International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459,ISO 9001:2008 Certified Journal, Volume 4, Issue 7, July 2014)
775
Grid Host Load Prediction Using GridSim Simulation and
Hidden Markov Model
Shweta Jaiswal
1, Atish Mishra
2, Praveen Bhanodia
3 1Research Scholar-M.Tech, Patel College of science and Technology, Indore
2Asst.Prof., 3HOD, Computer Science Department, Patel College of science and Technology, Indore
Abstract – Grid computing enables the efficient computing
and computational resource management. Now in these days these services are frequently obtainable. On the other hand the load on these servers is increases as the amount of requested resources are increases thus resources conflict and network issues are occurred in computational servers. In order to prevent such kind of faults Hidden Markov Model based predictive schemes is proposed and implemented for host load approximation. The presented simulation is first compute the host load using the GridSim simulator and then a separate tool is implemented for next approximated. The obtained results demonstrate the effectiveness of technique in terms of high accurate predictive values and less time and space complexity of the system. Therefore the presented technique is adoptable for the real world scenarios of host load approximation and fault tolerance scheme development.
Keywords - Grid computing, CPU loads, Prediction
techniques, HMM.
I. INTRODUCTION
In network Grid computing allow accessing distributed resources of - CPU processes, storage capability, devices used for input and output working, provide services, available applications. Today Grid main purpose is resource sharing. It is not only work with simple file exchange but also work on computation power, software, and data and directly accesses other resources. Some of the target systems can be clusters of nodes with itself or high performance servers [1].
In Grid computing the main problem is allocation of the resources, the scheduling of tasks and monitoring etc. In this manner it shows that there is no doubt on resource performance. The performance of grid resources are mainly achieved by means of two mechanisms: monitoring and prediction [1].
Grid resource monitoring aims to acquire the status, distribution, load as well as the fault situation of the resources in grid environment by means of monitoring methods. While grid resource prediction aims to handle the variation principles and running traces of grid resources by means of modeling and analyzing on historical monitoring data [2].
Grid applications include the following: Simulations on remote supercomputers.
Cooperation of very large data sets for simulation. Distributed processing to compute load by data
analysis.
[image:1.612.334.549.322.574.2] Coupling of method with remote computers and data archives.
Figure 1: Load taxonomy
Computational resources are required to achieve load balancing or forecast the load. For any application turnaround time is most important information for prediction because CPU and network is important elements of computation resources. The result of experiment gives accuracy and practicability using Real CPU load and network load [3].
To find the specific load, there are some major parameters which define the algorithm will employ [4].
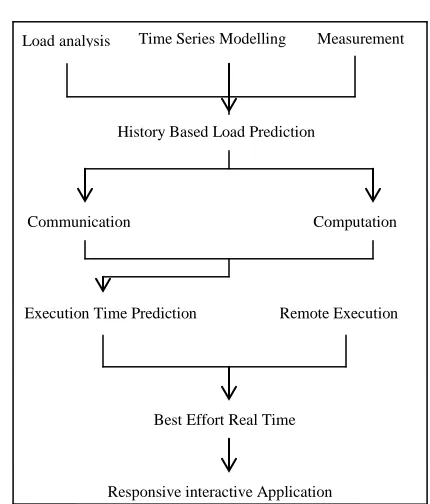
Load analysis Time Series Modelling Measurement
History Based Load Prediction
Communication Computation
Execution Time Prediction Remote Execution
Best Effort Real Time
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459,ISO 9001:2008 Certified Journal, Volume 4, Issue 7, July 2014)
776 Information in the form of dataset that should be used
in terms of load balancing.
Algorithm makes the load balancing decision. Finally the load balancing decision is made.
The structure of this paper is organized as follows. Section 1 is the introduction. Section 2 discusses related work. Section 3 introduces background of related work. Next section 4 describes prediction model in detail. The results of the experiments and the evaluations of the approach are also presented in Section 4. Finally, in Section 5, conclusion and future work is pointed out.
II. RELATED WORK
In distributed computing environment, resource prediction algorithms have been developed to monitor the status of system. Grid as distributed computing environment works on service selection, task allocation and monitoring. So these decisions are helpful in resource load prediction.
Earlier linear models applied to predict the future load. In one step ahead prediction the Network Weather Service (NWS) (Wolski 1998) is famous tool based on linear model. Dinda and O’Hallaron (2000) predicted the task running times based on CPU load prediction using different linear model including AR (Autoregressive model), MA (Moving average model), ARMA (Autoregressive Moving average model), and ARIMA (Autoregressive Integrated Moving average model). In all these model AR is best model. It performed CPU prediction because of its good predictive power and low overhead. Yang et al. (2003) presented two prediction strategies such as homeostatic and tendency based. In 2006 Dinda designed a toolkit to predict the online resource performance. Zhang et al. (2008) presented a running time prediction method for Grid tasks. They provided a resource oriented approach to predict future performance of resource and multi-step-ahead CPU load prediction approaches by repeatedly using one step-ahead prediction strategy. If one step-step-ahead value is not accurate then latter value is based on the previous predicted value. Liu et al. (2011) proposed hybrid non linear algorithm. In this, they compare six approaches including LAST, Exponential Smoothing, MEAN, AR, Moving Average and Network Weather Service.
Now today’s era various load prediction algorithms are available but they contain some drawbacks. This section explained various previously defined methods of the host load estimation, prediction and monitoring [5].
Researcher has developed various prediction model such as ANNs [6], [7], fuzzy inference [8], [6], SVMs [9][7], Bayesian model [10], Markov model [11], [9], and other.
III. BACKGROUND
These sections describe the past background of the prediction model that utilized in proposed work.
A.Artificial neural network
Artificial neural networks are compositions of interconnecting artificial neurons these neurons are programmatically constructed. In computer science it is used to solve artificial intelligence problems. It is a data model created using mathematical complex calculations. Application areas of ANNs contain system identification and control like vehicle control, process control and decision making, pattern recognition radar systems, face identification, sequence recognition gesture, handwritten text recognition, speech, financial applications, medical diagnosis, e-mail spam filtering and data mining or knowledge discovery in databases visualization [12].
B.Bayesian classifier
The fundamental idea is to generate the posterior probability from the prior probability distribution and the run-time evidence of the recent load fluctuations, according to a Bayes Classifier. It is suitable classifier that is frequently used for the classifying the host load, but it is inefficient due to the binary classification scheme. In addition to that this classifier also reflects the slow learning rate for recognizing the data pattern [13].
C.Neural network
That is much efficient and effective in order to recognition of data patterns, classifying them and predictive methodologies. On the other hand that method is much efficient in order to produce the predictive values with less time, but in order to recognize the data pattern the method is not much efficient because of the training time, the number of training cycles are required to introduce for more accurate values prediction. In addition of that that method reflects slow learning rate when the data is available in streamed manner.
D.Hidden markov model
That is an efficient classifier and predictive method which uses the probabilistic concept for approximating the future values. That is based on the transactional pattern analysis based method. That is inefficient due to huge amount of data available for analysis therefore that technique is also reflect the slow learning rate during pattern recognition [14].
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459,ISO 9001:2008 Certified Journal, Volume 4, Issue 7, July 2014)
777
Load sample Collection
Forecast upcoming Load Data
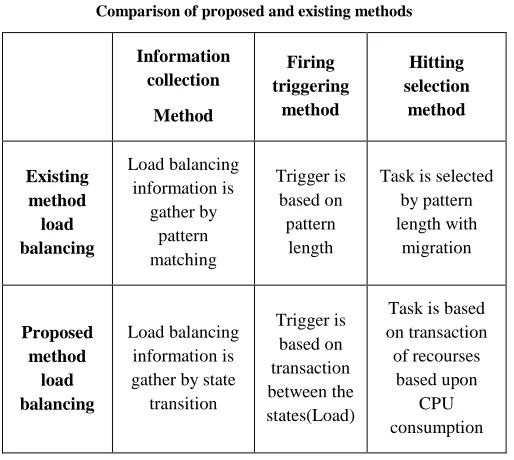
[image:3.612.41.298.130.360.2]analysis Table 1
Comparison of proposed and existing methods
Information collection
Method
Firing triggering
method
Hitting selection
method
Existing method load balancing
Load balancing information is
gather by pattern matching
Trigger is based on pattern
length
Task is selected by pattern length with
migration
Proposed method
load balancing
Load balancing information is gather by state transition
Trigger is based on transaction between the states(Load)
Task is based on transaction of recourses
based upon CPU consumption
Major purpose of proposed algorithm is Time Complexity i.e., in proposed Algorithm time complexity is low while in existing Algorithm time complexity is more than newly proposed algorithm. Execution time in .Net Framework using proposed algorithm is too much fast compared to existing algorithms [12].
There are various Load Balancing Algorithms available but they contain several drawbacks. Such problems can be solving by the proposed dynamic load balancing algorithm [12].
IV. PROPOSED ALGORITHM
The main aim to achieve forecasting is to get or collect the load parameters from all the grid nodes and organize data according to these parameter values to predict the future load.
Figure 2 Basic flow of system
For that purpose two different algorithms are required to study and compare first BPN and second self-pattern analysis algorithm is designed.
The algorithm has following steps:
Initialization of grid, Workload reading, Neural network training, proposed model training, Prediction using neural network, Prediction using proposed model, Performance comparison.
Hidden Markov Model
An HMM is a double implanted stochastic process with two hierarchy levels. It can be used to model much more complex stochastic processes as compared to a traditional Markov model. In a specific state, an observation can be generated according to an associated probability distribution. It is only the observation and not the state that is visible to an external observer.
An HMM can be characterized by the following:
1. N is the number of states in the model. Si, i= 1, 2...n is an individual state denote the set of states S = {S1, S2...Sn}. The state at time instant t is denoted by qt.
2. M is the number of distinct observation symbols per state Vi where i = 1, 2 ... m is an individual symbol denote the set of symbols V = {V1, V2 ...Vm}.
3. The state transition probability matrix A = [aij], where
Here aij > 0 for all i, j. Also,
4. The remark symbol probability matrix B = {bj (k)}, where
5. The initial state probability vector = , where
Such that
6. The remark sequence O = O1, O2, O3 ...Or, where each remark Ot is one of the symbols from V, and R is the number of remarks in the sequence.
[image:3.612.55.285.555.603.2]International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459,ISO 9001:2008 Certified Journal, Volume 4, Issue 7, July 2014)
778
We use the notation λ = (A, B, ) to specify the complete set of parameters of the model, where A, B implicitly contain N and M.
As mentioned above, an observation sequence O can be generated by many possible state sequences. Consider one such particular sequence Q = q1, q2 ... qr. where q1 is the initial state. The probability that O is generated from this state sequence is given by
The statistical independence of observations of above equation can be assumed and expanded as
The state sequence probability P (Q | λ) is given as
Thus, the generation of the observation sequence probability P (O | λ) by the HMM can be written as follows:
Deriving the value of probability of the observation sequence using the direct definition of is computationally intensive. Hence, a procedure to compute the value named as Forward-Backward procedure is used to
compute .
[image:4.612.311.568.96.510.2]In this section, the proposed algorithm generating the upcoming load data, that algorithm help to estimate the upcoming load values approximation using probability of states and provide the new load pattern that arises in at least five steps ahead.
Table 2 Proposed Algorithm
Input: Work load data.
Output: Next load values.
Process:
1. Read load data in a vector format.
2. Find unique values in CPU load attribute.
3. These CPU cost unique values are treated as states.
4. Create transition matrix using the states evaluated.
5. Pair the workload data in a group of 5 values.
6. Label the groups as observation.
7. Using the obtained states and the observations create an observation matrix.
8. The probability of generation of the observation sequence observed by the HMM is given using formula
9. Append the generated sequence in the available observation.
10.Repeat the step 8 for new load data estimation.
V. IMPLEMENTATION
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459,ISO 9001:2008 Certified Journal, Volume 4, Issue 7, July 2014)
779
For data set, the information gathered from cs.huji at computer IBM SP during the months of 25 Apr 2000 to 1 Jan 2003.
A further section shows the detailed description, approach and design of each application module. The results obtained briefly discussed with the help of snapshots obtained from the application.
In first step as shown in Fig. 5(a) simulation requires to give values to fields as Number of user, rating of each PEs in MIPS, Number of PEs for each machine and total number of machine. These grid parameters are requiring for running simulation.
Fig. 5(a) Grid environment window
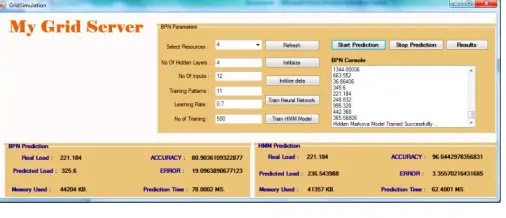
After this it calculates the load as shown in Fig. 5(b) on grid then it saved in database. This database is connected to proposed algorithm to predict the load of CPU. Now proposed algorithm is worked with its parameter and generates the real load and predicted load.
Fig. 5(b) Initializing data and predict load values
These all parameters give accuracy, error, and memory consumption and prediction time of predicted value as shown in Fig. 5(c).
In this way proposed algorithm predicts future load value.
Here the four parameter i.e. accuracy, error, memory consumption and prediction time is used to show the graphical presentation of algorithm.
Fig. 5(c) Graphical presentation
VI. RESULT ANALYSIS
The effectiveness of our proposed concepts is shows by below figures. They show the accuracy, error, memory and prediction curves for load indicated by a Blue line. These results show how the use of our technique may bring several benefits to the implementation of load prediction in grid environment both in terms of data analysis and load distribution results.
To test performance of algorithm, we compared the prediction results of HMM with the results of Neural Network. Firstly, we tested the accuracy of the proposed algorithm. As Fig. 6(a) shows, our HMM is more accurate than Neural Network.
0 20 40 60 80 100
5 40 75
11
5
15
0
18
5
23
5
A c c u r a c y
%
Time In Sec
proposed
Neural Network
Fig. 6(a) Accuracy Graph
[image:5.612.325.577.111.281.2] [image:5.612.49.288.265.365.2] [image:5.612.49.302.446.555.2] [image:5.612.326.574.457.608.2]International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459,ISO 9001:2008 Certified Journal, Volume 4, Issue 7, July 2014)
780 0
10 20 30 40 50
5 40 75
115 150 185 235
E r r o r
r a t e %
Time In Sec
Proposed Neural Network
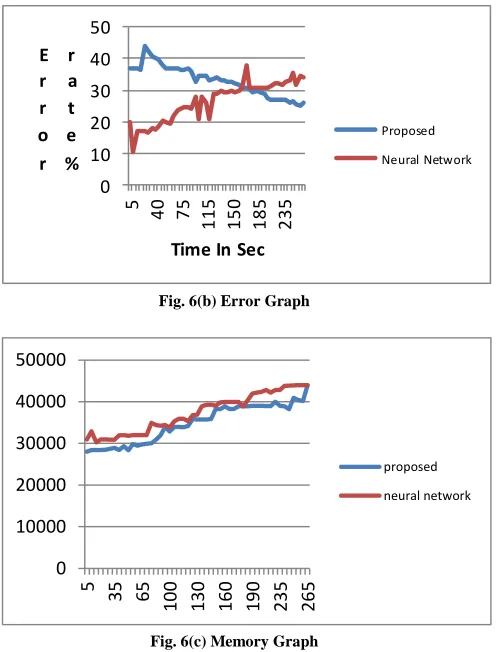
Fig. 6(b) Error Graph
0 10000 20000 30000 40000 50000
5 35 65
10
0
13
0
16
0
19
0
23
5
26
5
proposed neural network
Fig. 6(c) Memory Graph
Finally, we compared the model-building time and prediction time of Hidden Markov model. As Fig. 6(d) and Fig. 6(e) shows the model-building time for the HMM is shorter than Neural network. As a whole, our HMM is more effective than neural network, and it provides efficient monitoring and prediction of load.
Fig 6(d) Built Time Graph
Fig. 6(e) Decision Time Graph
VII. CONCLUSION
The proposed work is a predictive methodology for grid host load computation. In this proposed work, a predictive methodology is proposed and implemented using the GridSim discrete event simulation environment.
The contribution of this paper is Hidden Markov model for CPU load prediction.Firstly data is prepared through which loads are generated. Based on the calculation, algorithms train the model and predict the load. To justify the results obtained the comparative study of proposed methodology is also provided with respect to the neural network. According to the comparative analysis proposed algorithm is effective enough and consumes fewer resources than previously available methods.
VIII. FUTURE EXTENSIONS
The proposed work is implementation of a predictive algorithm for grid host load, there are some problem such as memory usage and disk usage prediction are remain to fix in near future during calculations. On the other hand the proposed method is lacked due to their decision time. Therefore improvements on decision making methodology are also required in future works.
REFERANCES
[1] Dingyu Yang, Jian Cao, Jiwen Fu, Jie Wang, Jianmei Guo, “A pattern fusion model for multi-step-ahead CPU load prediction,” © 2012 Elsevier Inc. All rights reserved.
[2] Mario Cannataro, Andrea Pugliese, Paolo Trunfio, “Distributed Data
Mining on Grids: Services, Tools, and Applications,”
IEEE TRANSACTIONS ON SYSTEMS, MAN, AND
[image:6.612.326.563.112.259.2] [image:6.612.51.299.123.449.2] [image:6.612.56.280.528.647.2]International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459,ISO 9001:2008 Certified Journal, Volume 4, Issue 7, July 2014)
781 [3] Sayaka Akioka, Yoichi Muraoka, “Extended Forecast of CPU and
Network Load on Computational Grid,” International Symposium on Cluster Computing and the Grid IEEE, 2004.
[4] Junwei Cao1, Daniel P. Spooner, Stephen A. Jarvis, and Graham R. Nudd, “Grid Load Balancing Using Intelligent Agents”.
[5] Prabhat Kr.Srivastava, Sonu Gupta, Dheerendra Singh Yadav, “Improving Performance in Load Balancing Problem on the Grid Computing System,” IJCA Volume 16– No.1, February 2011. [6] O. Nasraoui and R. Krishnapuram, “One step evolutionary mining of
context sensitive associations and Web navigation patterns,” in Proc. SIAM Int. Conf. Data Mining, Arlington, VA, pp. 531–547, April 2002.
[7] M. Awad and L. Khan, “Web navigation prediction using multiple evidence combination and domain knowledge,” IEEE Trans. Syst., Man, Cybern. A, Syst., Humans, vol. 37, no. 6, pp. 1054–1062, November 2007.
[8] O. Nasraoui and C. Petenes, “Combining Web usage mining and fuzzy inference for Website personalization,” in Proc. WebKDD, pp. 37–46, 2003.
[9] M. Awad, L. Khan and B. Thuraisingham, “Predicting WWW surfing using multiple evidence combination,” VLDBJ, vol. 17, no. 3, pp. 401–417, May 2008.
[10] M. T. Hassan, K. N. Junejo, and A. Karim, “Learning and predicting key Web navigation patterns using Bayesian models,” in Proc. Int. Conf. Comput. Sci. Appl. II, Seoul, Korea, 2009, pp. 877–887. [11] J. Pitkow and P. Pirolli, “Mining longest repeating subsequences to
predict World Wide Web surfing,” in Proc. 2nd USITS, Oct. 1999. [12] Truong Vinh Truong Duy, Yukinori Sato, Yasushi Inoguchi,
“Improving Accuracy of Host Load Predictions on Computational Grids by Artificial Neural Networks,” Received 20 July 2009; final version received 20 February 2010.
[13] Sheng Di, Derrick Kondo, Walfredo Cirne, “Host Load Prediction in a Google Compute Cloud with a Bayesian Model,”978-1-4673-0806-9/12/$31.00, 2012 IEEE.
[14] Jesper Nielsen, Andreas Sand, “Algorithms for a parallel implementation of Hidden Markov Models with a small state space,” IEEE International Parallel & Distributed Processing Symposium, 2011.
[15] Liang Hu, Xiaochun Cheng, Xilong Che, “Survey of Grid Resource Monitoring and Prediction Strategies,” International Journal of Intelligent Information Processing, Volume 1, Number 2, December 2010.
[16] Rahul Nayak, Prof. Rashmi Gupta, “CPU Load Predictions on the Computational Grid Using Distance Based Algorithm,” IJACST, Volume 2, No.7, July 2013.
[17] Peter A. Dinda, David R. O’Hallaron, “Host Load Prediction Using Linear Models,” in part by the national Science Foundation under Grant CMS- 9318163, and in part by grant from the Intel Corporation.
[18] Lingyun Yang, Ian Foster, Jennifer Schopf, “Homeostatic and Tendency-based CPU Load Predictions,” Proceedings of IPDPS 2003, April 2002.
[19] R. Vilalta, C. V. Apte , J. L. Hellerstein, S. Ma, S. M. Weiss, “Predictive algorithms in the management of computer systems,” IBM SYSTEMS JOURNAL, VOL 41, NO 3, 2002.
[20] Introduction to Grid Computing, Bart Jacob, Michael Brown, Kentaro Fukui, Nihar Trivedi, ibm.com/Redbooks.
[21] EunJoung Byuna, SungJin Choia, MaengSoon Baikb, JoonMin Gilc, ChanYeol Parkd,ChongSun Hwanga,”MJSA: Markov job scheduler based on availability in desktop grid computing environment,” Future Generation Computer Systems 23 (2007) 616–622, 16 September 2006.
[22] Peter A. Dinda, “The Statistical Properties of Host Load (Extended Version),” CMU-CS-98-175, March1999.