International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459,ISO 9001:2008 Certified Journal, Volume 3, Issue 10, October 2013)
236
Missing Value Imputation of Mixed Attribute FCM Clustered
Data Sets Using Higher Order Kernels
Selva Mary. G
1, Prof. Sachin Bojewar
21
PG Scholar, Dept of Computer Engineering, Alamuri Ratnamala Institute of Engineering and Technology, Mumbai University, India
2Asst. Prof., Dept of Computer Engineering, Vidyalankar Institute of Technology, Mumbai University, India
Abstract
—
Data Mining is the efficient discovery of previously unknown, valid, potentially useful, understandable patterns in large datasets. There is a need for quality of data, thus the quality of data is ultimately important. The existing system provides a new setting for missing data imputation, i.e., imputing missing data in data sets with heterogeneous attributes (their independent attributes are of different types), referred to as imputing mixed-attribute data sets. The system provides various estimators to impute the missing data.A mixture-kernel based iterative estimator is advocated to impute mixed-attribute data sets. The proposed system implements the estimators with higher order kernels such as Spherical kernel and Bayesian kernel and a new setting of handling missing data imputation in FCM classified data sets. The estimators are evaluated with extensive experiments compared with some typical algorithms, and the result demonstrates that the proposed approach is better than these existing imputation methods in terms of classification accuracy and root mean square error (RMSE) at different missing ratios.
Keywords- Data mining, Imputation, Missing values, Mixed attributes, Regression
I. INTRODUCTION
Data mining, the extraction of hidden predictive information from large databases, is a powerful new technology with great potential to help companies focus on the most important information in their data warehouses. A common problem in data mining is that of automatically finding outliers or anomalies in a database. Outliers are an observation that is numerically distant from the rest of the data. Since outliers and anomalies are highly unlikely, they can be indicative of bad data or malicious behaviour. Bad data interns produce falls outcome.
Examples of bad data include skewed data values resulting from measurement error, or erroneous values resulting from data entry mistakes, missing values, missing data. Missing data, or Missing values, occur when no data value is stored for the variable in the current observation.
Common solution is either ignore the missing data is called as marginalization or fill in the missing values is called as imputation. Imputed values are treated as just as reliable as the truly observed data, but they are only as good as the assumptions used to create them. Techniques of dealing with missing values can be classified into three categories. 1) Deletion, 2) Learning without handling of missing values, and 3) Missing value imputation The first technique is to simply omit those cases with missing values and only to use the remaining instances to finish the learning assignments .The deletion is classified in two categories they are, i) List wise or Case deletion ii) Pair wise deletion. The second approach is to learn without handling of missing data, such as Bayesian Networks method, Artificial Neural Networks method 15, the methods. Missing data imputation is a procedure that replaces the missing values with some possible values.
A variety of methods have been developed with great success on dealing with missing values in data sets with uniform attributes.(their independent attributes are all either continuous or discrete). However, these imputation algorithms cannot be applied to many real data sets, such as equipment maintenance databases, industrial data sets, and medical databases, because these data sets are often with continuous, discrete and categorical independent attributes. These heterogeneous data sets are referred to as mixed-attribute data sets and their independent attributes are called as mixed independent attributes. It advocates that a missing datum is imputed if and only if there are some complete instances in a small neighbourhood of the missing datum, otherwise, it should not be imputed. Further, a Non parametric iterative estimator is proposed to utilize all the available observed
information, including observed information in
incomplete instances with missing values.
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459,ISO 9001:2008 Certified Journal, Volume 3, Issue 10, October 2013)
237
II. EXISTING SYSTEM
The existing work bring out the new setting of missing data imputation, i.e., imputing missing data in data sets with mixed attributes (their independent attributes are of different types i.e. the datasets consists of both discrete and continuous attributes), referred to as imputing mixed-attribute data sets.
Although many real applications are in this setting, there is no estimator designed for imputing data sets with heterogeneous attributes. It first proposes two reliable estimators for discrete and continuous missing target values, respectively.
Imputing can be taken as a new problem in missing data imputation because there is no estimator designed for imputing missing data in mixed attribute data sets.
III. PROPOSED SYSTEM
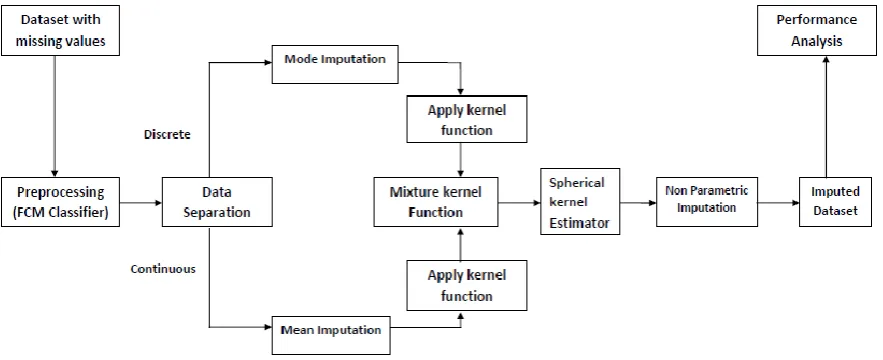
[image:2.595.77.519.305.485.2]The higher order kernel here we propose for value estimation is spherical kernel and Bayesian kernel. These kernels are used to offer the user a large set of functionalities on higher dimensional space. A novel adaptive spherical kernel is utilized for nonlinear regression, and the stage wise optimization algorithm for maximizing Bayesian evidence in Bayesian kernel framework is proposed.
Fig. 1 Proposed System Model
A.Data Preparation
In this module, from the input heterogeneous data set the records with missing values will be identified and categorized based on attribute type of missing values, attributes are grouped. Mean and mode value for continuous and discrete category is calculated separately. Basic imputation has been done with this calculated value.
B.Single Imputation Using Kernel Function
This module shows about the kernel function. After getting the basic imputation, then apply the kernel function separately for both the discrete and continuous attributes. Then integrate both the discrete and kernel function to get the mixture kernel function
a. Discrete Kernel Function
Where
λ - Smoothing parameter
Normally discrete attributes are contains a binary format values example is either it will be 0 or 1.so for this step ,the output will shows about the similar values as the imputation for the missing values by taking one
attribute as a relation.
b. Continuous Kernel Function
K(x - Xi /h)
K(.) is a mercer kernel, i.e., positive definite kernel.
c. Mixture Kernel Function
K h, λ,ix = K(x-Xi/h) L(Xid , xid , λ)
Where, h->0 and λ->0 (λ, h is the smoothing parameter)
Kh,λ,ix - symmetric probability density function.
K(x - Xi /h) - Continuous Kernel Function
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459,ISO 9001:2008 Certified Journal, Volume 3, Issue 10, October 2013)
238
C. Constructing the Estimator and Iterative Imputation
Construct the estimator, separately for both attributes. Estimator is nothing but, it attempts to approximate the unknown parameter using the measurements. Then by the idea of the estimator calculate the iterative value for each attributes by using the formula.
The iterative method explains that all the imputed values are used to impute subsequent missing values, i.e.,
the (t+1)th (t≥1) iteration imputation is carried out based
on the imputed results of the t th imputation, until the filled-in values converge or begin to cycle or satisfy the demands of the users. Normally first imputation is single imputation. It cannot provide valid standard confidence intervals. Therefore running extra (imputation) iterative imputation based on the first imputation is reasonable and necessary for better dealing with the missing values.
D. Pre-Processing Data set using cluster Algorithm
Before sending data to the data preparation module, clustering take place to group similar data object. By applying the formula mentioned below, the data sets are grouped in two sets with respect to every attribute. This clustering process may give a better output than the process without clustering process.
I. Higher Order kernel based estimator
In this work we propose a missing value estimation heterogeneous attributes using higher order kernel named spherical kernel. In this work we estimate the missing value of attribute by using polynomial, RBF, spherical, polynomial and RBF, polynomial and spherical, RBF and spherical kernel combinations. We also implement the Bayesian kernel to obtain a better bandwidth. The experimental results of the missing value imputation are verified.
Finally the nonparametric iterative imputation
algorithm extended from a single kernel to a mixture of kernel is designed and analyzed. Then our proposed system is evaluated and compared with other approaches. Here for the experimental studies we are using a set of data from the real applications and datasets from the UCI repository. From the results it was found that our proposed approach works better than the existing systems.
A research method is presented to obtain the optimal bandwidth for the proposed spherical kernel and Bayesian kernel estimators, instead of the data-driven method. The data imputation is done using all the methods such as Frequency Estimator, Polynomial Kernel, RBF kernel, mixed kernels and the higher order kernels.
The mixed kernel is said to be the linear combination between poly kernel and RBF kernel, gives the extrapolation and interpolation not much better than either a local kernel or a global kernel. It is not mandatory that all the imputed data must be accurate.
Diversified data could also be imputed which are said to be errors. The imputed data methods are calculated for error rates. The higher order kernel method shows the least error rates compared with the other methods.
The proposed method is evaluated with extensive experiments compared with some typical algorithms, and the result demonstrates that the proposed approach is better than these existing imputation methods in terms of classification accuracy and root mean square error (RMSE) at different missing ratios.
Therefore, in this work we advocate to well utilize the information within incomplete instances when estimating missing values
Advantages of the proposed system are:
Use of Higher order kernels (Spherical kernel and
Bayesian Kernel) which provides high accuracy in prediction.
Provides a larger set of functionalities on higher
dimensional space.
Higher order efficient nonparametric iterative
imputation algorithm is designed which imputes the iterative missing target values effectively and accurately.
Faster and accurate imputation.
Achieve better extrapolation and interpolation
abilities in learning algorithms
The error rate of the imputed data using the
proposed system is much lesser than the other methods.
Maximum errors are avoided.
Further, a higher order-kernel-based iterative estimator is proposed to utilizes all available observed information, including observed information in incomplete instances (with missing values), to impute missing values, whereas existing imputation methods use only the observed information in complete instances (without missing values).
To improve the accuracy cluster based non-parametric iterative imputation is proposed. Fig 1 shows that proposed system architecture. It initially considers the database with missing values, and then identifies the attribute type by using appropriate techniques to find attributes of either continuous or discrete attribute.
If it is a continuous attribute Mean Pre-Imputation is applied otherwise Mode Pre-Imputation is applied. This is the basic step of imputation techniques. Then by using the pre imputed data sets kernel function is applied separately to both the attributes. This imputation is said to be single imputation.
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459,ISO 9001:2008 Certified Journal, Volume 3, Issue 10, October 2013)
239
Finally Iterative kernel estimator is applied separately for continuous as well as discrete attributes to get final value for imputation. This data will be imputed in the missing data set to make it as a complete dataset. Further to improve the accuracy clustering algorithm is applied. This clustered data set considered as a first step of the framework.
II. Fuzzy c-means Clustering algorithm
The Algorithm Fuzzy c-means (FCM) is a method of clustering which allows one piece of data to belong to two or more clusters. This method is frequently used in pattern recognition. Fuzzy C-means clustering algorithm is a popular approach for exploring the structure of a set of patterns, especially when the clusters are overlapping or fuzzy.
However, the fuzzy C-means clustering algorithm cannot be applied when the data contain missing values. In many cases, the number of patterns with missing values is so large that if these patterns are removed, then the number of patterns to characterize the data set is insufficient. This paper proposes a technique to exploit the information provided by the patterns with the missing values so that the clustering results are enhanced. There are various pre-processing methods to substitute the missing values before clustering the data. However, instead of repairing the data set at the beginning, the repairing can be carried out incrementally in each iteration based on the context. It is thus more likely that less uncertainty is added while incorporating the repair work. Fine-tuning the missing values using the information from other attributes further consolidates this scheme. Applications of the proposed method in medical domain have produced good performance.
The algorithm is composed of the following steps:
1. Initialize U=[uij] matrix, U(0)
2. At k-step: calculate the centers vectors C(k)=[cj]
with U(k)
3. Update U(k) , U(k+1)
4. If || U(k+1) - U(k)||< STOP. Otherwise return to
step 2.
The clustering algorithm, which is derived from the generalized FCM and the iteratively reweighted least square (IRLS) technique, is applied to a post-supervised classifier. Cluster memberships are defined by a function of Mahalanobis distances between data vectors and cluster centroids. The algorithm is called FCM classifier.
Advantages
Gives best result for overlapped data set and
comparatively better then k-means algorithm.
Unlike k-means where data point must exclusively
belong to one cluster center here data point is assigned membership to each cluster center as a result of which data point may belong to more than one cluster center.
Disadvantages
Apriori specification of the number of clusters.
With lower value of β we get the better result but at
the expense of more number of iteration.
Euclidean distance measures can unequally weight
underlying factors.
IV. CONCLUSION
In this paper we can conclude that we can use Fuzzy C means algorithm for better result. Even though Fuzzy C means takes more computation time, we can still use this algorithm where mixed data types (Discrete and Continuous) involved and when we need better accuracy. Since fuzzy C- Means gives better result in Mixed attributes data sets.
Also, we apply the higher order kernel based estimator for both discrete as well as the continuous data clustered sets to get the better accuracy. Estimated value is calculated by the standard formulas. Finally Iterative kernel estimator is applied separately for continuous as well as discrete attributes to get final value for imputation.
REFERENCES
[1 ] Xiaofeng Zhu, Shichao Zhang Senior Member,
IEEE,(2011)“Missing Value Estimation for Mixed Attribute Data Sets” , IEEE Transactions on Knowledge and Data Engineering, vol.23,No.1.2011
[2 ] Ana S. Lukic, Miles N. Wernick,Dimitris G. Tzikas, Xu Chen, AristidisLikas, Nikolas P. Galatsanos, YongyiYang, Fuqiang Zhao and Stephen C.Strother, “Bayesian Kernel Methods for Analysis of Functional Neuro images”, IEEE Transactions On Medical Imaging, Vol. 26, No. 12,December 2007.
[3 ] Dimitris G. Tzikas, Aristidis C. Likas,and Nikolaos P. Galatsanos, “Sparse Bayesian Modeling with AdaptiveKernel Learning”, IEEE TransactionsOn Neural Networks, Vol. 20, No. 6,June 2009
[4 ] Hyun-Chul Kim and ZoubinGhahramani, “Bayesian
GaussianProcess Classification with the EM-EPAlgorithm”, IEEE Transactions OnPattern Analysis And MachineIntelligence, Vol. 28, No. 12,December 2006
[5 ] Klaus-Robert Müller, Sebastian Mika, Gunnar Rätsch, Koji Tsuda, and Bernhard Schölkopf, “An Introduction to Kernel-Based Learning Algorithms”, IEEE Transactions On Neural Networks, Vol. 12, No. 2,March 2001
[6 ] C. Blake and C. Merz UCI Repositoryof Machine Learning Data base, http://www.ics.uci.edu/~mlearn/MLResoesitory.html, 1998. [7 ] Dempster, N.M. Laird, and D. Rubin, “Maximum Likelihood
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459,ISO 9001:2008 Certified Journal, Volume 3, Issue 10, October 2013)
240
[8 ] J. Racine and Q. Li, “Nonparametric Estimation of Regression Functions with Both Categorical and Continuous Data,” J. Econometrics, vol. 119, no. 1, pp. 99-130, 2004.
[9 ] Y.S. Qin et al., “Semi-Parametric Optimization for Missing Data Imputation,” Applied Intelligence, vol. 21, no. 1, pp. 79-88, 2007. [10 ] M. Alirera, “A Novel Framework for Imputations of Missing
Values in Databases,” IEEE Transactions Vol 37,No. 5, 2007. [11 ] R. Caruana, “A Non-Parametric EM-Style Algorithm for
Imputing Missing Value,” Artificial Intelligence and Statistics, Jan. 2001.
[12 ] R. Little and D. Rubin, Statistical Analysis with Missing Data, second ed. John Wiley and Sons, 2002.
[13 ] S.C. Zhang, “Par imputation: From Imputation and Null-Imputation to Partially Null-Imputation,” IEEE Intelligent Informatics Bull., vol. 9, no. 1, pp. 32- 38, Nov. 2008.
[14 ] Y.S. Qin et al., “POP Algorithm: Kernel-Based Imputation to Treat Missing Values in Knowledge Discovery from Databases,” Expert Systems with Applications, vol. 36, pp. 2794-2804, 2009. [15 ] Zhang.S.C, “Estimating Semi-Parametric Missing Values with