Available online: https://edupediapublications.org/journals/index.php/IJR/ P a g e | 1369
An Effective Method for Entity Resolution by Query Driven
Approach
B.V.N.Geethanjali & M.Sarada
PG Student, dept. of MCA, St. Ann’s College of Engineering & Technology, Chirala.
Assistant Professor, Dept. of MCA, St. Ann’s College of Engineering & Technology, Chirala.
ABSTRACT
This paper investigates "on-the-fly" information cleaning with regards to a client question. A novel Query-Driven Approach (QDA) is created that plays out a negligible number of cleaning steps that are just important to answer a given determination question accurately. The complete exact assessment of the proposed approach shows its noteworthy leverage as far as productivity over customary methods for question driven applications. The all encompassing trial sentiment of QDA exhibits imperative outcomes_ that is QDA is a considerable measure better when contrasted and regular ER procedures , especially much as the cross examine is very particular.
1. Introduction
Organizations and administrative associations around the globe distribute a colossal volume of information, which can be put away in various information sources. Keeping in mind the end goal to get to and break down
these information, systems for information
combination are required. The point of information incorporation is to consolidate heterogeneous and self-ruling information hotspots for giving a solitary view to the client . An imperative segment of the
information coordination process is the Entity Resolution (ER) undertaking .The ER objective is to distinguish alluding to the same real word element .This issue is known by an assortment of names: Record Linkage, Entity Resolution, Object Reference,
Reference Linkage, Duplicate Detection or
duplication. In this paper, we receive the term Entity Resolution (ER) .
Frequently, organizations and associations need to manage dynamic information sources with a substantial volume of information. In this specific circumstance, the ER procedure can be exceptionally testing on the grounds that most current accessible ER systems process every one of the substances at one time. This happens on the grounds that a large portion of these systems depend on bunch calculations, which settle all tuples as opposed to settling those identified with a solitary question . At that point, emerges the need of new procedures to help continuous ER for dynamic and extensive databases.
Available online: https://edupediapublications.org/journals/index.php/IJR/ P a g e | 1370
"Getoor"). To answer this inquiry, it isn't important to search for other creator's papers and to play out the ER thinking about the entire arrangement of papers. For this situation, it is smarter to concentrate on the tuples depicting just papers from the creator indicated in the question.
In this paper, we propose a Query-Driven and Incremental process for Entity Resolution (Quid). The Quid procedure considers question comes about on various information sources. It is an incremental procedure, i.e., for each new question result, Quid reuses the past ER bunch to answer future inquiries. In our approach, ER is considered as a grouping issue , in which each bunch compares of a solitary certifiable element. Amid the ER, the after effects of inquiries are examined, and each of the inquiry result is embedded incrementally in a bunch. Our answer holds a file, and performs incremental bunching, bringing about groups of tuples that allude to a similar true substance. Whatever is left of the paper is sorted out as takes after.
2. RELATED WORK
Element determination is a notable issue and it has gotten noteworthy consideration in the writing in the course of recent decades. An exhaustive diagram of the current work around there can be found in overviews. We characterize the ER methods into two classes as take after: Generic ER. A run of the mill ER cycle comprises of a few periods of information changes that include: standardization, blocking,
comparability calculation, grouping, and
consolidating, which can be intermixed.
In the standardization stage, the ER structure institutionalizes the information positions. The following stage is blocking which is a fundamental conventional system utilized for enhancing ER proficiency. Frequently blocking parcels records into basins or overhangs. From that point onward, in the likeness calculation stage, the ER structure utilizes a
purpose/closeness capacity to register the
comparability between the distinctive genuine substances. Customary techniques investigate the closeness of elements to decide whether they co-allud . As of late new methodologies misuse new data sources, for example, investigating setting, abusing
connections between elements, space/honesty
Available online: https://edupediapublications.org/journals/index.php/IJR/ P a g e | 1371
questions where the sort of the condition property isn't a string.
Despite the fact that the ER system in is likewise "on-the-fly", it tackles an alternate issue since it settle
inquiries under information vulnerability by
interfacing thoughts of record linkage and probabilistic databases. The term inquiry alludes to a mix of (quality name/esteem) sets and every element returned as an answer is joined by a likelihood that this substance will be chosen among every single conceivable world.
The creators handle element vulnerability at query time for OLAP applications. Not at all like our own, this work accept the presence of a record-to-bunch mapping table and its objective is to answer assemble by OLAP questions by returning outcomes as strict extents.
Note that the methodologies can't answer non specific determination questions like: select just very much reference to (e.g., with reference tally over 45) papers composed by 'J. Smith' – which is the essential concentration of our paper. That is, none of the current arrangements consider improving non specific SQL choice inquiries examined in our paper.
Bhattacharya and Getoor proposed a system balanced for question time element determination by distinguishing and settling just those database references that are the most accommodating for preparing a given inquiry. Altwaijry proposed an inquiry driven way to deal with ER, misusing the specificity and semantics of the given SQL question.
The two papers don't propose to reuse past aftereffects of the ER procedure. The arrangement proposed by Gruenheid utilizes an incremental grouping calculation to perform ER. Each embedded tuple is contrasted and existing bunches, either putting the tuple into a current group, or making another bunch for it, utilizing additional data from the information updates to settle past group issues. This arrangement does not consider question comes about amid the ER errand. Not quite the same as the said approaches, the procedure proposed in this paper is incremental and inquiry driven. To the best of our insight there are no different methodologies that consolidate these two highlights.
3. PROBLEM STATEMENTS
In this segment we formally characterize the issue of inquiry driven and incremental ER (Section 3.1). We at that point portray our Query-Driven and Incremental process for Entity Resolution (Quid) (Section 3.2).
3.1 Problem Definition
Available online: https://edupediapublications.org/journals/index.php/IJR/ P a g e | 1372
volume of tuples. This system will likewise diminish the quantity of examinations made between tuples.
Formally, we denote S = {S1, S2, ..., SN} a set of data sources and Q = {Q1, Q2, ..., QM} a set of queries running on S. Each source has a set of entities Si .E, where E = {E1, E2, ..., EW}. Each entity EJ from Si .E has a set of triples Si .EJ.T = {t1, t2, ..., tn}, where each tp is an instance of the entity EJ . A triple tr is defined as follows.
Definition 1: Each triple tr belonging to Si .Ej .T, is represented by a set of pairs of attributes (Ak) and values (Vk), tp= {(Si,Ej,A1,v1),( Si,Ej,A2,v2), …, (Si ,EJ ,An ,Vn)}. Each attribute Ak belongs to an entity (EJ ) of a data source (Si ), denoted by Si EJ ,Ak. Each triple tr has a pair (SI ,EJ, Ak, Vk), which represents a single identifier of the tuple (Id).
An inquiry QI may not contain every one of the qualities essential (important) to characterize whether two tuples speak to a similar genuine element. In this manner, the question is submitted to an extension procedure for gathering the pertinent qualities [8] that were not educated in the underlying inquiry. This extension produces an inquiry QI '. The contribution of the Quid procedure is the consequence of the inquiry QI ', characterized as follows.
Definition 2: A query result, QI ’.R, is represented by a set of tuples (Definition 1) that belongs to an entity EJ. The attributes that describes the triples of the result QI.R includes the set of relevant attributes (AR ), Si,
EJ, AR , where Si ,EJ, AR ⊆ Si, EJ, AR. For each new
received query result, the ER process reuses the results
of previous ER tasks, i.e., previous generated clusters, to respond the query.
3.2 Quid
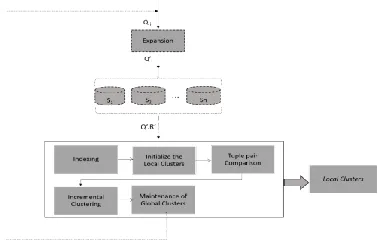
In this area, we portray the proposed procedure (Quid). Fig. 1 demonstrates the stream of data in Quid. The contribution of the procedure is an inquiry result (QI’ .R'). The procedure begins with the Indexing step, which expects to lessen the quantity of examinations between sets of tuples. Amid this progression, two lists are utilized: the Similarity Index and the Cluster Index. The first keeps up incrementally the closeness esteems between each combine of tuples. The second one keeps up incrementally arrangement of bunches of tuples identifiers.
Fig. 1. Proposed process (Quid)
Our approach, utilizes two sorts of bunches: worldwide groups and neighborhood bunches. Worldwide Clusters (GC) are made just once and refreshed, incrementally, at each inquiry resultQI '.R'. A GC offers support to the inquiry driven process reusing past outcomes in future questions. A
worldwide group is characterized in the
Available online: https://edupediapublications.org/journals/index.php/IJR/ P a g e | 1373
Definition 3: A Global Cluster (GC) is defined by a set of triples, GC={(Cluster Id, Si .Ej, Si .Ej. tp. Id)},
where Cluster is an identifier of the cluster, Si. Ej is the entity and the data source of the triple tp and Si. Ej. tp. Id is the triple identifier.
Local Clusters (LC) are created for each query result
QI ’.R’. The output of the ER process is the Cc
containing the duplicated tuples detected in the query result. LC will use previously classified information
from the global cluster GC. We define local cluster as
follows.
Definition 4: A Local Cluster (LC) is defined by a set of pairs, LC={(Si.Ej.tk, Cluster)}, where Si.Ej.tk is a
triple and Cluster is the identifier of the cluster which the tuple belongs to.
After the Indexing step, the nearby group (LC) is instated from GC, reusing the aftereffects of past ER assignments. After the introduction of LC triples not prepared already will be handled the amid the Triple Pair Comparison step. In this progression, similitude esteems are recouped from the Similarity Index, or new closeness esteems between two tuples are computed.
After the Tuple Pair Comparison stage, the following stage is the Incremental Clustering. The contribution of this errand is a closeness diagram, where hubs are tuples, and similitude esteems between tuples are edges. The objective of the Incremental Clustering is to embed into the nearby bunch (LC) and worldwide group (GC) the triples not handled some time recently. At last, after the Incremental Clustering, the yield of
Quid is Lc and GC as of now refreshed for reuse in the following ER assignments.
4. CONCLUSION
In this paper, we presented and propelled an incremental and inquiry driven Entity Resolution process, indicated Quid. We likewise exhibited the fundamental parts of Quid and some critical definitions identified with our proposition. In the present condition of our work, we actualized the two proposed lists (group file and likeness list). Right now, we are examining and assessing the effect of the incremental bunching calculation [3, 4] with regards to the proposed procedure. As future work, we will instantiate and assess the entire procedure.
REFERENCES
[1] Lenzerini, M. Ontology-based Data
Management. In: international conference on Information and knowledge management (CIKM’11). New York, NY, USA, pp. 5-6, 2011.
[2] Christen, P. Data Matching: Concepts and
Techniques for Record Linkage, Entity Resolution, and Duplicate Detection. Springer. 2012.
[3] Gruenheid, A.; Dong, X. L.; Srivastava, D.
Incremental Record Linkage. In: VLDB’2014. Hangzhou, China. 2014.
[4] Bhattacharya, I., Getoor, L. Query-time Entity
Resolution. Journal of Artificial Intelligence Research. 2007.
[5] Altwaijry H., Kalashnikov, D. D., Mehrotra,
Available online: https://edupediapublications.org/journals/index.php/IJR/ P a g e | 1374
[6] Su, W, Wang, J., Lochovsky, F, H. Record
Matching Over Query Results from Multiple Web Databases. IEEE Transactions on Knowledge and Data Engineering. Vol. 22, No. 4. 2010.
[7] 7. Berkhin, P.A Survey of Clustering Data
Mining Techniques. Grouping Multidimensional Data: Recent Advances in Clustering. Pp 25 – 71. Springer Berlin Heidelberg. 2006.
[8] Wang, S. E.; Marmaros, D.; Garcia-Molina, H.
Pay-As-You-Go Entity Resolution. In: IEEE Transactions on Knowledge and Data Engineering. Volume 25 Issue 5. 2013.
[9] 9] Z. Chen, D. V. Kalashnikov, and S.
Mehrotra. Exploiting context analysis for combining multiple entity resolution systems. In SIGMOD, pp. 207–218, 2009.
[10] [10] M. Hernandez and S. Stolfo. The
merge/purge problem for large databases. In SIGMOD, pp. 127–138, 1995.
[11] [11] X. Dong, A. Halevy, and J. Madhavan.
Reference reconciliation in complex information spaces. In SIGMOD, pp. 85–96, 2005.
[12] [12] E. Elmacioglu, M.-Y. Kan, D. Lee, and
Y. Zhang. Web based linkage. In WIDM, pp. 121– 128, 2007.
[13] [13] A. Elmagarmid, P. Ipeirotis, and V.
Verities. Duplicate record detection: A survey. In KDE, pp. 1-16, 2007.
[14] [14] W. Fan, X. Jia, J. Lo, and S. Ma.
Reasoning about record matching rules. In VLDB, pp. 407-418, 2009.
[15] [15] I. P. Fellegi and A. B. Sunter. A theory for record linkage. In JASA, pp. 1183-1210, 1969.
[16] [16] E. Ioannou, W. Nejdl, C. Nieder´ee, and
Y. Velegrakis. On-the-fly entity-aware query processing in the presence of linkage. In VLDB End., pp. 429–438, 2010.