International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459,ISO 9001:2008 Certified Journal, Volume 4, Issue 3, March 2014)Data Mining Techniques in Parallel and Distributed
Environment- A Comprehensive Survey
Shraddha Masih
1, Sanjay Tanwani
21,2
School of Computer Science & IT, DAVV, Indore, India
Abstract—Distributed sources of voluminous data have raised the need of distributed data mining. Conventional data mining techniques works well on structured data which is clean, pre-processed and properly arranged either in the form of structured files, databases or data warehouse. These techniques are based upon centralised data store however they have several limitations in distributed scenario where the data is scattered in different geographical locations on data servers all across the network. It becomes a costly affair to accumulate huge data on a centralised node in real time. To overcome these limitations, application of distributed data mining techniques has become essential. This paper describes various data mining tools and techniques that can be used in distributed environment. Different algorithmic and architectural approaches are followed in various distributed mining techniques. Latest approaches in distributed data mining are explored. Various research issues and challenges in the field of distributed data mining are also discussed.
Abbreviations: KDD-Knowledge discovery in databases, ARM- Association rule mining, DDM- Distributed Data Mining, GPU-Graphical processing Unit
I. INTRODUCTION
Organizations need to accumulate vast and growing amounts of data in different databases. This data may be either transactional data like sales, inventory, payroll, accounting etc. or analytical data that is helpful in decision support systems. For utilizing this data, it must be analyzed thoroughly. Many analytical tools are available in market. Data mining techniques also come in the category of analytical systems that help to give insight into hidden information. It can be helpful to find patterns, relationships and categories of data [2].
Data mining is considered as a part of KDD process. Main steps of KDD include data accumulation, cleaning, pre-processing, storing, mining and finally representing the patterns in a presentable format.
In last twenty years lot of research has been done on improvising performance of data mining techniques. From past to present, three different trends have been observed. The first trend is based on centralized approach where all data needs to be stored on a central node. Mostly sequential algorithms were a part of this approach.
The second trend was observed in terms of
parallelizing centralized algorithms. Two main
Parallel computing techniques took a boost with the advent of multi core CPUs and cheaper GPUs. A combination of CPU and GPU resulted in multi fold performance benefit.
Last trend is distributed data mining where data mining techniques were applied in different distributed computing paradigms like peer to peer, clusters, grids and cloud environment [1].
II. ABOUT DATA MINING
In this competitive world, top level management needs to take right decisions at right time for giving better service to customers, and to provide better organizational image. Decisions based on better analysis results in increasing profit and decreasing loss. For doing so, management is dependent on better analytical and data mining services.
Fig.1Data Mining Process
Data mining offers a wide range of algorithms used for analysis, pattern discovery and prediction. It includes techniques such as association rule mining, decision trees, regression, support vector machines and many more.
Data mining techniques evolved as a requirement when enormous data started accumulating in digital format. A wide variety of profitable solutions are hidden inside this wide pool of data.
The existing data mining algorithms can work in three different computing environments:
Centralised
Parallel
Distributed
A. Centralised Approach for Data Mining
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459,ISO 9001:2008 Certified Journal, Volume 4, Issue 3, March 2014)In centralized approach, data is extracted and accumulated on a centralized store after cleaning and pre -processing. From this central store, task relevant data is selected and mining techniques are applied.
Initially, data mining techniques were restricted to centralized processing [3],[4][5][6][7].
Data mining algorithms are helpful in digging out hidden previously unknown information from existing data.
Xindong Wu et al.[2] did a survey in 2007 and presented top 10 algorithms mostly used by the analysts of the world. The algorithms were rated on the basis of their popularity, performance and utility. The centralised algorithms that were considered to be most influential are C4.5, k-Means, SVM, Apriori, EM, PageRank, AdaBoost, kNN, Naive Bayes, and CART. [8,9,10,11]. A brief about these algorithms is presented below:
Table.1
Top Algorithms of Data Mining Data mining
Technique
Centralized Algorithms Feature
Association Rule A Priori Botttom-Up Approach: Requires n scans of database for finding association rules upto n itemsets.
Pincer Search Botttom-Up with Top Down Approach: Requires early termination if big itemsets are found to be frequent while doing top down comparison.
FP Tree Growth Requires database scan only twice since the rules are derived from the Frequent Pattern Tree.
Clustering K Means Hill climbing method of clustering for creating K clusters.
EM Algorithm Mathematical modelling method based on random phenomenon.
Classification C4.5 Decision tree based method for classification from which rules can also be derived. Based upon
Gini Diversity Index. Multiway tree can be generated.
CART Generates binary decision tree. Information based method for splitting nodes.
SVM Derives classification function to distinguish different classes of training dataset
kNN It is not based on exact match for classification. It finds a group of k objects in the training set that are closest to the test object.
Niave Bayes Supervised classification method based on comparing score with threshold.
Prediction AdaBoost Ensemble learning method that combines many weak rules for creating accurate prediction rules.
Others PageRank Search Ranking algorithm based on web hyperlinks of web pages.
B.Parallel Approach for Data Mining
Many scientific and compute intensive and large problems can be better solved using parallel programming approach. Data mining can be executed in a highly parallel environment over multiple processors. Parallel implementations of data mining algorithms can be distinguished on the basis of task parallel and data-parallel approaches [16].
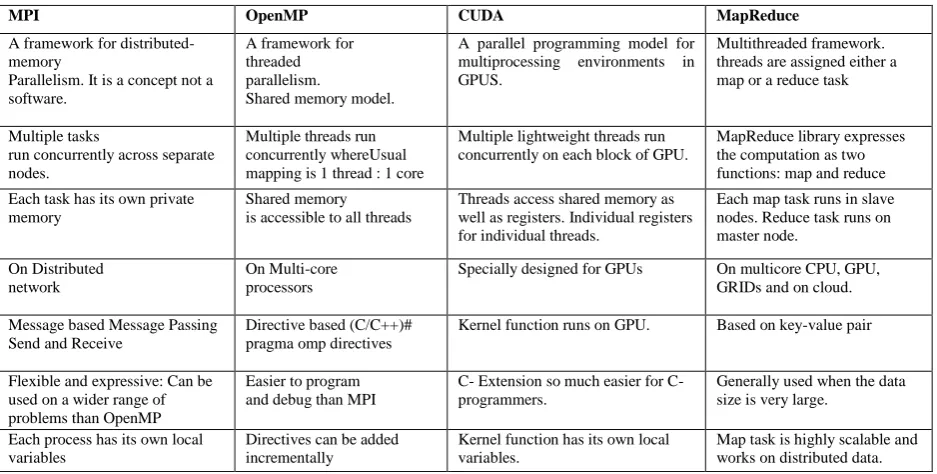
Modern Programming languages are also structured so as to efficiently utilize novel architectures. There exist dedicated parallel programming paradigms for parallelizing the algorithms over multiprocessor and networked systems. OpenMP and MPI are exclusively used to achieve shared and distributed memory parallelization. [24, 25].
CUDA is a programming language that is designed for programming on NVIDIA GPUs [23]. CUDA offers a data parallel programming model. In CUDA, threads access different memories of GPU.
General purpose programming can also be done on Graphical Processing Units where multi cores can be exploited for highly parallel processing. Many data mining algorithms have been specifically designed in CUDA and shows drastic improvement in performance.
Parallel programming is incomplete without
discussing on the recent approach called Map Reduce [17]. It can process large sized data sets in a highly parallel manner. Map Reduce was introduced by Google in 2004. Map Reduce has become the most popular framework for mining large-scale datasets in parallel as well as distributed environment. Different
computing environments’ require different
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459,ISO 9001:2008 Certified Journal, Volume 4, Issue 3, March 2014)Table 2. Parallel approaches
Future Scope in Parallel Data mining
With the availability of cheaper, highly parallel GPUs in market, lot of research is done in parallelizing data mining algorithms for these devices. GPUMiner, is a novel parallel data mining system that utilizes new-generation graphics processing units (GPUs). This system relies on the massively multi-threaded SIMD architecture. [26].
Various data mining algorithms including association rules, clustering and classification have been modified for parallel processing architectures [27, 28, 29, 30, 31, 32]. Parallel mining on multidimensional data storage have also been explored by S.Goil and A. Choudahary. [33].
Jin, Ruoming, Ge Yang, and Gagan Agrawal focused on shared memory parallelization of data mining algorithms. They parallelized data mining algorithms, and their technique applied to large number of data mining problems. They proposed a reduction-object-based interface for specifying a data mining algorithm [63].
We present identified future scopes in the field of parallel data mining.
i. CPU+GPU combination can be used for performance enhancement in compute intensive tasks [79]. CUDA can make computations on a single computer run faster by using its CPU+GPU combination.
ii.Using GPUs in clusters of computers can achieve large scale, cost-effective, and power efficient solution of data mining [80].
iii. Lot of scope is there in developing map-reduce-like models for programming in heterogeneous CPU-GPU clusters.
C. Distributed Approach for Data Mining
The larger amount of data you store on a single machine, the longer it takes to access. With time the amount of data grows so large that firing analytical queries on these data becomes very time consuming.
By dividing the data and distributing it on several machines, you need strong indexing techniques to point at the appropriate servers. Distributed approach for data mining is useful when the data sources are at multiple sites. Data extraction, cleaning, pre processing and integrating consumes majority of time thereby affecting the analysis process. When it comes to time critical applications, this delay cannot be tolerated. Thus, there exists a requirement to mine such data in a distributed manner.
D. Distributed Data mining Challenges
Distributed data:As the dimension of an organization
grows, managing data is convenient when distributed as per the location or functionality.
Storing and managing distributed data is a challenge especially when it has to be reused for global processing. Wilford-Rivera Ingrid [11] have explored the methods to apply data mining on distributed databases.
BIGDATA: Big data is a collection of structured and
unstructured data sets that so large and complex that it becomes difficult to process using conventional database
MPI OpenMP CUDA MapReduce
A framework for distributed-memory
Parallelism. It is a concept not a software.
A framework for threaded parallelism.
Shared memory model.
A parallel programming model for multiprocessing environments in GPUS.
Multithreaded framework. threads are assigned either a map or a reduce task
Multiple tasks
run concurrently across separate nodes.
Multiple threads run concurrently whereUsual mapping is 1 thread : 1 core
Multiple lightweight threads run concurrently on each block of GPU.
MapReduce library expresses the computation as two functions: map and reduce
Each task has its own private memory
Shared memory is accessible to all threads
Threads access shared memory as well as registers. Individual registers for individual threads.
Each map task runs in slave nodes.Reduce task runs on master node.
On Distributed network
On Multi-core processors
Specially designed for GPUs On multicore CPU, GPU, GRIDs and on cloud.
Message based Message Passing Send and Receive
Directive based (C/C++)# pragma omp directives
Kernel function runs on GPU. Based on key-value pair
Flexible and expressive: Can be used on a wider range of problems than OpenMP
Easier to program and debug than MPI
C- Extension so much easier for C- programmers.
Generally used when the data size is very large.
Each process has its own local variables
Directives can be added incrementally
Kernel function has its own local variables.
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459,ISO 9001:2008 Certified Journal, Volume 4, Issue 3, March 2014)BIGDATA come from variant sources like web logs, click histories, e-commerce applications, Retail purchase histories, bank and credit card transactions, social networking and media, mobile devices call & text data, networked devices and sensors.
Traditional data mining techniques are not up to the mark for processing and analyzing Big Data in a time & cost-efficient manner.
For such applications, the Map Reduce frame work has recently attracted a lot of attention. Google’s MapReduce and open-source equivalent Hadoop is a powerful tool for building such applications.
The main benefit of Hadoop is that it takes advantage of distributed processing and is scalable and fault tolerant.
Kyuseok Shim [17] applied parallel programming
method MapReduce that can be used for many machine learning applications. In this paper, MapReduce framework based on Hadoop is discussed, and the state-of-the-art in MapReduce algorithms for data mining is presented.
Unstructured and Complex Data:Unstructured data is
the one that cannot be retrieved through SQL. It is generally non tabular and does not have any pattern [14].
A related new style of database called NoSQL (Not Only SQL) has emerged now a days. NoSQL encompasses wide variety of data management techniques but exploring NoSQL data for analysis is still a challenging job. Main NoSQL databases [15] currently available include: HBase, Cassandra, MarkLogic, Aerospike and MongoDB.
Distributed operations: Distributed queries are fired
when an application distributes its tasks among different computers in a network. The challenge is to apply data mining techniques in a distributed fashion with underlying consideration of reducing overall data transfer over the network. Service-oriented architecture can be exploited for the implementation of data mining in distributed environments [18,19].
Data privacy and security:Automated data mining in
distributed environments raises serious issues in terms of data privacy, security, and governance. Various algorithms have been modified so as to retain privacy in distributed environment.[37,38,39,40].
E. Distributed data mining algorithms
With fast growing business intelligence market, exponential increase in the amount of data and distributed locations of data, there has raised a requirement of distributed data mining. The distribution may be either of computation or of data.
For distributing the mining task, any one of two strategies can be used: i. Message passing among nodes
or processors: Nodes in a distributed system
communicate via messages.
This method requires lot of synchronization
overheads. ii. Centralized ensemble methods: This method generates local models and transmits them to a central site (asynchronously). The central site forms a combined global model. These methods require only a single round of message passing, resulting in modest synchronization requirements [41].
First, we present different distributed data mining techniques proposed by researchers that have helped in enhancing performance of basic data mining techniques. We included association rules, classification and clustering in our study.
Distributed Association Rules:
Association rule mining has been studied intensively in last 20 years. Hundreds of algorithms are proposed till date but the recent focus is on mining association rules in a distributed fashion. A-priori, pincer-search, FP- Tree growth algorithms have been implemented in different ways using different data structures. Moving toward distributed approach, researchers have tried to parallelize existing algorithms and proposed CD-Count distribution, FDM-Fast distributed algorithm, FPM-Frequent pattern mining and DDM-Distributed data mining.
Later, the researchers started optimizing the ARM algorithms by using hybrid methods. Assaf Schuster, Ran Wolff, Dan Trock used a combination of sampling & storing in vertical trie data structure and further mined this data structure using DDM method[42].
A Tree based Algorithm for Generating of Frequent Item Sets was also proposed which uses Pattern Count Tree for representing the database. [44].
A parallel algorithm for data mining of association rules on shared-memory multiprocessors was tested for optimizations of fast frequency computation. Degree of parallelism, synchronization, and data locality issues have also been discussed for shared memory systems [46].
D-ARM algorithm [47] proposed by Assaf Schuster outperformed on a number of computing nodes with less communication cost.
Distributed Classification Algorithms:
Standard classification algorithms include C4.5, ID3, SLIQ and SPRINT. Many researchers have put efforts on parallel implementation of these algorithms [48].
An algorithm for classification on multi relational data with handling of missing values and less communication cost have been proposed by Anna Atramentov [49].
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459,ISO 9001:2008 Certified Journal, Volume 4, Issue 3, March 2014)In distributed environment, data is distributed and every data server has a partial set of the data. A classification algorithm for vertically partitioned data assumes that local classifiers can be constructed locally. These local classifiers can be used to support decision making at each location. Global classifier can then be constructed having access to the entire feature set [51].
Distributed Clustering Algorithms:
S. Datta, C. Giannella, and H. Kargupta [52] presented K Means algorithm for clustering on large data distributed over dynamic network. This algorithm is robust to network change and does not require global synchronization. It is based upon local synchronization.
S. Bandyopadhyay, C. Giannella, U. Maulik, H. Kargupta , K. Liu, and S. Datta[53] described a technique for clustering homogeneously distributed data in a peer-to-peer environment. The proposed technique is based on the principles of the K-Means algorithm. In this technique, the neighbouring nodes communicate in a localized asynchronous manner.
Clustering process can be optimised by sending best representatives to a server site. The process can be very efficient, because determining local representatives can be carried out quickly and independently from each other. Based on the most suitable local representatives, global clustering can be done efficiently [54, 55]. A novel distributed clustering algorithm KDEC uses Sampling based methods for non-parametric kernel density estimation on local sites. It also takes into account the issues of privacy and communication costs that arise in a distributed environment [56].
F. Data Mining in Distributed Computing Environments
PEER to PEER systems:
Idea behind peer to peer computing is to create a group of computers connected together to combine their computing and processing abilities to solve complex problems. Each computer has equal capability. This architecture is widely used for enormous data storage, scientific computations and data analytics.
DDM applications and algorithms for Peer to per environments, are described by Datta and Souptik where both exact and approximate local P2P data mining algorithms work in a decentralized and communication-efficient manner[57].
Wolff, Ran, and Assaf Schuster proposed an Association rule mining in peer-to-peer systems[58]. They presented an algorithm by which every node in the system can find about equal confidence level though they work on data partitions.
Schuster, Assaf, and Ran Wolff [59] also presented a set of new algorithms that solve the Distributed
A K-Means based P2P mining technique [60] for clustering homogeneously distributed data works by communicating with the neighbouring nodes in asynchronous manner. The work also offers theoretical analysis of the algorithm that bounds the error in the distributed clustering process compared to the centralized approach.
New cast model of computation is used by Wojtek Kowalczyk, Mark Jelasity, and A.E. Eiben efficiently mines data over P2P overlay networks [61].
GRIDS:
GRID consists of many tightly coupled perhaps geographically distributed heterogeneous computers which are made to work together on either single or related problems. Grids are required by professional communities who need to access remote resources, distributed datasets, and for large scale data analyses. Grid can play a significant role in providing an effective computational support for distributed data mining applications.
Cannataro M, Congiusta A, Pugliese A, Talia D, Trunfio P. [62]designed a system called Knowledge Grid. Their work describes the Knowledge Grid framework and presents the toolset provided by the Knowledge Grid for implementing distributed data mining on GRID.
A three layered architecture called Data Mining Grid system was proposed to enable creation of grids dedicated to data mining tasks [67].Globus toolkit 4 is used as a middleware between upper and lower layers.
Grid can offer an infrastructure for supporting decentralized and parallel data analysis. Service oriented grid computing can allow the end-users to focus on the knowledge discovery process without worrying about the details of grid infrastructure [68]. Data mining services on grids can now be accesses through web services also [69].
A system called KNOWLEDGE GRID framework presents the toolset provided implementing distributed knowledge discovery. Tool provides the facility of starting from searching grid resources, and then finally executing the resulting data mining process on a grid [70].
Intra Grid based data mining tool DMGCE is developed with the use of competitive directed acyclic graphs in a heterogeneous computing environment. It works on a dynamic scheduling framework. In this framework, reuse of existing DM algorithms is achieved by encapsulating them into agents [71].
CLUSTERS:
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459,ISO 9001:2008 Certified Journal, Volume 4, Issue 3, March 2014)Computers in a cluster works as a single computing resource and are connected by high speed networks. A cluster is a cheaper alternative to a single high performance processor system like super computers. Clusters are ideal for users who need to run similar jobs as in case of data mining.
Tree data structure is generally used to compress database. Such tree structures can be efficiently mined using frequent pattern growth methodology. PC cluster based framework can be used for tree mining resulting in improved support counting procedure [72]. However there is a problem when FP-tree cannot fit into the memory. A parallel execution of FP-growth using PC Cluster is implemented for execution efficiency on shared-nothing environment [73]. Performance of FP- Tree decreases with the increase in size of database. For handling this problem a combination of parallel and distributed techniques can be applied. Use of Tid based Parallel FP-tree (TPFP-tree) and Balanced Tid set-based Parallel FP-tree (BTP-tree) for frequent pattern mining on PC Clusters and multi-cluster grids shortens the execution time significantly [74].
Recently, a framework called MATE-CG is proposed that uses a Map Reduce-Like Framework Data-Intensive Computations on a heterogeneous cluster of multi-core CPUs and many-core GPUs [75].
CLOUD:
Cloud is an infrastructure that provides services and
resources through internet. Main services are
Infrastructure as a service IAAS, Platform as a service -PAAS and Software as a service -SAAS. Cloud can be used to utilize virtual resources to perform data and compute intensive analyses. Data mining computations can be optimised using parallel programming paradigms like Hadoop-Mapreduce, CGL-MapReduce, and Dryad. However, many scientific applications still require low latency communication mechanisms by runtimes such as MPI. Different MapReduce implementations of data mining algorithms have been performed on virtualised resources on cloud [76].
To efficiently support many important data mining
algorithms in cloud environment, a distributed
framework called GraphLab is recently proposed. It is graph based extension which is fault tolerant and reduces network congestion [77].
High performance cloud can be used to mine large distributed data sets[78]. Sector is a distributed file system that can be processed by Sphere which is a high performance parallel data processing engine. Sector and Sphere are designed for analyzing large data sets using computer clusters connected with wide area high performance networks A distributed data mining application have been developed using Sector and Sphere.
Data mining on very large datasets can be optimised by using Open source framework called Hadoop. Hadoop – MapReduce is a highly parallel programming paradigm that is used by big shots like Yahoo, Facebook, Ebay, Twitter and many more.
Future Scope in Distributed Data mining:
We have discussed several issues related to distributed data mining. After carefully examining the current trends, we propose that data mining techniques in near future will be oriented towards following areas:
i. Use of Hadoop Mapreduce for large sized
data[81,82]. Hadoop Distributed file system automatically handles scalability and fault tolerant issues.
ii.Combining ETL tools like Mahout,
Sqoop, Flume and Mongo-Hadoop Connector, we can mine NoSQL Big databases[83].
iii. CUDA a highly parallel programming language that is designed for GPU can run within Mapreduce for further improving efficiency of mining compute-intensive tasks over petabytes of data[84]. iv.Use of G-Hadoop with G-Farm file system, a
MapReduce framework that can be used for large-scale distributed computing on distributed data [85]. v.Cloud based techniques for data mining are almost unexplored so there is lot of scope in this direction.
III. CONCLUSION
Data mining has become more relevant today with the increase in the amount of data generated every minute. With issues like increase in size, data distribution, unstructured data, cleaning and pre-processing and is an open challenge. Data mining techniques can be speeded up by proper combination of parallel and distributed approaches. As data floats on network in distributed systems, privacy preservation techniques are mandatory to be applied on every DDM technique. In distributed scenario, we can get better performance in terms of memory utilization and speedup if there is utilization of proper blend of resources.
Lot of advancements in the field of data mining is observed in last decade. Several network and computing related bottlenecks still exist. We have addressed many challenges and recent research areas in the field of distributed data mining. Distributed data mining has to go long way for benefitting scientists, academicians and industries.
REFERENCES AND BIBLIOGRAPHY
[1] Zeng, Li, et al. "Distributed data mining: a survey." Information Technology and Management 13.4 (2012): 403-409.
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459,ISO 9001:2008 Certified Journal, Volume 4, Issue 3, March 2014)[3] R. Agrawal and R. Srikant. Fast algorithms for mining association rules in large databases. In J. B. Bocca, M. Jarke, and C. Zaniolo, editors, VLDB, pages 487–499. Morgan Kaufmann, 1994. [4] P. S. Bradley, U. M. Fayyad, and C. Reina. Scaling clustering
algorithms to large databases. In Proceedings of Knowledge discovery in Data Conference, pages 9–15, 1998.
[5] Chiang D, Lin C, Chen M (2011) The adaptive approach for storage assignment by mining data of warehouse management system for distribution centres. Enterp Inf Syst 5(2):219–234 [6] Duan L, Xu L, Guo F, Lee J, Yan B (2007) A local-density based
spatial clustering algorithm with noise. Inf Syst 32:978–986 [7] Duan L, Xu L, Liu Y, Lee J (2009) Cluster-based outlier
detection. Ann Oper Res 168:151–168
[8] Agrawal R, Srikant R Fast algorithms for mining association rules. In: Proceedings of the 20th VLDB conference 1994, pp487– 499
[9] Ahmed S, Coenen F,Leng PH Tree-based partitioning of date for association rule mining. 2006KnowlInfSyst 10(3):315–331 [10] Banerjee A, Merugu S, Dhillon I, Ghosh J Clustering with
Bregman divergences. J Mach Learn Res6 2005 :1705–1749 [11] Wilford-Rivera, Ingrid, et al. "Integrating Data Mining Models
from Distributed Data Sources." Distributed Computing and Artificial Intelligence. Springer Berlin Heidelberg, 2010. 389-396. [12] http:// www.sas.com/ en_us/ insights/ big-data/
[13] Lämmel, Ralf. "Google’s MapReduce programming model— Revisited." Science of computer programming 70.1 (2008): 1-30. [14] Blumberg, Robert, and Shaku Atre. "The problem with
unstructured data." DM REVIEW 13 (2003): 42-49.
[15] Han, Jing, et al. "Survey on NoSQL database." Pervasive computing and applications (ICPCA), 2011 6th international conference on. IEEE, 2011.
[16] Andrade, Diego, et al. "Task-parallel versus data-parallel library-based programming in multicore systems." Parallel, Distributed and Network-based Processing, 2009 17th Euromicro International Conference on. IEEE, 2009.
[17] Shim, Kyuseok. "MapReduce algorithms for Big Data analysis." Proceedings of the VLDB Endowment 5.12 (2012): 2016-2017. [18] Talia, Domenico, Paolo Trunfio, and Oreste Verta. "Weka4ws: a
wsrf-enabled weka toolkit for distributed data mining on grids."
Knowledge Discovery in Databases: PKDD 2005. Springer Berlin
Heidelberg, 2005. 309-320.
[19] Talia, Domenico, Paolo Trunfio, and Oreste Verta. "The Weka4WS framework for distributed data mining in service‐oriented Grids." Concurrency and Computation: Practice
and Experience 20.16 (2008): 1933-1951.
[20] Pujari, Arun K. Data mining techniques. Universities press, 2001. [21] Han, Jiawei, Micheline Kamber, and Jian Pei. Data mining:
concepts and techniques. Morgan kaufmann, 2006.
[22] Piatetsky-Shapiro, Gregory, et al. "What are the grand challenges for data mining?: KDD-2006 panel report." ACM SIGKDD Explorations Newsletter 8.2 (2006): 70-77.
[23] Nickolls, John, et al. "Scalable parallel programming with CUDA." Queue 6.2 (2008): 40-53.
[24] Anuradha, T., R. Satya Pasad, and S. N. Tirumalarao. "Parallelizing Apriori on Dual Core using OpenMP." International Journal of Computer Applications 43 (2012).
[25] http://www.cs.ucla.edu/~palsberg/course/cs239/papers/EECS-2006-183.pdf
[26] Zaki, Mohammed Javeed, et al. "New Algorithms for Fast Discovery of Association Rules." KDD. Vol. 97. 1997.
[28] Zaïane, Osmar R., Mohammad El-Hajj, and Paul Lu. "Fast parallel association rule mining without candidacy generation." Data Mining, 2001. ICDM 2001, Proceedings IEEE International Conference on. IEEE, 2001.
[29] Zaki, Mohammed Javeed, Ching-Tien Ho, and Rakesh Agrawal. "Parallel classification for data mining on shared-memory multiprocessors." Data Engineering, 1999. Proceedings., 15th International Conference on. IEEE, 1999.
[30] Huang, Zhexue. "A Fast Clustering Algorithm to Cluster Very Large Categorical Data Sets in Data Mining." DMKD. 1997. [31] Kwok, Terence, et al. "Parallel fuzzy c-means clustering for large
data sets." Euro-Par 2002 Parallel Processing. Springer Berlin Heidelberg, 2002. 365-374.
[32] Foti, D., et al. "Scalable parallel clustering for data mining on multicomputers." Parallel and Distributed Processing. Springer Berlin Heidelberg, 2000. 390-398.
[33] Goil, Sanjay, and Alok Choudhary. "PARSIMONY: An infrastructure for parallel multidimensional analysis and data mining." Journal of parallel and distributed computing 61.3 (2001): 285-321.
[34] Du, Wenliang, and Zhijun Zhan. "Building decision tree classifier on private data." Proceedings of the IEEE international conference on Privacy, security and data mining-Volume 14. Australian Computer Society, Inc., 2002.
[35] Du, Wenliang, Yunghsiang S. Han, and Shigang Chen. "Privacy-Preserving Multivariate Statistical Analysis: Linear Regression and Classification." SDM. Vol. 4. 2004.
[36] Zhan, Zhijun, and Wenliang Du. "Privacy-Preserving Data Mining Using Multi-Group Randomized Response Techniques." Group 1.2 (2010): 3.
[37] Kiran, P., and N. P. Kavya. "A Survey on Methods, Attacks and Metric for Privacy Preserving Data Publishing." International Journal of Computer Applications 53 (2012).
[38] Han, Jiawei, Micheline Kamber, and Jian Pei. Data mining: concepts and techniques. Morgan kaufmann, 2006.
[39] Schuster, Assaf, Ran Wolff, and Dan Trock. "A high-performance distributed algorithm for mining association rules." Knowledge and Information Systems 7.4 (2005): 458-475.
[40] Agarwal, Ramesh C., Charu C. Aggarwal, and V. V. V. Prasad. "A tree projection algorithm for generation of frequent item sets." Journal of parallel and Distributed Computing 61.3 (2001): 350-371.
[41] Ananthanarayana, V. S., D. K. Subramanian, and M. Narasimha Murty. "Scalable, distributed and dynamic mining of association rules." High Performance Computing—HiPC 2000. Springer Berlin Heidelberg, 2000. 559-566.
[42] Nestorov, S. "Mining Qualified Association Rules in Distributed Databases." Work-shop on Data Mining and Exploration Middleware for Distributed and Grid Computing, Minneapolis, MINI (2003).
[43] Parthasarathy, Srinivasan, et al. "Parallel data mining for association rules on shared-memory systems." Knowledge and Information Systems 3.1 (2001): 1-29.
[44] Schuster, Assaf, Ran Wolff, and Dan Trock. "A high-performance distributed algorithm for mining association rules." Knowledge and Information Systems 7.4 (2005): 458-475.
[45] Amado, Nuno, Joao Gama, and Fernando Silva. "Exploiting Parallelism in Decision Tree Induction." Proceedings from the ECML/PKDD Workshop on Parallel and Distributed computing for Machine Learning. 2003.
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459,ISO 9001:2008 Certified Journal, Volume 4, Issue 3, March 2014)[47] Bar-Or, Amir, et al. "Hierarchical decision tree induction in distributed genomic databases." Knowledge and Data Engineering, IEEE Transactions on 17.8 (2005): 1138-1151. [48] Basak, Jayanta, and Ravi Kothari. "A classification paradigm for
distributed vertically partitioned data." Neural computation 16.7 (2004): 1525-1544.
[49] S. Datta, C. Giannella, and H. Kargupta. K-Means Clustering over a Large, Dynamic Network. In Proceedings of 2006 SIAM Conference on Data Mining, Bethesda, MD, April 2006. [50] K.HammoudaandM .Kamel. HP2PC: Scalable Hierarchically
Distributed Peer-to-Peer Clustering. In Proceedings of the 2007 SIAM International Conference on Data Mining (SDM ’07), Philadelphia, PA, 2007.
[51] Klusch, Matthias, Stefano Lodi, and Gianluca Moro. "Distributed clustering based on sampling local density estimates." IJCAI. 2003.
[52] Januzaj, Eshref, Hans-Peter Kriegel, and Martin Pfeifle. "Scalable density-based distributed clustering." Knowledge Discovery in Databases: PKDD 2004. Springer Berlin Heidelberg, 2004. 231-244.
[53] Klusch, Matthias, Stefano Lodi, and Gianluca Moro. "Distributed clustering based on sampling local density estimates." IJCAI. 2003.
[54] Datta, Souptik, et al. "Distributed data mining in peer-to-peer networks." Internet Computing, IEEE 10.4 (2006): 18-26. [55] Wolff, Ran, and Assaf Schuster. "Association rule mining in
peer-to-peer systems." Systems, Man, and Cybernetics, Part B: Cybernetics, IEEE Transactions on 34.6 (2004): 2426-2438. [56] Schuster, Assaf, and Ran Wolff. "Communication-efficient
distributed mining of association rules." Data Mining and Knowledge Discovery 8.2 (2004): 171-196.
[57] Bandyopadhyay, Sanghamitra, et al. "Clustering distributed data streams in peer-to-peer environments." Information Sciences 176.14 (2006): 1952-1985.
[58] Kowalczyk, Wojtek, Márk Jelasity, and A. Eiben. "Towards data mining in large and fully distributed peer-to-peer overlay networks." Proceedings of BNAIC’03. 2003.
[59] Cannataro M, Congiusta A, Pugliese A, Talia D, Trunfio P.‖Distributed data mining on grids: services, tools, and applications‖. IEEE Trans Syst Man Cybern B Cybern. 2004 Dec;34(6):2451-65.
[60] Jin, Ruoming, Ge Yang, and Gagan Agrawal. "Shared memory parallelization of data mining algorithms: Techniques, programming interface, and performance." Knowledge and Data Engineering, IEEE Transactions on 17.1 (2005): 71-89.
[61] K. Bhaduri, R. Wolf, C. Giannella, and H. Kargupta. Distributed decision-tree induction in peer-to-peer systems. Stat. Anal. Data Min., 1(2):85–103, 2008.
[62] P.Luo,H.Xiong,K.Lu,andZ.Shi. distributed Classification inPeer-to-PeerNetworks. In Proceedings of the 13th International Conference on Knowledge Discovery and Data Mining (KDD ’07), pages 968–976, New York NY, 2007.
[63] Stankovski, Vlado, et al. "Grid-enabling data mining applications with DataMiningGrid: An architectural perspective." Future Generation Computer Systems 24.4 (2008): 259-279.
[64] María S. Pérez, Alberto Sánchez, Víctor Robles, Pilar Herrero, José M. Peña ―Design and implementation of a data mining grid-aware architecture‖ Future Generation Computer Systems, Volume 23, Issue 1, 1 January 2007, Pages 42–47
[65] Antonio Congiusta, Domenico Talia, Paolo Trunfio ‖ Service-oriented middleware for distributed data mining on the grid‖ Journal of Parallel and Distributed Computing, Volume 68, Issue 1, January 2008, Pages 3–15
[66] Richard Olejnik, Teodor-Florin Fortiş, Bernard Toursel ―Web services oriented data mining in knowledge architecture‖ Future Generation Computer Systems, Volume 25, Issue 4, April 2009, Pages 436–443
[67] Cannataro, Mario, et al. "Distributed data mining on grids: services, tools, and applications." Systems, Man, and Cybernetics, Part B: Cybernetics, IEEE Transactions on 34.6 (2004): 2451-2465.
[68] Luo, Ping, et al. "Distributed data mining in grid computing environments." Future Generation Computer Systems 23.1 (2007): 84-91.
[69] Pramudiono, Iko, and Masaru Kitsuregawa. "Tree structure based parallel frequent pattern mining on pc cluster." Database and Expert Systems Applications. Springer Berlin Heidelberg, 2003. [70] Pramudiono, Iko, and Masaru Kitsuregawa. "Parallel FP-growth
on PC cluster." Advances in Knowledge Discovery and Data Mining. Springer Berlin Heidelberg, 2003. 467-473.
[71] Yu, Kun-Ming, and Jiayi Zhou. "Parallel TID-based frequent pattern mining algorithm on a PC Cluster and grid computing system." Expert Systems with Applications 37.3 (2010): 2486-2494.
[72] Jiang, Wei, and Gagan Agrawal. "Mate-cg: A map reduce-like framework for accelerating data-intensive computations on heterogeneous clusters." Parallel & Distributed Processing Symposium (IPDPS), 2012 IEEE 26th International. IEEE, 2012. [73] Ekanayake, Jaliya, and Geoffrey Fox. "High performance parallel
computing with clouds and cloud technologies." Cloud Computing. Springer Berlin Heidelberg, 2010. 20-38.
[74] Low, Yucheng, et al. "Distributed GraphLab: a framework for machine learning and data mining in the cloud." Proceedings of the VLDB Endowment 5.8 (2012): 716-727.
[75] Grossman, Robert, and Yunhong Gu. "Data mining using high performance data clouds: experimental studies using sector and sphere." Proceedings of the 14th ACM SIGKDD international conference on Knowledge discovery and data mining. ACM, 2008.
[76] Linchuan Chen, Xin Huo , and Gagan Agrawal . ―Accelerating MapReduce on a coupled CPU - GPU architecture‖. In Proceedings of the International Conference on High Performance Computing, Networking, Storage and Analysis, SC ’12, pages 25:11, Los Alamitos, CA, USA, 2012. IEEE Computer Society Press.
[77] J.A. Stuart and J.D. Owens. ―Multi GPU MapReduce on GPU Clusters‖. In Parallel Distributed Processing Symposium (IPDPS), 2011 IEEE International, pages 1068 1079, may 2011.
[78] C. Ranger, R. Raghuraman, A. Penmetsa, G. Bradski, and C. Kozyrakis. Evaluating mapreduce for multi-core and multiprocessor systems. In HPCA ’07: proceedings of the 2007 IEEE 13th International Symposium on High Performance Computer Architecture, pages 13–24, Washington, DC, USA, 2007. IEEE Computer Society.
[79] Jeffrey Dean and Sanjay Ghemawat. ― MapReduce: simplified data processing on large clusters‖. Commun. ACM, 51(1):107– 113, January 2008.
[80] Hadoop. http://hadoop.apache.org/
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459,ISO 9001:2008 Certified Journal, Volume 4, Issue 3, March 2014)[82] F. Ahmad, S. T. Chakradhar, A. Raghunathan, and T. N. Vijaykumar. Tarazu: optimizing mapreduce on heterogeneous clusters. In Proceedings of the seventeenth international conference on Architectural Support for Programming Languages and Operating Systems, ASPLOS ’12, pages 6174, New York, NY, USA, 2012. ACM