tweet with the proper word entered by the past show transmitted in the delineation of
the word. We utilize the word AraVec [28] that has been starting late referenced in Twitter data following the methodology of Word2vec [18]. Each tweet is slanted by a two-dimensional vector of x d. Where is the length of the words in the tweet and the overviewed length of the vector picture of the word? We utilize the Ara Vec gram preclusion model to assess 300. For instance = 300. To guarantee that the all out tweets are of a fixed size, we search for them in the wake of drawing nearer [7], coding the course of action of each tweet by zeros . In this sense, each tweet will have the size of S, so we decide to be 40.
3.2.2. Handling unknown words
When overriding tweet words with vector pictures, two or three words won't show any issue in the shortcoming. There are various responses to this issue, either to slaughter the word or to orchestrate its vector with dissipated properties. For a practically identical explanation, it will when all is said in done be changed according to a customary word examinations <UNK>, paying little character to this will give all of you the words and the decay of all impacts can be disengaged picture vectors. As goal, we are searching for an elective system connected by Quick Text [6], to spend weddings on missing words. We separate 3 grams of word cutoff and mission for every gram in the word area structure. By at that point, we gain the limit with the standard subject of the gram found. This standard is utilized to tear the closeness of the word stroke. On the off chance that it is never wide for any of the 3 grams of the word, we attempt with 4 grams, etc, until we discover the word in the closer view or land along the dim word. In the last case, we destroy the word from Tweets.
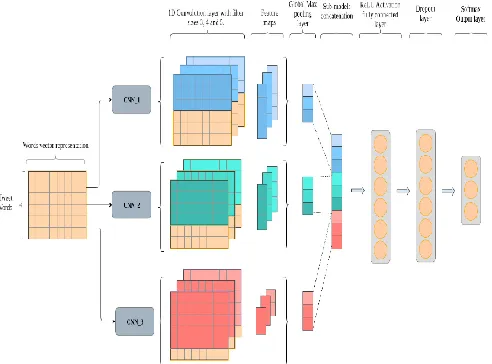
3.3. CNN Model
153 first passed to all LSTMs; Each LSTM has a declared size.
The last execution of each LSTM is associated with a vector execution of 2 h long. This vector is then passed to a layer that is totally associated with the ReLU choice work. The spillage layer is set up after the LSTM layer and the other spillage layer is set up not long after the related layer. At last, a softmax layer is added to give a class of articulations of adoration for a tweet. Figure 2 shows a low LSTM type.
Fig. 1: CNN model design. In this simplified design, a tweet consists of 6 words and an insert word that contains element 8. It uses three channel sizes 3, 4 and 5 with 3
different channels for each channel size.
4. EXPERIMENTS AND EVALUATION
In this paper, we show the academic beginners. We change the silly parameters used in the two models and pick the exactness and level of F1. We use an ASTD educational record [20], which contains 10,000 tweets, disengaged into 4 classes (positive, negative, reasonable and objective). We look at the structure [4] by taking tweets from express sections of our choice to consider our results. The tweets in the target region were flushed considering the course by which the scattering is unequivocally made in the evaluation corridor, and it is reliably key to focus on the limit score rather than the character rating. This number has made 3,315 tweets with authentically adjusted degree scattering (24% positive, 51% negative and 25% reasonable). The educational record was a tremendous measure of 70%, 10% and 20% self-coordinating control, solicitation and test contraptions. We furthermore use a close to hash rate like [4] to make a reasonable appraisal with it. The evaluation system occurs in the test gathering. 6Maha Heikal et al. /Procedure Computer Science 00 (2018) 000–000 pictures. 2: Master cerebrum of the LSTM model. In this model, the size of the LSTM guaranteed status is 3.4.1. CNN model evaluations We consider the ludicrous parameter used in the default plan [7]. In each assessment, we change the techniques of respect for ludicrous parameters, keeping up different static plans, for instance, the default plan. The default CNN default parameters are recorded in Table 1. Table 1: The structure of the default CNN model. Hyperparameter regard Filter size s [3, 4, 5] Number of channels 200 Number of units in a totally related layer 30
Interrupt rate 0.5 Learning rate 00101 Number of periods 10 Lot size 504.2. Delayed consequences of the CNN model The CNN model that achieves the best result is a model that uses a totally related layer of 100 layers, while the different parameters are held as the default graph. Goals and F1 show the result in Table 2.
Fig.2: LSTM model architecture. the LSTM hidden state size is 3.
4.1CNN Model Experiments
We consider the excessive parameter used in [7] the default plan. In each test, we convert one of the superparameter parameters while maintaining different routes so that they function stably. The default CNN parameters are recorded in Table 1.
Table 1: CNN model configuration
4.2. CNN Model Results
The best result of the CNN model is a model that uses a layer that is completely linked to size 100, while several parameters are retained as the default route to work. The accuracy and F1 score are shown in Table 2.
154 Table 3: Confusion Matrix for CNN model.
4.3. LSTM Model Experiments
We use the LSTM configuration described in [7], which is recorded in Table 4. We change each consideration of the excessive parameter freely and determine the accuracy and F1 score.
Table 4: LSTM model parameters
4.4. LSTM Model results
The best results for the LSTM model are developed using the leakage frequency of 0.2, while retaining various parameters such as the default plan. The result is shown in Table 5.
Table 5: LSTM model results.
Table 6: Confusion Matrix of LSTM model.
5. CONCLUSION
In this paper, we apply deep learning procedures to our tweets to disconnect your feelings. However, we conducted the analysis to find the best LSTM and DCNN standards. By then, we show that the best classifier is DCNN, behind LSTM. Both frames give a higher correction than the previous procedures, for example, NB and SVM, but not Max Ent. Finally, we investigate the sentences with a balanced word to show that the word path affects the emotional analysis in Twitter data. Despite our evaluation, there is another area to use deep learning methods. Many ordered vector words of the classification structure can be used in several areas of semantic search. For future work, we recognize that precision can be revived by improving the process of designating parts and the convolutional process.
REFERENCES
[1]. A. V. Yeole, P. V. Chavan, and M. C. Nikose, Opinion mining for emotions determination, ICIIECS 2015 - 2015 IEEE Int. Conf. Innov. Information, Embed. Commun. Syst., 2015
[2]. B. Heredia, T. M. Khoshgoftaar, J. Prusa, and M. Crawford, CrossDomain Sentiment Analysis: An Empirical Investigation, 2016 IEEE 17th Int. Conf. Inf. Reuse Integr., pp. 160165, 2016.
[3]. F. Luo, C. Li, and Z. Cao, Affective-feature-based sentiment analysis using SVM classifier, 2016 IEEE 20th Int. Conf. Comput. Support. Coop. Work Des., pp. 276281, 2016.
[4]. M. Haenlein and A. M. Kaplan, An empirical analysis of attitudinal and behavioral reactions toward the abandonment of unprofitable customer relationships, J. Relatsh. Mark., vol. 9, no. 4, pp. 200228, 2010. [5]. J. Singh, G. Singh, and R. Singh, A review of
sentiment analysis techniques for opinionated web text, CSI Trans. ICT, 2016.
[6]. E. Aydogan and M. A. Akcayol, A comprehensive survey for sentiment analysis tasks using machine learning techniques, 2016 Int. Symp. Innov. Intell. Syst. Appl., pp. 17, 2016.
[7]. M. Day and C. Lee, Deep Learning for Financial Sentiment Analysis on Finance News Providers, no. 1, pp. 11271134, 2016.
[8]. P. Vateekul and T. Koomsubha, A Study of Sentiment Analysis Using Deep Learning Techniques on Twitter Data, 2016.
[9]. Y. Zhang, M. J. Er, N. Wang, M. Pratama, and R. Venkatesan, Sentiment Classification Using Comprehensive Attention Recurrent Models, pp. 15621569, 2016.
[10]. S. Zhou, Q. Chen, and X. Wang, Active deep learning method for semi-supervised sentiment classification, Neurocomputing, vol. 120, pp. 536546, 2013.
[11]. L. Deng, G. Hinton, and B. Kingsbury, New types of deep neural network learning for speech recognition and related applications: an overview, 2013 IEEE Int. Conf. Acoust. Speech Signal Process, pp. 85998603, 2013.
[12]. S. Bengio, L. Deng, H. Larochelle, H. Lee, and R. Salakhutdinov, Guest Editors Introduction: Special Section on Learning Deep Architectures, IEEE Trans. Pattern Anal. Mach. Intell., vol. 35, no. 8, pp. 17951797, 2013.
[13]. L. Arnold, S. Rebecchi, S. Chevallier, and H. Paugam-Moisy, An Introduction to Deep Learning, Esann, no. April, p. 12, 2011.
[14]. Y. Guo, Y. Liu, A. Oerlemans, S. Lao, S. Wu, and M. S. Lew, Deep learning for visual understanding: A review, Neurocomputing, vol. 187, pp. 2748, 2016. [15]. X. Ouyang, P. Zhou, C. H. Li, and L. Liu, Sentiment
Analysis Using Convolutional Neural Network, Comput. Inf. Technol. Ubiquitous Comput. Commun. Dependable, Auton. Secure. Comput. Pervasive Intell. Comput. (CIT/IUCC/DASC/PICOM), 2015 IEEE Int. Conf., pp. 23592364, 2015.
155 [17]. T. Mikolov, K. Chen, G. Corrado, and J. Dean,
Efficient Estimation of Word Representations in Vector Space, Arxiv, no. 9, pp. 112, 2013.
[18]. N. Kalchbrenner, E. Grefenstette, and P. Blunsom, A Convolutional Neural Network for Modelling Sentences, Acl, pp. 655665, 2014.