2016 Joint International Conference on Artificial Intelligence and Computer Engineering (AICE 2016) and International Conference on Network and Communication Security (NCS 2016)
ISBN: 978-1-60595-362-5
Short Text Classification Based on Latent Topic
Modeling and Word Embedding
Peng LI
1,a, Jun-Qing HE
2,b,*, Cheng-Long MA
2,c1National Computer Network Emergency Response Technical Team/
Coordination Center of China, Beijing, China
2Institute of Acoustics, Chinese Academy of Science, Beijing, China
a[email protected], b[email protected], c[email protected]
*Corresponding author
Keywords: Short Text, Text Classification, Semantic Representation, Topic Model, Word Embedding.
Abstract. With the rapid development of the social network and e-commerce, we are exposed to
enormous short text every day, ranging from twitters, movie comments, search snippets to news summaries. To classify the short and sparse text accurately is always the basic need for us to deal with information efficiently. However, previous methods fail to achieve high performance due to the sparseness and meaningless of the representation of text. The key breakout lies on the appropriate representation of the words, on which we excogitate a new framework. By discovering the latent topics in the related data crawled from the web, topic distribution can describe the text content in general. Combining with the word embedding generated from the online universal data, the proposed method is a more dense representation, containing semantic information from two different aspects. With this semantic representation of the texts, this framework greatly outperform the previous methods even using the most common SVM classifier, improving the accuracy by 11.58% on standard data set.
Introduction
Classification is a mature field in machine learning, with many methods have been proposed by great minds, such as k-nearest neighbors (kNN), Naive Bayes, Bernouli Bayes, Decision Tree, maximum entropy, Random forest and support vector machines (SVMs). With the development of parallel processing, deep neural networks (DNN), convolutional neural networks (CNN) and recurrent neural networks (RNN) are used to classify large scale of data. Some of these methods are proved of to be useful in long text classifications in certain data sets [1]. However, this conventional classifiers turn pale when dealing with short text by using traditional representations such as bag of words (BOW), term frequency (TF) and term frequency-inverse document frequency (TF-IDF).
What is the reason for the unsatisfied performance? The secret lies on the feature selection of the short text and the lack of training corpus. For the intrinsic reason, the short texts have been transformed to long and sparse vectors when using BOW representation, which drastically decrease the performance of the classifiers. Many methods are studied to reduce the dimensions of the representations like SVD, PCA and so on. But they just make a dimension reduction in a mathematical way, ignoring the semantic importance of different words in a sentence. So only the reasonable representations of texts can make magnificent improvement in short text classification.
In addition, topic model is another way to encode the intention of the sentences, while making the representations dense. Topic model is to describe a topic by the distribution of related words and suppose that each word in a document is generated by a topic-word distribution under a topic, which is generated by a document-topic distribution given a certain topic. Here we use recently successful latent topic analysis model, the LDA [4] to model the topics. We can obtain the topic distributions for each document and use it as a representation of the document. Research has been proved that this method can make a positive difference for short text classification [5, 6].
To overcome the corpus problem, one way is to expand and enrich the context of data using web resources via search engines [7, 8, 9]. They obtain several results through search engines (e.g. Google) and compute similarity scores to decide which they should employ. However, it is unrealistic to query the search engine for each document for the great amount of documents, which is expensive. Another way is to utilize online data repositories, such as Wikipedia [16] and ODP [17], as external knowledge sources [10, 11]. This method is more useful and practical.
In our framework, we first employ pre-trained word2vec models to represent each word in a document and express the document in the vector space using the word vectors. Secondly we do latent topic discovery for online resource which we scratched from Wikipedia and inference the latent topics of datasets. Merging the topic information into the word vectors, finally we use the most popular and ordinary SVM as classifier.
Related Work
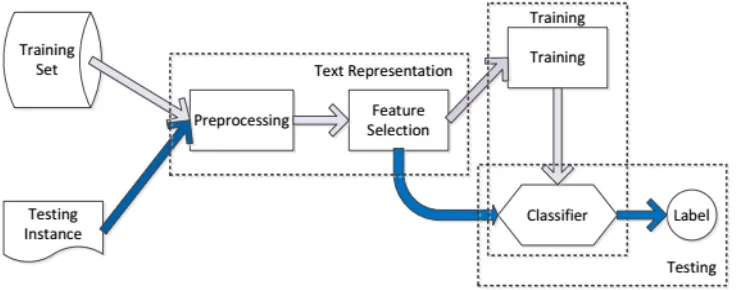
[image:2.612.125.494.410.555.2]Text classification is commonly defined simply as follow (Fig.1) [22]: Given a set of documents D and a set of categories (or labels) C, we define a function F that will assign a value from the set of C to each document in D. In this task, we have a training set with labels and a test set without labels. Our goal is to decide the category of each document in test set by training the function F with training set’s features.
Figure 1. General procudure of text classification.
The General Framework
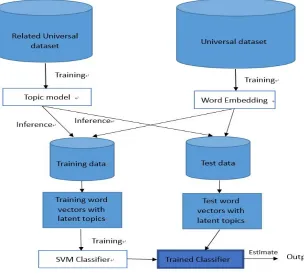
[image:3.612.152.456.208.482.2]The general framework of our system is as follow (Fig.2). Aiming to make use of the abundant external online resources, we crawled some data-related corpus from the Wikipedia as Related Universal corpus. It is an impressive resolution to the data shortage and make the subsequent models more objective and precise. Then we discovered the latent topics of the related universal dataset with LDA and gained topic models, by which we can inference the topics of the training data and test data as topic features. LDA, a generative graphical model, is the best in latent topic analysis since 2008. Meanwhile, we use various word embeddings pre-trained from online big data such as Google News, Wikipedia to represent the documents. After combining the topic features, a SVM classifier was fine tuned to estimate the labels of test data.
Figure 2. The framework of our proposal.
LDA Topic Model
The LDA model is clearly defined in [4], and have been explained in detailed in [5, 6]. Massive Data Collection
Wikipedia is characterized by its wide coverage of all kinds of fields. So it is wise to serve it as universal knowledge base in our task. First we obtain the whole wiki data via wiki dump [18]. Then we do some preprocessing, deleting the non-roman characters and MediaWiki markups. In our experiment, we indexed related knowledge by searching content involved with the training data, using Lucene [19]. The indexed corpus extracted from Wikipedia data form our related universal dataset.
Feature Generation
Experiments Data Preparation
Related Universal Dataset. Wikipedia dataset is available in [18]. We dump the English data of
the 8th, Oct, 2014 version and preprocessed the data by cutting off the noisy input. Then Lucene was used to index the wiki data related to our training data. Finally we transfer the data into the format that suitable for LDA modeling. The data is 5.4G at last.
Word embedding. Various kinds of pre-trained word embedding was used with different training
method and different web resources, such as Wikipedia and Google News. With wiki_vector_100, wiki_vector_300, wiki_vector_400 and google_300 trained by word2vec, glove_50 by Glove, senna_50 by SENNA, we can evaluate the performance of this word embeddings and find the most suitable one. The number above means the dimension of the vectors.
Search Snippets. Search snippets contains three parts: a URL, a short title and a short text
[image:4.612.191.424.318.456.2]description. We only interested in the title and description. For each query phrase put into Google search engine, the top 20 or 30 ranked web search snippets were collected. Then the class label of the collected search snippets was assigned as the phrase. Some basic statistics of both the corpus and the search snippets are summarized in Table 1. Here we use the search snippets the same as in [5].
Table 1. Detailed statisics of search snippets.
Domain Train data Test data
Business 1200 300
Computer 1200 300
Culture-Arts-Ent 1880 330
Education-Science 2360 300
Engineering 220 150
Health 880 300
Politics-Society 1200 300
Sports 1120 300
Total 10060 2280
Implementation
Here we use genism [24] to generate the latent topic models of related universal dataset, and SVM as classifier, conducted 3 experiments in total: (a) The baseline of only use topic features with different topic number from 20 to 200 as [5]; (b) Only use word embedding as representation with the five different word embedding mentioned above; (c) Combine topic features and word embedding with different topic number under the best word embedding.
Experimental Results
The experimental result of (a) is as Table 2, from which we can see the best result is 74.21%.
Table 2. Only use topic features.
Topic number 20 30 40 50 60 70 80 90 100 110
Accuracy[%] 71.32 69.56 68.86 72.46 70.22 74.04 70.22 73.95 68.64 74.21
Topic number 120 130 140 150 160 170 180 190 200
Table 3. Result of different word embeddings.
Word embeddings Accuracy[%]
glove_50 81.52
google_300 81.47
senna_50 76.17
wiki_50 78.67
wiki_100 80.11
wiki_300 82.26
wiki_400 81.74
The result of experiment (b) is as Table 3, the best result reached the 82.26% of accuracy, outperforms the best result of (a).
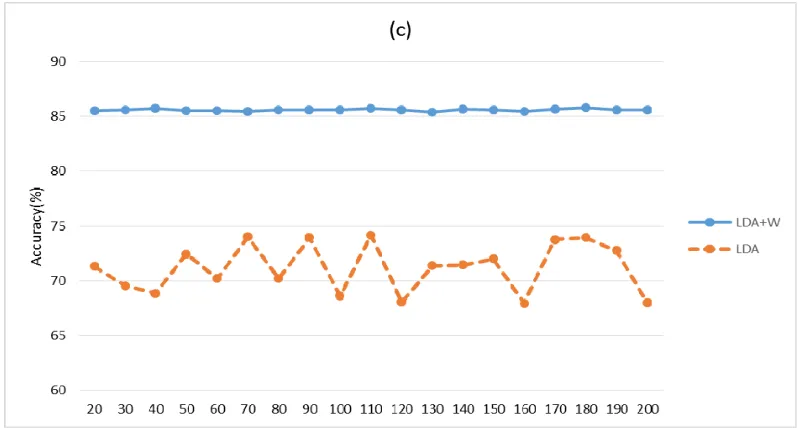
Figure 3. Results with different topic number when using wiki_300 and iteration=500.
The (Fig.3) illustrates the results changed with the topic number. The LDA+W means LDA with Word Embedding. When the topic number is 180, reach the highest accuracy of 85.79%, 3.54% better than pure word embedding (b), gained an impressive 11.58% improvement compared with baseline (a). The clear result compare is listed as Table 4.
Table 4. Best results using different algorithms.
Features Accuracy[%]
Baseline(LDA) 74.21
Word embedding 82.26
LDA+Word embedding 85.79
Summary
[image:5.612.187.423.582.639.2]Therefore, this semantic representation combined with topic features can better express the meaning of documents and extract the distinguishing features of text.
However, there is much space to improve in short text classification. Our framework can be further enhance since it rely too much on the universal resource. The relativeness between training data and the universal corpus we crawled is pivotal to a great extent.
Acknowledgement
This work is partially supported by the National Natural Science Foundation of China (Nos. 11461141004, 61271426, 11504406, 11590770, 11590771, 11590772, 11590773, 11590774).
References
[1] Y. Kim. Convolutional Neural Networks for Sentence Classification, C. EMNLP, 2014. [2] T. Mikolov, K. Chen, G. Corrado, J. Corrado. Efficient Estimation of Word Representations in Vector Space, J. CoRR, abs/1301.3781, 2013.
[3] E. Iosif, A. Potamianos. Unsupervised Semantic Similarity Computation between Terms Using Web Documents, C. IEEE Transations on knowledge and data engineering , 2010.
[4] D. Blei, A. Ng, and M. Jordan. Latent Dirichlet Allocation, J.JMLR, 3: 993–1022, 2003.
[5] X. Phan, L. Nguyen, S. Horiguchi. Learning to Classify Short and Sparse Text & Web with Hidden Topics from Large-scale Data Collections, C. IW3C2, 2008.
[6] M. Chen, X. Jin, D. Shen. Short Text Classification Improved by Learning Multi-Granularity Topics, C. Proceedings of the Twenty-Second International Joint Conference on Artificial Intelligence, 2011.
[7] K.Kim. Chung, B. Chung, Y.Choi, S.Lee, J. Jung, J.Park. Language independent semantic kernels for short-text classification, J. Expert Systems with Applications, 1(2)735-743, 2012.
[8] D. Song, P.D. Bruza, Z. Huang et al. Classifying Document Titles Based on Information Inference, Proceedings of the14th International Symposium on Methodologies for Intelligent System, pp. 297-306, 2003.
[9] B. Sriram, D. Fuhry, E. Demir, H. Ferhatosmanoglu, M. Demirbas. Short Text Classification in Twitter to Improve Information Filtering, C. Proceeding of the 33rd international ACM SIGIR Conference on Research and Development in Information Retrieval, 2010
[10] S. Zelikovitz. Transductive LSI for Short Text Classification Problems, C. Proceedings of the 17th International Flairs Conference, 2004.
[11] J.M. Cabrera, H.J. Escanlente, M. Montes-y-mez. Distributional term representations for short-text categorization. Distributional Term Representations for Short-text Categorization, 2013 [12] Q. Pu, G. Yang. Short-Text Classification Based on ICA and LSA. Advances in Neural Networks ISNN 2006, pp. 265-270, 2006.
[13]S. Zelikovitz and H. Hirsh. Using LSI for text classification in the presence of background text, C. In Proceedings of 10th International Conference on Information and Knowledge Management, pp. 113-118, 2001
[14] B. Wang, Y. Huang, W. Yang, X. Li. Short text classification based on strong feature thesaurus, J. Journal of Zhejiang University Science C, Vol. 13(9), pp. 649-659, 2012.
[16] Information on http://en.wikipedia.org. [17] Information on http://www.dmoz.org.
[18] Data on https://meta.wikimedia.org/wiki/Data_dump_torrents#enwiki. [19] Information on https://lucene.apache.org/.
[20] Information on http://nlp.stanford.edu/projects/glove/. [21] Information on http://ml.nec-labs.com/senna/.
[22] G.song, Y. Ye, X. Du, et al. Short Text Classification: A Survey, J. Journal of Multimedia. Vol. 9(5), 2014.