International Journal in Commerce, IT and Social Sciences
Volume 5 Issue 07, July 2018 ISSN: 2394-5702 Impact Factor: 4.218
Journal Homepage: http://ijmr.net.in, Email: [email protected] Double-Blind Peer Reviewed Refereed Open Access International Journal
84
International Journal in Commerce, IT and Social Sciences http://ijmr.net.in, Email: [email protected] WEB MINING TECHNIQUES PERFORMANCE IN KNOWLEDGE DISCOVERY ANDDATA MINING: A STUDY
KodukulaSubrahmanyam1, Dr. Rashi Agarwal2 Department of Computer Science
1,2
Shri Venkateshwara University, Gajraula (Uttar Pradesh)
Abstract
This paper discussed the web mining techniques performance in knowledge discovery and data mining.Web mining is the procedure that helps clients find valuable information from the rich data on the World Wide Web. Numerous applications, for example, showcase analysis and business the executives, can profit by the utilization of the information and knowledge separated from a lot of data. Knowledge discovery can be seen as the process of nontrivial extraction of information from enormous databases, information that is verifiably displayed in the data, beforehand obscure and possibly helpful for clients. Data mining is hence a fundamental advance in the process of knowledge discovery in databases.Knowledge discovery alludes to the general process of discovering helpful knowledge from data, while data mining alludes to the extraction of examples from data. This research gives a sensibly far-reaching survey of knowledge discovery and its related data mining techniques.
1. OVERVIEW
In the previous decade, a critical number of data mining techniques have been displayed to perform diverse knowledge errands. These techniques incorporate affiliation principle mining, visit item set mining, successive example mining, most extreme example mining and shut example mining. The vast majority of them are proposed to create effective mining calculations to discover specific examples inside a sensible and adequate period. With countless examples created by utilizing the data mining approaches, how to viably misuse these examples is as yet an open research issue. The World Wide Web gives rich information on an amazingly enormous measure of connected Web pages. Such a store contains content data as well as multimedia objects, for example, pictures sound, and video cuts. Data mining on the World Wide Web can be alluded to as Web mining, which has increased much consideration with the fast development in the measure of information accessible on the internet.
Data mining and relative data preparing are directed by creating intelligent tools[1]. The performance of the calculations utilized in our philosophy is exhibited with the bunched activity postings dataset and grouped employment searchers dataset by utilizing the three estimates exactness, review and accuracy for the clustering calculation and the mistake of arrangement for the characterization procedure. The outcomes demonstrate that our proposed methodology of mix winds up with great outcomes in Knowledge Discovery from the web.
Web mining is ordered into a few classes, including Web substance mining, Web use mining and Web structure mining. Most Web content mining strategies utilize the watchword based methodologies, while others pick the expression strategy to develop a content portrayal for a lot of archives. It is trusted that the expression based methodologies ought to perform superior to anything the catchphrase based ones as it is viewed as that more information is conveyed by expression than by a solitary term.
International Journal in Commerce, IT and Social Sciences
Volume 5 Issue 07, July 2018 ISSN: 2394-5702 Impact Factor: 4.218
Journal Homepage: http://ijmr.net.in, Email: [email protected] Double-Blind Peer Reviewed Refereed Open Access International Journal
85
International Journal in Commerce, IT and Social Sciences http://ijmr.net.in, Email: [email protected] ordering literature was not better than the word-based one. In spite of the fact that expressions convey not so much uncertain but rather briefer implications than individual words, the probable explanations behind the demoralizing exhibition from the utilization of expressions are:(1) Phrases have inferior statistical properties to words, (2) They have a low frequency of occurrence, and
(3) There are a large number of redundant and noisy phrases among them.
The extreme development of information advances numerous new difficulties for Web researchers, which incorporate in addition to other things, high data dimensionality and very unpredictable and always advancing substance. Because of this, it has turned out to be progressively important to make better than ever ways to deal with customary data mining techniques can be connected for Web mining.
Consequently, separating valuable information is a key testing issue in web data mining. The billions of Web pages made are produced progressively by basic Web database service motors utilizing HTML or XML. Be that as it may, looking, understanding, and utilizing the semi-organized information put away on the Web represents a critical test since this data is more refined and dynamic than the information that business database systems store — the mining data shifts from organized to unstructured. Data mining, for the most part, manages organized data sorted out in a database while content mining primarily handles unstructured data. Web mining lies in the middle of and adapts to semi-organized data or potentially unstructured data. Web mining calls for innovative utilization of data mining or potentially content mining techniques and its unmistakable methodologies[2-7].
2. WEB DATA MINING
Data mining can be seen because of the natural development of information technology. The database system industry has seen a transformative way in the improvement of data accumulation, creation, data the board (counting data stockpiling and recovery, and database exchange processing), and propelled data analysis (including data warehousing and data mining). The research and advancement in database systems since the 1970s has advanced from early various leveled and network database systems to the improvement of social database systems (where data are put away in social table structures), data demonstrating tools, and ordering and getting to strategies.
Furthermore, clients increased advantageous and adaptable data access through inquiry dialects, UIs, enhanced question processing, and exchange the board. Proficient strategies for online exchange processing (OLTP), where a question is seen as a read-just exchange, have contributed considerably to the advancement and wide acknowledgment of social technology as a noteworthy tool for effective capacity, recovery, and the board of a lot of data. Application-arranged database systems, including a spatial, fleeting, multimedia, dynamic, stream, and sensor, and logical and designing databases, knowledge bases, and office information In bases, have prospered.
International Journal in Commerce, IT and Social Sciences
Volume 5 Issue 07, July 2018 ISSN: 2394-5702 Impact Factor: 4.218
Journal Homepage: http://ijmr.net.in, Email: [email protected] Double-Blind Peer Reviewed Refereed Open Access International Journal
86
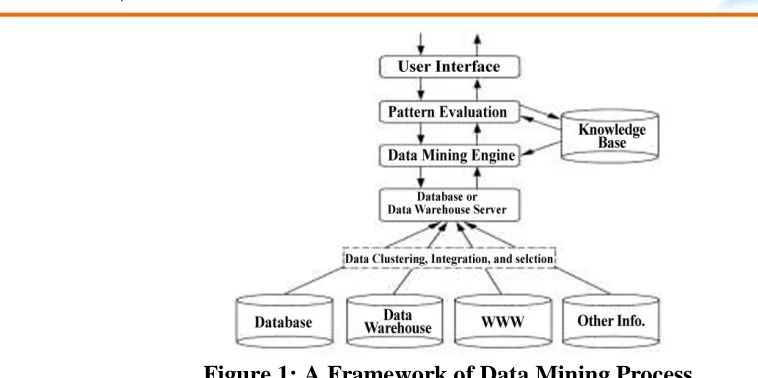
International Journal in Commerce, IT and Social Sciences http://ijmr.net.in, Email: [email protected]Figure 1: A Framework of Data Mining Process
To accessing information from web currently users choose various approaches. Most of the approaches are based on the following:
Content or Keyword based: Most of the search engine perform information search based on the keyword or content-directory browsing such as MSN, Google or Yahoo, which use keyword indices or manually built directories to find documents with specified keywords or contents.
Multilevel Deep Web Querying: Information cannot be accessed through static URL links, as most of the information hides behind searchable database query forms that unlike the surface. For example, if a user searching for a movie, book or song, which information not remain on the index pages it need to go for multilevel web search to find the relevant information.
Dynamic Web Link Clicking: Dynamically surfing the Web linkage links to a web resource presented by search engines.
3. LIMITATION AND CHALLENGES IN WEB DATA MINING
Web information presentation is a major challenge in current trends of information extraction. The traditional schemes for accessing the immense amounts of data that reside on the Web fundamentally assume the text-oriented, keyword-based view of Web pages. To achieve the required information, we need a high potential web mining technique to overcome the fundamental problems.
Current web search mining supports keyword, link address and content-based web search, where data mining will play an important role. But these web search engines still cannot provide high-quality, intelligent services because of several limitations in web mining which contributes to the problem.
Quality of keyword-based searches:
The quality of keyword-based searches suffers from several inadequacies such as a search often returns many answers, especially if the keywords posed include words from popular categories such as sports, politics, or entertainment.
Effective of deep-Web Extraction:
International Journal in Commerce, IT and Social Sciences
Volume 5 Issue 07, July 2018 ISSN: 2394-5702 Impact Factor: 4.218
Journal Homepage: http://ijmr.net.in, Email: [email protected] Double-Blind Peer Reviewed Refereed Open Access International Journal
87
International Journal in Commerce, IT and Social Sciences http://ijmr.net.in, Email: [email protected] accessible. Because current Web crawlers cannot query these databases, the data they contain remains invisible to traditional search engines.Self-organized and constructed directories:
A content or type-oriented Web information directory presents an organized picture of a Web sector and supports a semantics-based information search [9], which makes such a directory highly desirable. For example, following organization links like Country > Sports > Football > Players makes searches more efficient. Unfortunately, developers construct such directories manually which limit coverage of these costly directories provide and developers cannot easily scale or adapt them.
Semantics-based query:
Most keyword- based search engines provide a small set of options for possible keyword combinations, essentially ―with all the words‖ and ―with any of the words.‖ Some Web search services, such as Google and Yahoo, provide more advanced search primitives, including with exact phrases, without certain words,‖ and with restrictions on date and domain site type.
Human activities feedback:
Web page authors provide links to authoritative‖ Web pages and also traverse those Web pages they find most interesting or of highest quality. Unfortunately, while human activities and interests change over time, Web links may not be updated to reflect these trends
Multidimensional Data analysis and mining:
Because current Web searches rely on keyword-based indices, not the actual data the Web pages contain, search engines provide only limited support for multidimensional Web information analysis and data mining. These challenges and limitation have promoted research into efficiently and effectively discovering and using Internet resources, a quest in which web data mining play an important role.
Application of Web Data Mining
Web data mining can successfully fix information extraction and the following features incorporated with the web mining program must be fixed if we need to use data mining successfully in creating Web intelligence.
Web search-engine data mining
For website streamlining web slithers on files Websites and assembles and stores huge catchphrase-based lists that help distinguish sets of Websites that contain explicit watchwords and expressions. By utilizing a lot of firmly limited catchphrases and expressions, an accomplished client can rapidly distinguish fitting archives
Web Link Structure Analysing
Given a watchword and key expression or subject, for example, venture, we trust an individual might want to discover web pages that are incredibly fitting, yet reliable and of high calibre. In a flash, determining reliable Websites for a specific subject will improve a Web search's brilliance. The mystery of intensity hides in Website linkages
Automatically Classifying Web documents
Even though Yahoo and comparable Web listing service systems utilize human guests to order Web records, reasonable and improved speed make robotized classification exceedingly appropriate.
International Journal in Commerce, IT and Social Sciences
Volume 5 Issue 07, July 2018 ISSN: 2394-5702 Impact Factor: 4.218
Journal Homepage: http://ijmr.net.in, Email: [email protected] Double-Blind Peer Reviewed Refereed Open Access International Journal
88
International Journal in Commerce, IT and Social Sciences http://ijmr.net.in, Email: [email protected] Robotized evacuation of Website segments and semantic material can be troublesome given the present limitations on electronic natural-language parsing. Be that as it may, self-loader techniques can distinguish a huge piece of such segmentsDynamic Web Mining
Web mining can likewise perceive as elements web. How the Web changes in the viewpoint of its material, segments, and availability styles. Sparing certain bits of conventional subtleties identified with these Web investigation components helps in discovering changes in material and linkages.
4. CLASSIFICATION AND FEATURE SELECTION TECHNIQUES IN DATA MINING
As the world develops in intricacy, overpowering us with the data it creates, data mining turns into the main trust in explaining the examples that underlie it. The manual process of data analysis winds up dreary as the size of data develops and the quantity of measurements increments, so the process of data analysis should be computerized. The term Knowledge Discovery from data (KDD) alludes to the mechanized process of knowledge discovery from databases. The process of KDD is included numerous means to be specific data cleaning, data combination, data choice, data change, data mining, design assessment, and knowledge portrayal. Data mining is a stage in the entire process of knowledge discovery which can be clarified as a process of separating or mining knowledge from a lot of data.
5. KNOWLEDGE DISCOVERY IN DATA BASES
The transformation of data into knowledge has mostly been dependent on manual methods for data analysis and interpretation, which makes the process of pattern extraction of databases expensive, slow and highly subjective, and unthinkable especially if the data is anonymous. The interest in automating the analysis of large volumes of data has been the motivation factor for several research projects in the emergent field called Knowledge Discovery in Databases (KDD). KDD is the process of knowledge extraction from a large mass of data with the goal of obtaining meaning to be able to interpret data, and to acquire new knowledge if any.
Data Mining involves the process of analyzing data to show patterns or relationships; sorting through large amounts of data; and picking out pieces of relative information existing in data. Data Mining has several tasks which can be roughly classified into six categories:
Estimation and prediction Classification
Association discovery
Clustering and cluster analysis Visualization of data, and Visual data exploration
Some of the most popularly applied techniques to perform data mining task are: a. Statistical Analysis
b. Decision Tree c. Neural Network
d. Inductive Logic Programming e. Clustering
f. Association Rule
International Journal in Commerce, IT and Social Sciences
Volume 5 Issue 07, July 2018 ISSN: 2394-5702 Impact Factor: 4.218
Journal Homepage: http://ijmr.net.in, Email: [email protected] Double-Blind Peer Reviewed Refereed Open Access International Journal
89
International Journal in Commerce, IT and Social Sciences http://ijmr.net.in, Email: [email protected] h. Genetic Algorithmsi. Fuzzy Logic j. Rough Sets
k. Concept Learning and l. Rule-Based Reasoning.
A detailed review of data mining assignments, data mining techniques has been displayed in the research. This investigation, for the most part, centers on bunching and affiliation standard mining. Hence the meaning of grouping and affiliation guideline has been explained in the accompanying subsections. Data Mining is the process of breaking down data from alternate points of view and abridging it into valuable information for various applications. The adequacy of RST has been examined in the spaces of artificial intelligence and psychological sciences particularly for portrayal of and prevailing upon ambiguous as well as loose knowledge, data grouping and analysis, machine learning and knowledge discovery.
6. APPLICATIONS OF DATA MINING
These days, numerous enterprises are being utilized the electronic data storehouses for putting away the gigantic size of their data. Concentrate the knowledge from the tremendous size of these data sources is non-suitable to the expert for better basic leadership process. The customary techniques are lacking to investigate these sorts of data. The present world data are gathered and put away at gigantic paces. So it is basic to the businesses to locate a unique tool for putting away and getting to these databases. The data mining tools are such kind of tools. These tools are connected to both business and logical data. The business data are mined to give better service to clients, alter, and ace actuates their services.
7. CONCLUSION
The research and execution of a support system for Knowledge Discovery is the test of numerous researchers. As Web Data Mining is the primary key advance in Knowledge Discovery process in Databases (KDD), web data extraction assuming the job of data gathering from the web and data mining methods on the removed downright data to find knowledge. This research is proposing an approach to apply the clustering idea on all-out web data and to utilize the clustering results as a component of the contribution for the characterization led on another arrangement of data.
Web mining is an extremely hot research theme which joins two of the actuated research regions: Data Mining and World Wide Web. The Web mining research identifies with a few research networks, for example, Database, Information Retrieval, and Artificial Intelligence. Even though there exists very some perplexity about Web mining, the most perceived methodology is to order Web mining into three territories:
The qualification between these two classes is not reasonable some of the time. Web utilization mining is relatively free, yet not disengaged, class, which mostly portrays the techniques that discover the client's use example and attempt to foresee the client's practices. This research is a review dependent on them as of late distributed research papers. Other than giving a general perspective on Web mining, this research will concentrate on Web use mining.
REFERENCES
International Journal in Commerce, IT and Social Sciences
Volume 5 Issue 07, July 2018 ISSN: 2394-5702 Impact Factor: 4.218
Journal Homepage: http://ijmr.net.in, Email: [email protected] Double-Blind Peer Reviewed Refereed Open Access International Journal
90
International Journal in Commerce, IT and Social Sciences http://ijmr.net.in, Email: [email protected] [2]. Mr. S. P. Deshpande and Dr. V. M. Thakare, “Data Mining System and Applications: AReview,” International Journal of Distributed and Parallel systems (IJDPS) Vol.1, No.1, September 2010.
[3]. Sankar K. Pal, VarunTalwar, PabitraMitra, (2002) “Web Mining in Soft Computing Framework: Relevance, State of the Art and Future Directions” IEEE Transactions on Neural Networks, Vol. 13, No. 5.
[4]. K. J. Cios, W. Pedrycz, and R. M. Swiniarski. Data Mining: A Knowledge Discovery Approach., Chapter 2, pp. 9-24, Springer Press, 2007
[5]. Jianshan Sun, Gang Wang, Xusen Cheng, Yelin Fu, "Mining Effective Text to Improve Social Media Item Recommendation", Elsevier-Information Processing and Management, Volume 51, Issue 4, July 2015, pp.444-457.
[6]. P Ristoski, H Paulheim, "Semantic Web in Data Mining and Knowledge Discovery: A comprehensive Survey", ElsevierServices and Agents on the World Wide Web, 2016, pp. 1-22.