2017 2nd International Conference on Wireless Communication and Network Engineering (WCNE 2017) ISBN: 978-1-60595-531-5
An Entropy Gain Ratio-based Algorithm for Community
Detection in Mobile Social Networks
Wei ZHENG
1,2, Xiao-kang ZHAO
2,*and Zhao KANG
2 1School of Mathematics and Statistics, Xidian University, Xi’an, Shanxi 710071 P.R. China
2
School of Software. Nanchang, Hangkong, University, Nanchang, Jiangxi 330063 P.R. China
*Corresponding author
Keywords: Mobile social networks, Information entropy, Entropy gain ratio, Community structure, Multi-slice networks.
Abstract. Community structure is one of the important properties of complex networks, and many algorithms have been proposed to detected community based on optimization of Modularity Q. In this article, A more effective theoretic model based information gain ratio (IGA) that combines optimizing modularity and reduce the ratio of information entropy is proposed. IGA algorithms reaches better community detecting results than information entroy-based and FastGN algorithm on both computer generated by benchmark graphs and real mobile social networks. According to experimental result compared the others cluster methods in different datasets, our method tries to detecting community with low information entropy and keeping not far-off modularity.
Introduction
Complex networks have proved to be a useful tool to model structural complexity of a variety of complex systems in different domains including sociology, biology, ethology and computer science. Community structure detecting studies based on complex networks has received increasing attention of researchers in the above listed fields. Since the community structure has tight relationship with the function of specific network. Such as people belonging to the same community are more likely to have common hobbies on topics, social functions and so forth in social network(Zhao et al, 2012). Identiting significative network community structure and analyzing relevant properties is the pivotal issue. People have come up with many community detecting algorithm and quality evaluate methods. The most favoured way of such methods is using cluster or divisive generate gradational community structure and then calculate the modularity to evaluating quality of identited. The proposed approaches include Kernighan-Lin algorithm (Kernighan and Lin 1970), Girvan-Newman algorithm (GN) (Girvan and Newman2002), fast GN algorithm (FGN) (Newman 2004), clique percolation algorithm (CPM) (Palla et al.2005). Spectral clustering algorithm (SCA) (Shiga et al. 2007), information-theoretic approach for detecting communities (ITDC) (Li et al. 2014) and so on. However, the time complexity of above noted methods, except FGN, are huge. Meanwhile, the accuracy leave much to be desired. This paper aims to propose a computationally economical same as FGN and based on information gain ratio theory to getting a high accuracy. According to simulation result compared and analyzed with the classic detecting methods on artificial random networks to reveal the essential characteristic of modularity about community detection. This is the first insight of this paper.
be in separate communities depending on the layer. Based on this property, MSNs are linked with different dynamics time. Interlinkage between the nodes as a function of time (multiplex network mining: a brief survey). In this paper, we first defined the MSNs as a multilayer network and then reform the prior presented method and apply it to multilayer network.
Entropy and Information Gain Ratio of Single-layer Network
Network community detecting is via algorithms to find sets of nodes that are connected more densely to each other than they are to the rest of a network. There are numerous notions of community character, that is Modularity by Newman proposed[1]. The modularity is defined as:
Q = ∑
−
(1)
Where k is the number of network community, m denote the total number of links, represent the number of links within the ith community, is the sum of degree of the node i within the ith community.
In the field of information science, information entropy is always adapted to define the information value contained in one system. Here we also quantify the information of networks by the information entropy. The entropy of network system can be obtained by
HX = C ∑ " 1/ (2)
Where n is the total number of nodes included in the network and is the uncertainly probability.
In this paper, we defined that if the network be detected to m communities, is the number of link within the community, $ is the number of link between the two communities. In order to find the more clear community structure, we need to obtain all potentially identified community through iterative analysis. The identified result every iterate step is closely related to the information entropy. We first defining the ratio of node degree and degree of all nodes as the significance of node.
% = &/ ∑ &' (3)
Where N is the number of the network, & is the degree of the node. Obviously, the greater degree of node, the node is relatively more important, analogously, the information entropy of node
i is proportional to the degree of the node, and inversely proportional to the total degree of the network. According to the definition of Eq. 2, we express () as the probability that node may be divided into community m. then, we can further to get the information entropy of a node by
*+ = %∗ ()-1/(). (4)
The value of () obtained by calculated the ratio of node number within the community / and total node number of network. A more obvious community structure should have greater value of Eq. 4. namely, within community are more dense links and that between of community more sparse. If we consider the community structure within a network[2]. The information entropy contained between communities of the network also can defined as (according to defined above)
*-0$. = 1∑,3$$4
(5)
The *-0$. defined in Eq. 5 measures the information entropy contained in the community 0$ with others. We would suggest the smaller entropy value means the links are thinner. Information entropy H56 remained inside these community defined further as
*56 =∑ 7
89 ∑ :∑ *+
";
− *-0$./2=
According to the definition of H56 , the whole network information entropy of the already yield set of communities is split into two parts: one is the sum of total information entropy *+ and the other is H56 reflecting the information entropy of intra-community. There is no doubt that a distinct community structure should possessed more information entropy in communities and leave less outside communities, because the process of nodes aggregation is the process of community’s information entropy lead to increase. According to the idea, we will adapt a heuristic approaches for reduce the value H56.
Algorithm Analysis and Experiment
[image:3.612.108.498.295.518.2]In the actual detection of community, we combine the theoretical ideas of Newman’s fast algorithm [3] and information entropy. The iterations of merging those nodes simultaneously calculate the network’s modularity. Finally get the detection result and modularity consist of every step and that the detection of largest modularity is the optimal community structure. To find the optimal merged node in every iteration step, we calculated the information gain ratio instead of information gain, so that can avoid always choose large community mergers. The algorithm method as below:
Table 1. The algorithm of solving the minimize problem in formula(6).
Input: the given network G.
Output: the best partitioned network 0 1.Initialization:
Initialize the network for n communities, that means each node is an independent community. Calculate the initial matrix ℎ$ and value ?.
ℎ$= A 1
2 $1 , exist link between node i and j. 0, other ?= H+
2. Merging two community be linked in sequence, meanwhile calculate the information gain ratio
IGR-HRN.
IGR-HRN. = ℎ$+ ℎ$− 2??$ − $
2
T $T2
= 2ℎ$− ??$
According to the principle of the greedy algorithm. Each merge should be carried out in the direction that maximum decrease value of ∆Q-HRN., meanwhile update ℎ$ and ?.
3. Repeating execute step 2, calculating the modularity in every step. Until all nodes merged to one community. The repeat execute n-1 times at most.
4. Finally we obtain a hierarchical partition results. Selecting the one of the partition corresponding maximal modularity as the best partition.
A widespread used method of evaluating the performance of ours detection algorithm is to generate randomly artificial networks that community structure is known, and then to compare the detection result of some method with the known community structure [4,5]. In this paper, we here generate the community-known graph as RN<200,5,20,μ,7,30> by the LFR benchmark[6,7]. Here, the number 200 is the number of nodes in the simulation networks, the 5 is the average node degree and the 20 is the maximum node degree, 7 and 30 respectively are minimum and maximum for the generated networks. The μ means the instability of the network’s community structure and the more large the more mess. In our simulation experiment, we design 10 cases with μ taking different values from 0.5 to 1 by 0.05 in each generation step, and then we applied the proposed algorithm and the classic algorithm to the 10 networks respectively. For compare the performance, we used the normalized mutual information to estimate the goodness of the detection results given by those algorithm as compared to the known community[8]. The whole result is shown in Figure 1. In a situation where the community structure is not obvious, our method obtained better performance than the classic FastNewman algorithm and common algorithm based on information entropy on the accuracy ratio.
nodes and overlapping community. Furthermore, the real network structure is the same. Therefore, we can’t simply use the modularity to determine the stand or fall of detection. Even so, the modularity based on our method close to 0.4.
Figure 1. The accuracy(left) and modularity(right) at different values of μ.
Apply the Method to the Mobile Social Networks
Community detection in mobile social networks has been well studied in literature. For example, Berger-wolf et al.[9] and Tantipathananandh et al[10], they all aim to proposed a framework and then to identify communities and analyze their evolution in mobile social networks. In this paper, we focus to identify global communities in the mobile social networks contained real time.
Our work is like the study of Peter J. Mucha[11]. Which mainly redefined the formula of modularity adapted to the multiplex networks. The mobile social networks are heterogeneous and dynamic, such the nodes and links are evolve with time, so we first introduce and provide an expressive model for modeling real-world mobile social networks. Which is the multilayer network extended of the basic single-layer network model.
Model Definition
The method is to cut a time series of mobile social networks into many time slices according to the same time domain. Then re-connected nodes between adjacent time slice. The multilayer network of this period of time is constructed by these time slices. In order to clearly define the multilayer network model, we defined a multilayer network as a triplet G〈X, Y"Z[\, Y"Z\]〉 where V =
`a, a, … , a, … , acd is a set of nodes, ac represent the + node in s slice. Y"Z[\ =
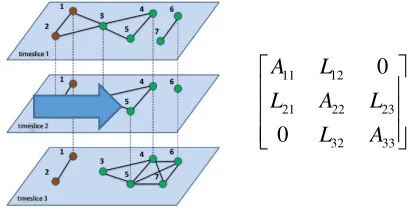
`e, e, … , ef, … , ec\d represent the edge sets between the adjacent slices, the ec\ is the edge joint same node + on two adjoining slice. Y"Z\]= ge, ef, … , e, … , e$ch is the edge sets on each slice, the e$c is the edge of the node + and i on slice j. In order to adapt this model to our proposed algorithm. Typically, one first operation to apply to multilayer networks is network flatten. This consists on transforming the multilayer into a monoplex network. Flattened network is obtained by applying a layer aggregation function. Our function is flatten a multilayer network into block matrix constituted by intra-slice adjacent matrix and inter-slice diagonal matrix. Figure 2 illustrates flatten process. As show in the figure, k, k, kff represent intra-slice adjacent matrix of 2 network layer. l, lf represent diagonal of inter-slice.
11 12
21 22 23
32 33
0
0
A L
L A L
L A
[image:4.612.220.425.624.729.2]Now, we apply our method on the monolex network flattened by four typical real mobile social networks. Following is the specific introduction: Cambridge lab dataset and Info 05 dataset be applied to the proposed research method. The numbers of nodes and slices sum be partitioned of two MSNs are listed in Table 2. The Cambridge lab dataset collected encounter data from a number of traces of Bluetooth sighting by 19 graduate students carrying small devices for a several days. Info 05 dataset was got from Infocom 2005 experiment with 268 nodes.[12].
Table 2. Common characteristics of network model about four realistic MSNs.
Dataset The Member Nodes Duration time Preestablish of slices
CambLab 223 6says 12
Info05 268 3days 6
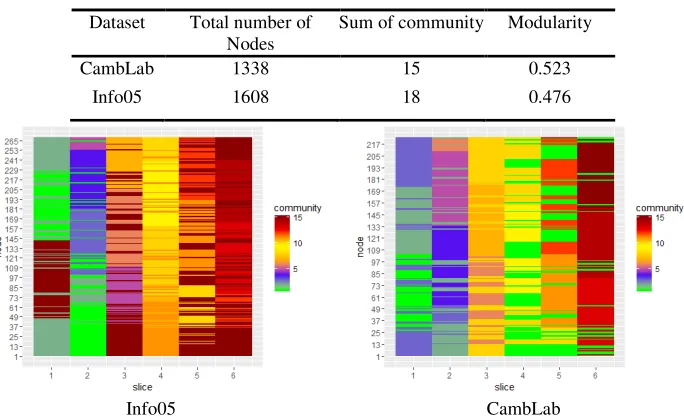
[image:5.612.134.476.296.505.2]From the above analyzes based on the artificial generated and community known networks, this paper’s method received a satisfying accuracy of detecting community. By using our multilayer network community detection procedure, we also get higher modularity and good detection performance in Table 3. To help understand the change of community in time series about the MSNs. We plot the heat map of two experimental data in Figure 3.
Table 3. The module sum and modularity be partitioned of two real MSNs.
Dataset Total number of Nodes
Sum of community Modularity
CambLab 1338 15 0.523
Info05 1608 18 0.476
Info05 CambLab
Figure 3. Multislice community detection of info05 and CambLab coupling of 6 slices across 3 days and 6 days respectively. Colors depict community assignments of the member nodes in each of the splitted slices.
Discussion and Conclusion
This paper introduces a community detection method based on information entropy called IGA which tested on artificial networks that community structure is known. The algorithm based on minimize the information entropy between the two communities of networks. In each iteration of the algorithm, the method merge two community that the value of information gain ratio is minimum. By experiments, the algorithm performs well than earlier method in terms of accuracy. Finally, the algorithm is well suited to manage dynamically changing networks (MSNs).
IGA algorithm only detects the non-overlapping communities. However, in real networks nodes may belong to not only one community. In the future study this algorithm may be used to identify the overlapping communities. And additionally, for large MSNs dataset, we need apply this algorithm to parallel computation framework for reducing time consumption.
Acknowledgement
61501217, 61762065. Natural Science Foundation of Jiangxi Province under Grant Nos 20171ACB20018, 20161BAB212034. and The 13th Five Years Key plans for Science and Education of Jiangxi province under Grant No 17ZD033.
References
[1] Newman M E J. Finding community structure in networks using the eigenvectors of matrices.[J]. Physical Review E Statistical Nonlinear & Soft Matter Physics, 2006, 74(3 Pt 2):036104.
[2] Deng X, Wang B, Wu B, et al. Research and Evaluation on Modularity Modeling in Community Detecting of Complex Network Based on Information Entropy[C]//Third IEEE International Conference on Secure Software Integration and Reliability Improvement. IEEE Computer Society, 2009:297-302.
[3] Newman M E J. Fast algorithm for detecting community structure in networks.[J]. Physical Review E Statistical Nonlinear & Soft Matter Physics, 2004, 69(6 Pt 2):066133.
[4] Bianconi G, Pin P, Marsili M. Assessing the relevance of node features for network structure.[J]. Proceedings of the National Academy of Sciences of the United States of America, 2009, 106(28):11433-8.
[5] Girvan M, Newman M E J. Community structure in social and biological networks[J]. Proceedings of the National Academy of Sciences of the United States of America, 2001, 99(12):7821.
[6] Lancichinetti A, Fortunato S, Radicchi F. Benchmark graphs for testing community detection algorithms.[J]. Physical Review E Statistical Nonlinear & Soft Matter Physics, 2008, 78(4 Pt 2):046110.
[7] Lancichinetti A, Fortunato S. Community detection algorithms: a comparative analysis.[C]// International ICST Conference on Performance Evaluation Methodologies and TOOLS. ICST (Institute for Computer Sciences, Social-Informatics and Telecommunications Engineering), 2009:27.
[8] Danon L, Díazguilera A, Duch J, et al. Comparing community structure identification[J]. Journal of Statistical Mechanics Theory & Experiment, 2005, 2005(09):09008.
[9] Berger-Wolf T Y, Saia J. A framework for analysis of dynamic social networks[C]// Twelfth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Philadelphia, Pa, Usa, August. DBLP, 2006:523-528.
[10] Tantipathananandh C, Berger-Wolf T, Kempe D. A framework for community identification in dynamic social networks[C]// ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Jose, California, USA, August. DBLP, 2007:717-726.
[11] Mucha P J, Richardson T, Macon K, et al. Community structure in time-dependent, multiscale, and multiplex networks[J]. Science, 2009, 328(5980):876.