2016 International Conference on Artificial Intelligence and Computer Science (AICS 2016) ISBN: 978-1-60595-411-0
Abnormal Consumption Detection Based on Density in Campus Card
Zhi-qiang LI
1,a, Zhou-zhong ZHANG
1,band Hong-chen GUO
2,c,*1School of Software, Beijing Institute of Technology, Beijing 100081, China
2Network Information Technology Centre, Beijing Institute of Technology, Beijing, 100081, China
a[email protected], b[email protected], c[email protected]
*Corresponding author
Keywords: Campus card, Outlier detection, DBSCAN; LOF
Abstract. Abnormal consumption detection is of great significance to improve the safety of student’s
campus card. In order to detect the abnormal consumption on students’ habits and make the model suitable to detect abnormal record for individual. A model based on density is put forward to detect students’ abnormal consumption. Density-Based Spatial Clustering of Applications with Noise (DBSCAN) and Local Outlier Factor (LOF) are integrated to find the abnormal record and abnormal degree of the outlier is marked in the model. Experiments show that abnormal consumption on time, place, cost and frequency can be detected with good accuracy, the severity of the outlier is distinguished correctly. The model is suitable for different students.
Introduction
With the development of the digital campus, campus card system is popular in the universities and colleges. Large amounts of data have been produced by the campus card. The data includes ample consumption information, which reflects the consumption patterns and trends of the students. Compared with the normal information, detecting the abnormal records in the card data is more meaningful because the unsafe factor can be discovered and improve the security of campus consumption. So, abnormal detection on campus card consumption is of great practical significance. In order to detect the abnormal records, there are different methods to solve the problem. Statistical method based on distribution is widely used. It means the data is subject to a specific distribution. However, the card record isn’t subject to a distribution. Regression is used to find the abnormal records, but this method need training data, campus card record doesn’t have the training data so it isn’t suitable for the abnormal consumption. The DBSCAN [1] is used to find the students’ consumption behaviors. It is effective to find the outliers from different students’ consumption but it can’t find the outliers under different density clusters. The LOF [2] is used to detect the possible outliers with respect to the neighbor points, but it can’t consider sparse cluster as outliers.
In the paper, we define three main kinds of outlier, including the abnormal consumption on cost, low frequent consumption and consumption with the temporary change of habits. A new model for each student to detect the consumption outliers is proposed. The model uses the DBSCAN to find the low frequent consumption and uses the LOF to find the abnormal point on the change of habit, three kinds of the abnormal consumption are gotten by merging the result. The experiments show that the model can detect three kinds of abnormal consumption well, the model is suitable for different students.
Related Work
anomaly detection algorithm based on artificial immune clustering, using the distance based outlier factor to distinguish between normal and abnormal data, thus implementing the network intrusion detection, but the method is not suitable to find each abnormal record. Sun Meiyu [5] proposed a new algorithm for anomaly detection in time series based on distance and density, which can efficiently find the abnormal patterns in time series. Zhou [6] applied LOF algorithm in time sequence detection and found the abnormal point of time sequence. However, the change caused by other factor can’t be expressed well. Ruan Jinjing [7] integrated K-means with DBSCAN algorithm to achieve automatic selection parameters, but the severity of the outliers can’t be gotten. According to the shortcoming of LOF algorithm in the dynamic incremental database environment, a dynamic clustering algorithm is proposed by MengJing [8] to improve the LOF algorithm in the dynamic incremental environment, but the accuracy rate of LOF would be reduce with the not obvious distribution.
However, there are few research papers focusing on the outlier detection of the campus card records for each student, there is few definition of the abnormal consumption in campus card consumption. In the paper, we define three abnormal consumption and combine the LOF and DBSCAN to find these outliers.
Method
Definition of the Abnormal Consumption
The detection is based on the student’s abnormal consumption, so a clear definition of the abnormal consumption should be given. However, there is few discussion about the definition. According to the specific situation of the campus card records, three kinds of the abnormal consumption are defined and detected.
The first abnormal consumption is caused by the abnormal behaviour, which is far from normal consumption. For example, if a student has a high consumption that is much more than normal consumption, we consider this consumption is abnormal. If a consumption occurred in a strange time and place, it is also abnormal. This kind of the outliers are the most important because they are close related with the card’s security.
The second case is the abnormal consumption occurring in the normal consumption habits, including the abnormal consumption in time or place. For example, a student used the card to have a meal one hour later than usual time, it is considered as an abnormal consumption. it is the least important because it usually doesn’t influence the safety of the card, however, it can find the irregular lifestyle.
The third case is the consumption with low frequency. If a behaviour occurs lower frequent than most other behaviours, the record correspond to the behaviour is thought as an abnormal consumption. if a student seldom use card to drink water, we think the consumption of drinking water is abnormal.
Design of the Model
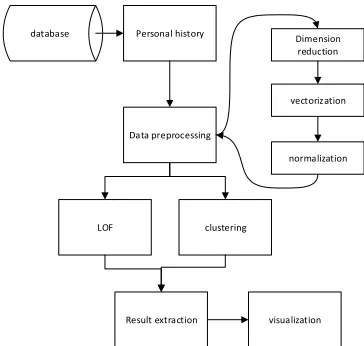
Due to different levels of consumption among the students, it is difficult to detect the abnormal consumption in the data of whole school, the consumption behaviours of each student can’t be discovered as well. So the model is established separately by individuals. The historical data in a month is selected, one month records can truthfully reflect students’ recent consumption activities and detect anomaly points accurately. Then the data is pre-processed by dimension reduction, vectorization and normalization. The LOF algorithm and DBSCAN algorithm are used to find the abnormal consumption records. The result is extracted and labelled to three different degree of abnormal points.The design of the abnormal detection model is shown in Fig. 1.
Detecting by the DBSCAN
find all the core points which eps neighbors are more than minpts, then find the all the points that are in the eps distance of the core points, all these points represent the normal consumption of the students, and the remains of data are global abnormal points which means the abnormal consumption, including the first kind and the third kind of the abnormal consumption.
database Personal history
Data preprocessing
LOF clustering
Result extraction visualization
Dimension reduction
vectorization
[image:3.612.221.403.123.296.2]normalization
Figure 1. Model of abnormal detection.
Detecting by the LOF
Since some outliers can’t be detected because the parameter eps or minpts isn’t always appropriate for the distribution of different students’ data. Besides, there are some points which is regarded as outliers from the local perspective but DBSCAN can’t detect them.
In order to address issues above, local outlier factor (LOF) is used in the model to figure out the abnormal degree of the point and detect the outlier with respect to its neighbors. The outliers output by the LOF means the abnormal consumption in the normal habits. First we find the k-nearest neighbor of the point, and get the distance to the k-nearest neighbor, denoted by k-dis(p). Then we get the reachability distance of the neighbors to the point using the Eq. 1.
(1) The density of point is calculated by the Eq. 2, denoted by lrd(p). The lrd value represents the density of the student’s one consumption record.
(2) Finally, the Local Outlier Factor(LOF) of the point is obtained by the Eq. 3.
(3) The LOF value is the average of the ratio of the density of p’s neighborhood points to the density of point p. The point p is more likely an outlier with the high LOF values. We use the model by set the k = minpts. The LOF can find the first kind and the second kind of the abnormal consumption. Result Extraction
Results
We conducted the experiment on the real data of the history card consumption record. The data is one month’s card consumption record from the database in our school. It consists of all students’ consumption and every record has the name of student, the time, the place, the cost, the card machine id and some other information of the consumption. One student’s consumption records are selected from the history data to be the input of the model.
The data has been pre-processed before detecting the abnormal consumption, duplicate and useless fields are dropped, the data irrelevant to the consumption such as recharge records is removed. and consumption records are selected, a three tuple X(x1,x2,x3) is gotten, representing time, place, cost respectively. The value of time is converted to decimal form and then all the parameters converted into dimensionless form by with the following Eq. 4.
(4) To evaluate the proposed model, Student A’s result is selected to demonstrate the effectiveness of the model. There are 507 records after data pre-processing. The outliers are shown in the Fig. 2.
[image:4.612.121.501.278.446.2]
Figure 2. The results of A. Figure 3. The results of B.
As shown in Fig. 2, it is known that there is no doubt the blue points are abnormal because these behaviours are deviated from the most consumption behaviours. The blue points are the first kind of abnormal consumption and are most abnormal because they are neither the normal costs nor the usual consumption habits, it may imply the fact that the card is lent to other students or is picked up by other people. By detecting this kind of outliers, the security of the students’ property can be protected better.
The green points in the Fig. 2 are the second kind of the abnormal consumption. For student A, he slept in the 2 a.m. In the usual time but one day he didn’t sleep and used the card to drink water, and these consumption is unusual although drinking water is a normal habit. By detecting these abnormal consumption, student can pay attention to their abnormal behavior and help them improve the lifestyles.
The red points are the outliers due to the low frequency of occurrence, which meet the third kind of outlier defined above. Student A seldom had a meal with price more than fifteen yuan in one month, so when he did this the model considered the consumption is abnormal. These records maybe reflect the potential abnormal consumption or new behaviours, students can get further analysis from them. It is shown that the model has a good accuracy to find the abnormal consumption defined above and all the results have a good practical significance and help students improve the safety of the property or improve the habits. In order to explain that the model has a good effect on different students, records of another student B with different consumption behaviors are selected to detect the outlier, the results of B is shown in the Fig. 3.
than A and his record is more dispersed than A’s. The model can detect most abnormal records and have a high accuracy on the most severe abnormal outliers which are blue points in the Fig. 3. It shows the good adaptability of the model and the accuracy of the model.
Conclusions
In this paper, we propose the definition of the abnormal consumption in the field of campus card consumption. A model based on density is designed to detect the abnormal consumption in the students’ consumption record. The abnormal degree of the outlier is presented. DBSCAN is used to detect the abnormal consumption data from a global perspective, and LOF is used to find the outliers in the local perspective. The experiment demonstrated that the model proposed by this paper achieved the expected performance on the real data, abnormal consumption on time, place, cost and frequency can be detected with good accuracy and the severity of abnormal consumption can be distinguished properly, and the model has strong adaptability for different students.
There remain several important directions for future work. One direction is to find the consumption pattern and predict the record in real time. Another work is to find the outlier with consideration of change of the students’ consumption habit. Besides the card record, other factor could be taken into account in the future.
References
[1] Ester M., Kriegel H.P., Sander J., et al. A density-based algorithm for discovering clusters in large spatial databases with noise, Kdd. 96(34) (1996) pp. 226-231.
[2] Breunig M.M., Kriegel H.P., Ng R.T., et al. LOF: identifying density-based local outliers, ACM sigmod record. 29(2) (2000) pp. 93-104.
[3] Hong-xiang Diao, China Computer & Communication, 11 (2011) 57-58, In Chinese.
[4] Xue-yu Huang, Na Wei, Jian-feng Tao, Computer Engineering. 36(1) (2010) 166-169, In Chinese.
[5] Mei-yu Sun, Computer Engineering and Applications. 20 (2012) 11-17, In Chinese.
[6] Da-zhuo Zhou, Yue-fen Liu, Wen-xiu Ma, Computer Engineering and Applications. 35 (2008) 145-147, In Chinese.
[7] Jing-jing Ruan. Research and Application of Statistical Data about Human Resource Exception Detection Based on Data Mining, Zhejiang University of Technology, 2013, In Chinese.