2020 4th International Conference on Modelling, Simulation and Applied Mathematics (MSAM 2020) ISBN: 978-1-60595-674-9
DHCC: An Efficient Algorithm for Supervised Discretization
Qing DENG*, Qing XUE, Xiang-zhong XU and Heng GAO
Academy of Army Armored Forces, Beijing, China *Corresponding author
Keywords: Discretization, Hierarchy clustering, Information entropy, Compatibility.
Abstract. To improve the speed and effectiveness of data mining in equipment simulation training
system, a discretization algorithm based on hierarchy clustering and compatibility (DHCC) is proposed. Compared with the traditional discretization algorithms, DHCC algorithm calculates the positive domain of clusters to adjust the number of clusters and realize the initial division of each attribute by combining the association between attributes. Further on the basis of the initial discretization results generated by hierarchy clustering, information entropy and simplified compatibility degree are calculated to merge the adjacent intervals to reduce the number of broken points and eliminate superfluous intervals. Therefore the valid and brief discretization scheme is generated. Through six typical datasets tests, the results show that DHCC algorithm is superior to Equal-W, Equal-F, Chimerge, MDLP, and CAIM algorithm in the total number of intervals and accuracy.
Introduction
The data generated by equipment simulation training system generally includes continuous data and discrete data. The former mainly refers to the data that can be taken continuously in the value range, such as temperature and wind speed in virtual battlefield environment. The latter refers to a few limited divisions within the range, such as combat formation and equipment type. Data discretization is an important preprocess for data mining of equipment simulation training system. In essence, the value domain of data is divided into several effective intervals, which are represented by some discrete values or symbols.
The existing discretization algorithms are mainly based on statistical independence, information entropy, class attribute interdependence, Bayesian classifier [3,9,10]. During using these methods in the process of each discretization, only one attribute is considered, and then iterate according to the set discretization criteria until each attribute is processed [1,7]. Although it has the characteristics of simple understanding and high efficiency, the relativity and complementarity among attributes are often ignored and separated. In most cases, class labels are influenced by several attributes. For example, when using tank driving simulator to train driving skills, the operation of accelerator, clutch and brake is not isolated, and they should cooperate with each other to better master the operation essentials and improve the training results. Therefore, when discretizing these operation data, we must consider the interaction between them for produce right rules in the subsequent data mining. In order to solve this problem, a discretization algorithm by hierarchical cluster and compatibility (DHCC) is proposed.
This paper is organized as follows. Section 2 reviews related work. In Section 3, a data discretization algorithm based on hierarchical clustering and consistency is proposed. Section 4 shows the comparison results with other discretization algorithms, Equal-W, Equal-F, Chimerge, MDLP, CAIM and some analysis. analyzes them. Section 5 concludes the paper.
Related Work
easy to realize. The Equal-W discretization algorithm generally sets the number of discretized intervals according to the data characteristics and empirical formula, and then divides the value range of continuous attributes with the same interval [2,4,5]. On the basis of setting the initial interval number, Equal-F discretization algorithm divides the value range of attributes into several intervals with the same frequency. In the unsupervised methods, continuous ranges are divided into subranges by the user specified width or frequency. This may not give good results in cases where the distribution of the continuous values is not uniform [1]. To overcome this shortcoming, supervised discretization methods are introduced and class information is used to find the proper intervals caused by cut-points.
Another dichotomy is local and global. A local method would discretize in a localized region of the instance space [6,11]. A local method is usually associated with a dynamic discretization method in which only a region of instance space is used for discretization [8]. While a global discretization method uses the entire instance space to discretize.
Discretization Algorithm by Hierarchical Clustering and Compatibility (DHCC)
Problem Definition
Definition. Given a decision tableS=<U A, C D V F, , >, Cis a set of all condition attributes. IfTC, uianduj are two samples, c u( )i c u( j) are satisfied, then uianduj are equivalent on T. The equivalent classes of ui on T are denoted by [ ]ui T. The set of all equivalence classes is called equivalence relation, which can be expressed as follows:
( ) ( ,i j) | ( )i ( j),
IND T u u U U c u c u cT (1)
Definition. For an equivalence relation IND D( ), if YIND D( ), then the positive domain is as follows:
( ) | [ ]
T i i i T
POS Y u u U u Y (2) From the expression above, the equivalence class obtained by equivalence relation IND T( ) completely determines the objects that can be included inIND D( ).
Definition. The consistency of decision table is defined as follows:
| ( ) : ( ), |
| |
T
POS Y Y IND D T C
U
(3)
| * |represents the cardinality of the collection. obviously. If 1, the decision table is consistent.
In order to ensure the accuracy during the whole discretization, the consistency of decision table should keep constant.
Definition. Given a decision tableS=<U A, C D V F, , >, U=u u1, 2, ,... un, C=c c1, 2, ,... ck. If any
attribute c is divided into Mc intervals, the information entropy of interval j is defined as follows:
2 1
| |
( )
| |
d
ji j
j
i j ji
R E R
R
∑
㏒ (4)DHCC Algorithm
DHCC algorithm is generally based on the idea of bottom-up, which is mainly divided into two steps. The first step is to calculate the positive domain of clusters and determine the number of clusters by combining the association between attributes, thus obtaining the initial partition of each attribute. On the basis of the clustering results, the second step proposes to use the information entropy and the simplified compatibility difference calculation method to merge the adjacent, so as to generate the final discretization scheme.
Initial Partition Based on Hierarchical Clustering
Hierarchical clustering is to carry out all the conditional attributes of the whole decision table at the same time, which can better maintain the relationship between attributes. Before clustering, in order to compare the similarity between data objects, c C the attribute values are standardized according to formula (5).
* ( ) ( ( ))
( )
( ( )) ( ( ))
i i
c u min c U
c u
max c U min c U
(5)
( ( ))
max c U
,min c U( ( ))respectively denotes the maximum and minimum value of attribute c in the whole decision table. At the beginning, each object is regarded as a cluster. Euclidean distance is
selected to establish the similarity matrix between clusters. Matrix elements SIMijrepresents the distance betweenui and uj.
2
[ ( ) ( )]
ij i j
c C
SIM c u c u
(6)Two data objects corresponding to the smallest element in the matrix are selected to cluster. Then calculate the similarity between the new cluster and other data objects according to the average distance, update the similarity matrix and delete the original two data objects. Clustering is iterated until the cluster number specified in advance is met However The cluster number cannot be predicted by the decision table formed by the data of equipment simulation training system. The current clustering process should be terminated. On the contrary, we can continue to cluster until all the data objects are processed.
Assuming the final clustering number is L, each cluster is projected into the conditional attribute space to obtain a series of value intervals for each attribute. For example, the data object set of
cluster k is Uk, then the value set of attribute c in the cluster is k c DT : ( ) | ( )
k c
DT u c u U k (7)
Further, the range of attribute in the cluster is:
[ ( ), ( )]
k k k
c c c
R min DT max DT (8) The left and right interval set of attribute c in each cluster is as follows:
( k) | 1, 2,...,
cl c
R min DT k L ,Rcr
max DT( ck) |k1, 2,...,L
(9) The elements of two intervals above are sorted from small to large, and the initial partition interval of the attribute c is obtained as follows:
1 2 2 3
[ , ],[ , ],...,[ L, L]
c cl cl cl cl cl cr
R R R R R R R (10) Interval Merging Based on Compatibility
Before interval merging, it is necessary to determine the priority of merging. According to information theory, entropy reflects the class distribution of data. Further, if the information entropy of the interval is smaller, the higher the consistency of the corresponding class distribution is. Then the importance of the interval is lower.
For the initial interval
1 2 2 3
[ , ],[ , ],...,[ L, L]
c cl cl cl cl cl cr
R R R R R R R
, Rci ,
1
i c
R are two adjacent intervals. According to the information entropy formula (4), the weighted average is used to calculate the information entropy of adjacent intervals.
2 1 | | ( ) | | i d ij i c c i
j c ij
R E R R
∑
㏒ (11)1 1, 1 2 1 1 1, | | ( ) | | i d i j i c c i
j c i j
R E R R
∑
㏒ (12)1
1 | | | | 1
( , ) ( ) ( )
| | | |
i i
i i c i c i
c c c c
R R
E R R E R E R
U U
(13)
During the process of merging, it is necessary to keep the consistency of the whole decision table , which can be treated as the judgment condition of interval merging. In order to achieve this goal, the compatibility ' after merging is calculated and compared with the original compatibility
0
'
. We can avoid the error caused by the traditional artificial threshold setting as the
merging judgment condition.
It is a computationally intensive process to determine the compatibility of the decision table for merging, especially the iterative calculation will take a lot of time. In order to solve the problem, we simplify the calculation process. For other intervals not involved in the merging will not affect the compatibility, that means the consistency of these attribute intervals will not be changed. The specific derivation is as follows:
1 0 1 1
1 1 1
| ( ) : ( ), ' |
'
| |
| ( ) : ( ), | 1
[ ( ) ( ) | | | | ( ) ( ) ( ) ( )] 1 [ ( ) | | k k
k k i i k
i
T
i i
T R R
C c C c
k k i
L i L
R R R R R
C c C c C c C c
k i k k i
R
C c C c
POS Y Y IND D T C
U
POS Y Y IND D T C
POS Y POS Y
U U
POS Y POS Y POS Y POS Y
POS Y POS
U
1( ) 1( )]
i i i
R R R
C c
Y POS Y
(14)
Experiment and Comparative Analysis
Experimental Condition
Six typical datasets are selected from UCI machine learning database, which are Heart disease, Movement, Vehicle, Artistic, Iris plant and Glass. They contain different data samples, condition attributes and category attributes and have been widely used in the field of data mining. Table 4 gives a brief description of the basic information of these six typical datasets.In order to evaluate the effectiveness of DHCC algorithm, five typical discretization algorithms are chosen, including Equal-W, Equal-F, Chimerge, MDLP, and CAIM.
Experimental Design
Step1. Initializes algorithm parameters. The number of discrete initial intervals is set by formula
/ 3
to 0.9. Initial interval of CAIM is set by category attribute. There are no additional parameters for MDLP and DHCC algorithm.
Step2. The experimental datasets are discretized by the above six discretization algorithms respectively. The required discrete datasets are generated. The total number of intervals after discretization and running time of the algorithm are recorded.
Step3. The discretized data is tested by 5 fold cross validation method. 80% of the data is randomly selected as the training set, remaining 20% is selected as the test set. C4.5 algorithm[25] is used to calculate the accuracy of classification.
Comparative Analysis of Experimental Results
Total Number of Intervals Analysis
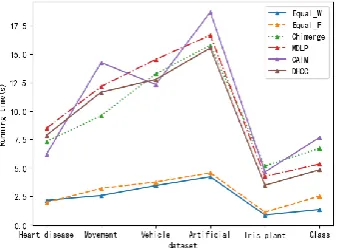
It can be seen from Table 5 and Figure 2 that the total number of average intervals after discretization by DHCC algorithm is the least. Because the hierarchical clustering part of the algorithm can cluster all attributes at one time, which belongs to global discretization. At the same time, combined with the change of positive domain as the termination judgment condition, the unreasonable intervals generated by discretization of single attribute can be avoided. In the interval merging part of DHCC algorithm, Category attribute information is introduced to guide interval merging according to compatibility. CAIM algorithm maximizes the interdependence between condition attributes and category attributes to select the optimal segmentation point, and the number of discrete intervals is relatively small. Statistics and information entropy are used as the basis of interval division in Chimerge and MDLP algorithm.
Accuracy Analysis
It can be seen from Figure 2 that in the six data sets tested, the accuracy of DHCC algorithm has certain advantages over other discretization algorithms. The average ranking of test accuracy is the highest, indicating that Dhcc discretization algorithm generates a better discretization scheme. This is because in the process of hierarchical clustering and interval merging, DHCC algorithm fully considers the correlation between all condition attributes and category attributes, effectively reduces the information loss and avoids the wrong rules in the classification process. The accuracy of Equal-W and Equal-F algorithm is relatively low, mainly because these two algorithms are unsupervised, do not use category attribute information and determine interval division by empirical formula. When the data distribution is unbalanced, it is easy to produce poor interval. Chimerge and MDLP algorithms belong to supervised discretization.
Running Time Analysis
Figure 1. Comparison of total number of intervals. Figure 2. Comparison of accuracy.
Figure 3. Comparison of running time (s).
Conclusion
The quality of data discretization of equipment simulation training system is important and directly related to the speed of data mining and the accuracy of generated rules. The existing discretization algorithms mainly considerer attributes while the relativity and complementarity among attributes are often ignored and separated, which can easily generate wrong rules in actual data of equipment simulation training system with strong interrelationships. In this paper, a discretization algorithm by hierarchical cluster and compatibility (DHCC) is proposed to solve the problem in two steps. The first step is to calculate the positive domain of clusters , thus obtaining the initial partition of each attribute. On the basis of the clustering results, the second step is to use the information entropy and the simplified compatibility difference calculation method to merge the adjacent. The experimental section presents the experimental data, the evaluation metrics, The results indicate that DHCC has some advantages over other algorithms in terms of the total number of intervals and accuracy.
Acknowledgements
This work is supported by the Military Scientific Research No. 41404060205. The authors wish to thank Wen Liang for her help in implementing some discretization methods and making the present form of experiments possible.
References
[1] A. Allendes, F. Fuica, E. Otárola, Adaptive finite element methods for sparse pde-constrained optimization, IMA Journal of Numerical Analysis (2019).
[2] H. L. And, H. Liu, R. Setiono, Chi2: Feature selection and discretization of numeric attributes. International Conference on Tools with Artificial Intelligence (1995).
[image:6.595.213.383.217.342.2][4] R. Bruni and G. Bianchi, Effective classification using a small training set based on discretization and statistical analysis, IEEE Transactions on Knowledge and Data Engineering 27(9) (2015), 2349-2361.
[5] M. Butler, and D. Kazakov, Sax discretization does not guarantee equiprobable symbols, IEEE Transactions on Knowledge and Data Engineering, 27(4) (2015), 1162-1166.
[6] A. Cano, D. T. Nguyen, S. Ventura, UR-CAIM: Improved CAIM discretization for unbalanced and balanced data, Soft Computing 20(2016), 173–188.
[7] J.Catlett, On changing continuous attributes into ordered discrete attributes. in:1991 European Working Session on Learning, Berlin, 164-177.)
[8] M.R. Chmielewski, and J.W. Grzymala-Busse, Global discretization of continuous attributes as preprocessing for machine learning, in: 1994 International Workshop on Rough Sets and Soft Computing, 294-301.
[9] H. Djelassi, M. Glass, A. Mitsos, Discretization-based algorithms for generalized semi-infinite and bilevel programs with coupling equality constraints, Journal of Global Optimization 3 (2019), 1-52.
![2,4 Bis(4 ethoxyphenyl) 1 methyl 3 azabicyclo[3 3 1]nonan 9 one](data:image/gif;base64,R0lGODlhAQABAIAAAP///wAAACH5BAEAAAAALAAAAAABAAEAAAICRAEAOw==)