International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, ISO 9001:2008 Certified Journal, Volume 5, Issue 1, January 2015)
389
Text to Speech Conversion System using OCR
Jisha Gopinath
1, Aravind S
2, Pooja Chandran
3, Saranya S S
41,3,4Student, 2Asst. Prof., Department of Electronics and Communication, SBCEW, Kerala, India
Abstract- - There are about 45 million blind people and 135 million visually impaired people worldwide. Disability of visual text reading has a huge impact on the quality of life for visually disabled people. Although there have been several devices designed for helping visually disabled to see objects using an alternating sense such as sound and touch, the development of text reading device is still at an early stage. Existing systems for text recognition are typically limited either by explicitly relying on specific shapes or colour masks or by requiring user assistance or may be of high cost. Therefore we need a low cost system that will be able to automatically locate and read the text aloud to visually impaired persons. The main idea of this project is to recognize the text character and convert it into speech signal. The text contained in the page is first processed. The pre-processing module prepares the text for recognition. Then the text is segmented to separate the character from each other. Segmentation is followed by extraction of letters and resizing them and stores them in the text file. These processes are done with the help of MATLAB. This text is then converted into speech.
Index terms- Binarization, OCR, Segmentation, Templates, TTS.
I. INTRODUCTION
Machine replication of human functions, like reading, is an ancient dream. However, over the last five decades, machine reading has grown from a dream to reality. Speech is probably the most efficient medium for communication between humans. Optical character recognition has become one of the most successful applications of technology in the field of pattern recognition and artificial intelligence. Character recognition or optical character recognition (OCR), is the process of converting scanned images of machine printed or handwritten text (numerals, letters, and symbols), into a computer format text. . Speech synthesis is the artificial synthesis of human speech [1]. A Text-To-Speech (TTS) synthesizer is a computer-based system that should be able to read any text aloud, whether it was directly introduced in the computer by an operator or scanned and submitted to an Optical Character Recognition (OCR) system [1]. Operational stages [2] of the system consist of image capture, image preprocessing, image filtering, character recognition and text to speech conversion.The software platforms used are MatLab, LabVIEW and android platform.
II. TEXT SYNTHESIS
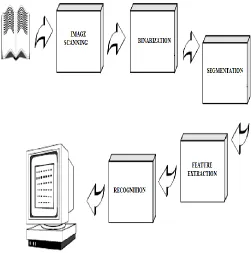
[image:1.612.325.576.277.530.2]Recognition of scanned document images using OCR is now generally considered to be a solved problem for some scripts. Components of an OCR system consist of optical scanning, binarization, segmentation, feature extraction and recognition.
Fig 1:Components of an OCR-system.
With the help of a digital scanner the analog document is digitizedand the extracted text will be pre-processed.Each symbol is extracted through a segmentation process [2]. The identity of each symbol comparing the extracted features with descriptions of the symbol classes obtained through a previous learning phase. Contextual information is used to reconstruct the words and numbers of the original text.
III. SPEECH SYNTHESIS
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, ISO 9001:2008 Certified Journal, Volume 5, Issue 1, January 2015)
390
Speech synthesis is the artificial production of human speech. A system used for this purpose is called a speech synthesizer, and can be implemented in software or hardware. Synthesized speech can be created by concatenating pieces of recorded speech that are stored in a database. The quality of a speech synthesizer is judged by its similarity to the human voice, and by its ability to be understood.
IV. TEXT TO SPEECH SYNTHESIS
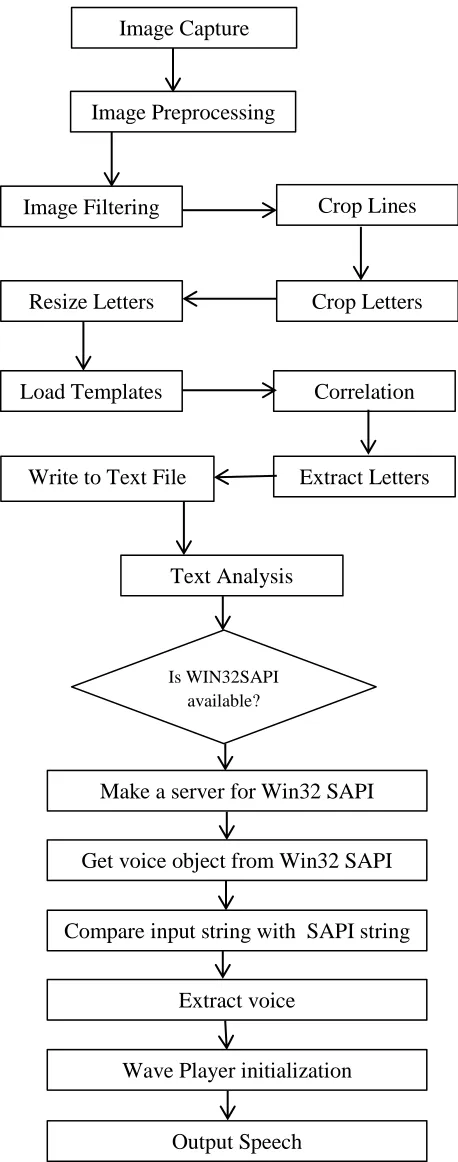
[image:2.612.63.277.297.513.2]A Text-To-Speech (TTS) synthesizer is a computer-based system that should be able to read any text aloud. The block diagram given below explains the same [3].
Fig 2: Overall Block diagram
A text-to-speech system (or "engine") is composed of two parts:a front-end and a back-end. The front-end has two major tasks. First, it converts raw text containing symbols like numbers and abbreviations into the equivalent of written-out words. This process is often called text normalization,pre-processing, ortokenization [4]. The front-end then assigns
phonetic transcriptions
to each word, and divides and marks the text intoprosodic units
, likephrases
,clauses
, andsentences
. The process of assigning phonetic transcriptions to words is called text-to-phoneme conversion. The back-end often referred to as thesynthesizer—then converts the symbolic linguistic representation into sound.In certain systems, this part includes the computation of the target prosody (pitch contour, phoneme durations), which is then imposed on the output speech.
V. SYSTEM IMPLEMENTATION
a)Using Lab VIEW
LabVIEW is a graphical programming language that uses icons instead of lines of text to create applications. LabVIEW uses dataflow programming, where the flow of data through the nodes on the block diagram determines the execution order of the VIs and functions.VIs, or virtual instruments, are LabVIEW programs that imitate physical instruments. In LabVIEW, user builds a user interface by using a set of tools and objects. The user interface is known as the front panel. User then adds code using graphical representations of functions to control the front panel objects. This graphical source code is also known as G code or block diagram code.
i) LabVIEW Program Structure
A LabVIEW program is similar to a text-based program with functions and subroutines; however, in appearance it functions like a virtual instrument (VI) [5]. A real instrument may accept an input, process on it and then output a result. Similarly, a LabVIEW VI behaves in the same manner. A LabVIEW VI has 3 main parts:
a) Front Panel window
Every user created VI has a front panel that contains the graphical interface with which a user interacts. The front panel can house various graphical objects ranging from simple buttons to complex graphs [6].
b) Block Diagram window
Nearly every VI has a block diagram containing some kind of program logic that serves to modify data as it flows from sources to sinks. The block diagram houses a pipeline structure of sources, sinks, VIs, and structures wired together in order to define this program logic. Most importantly, every data source and sink from the front panel has its analog source and sink on the block diagram. This representation allows the input values from the user to be accessed from the block diagram. Likewise, new output values can be shown on the front panel by code executed in the block diagram.
c) Controls, Functions and Tools Palette
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, ISO 9001:2008 Certified Journal, Volume 5, Issue 1, January 2015)
391
ii)Process Flowchartb)Using Android
Android is a Linux-based operating system for mobile devices such as smartphones and tablet computers. It is developed by the Open Handset Alliance led by Google.
Start
Create OCR session
Text analysis
Get ROI
Recognize
character and write
to text file
Error
Read text
Draw bounding
boxes
Image capture
Correlation
Read image and
character set file
Is Microsoft Win32 SAPI
Available ?
Make a server for
Win32 SAPI
Extract voice
Get voce object from
Win32 SAPI
Wave player
initialization
Compare input string
with SAPI string
Output speech
Stop
A
No
Yes
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, ISO 9001:2008 Certified Journal, Volume 5, Issue 1, January 2015)
392
Google releases the Android code as open-source, under the Apache License [7]. Android has seen a number of updates since its original release, each fixing bugs and adding new features. Android consists of a kernel based on the Linux kernel, with middleware, libraries and APIs written in C and application software running on an application framework which includes Java-compatible libraries based on Apache Harmony. Android uses the Dalvik virtual machine with just-in-time compilation to run Dalvik dex-code (Dalvik Executable), which is usually translated from Java bytecode. The main hardware platform for Android is the ARM architecture. There is support for x86 from the Android x86 project, and Google TV uses a special x86 version of Android.
i) System design
Open source OCR software called Tesseract is used as a basis for the implementation of text reading system for visually disabled in Android platform. Google is currently developing the project and sponsors the open development project. Today, Tesseract is considered the most accurate free OCR engine in existence. User can select an image already stored on the Android device or use the device’s camera to capture a new image; it then runs through an image rectification algorithm and passes the input image to the Tesseract service.
When the OCR process is complete it produces a returns a string of text which is displayed on the user interface screen, where the user is also allowed to edit the text then using the TTS API enables our Android device to speak text of different languages. The TTS engine that ships with the Android platform supports a number of languages: English, French, German, Italian and Spanish. Also American and British accents for English are both supported. The TTS engine needs to know which language to speak. So the voice and dictionary are language-specific resources that need to be loaded before the engine can start to speak [8,9].
ii) Process flowchart
c)Using MATLAB
i) System architecture
The system consists of a portable camera, a computing device and a speaker or headphone. Images can be captured using the camera. For better results we can use a camera with zooming and auto focus capability. OCR based speech synthesis system applications require a high processing speed computer system to perform specified task. It's possible to do with 100MHz and 16M RAM, but for fast processing (large dictionaries, complex recognition schemes, or high sample rates), we should shoot for a minimum of a 400MHz and 128M RAM. Because of the processing required, most software packages list their minimum requirements. It requires an operating system and sound must be installed in PC. System applications require a good quality speaker to produce a good quality of sound.
Start
Correct orientation
Image capture
Pass image to Tesseract OCR
engine
Pass the text field to TTS
API
Display the text output given
by OCR engine
Output speech
Stop
A
A
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, ISO 9001:2008 Certified Journal, Volume 5, Issue 1, January 2015)
393
ii)Process flowchart VI. RESULT
Text reading system has two main parts: image to text conversion and text to voice conversion. Image into text and then that text into speech is converted using MatLab, LabVIEW and in Android platform. For image to text conversion firstly image is converted into gray image then black and white image and then it is converted into text by using MatLab and LabVIEW. But in Android platform we processed rgb image. Microsoft Win 32 speech application program interface library has been used to produce speech information available for computer in MatLab and Labview. This library allows selecting the voice and audio device one would like to use. We can select the voices from the list and can change the pace and volume, which can be listened by installing wave player. Android platform implementation uses Android text to speech application program interface.
a)Using LabVIEW
Input:
[image:5.612.41.270.153.734.2]Input image Output:
Fig 3: Front panel of text reading system
Image Preprocessing
Image Filtering
Crop Lines
Crop Letters
Resize Letters
Load Templates
Correlation
Text Analysis
Write to Text File
Extract Letters
Is WIN32SAPI available?
Make a server for Win32 SAPI
Get voice object from Win32 SAPI
Compare input string with SAPI string
Extract voice
Wave Player initialization
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, ISO 9001:2008 Certified Journal, Volume 5, Issue 1, January 2015)
394
b)Using AndroidInput:
Input image
Image capture
Output:
Output
c)Using MatLab
Input:
Input image
Output:
Output text
VII. CONCLUSION
This paper is an effort to suggest an approach for image to speech conversion using optical character recognition and text to speech technology. The application developed is user friendly, cost effective and applicable in the real time. By this approach we can read text from a document, Web page or e-Book and can generate synthesized speech through a computer's speakers or phone’s speaker. The developed software has set all policies of the singles corresponding to each and every alphabet, its pronunciation methodology, the way it is used in grammar and dictionary. This can save time by allowing the user to listen background materials while performing other tasks. System can also be used to make information browsing for people who do not have the ability to read or write. This approach can be used in part as well. If we want only to text conversion then it is possible and if we want only text to speech conversion then it is also possible easily. People with poor vision or visual dyslexia or totally blindness can use this approach for reading the documents and books. People with speech loss or totally dumb person can utilize this approach to turn typed words into vocalization. Experiments have been performed to test the text reading system and good results have been achieved.
REFERENCES
[1] T. Dutoit, "High quality text-to-speech synthesis: a comparison of four candidate algorithms," Acoustics, Speech, and Signal Processing, 1994. ICASSP-94., 1994 IEEE International Conference on, vol.i, no., pp.I/565-I/568 vol.1, 19-22 Apr 1994.
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, ISO 9001:2008 Certified Journal, Volume 5, Issue 1, January 2015)
395
[3] http://www.voicerss.org/tts/
[4] http://www.comsys.net/technology/speechframe/text-to-speech-tts.html
[5] Image Acquisition and Processing with LabVIEW, Christopher G Relf, CRC Press, 2004.
[6] http://www.rspublication.com/ijst/aug%2013/6.pdf
[7] Implementing Optical Character Recognition on the Android Operating System for Business Cards Sonia Bhaskar, Nicholas Lavassar, Scott Green EE 368 Digital Image Processing.
[8] J. Liang, et. al. “Geometric Rectification of Camera-captured Document Images,” IEEE Transactions on Pattern Analysis and Machine Intelligence, pp. 591-605, July 2006.
[9] G. Zhu and D. Doermann. “Logo Matching for Document Image Retrieval,” International Conference on Document Analysis and Recognition (ICDAR 2009), pp. 606-610, 2009.
Authors Biographies
Jisha Gopinath, pursuing final year BTech degree in Electronics and Communication Engineering from Mahatma Gandhi University,
Kerala, India. Completed Diploma in
Electronics Engineering from Technical Board of Education, Kerala.
Aravind S, Assistant professor in the
Department of Electronics and
Communication Engineering, Sree Buddha College of Engineering for Women, Mahatma Gandhi University, Kerala, India. He obtained M.Tech degree in VLSI and Embedded Systems with Distiction from Govt. College of Engineering Chengannur, Cochin University in 2012. He received his B.Tech Degree in Electronics and Communication Engineering with
Distiction from the main campus of Cochin University ofScience
andTechnology, School of Engineering, Kerala, India, in 2009.
He has published ten research papers in various International Journals. He has presented three papers in National Conferences. He has excellent and consistent academic records,very good verbal and written communication skills. He has guided nine projects for graduate engineering students and one project for P.G student. He has academic experince of 3 years and industrial experience of 1.6 years. For Post Graduate students he has handled subjects such as Electronic Design Automation Tools, VLSI Circuit Design and Technology ,Designing with Microcontrollers and Adaptive Signal Processing. He taught subjects such as Network Theory, DSP, Embedded Systems, Digital Electronics, Microcontroller and applications, Computer Organisation and Architecture , Microprocessor and applications, Microwave Engineering ,Computer Networks and VLSI for B.Tech students.
Pooja Chandran, pursuing final year BTech degree in Electronics and Communication Engineering from Mahatma Gandhi University, Kerala, India.
Saranya.S.S, pursuing final year BTech degree in Electronics and Communication
Engineering from Mahatma Gandhi