Toward General-Purpose Learning for Information Extraction
Dayne Freitag
School of C o m p u t e r Science Carnegie Mellon University P i t t s b u r g h , PA 15213, USA
d a y n e © c s , crau. edu
A b s t r a c t
Two trends are evident in the recent evolution of the field of information extraction: a preference for simple, often corpus-driven techniques over linguistically sophisticated ones; and a broaden- ing of the central problem definition to include many non-traditional text domains. This devel- opment calls for information extraction systems which are as
retctrgetable
andgeneral
as possi- ble. Here, we describe SRV, a learning archi- tecture for information extraction which is de- signed for maximum generality and flexibility. SRV can exploit domain-specific information, including linguistic syntax and lexical informa- tion, in the form of features provided to the sys- tem explicitly as input for training. This pro- cess is illustrated using a domain created from Reuters corporate acquisitions articles. Fea- tures are derived from two general-purpose NLP systems, Sleator and Temperly's link grammar parser and Wordnet. Experiments compare the learner's performance with and without such linguistic information. Surprisingly, in many cases, the system performs as well without this information as with it.1 I n t r o d u c t i o n
The field of
information extraction
(IE) is con- cerned with using natural language processing (NLP) to extract essential details from text doc- uments automatically. While the problems of retrieval, routing, and filtering have received considerable attention through the years, IE is only now coming into its own as an information management sub-discipline.Progress in the field of IE has been away from general NLP systems, that must be tuned to work ill a particular domain, toward faster sys- tems that perform less linguistic processing of documents and can be more readily targeted at
novel domains (e.g., (Appelt et al., 1993)). A natural part of this development has been the introduction of machine learning techniques to facilitate the domain engineering effort (Riloff, 1996; Soderland and Lehnert, 1994).
Several researchers have reported IE systems which use machine learning at their core (Soder- land, 1996; Califf and Mooney, 1997). Rather than spend human effort tuning a system for an IE domain, it becomes possible to conceive of
training
it on a document sample. Aside fromthe obvious savings in human development ef- fort, this has significant implications for infor- mation extraction as a discipline:
Retargetability
Moving to a novel domainshould no longer be a question of code mod- ification; at most some feature engineering should be required.
G e n e r a l i t y It should be possible to handle a much wider range of domains than previ- ously. In addition to domains characterized by grammatical prose, we should be able to perform information extraction in domains involving less traditional structure, such as netnews articles and Web pages.
2 S R V
In order to be suitable for the widest possible variety of textual domains, including collections made up of informal E-mail messages, World Wide Web pages, or netnews posts, a learner must avoid any assumptions about the struc- ture of documents t h a t might be invalidated by new domains. It is not safe to assume, for ex- ample, t h a t text will be grammatical, or t h a t all tokens encountered will have entries in a lexicon available to the system. Fundamentally, a doc- ument is simply a sequence of terms. Beyond this, it becomes difficult to make assumptions t h a t are not violated by some common and im- portant domain of interest.
At the same time, however, when structural assumptions are justified, they may be criti- cal to the success of the system. It should be possible, therefore, to make structural informa- tion available to the learner as input for train- ing. The machine learning method with which we experiment here, SRV, was designed with these considerations in mind. In experiments re- ported elsewhere, we have applied SRV to collec- tions of electronic seminar announcements and World Wide Web pages (Freitag, 1998). Read- ers interested in a more thorough description of SRV are referred to (Freitag, 1998). Here, we list its most salient characteristics:
• L a c k o f s t r u c t u r a l a s s u m p t i o n s . SRV assumes nothing about the structure of a field instance 1 or the text in which it is e m b e d d e d - - o n l y t h a t an instance is an un- broken fragment of text. During learning and prediction, SRV inspects every frag- ment of appropriate size.
• T o k e n - o r i e n t e d f e a t u r e s . Learning is guided by a feature set which is separate from the core algorithm. Features de- scribe aspects of individual tokens, such as
capitalized, numeric, noun. Rules can posit
feature values for individual tokens, or for all tokens in a fragment, and can constrain the ordering and positioning of tokens.
• R e l a t i o n a l f e a t u r e s . SRV also includes
1We use the t e r m s field a n d field instance for t h e r a t h e r generic IE c o n c e p t s of slot a n d slot filler. For a n e w s w i r e article a b o u t a c o r p o r a t e acquisition, for e x a m - ple, a field i n s t a n c e m i g h t b e the t e x t f r a g m e n t listing t h e a m o u n t p a i d as p a r t of t h e deal.
a notion of relational features, such as next-token, which map a given token to an- other token in its environment. SRV uses such features to explore the context of frag- ments under investigation.
• T o p - d o w n g r e e d y r u l e s e a r c h . SRV constructs rules from general to specific, as in FOIL (Quinlan, 1990). Top-down search is more sensitive to patterns in the data, and less dependent on heuristics, than the b o t t o m - u p search used by sim- ilar systems (Soderland, 1996; Califf and Mooney, 1997).
• R u l e v a l i d a t i o n . Training is followed by validation, in which individual rules are tested on a reserved portion of the train- ing documents. Statistics collected in this way are used to associate a confidence with each prediction, which are used to manip- ulate the accuracy-coverage trade-off.
3 C a s e S t u d y
SRV's default feature set, designed for informal domains where parsing is difficult, includes no features more sophisticated than those immedi- ately computable from a cursory inspection of tokens. The experiments described here were an exercise in the design of features to capture syntactic and lexical information.
3.1 D o m a i n
As part of these experiments we defined an in- formation extraction problem using a publicly available corpus. 600 articles were sampled from the "acquisition" set in the Reuters corpus (Lewis, 1992) and tagged to identify instances of nine fields. Fields include those for the official names of the parties to an acquisition (acquired,
purchaser,
seller), as well as their short names (acqabr, purchabr, sellerabr), the location of the purchased c o m p a n y or resource (acqloc), the price paid (dlramt), and any short phrases sum- marizing the progress of negotiations (status).The fields vary widely in length and frequency of occurrence, both of which have a significant impact on the difficulty t h e y present for learn- ers.
3.2 F e a t u r e Set D e s i g n
.---,---.---,---.--,,-+-Ce-+Ss*b+
I I I I I I
First Wisconsin Corp said.v it plans.v ...
token." Corp I [token: soi 1 I oken: it I Ilg_tag: nil | / l g _ t a g : "v" / | l g _ t a g : n i l /
~left_G / I ~left_S / I l\left C / I
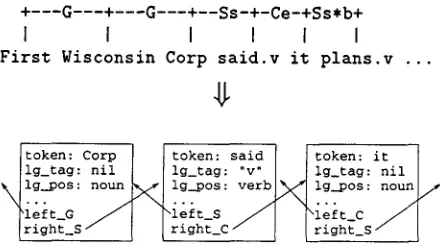
Figure 1: An example of link g r a m m a r feature derivation.
NLP tools, the link g r a m m a r parser and Word- net.
The link g r a m m a r parser takes a sentence as input and returns a complete parse in which terms are connected in typed binary relations ("links") which represent syntactic relationships (Sleator and Temperley, 1993). We mapped these links to relational features: A token on the right side of a link of type X has a cor- responding relational feature called left_)/ t h a t maps to the token on the left side of the link. In addition, several non-relational features, such as part of speech, are derived from parser output. Figure 1 shows part of a link g r a m m a r parse and its translation into features.
Our object in using Wordnet (Miller, 1995) is to enable 5RV to recognize t h a t the phrases, "A bought B," and, "X acquired Y," are in- stantiations of the same underlying pattern. Al- though "bought" and "acquired" do not belong to the same "synset" in Wordnet, they are nev- ertheless closely related in Wordnet by means of the "hypernym" (or "is-a') relation. To ex- ploit such semantic relationships we created a single token feature, called wn_word. In con- trast with features already outlined, which are mostly boolean, this feature is set-valued. For nouns and verbs, its value is a set of identifiers representing all synsets in the h y p e r n y m path to the root of the h y p e r n y m tree in which a word occurs. For adjectives and adverbs, these synset identifiers were drawn from the cluster of closely related synsets. In the case of multiple Word- net senses, we used the most common sense of a word, according to Wordnet, to construct this set.
3.3 C o m p e t i n g L e a r n e r s
\¥e compare the performance of 5RV with t h a t of two simple learning approaches, which make predictions based on raw term statistics. Rote (see (Freitag, 1998)), memorizes field instances seen during training and only makes predic- tions when the same fragments are encountered in novel documents. Bayes is a statistical ap- proach based on the "Naive Bayes" algorithm (Mitchell, 1997). Our implementation is de- scribed in (Freitag, 1997). Note t h a t although these learners are "simple," they are not neces- sarily ineffective. We have experimented with them in several domains and have been sur- prised by their level of performance in some cases.
4 R e s u l t s
The results presented here represent average performances over several separate experiments. In each experiment, the 600 documents in the collection were randomly partitioned into two sets of 300 documents each. One of the two subsets was then used to train each of the learn- ers, the other to measure the performance of the learned extractors.
\¥e compared four learners: each of the two simple learners, Bayes and Rote, and SRV with two different feature sets, its default feature set, which contains no "sophisticated" features, and the default set augmented with the features de- rived from the link g r a m m a r parser and Word- net. \¥e will refer to the latter as 5RV+ling.
Results are reported in terms of two metrics closely related to precision and recall, as seen in information retrievah Accuracy, the percentage of documents for which a learner predicted cor- rectly (extracted the field in question) over all documents for which the learner predicted; and coverage, the percentage of documents having the field in question for which a learner made some prediction.
4.1 P e r f o r m a n c e
Table 1 shows the results of a ten-fold exper- iment comparing all four learners on all nine fields. Note t h a t accuracy and coverage must be considered together when comparing learn- ers. For example, Rote often achieves reasonable accuracy at very low coverage.
[image:3.612.76.296.82.208.2]Acc lCov
Alg a c q u i r e dRote 59.6 18.5
Bayes 19.8 100 SRV 38.4 96.6 SRVIng 3 8 . 0 95.6
acqabr
R o t e 16.1 42.5
Bayes 23.2 100
SRV 31.8 99.8
SRVlng 35.5 99.2
acqloc Rote 6.4 63.1
Bayes 7.0 100 SRV 12.7 83.7 SRVlng 15.4 80.2
Ace I V or
p u r c h a s e r
43.2 23.2 36.9 100 42.9 97.9 42.4 96.3 p u r c h a b r 3.6 41.9 39.6 100 41.4 99.6 43.2 99.3
status
42.0 94.5 33.3 100 39.1 89.8 41.5 87.9
Acc l Cov
seller 38.5 15.2 15.6 100 16.3 86.4 16.4 82.7 sellerabr 2.7 27.3 16.0 100 14.3 95.1 14.7 91.8 dlramt 63.2 48.5 24.1 100 50.5 91.0 52.1 89.4
T a b l e 1: A c c u r a c y a n d c o v e r a g e for all four l e a r n e r s on t h e acquisitions fields.
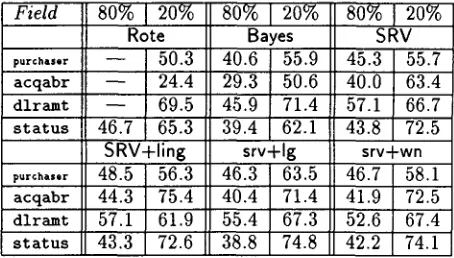
age levels, 20% a n d 80%, on f o u r fields which we c o n s i d e r e d r e p r e s e n t a t i v e of tile wide r a n g e of b e h a v i o r we o b s e r v e d . In a d d i t i o n , in o r d e r to assess t h e c o n t r i b u t i o n o f each kind of linguis- tic i n f o r m a t i o n ( s y n t a c t i c a n d lexical) t o 5RV's p e r f o r m a n c e , we ran e x p e r i m e n t s in which its basic f e a t u r e set was a u g m e n t e d with only one t y p e or t h e o t h e r .
4 . 2 D i s c u s s i o n
P e r h a p s surprisingly, b u t c o n s i s t e n t with results we have o b t a i n e d in o t h e r d o m a i n s , t h e r e is no one a l g o r i t h m which o u t p e r f o r m s t h e o t h e r s on all fields. R a t h e r t h a n t h e a b s o l u t e difficulty of a field, we s p e a k of t h e s u i t a b i l i t y of a l e a r n e r ' s inductive bias for a field (Mitchell, 1997). B a y e s
is clearly b e t t e r t h a n SRV on t h e seller and
s e l l e r a b r fields a t all p o i n t s on t h e a c c u r a c y - c o v e r a g e c u r v e . We s u s p e c t this m a y be due, in p a r t , to t h e relative i n f r e q u e n c y of t h e s e fields in t h e d a t a .
T h e o n e field for which t h e linguistic f e a t u r e s offer benefit a t all p o i n t s along t h e a c c u r a c y - c o v e r a g e c u r v e is acqabr. 2 We s u r m i s e t h a t two f a c t o r s c o n t r i b u t e to this success: a high fre- q u e n c y o f o c c u r r e n c e for this field (2.42 t i m e s
2The acqabr differences in Table 2 (a 3-split exper- iment) are not significant at the 95% confidence level. However, the full 10-split averages, with 95% error mar- gins, are: at 20% coverage, 61.5+4.4 for SRV and 68.5=1=4.2 for SRV-I-[ing; at 80% coverage, 37.1/=2.0 for SRV and 42.4+2.1 for SRV+ling.
Field 8 0 % [ 2 0 %
R o t e p.r0h .... .. - - ' 50.3 acqabr . . . . 24.4 dlramt . . . . 69.5
s t a t u s 46.7 65.3 SRV+ling
purch . . . . 48.5 56.3
acqabr 44.3 75.4 dlramt 57.1 61.9
s t a t u s 43.3 72.6
80%12o%
Bayes40.6 55.9 29.3 50.6 45.9 71.4 39.4 62.1
srv+lg 46.3 63.5 40.4 71.4 55.4 67.3 38.8 74.8
80%120%
SRV 45.3 55.7 40.0 63.4 57.1 66.7 43.8 72.5
srv- -wfl
46.7 58.1 41.9 72.5 52.6 67.4 42.2 74.1
T a b l e 2: A c c u r a c y f r o m a t h r e e - s p l i t e x p e r i m e n t at fixed c o v e r a g e levels.
A fragment is a a c q a b r , if: it contains exactly one token; the token (T) is capitalized; T is followed by a lower-case token; T is preceded by a lower-case token; T has a right AN-link to a token (U) with wn_word value "possession"; U is preceded by a token
with wn_word value "stock"; and the token two tokens before T
is not a two-character token.
to purchase 4.5 m l n ~ common shares at
acquire another 2.4 mln~-a6~treasury shares
F i g u r e 2: A learned rule for acqabr using linguis- tic f e a t u r e s , along with two f r a g m e n t s of m a t c h - ing t e x t . T h e AN-link c o n n e c t s a noun modifier to t h e n o u n it modifies (to "shares" in b o t h ex- a m p l e s ) .
per d o c u m e n t on a v e r a g e ) , a n d c o n s i s t e n t oc- c u r r e n c e in a linguistically rich c o n t e x t .
F i g u r e 2 shows a 5RV+ling rule t h a t is able to e x p l o i t b o t h t y p e s o f linguistic informa- tion. T h e W o r d n e t s y n s e t s for "possession" and " s t o c k " c o m e f r o m t h e s a m e b r a n c h in a hy- p e r n y m t r e e - - " p o s s e s s i o n " is a generalization o f " s t o c k " 3 - - a n d b o t h m a t c h t h e collocations " c o m m o n s h a r e s " a n d " t r e a s u r y shares." T h a t t h e p a t h s [right_AN] a n d [right_AN p r e v _ t o k ]
b o t h c o n n e c t t o t h e s a m e s y n s e t indicates t h e presence of a t w o - w o r d W o r d n e t collocation.
It is n a t u r a l t o ask w h y SRV+ling does not
[image:4.612.72.296.75.260.2] [image:4.612.311.538.77.206.2]outperform SRV more consistently. After all, the features available to SRV+ling are a superset of those available to SRV. As we see it, there are two basic explanations:
• N o i s e . Heuristic choices made in handling syntactically intractable sentences and in disambiguating Wordnet word senses in- troduced noise into the linguistic features. The combination of noisy features and a very flexible learner may have led to over- fitting that offset any advantages the lin- guistic features provided.
• C h e a p f e a t u r e s e q u a l l y e f f e c t i v e . The simple features may have provided most of the necessary information. For exam- ple, generalizing "acquired" and "bought" is only useful in the absence of enough data to form rules for each verb separately.
4.3 C o n c l u s i o n
More than similar systems, SRV satisfies the cri- teria of
generality
andretargetability.
The sep- aration of domain-specific information from the central algorithm, in the form of an extensible feature set, allows quick porting to novel do- mains.Here, we have sketched this porting process. Surprisingly, although there is preliminary evi- dence that general-purpose linguistic informa- tion can provide benefit in some cases, most of the extraction performance can be achieved with only the simplest of information.
Obviously, the learners described here are not intended to solve the information extraction problem outright, but to serve as a source of in- formation for a post-processing component that will reconcile all of the predictions for a docu- ment, hopefully filling whole templates more ac- curately than is possible with any single learner. How this might be accomplished is one theme of our future work in this area.
Acknowledgments
Part of this research was conducted as part of a summer internship at Just Research. And it was supported in part by the Darpa HPKB pro- gram under contract F30602-97-1-0215.
R e f e r e n c e s
Douglas E. Appelt, Jerry R. Hobbs, John Bear, David Israel, and Mabry Tyson. 1993. FAS-
TUS: a finite-state processor for information extraction from real-world text.
Proceedings
of IJCAI-93,
pages 1172-1178.M. E. Califf and R. J. Mooney. 1997. Relational learning of pattern-match rules for informa- tion extraction. In
Working Papers of ACL-
97 Workshop on Natural Language Learning.
D. Freitag. 1997. Using grammatical in- ference to improve precision in informa- tion extraction. In
Notes of the ICML-97
Workshop on Automata Induction, Gram-
matical Inference, and Language Acquisition.
h t t p : / / w w w . c s . c m u . e d u / f ) d u p o n t / m 1 9 7 p / m197_GI_wkshp.tar.
Dayne Freitag. 1998. Information extraction from HTML: Application of a general ma- chine learning approach. In
Proceedings of
the Fifteenth National Conference on Artifi-
cial Intelligence (AAAI-98).
D. Lewis. 1992.
Representation and Learning
in Information Retrieval.
Ph.D. thesis, Univ.of Massachusetts. CS Tech. Report 91-93. G.A. Miller. 1995. WordNet: A lexical
database for English.
Communications of the
ACM,
pages 39-41, November.Tom M. Mitchell. 1997.
Machine Learning.
The McGraw-Hilt Companies, Inc.
J. R. Quinlan. 1990. Learning logical def- initions from relations.
Machine Learning,
5(3):239-266.
E. Riloff. 1996. Automatically generating ex- traction patterns from untagged text. In
Proceedings of the Thirteenth National Con-
ference on Artificial Intelligence (AAAI-96),
pages 1044-1049.
Daniel Sleator and Davy Temperley. 1993. Parsing English with a link grammar.
Third
International Workshop on Parsing Tech-
nologies.
Stephen Soderland and Wendy Lehnert. 1994. Wrap-Up: a trainable discourse module for information extraction.
Journal of Artificial
Intelligence Research,
2:131-158.S. Soderland. 1996.