International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, Volume 2, Issue 11, November 2012)750
Implementation of a New Approach to Mine Web Log Data
Using Mater Web Log Analyzer
Mahadev Yadav
1, Prof. Arvind Upadhyay
21,2
Computer Science and Engineering, IES IPS Academy, Indore India
Abstract - Web is a large and dynamic domain of knowledge and discovery. Many of researcher, technicians and different research organizations are collect and find the important data from web. In this paper, we emphasize on a new approach over the information gathering by the mining of web access logs or web usage data. Our propose framework is composed of five steps. The first step, Web usage based mining on Web Logs Data is applied for preprocessing of web log and extract the formal information from the log file. In next step, User profiling is creating by session identification of same IP Source. In third steps Web Log classification algorithm applied on user profiled data for predict response of server for user request. In forth steps, we analyze the user behavior pattern using frequent pattern analysis algorithms and developed a new modify Apriori algorithm to give the solution with higher optimized efficiency. In the final steps, a comparison between different classification and frequent pattern analysis algorithms is perform with different attribute to know about the behavior of algorithms for different dataset.
Keywords - Web Access Log, Web Log, Web Usage Mining, Log Analyzer, User Profiling.
I. INTRODUCTION
The expansion of the World Wide Web (Web for short) has resulted in a large amount of data that is now in general freely available for user access. The different types of data have to be managed and organized in such a way that they can be accessed by different users efficiently. Thus, Web mining has been developed into an autonomous research area.
Web mining involves a wide range of applications [2] that aims at discovering and extracting hidden information in data stored on the Web. Another important purpose of Web mining is to provide a mechanism to make the data access more efficiently and adequately. The third interesting approach is to discover the information which can be derived from the activities of users, which are stored in log files for example for predictive Web caching [4]. Thus, Web mining can be categorized into three different classes based on which part of the Web is to be mined [2, 3, 4]. These three categories are Web content mining, Web structure mining and Web usage mining.
Decision tree algorithm [10, 11] is used to classify the data into different classes. Association rule Mining is defined, in [12, 13], as the task of finding frequent patterns, associations, correlations, or causal structures among sets of items or objects in transaction databases, relational databases, and other information repositories.
II. RELATED WORK
Many different kinds of tools are designed and developed [1, 2] to extract important information from the web log file.
Table1
Different web log analyzer tool.
Name Firma Type Comments
Web log Parse ACME Labs Softwa re Log files Processi ng
Extract specific fields from a web log file. support different web log format. Web log Darryl C. Burgd orf Log files Analysi s Tool
Keep track of activity on your site by month, week day,pageview byte transfer etc.
Ana log
Univer sity of Cambr idge Log files Analyze r
It tell which page are most popular ,which country people are visited from, etc
The most of tool extract same data from the log. Thus required a new tool by which administrator can extract more and different information from the analysis of web log file.
There are some problem related to existing software are
They don’t work for user personalization.
They are not able to predict what response will be generated by the server for user request.
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, Volume 2, Issue 11, November 2012)751
They perform analysis on huge amount of data ittakes more time to process the data.
To resolve above problem a new analyzer is developed to extract more information from the web usage data with more accuracy and less amount of time. In next secession a step by step working of new approach of web log mining by Master Web Log Analyzer is define.
III. SYSTEM ARCHTECTURE
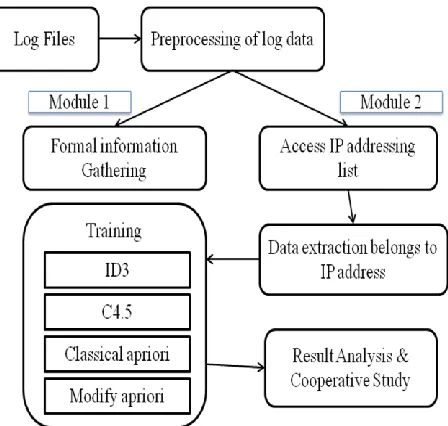
[image:2.612.54.278.308.521.2]The below diagram shows the basic system architecture of the system this system is combination or integrations of different sub system. Sub system can be defined as Group of interconnected parts that performs an important task as a component of a larger system.
Figure 1: Shows the Proposed Architecture of Master Web Log Analyzer
IV. STEP BY STEP PROCESSING OF THE PROPOSED
SYSTEM
This section describes the details of the operation and performance of our proposed multi-purpose analyzer.
A. Import Log File
A software program or server computer equipped to offer World Wide Web access. Web servers allow you to serve content over the Internet using the Hyper Text Markup Language (HTML).The Web server accepts requests from browsers like Netscape and Internet Explorer and then returns the appropriate HTML documents.
A server log [5] is a log file (or several files) automatically created and maintained by a server of activity performed by user. The W3C maintains a standard format (the Common Log Format) for web server log files, but other proprietary formats exist. Web log is click stream data of user navigate with web site. Information about the request, including client IP address, request date/time, page requested, HTTP code, bytes served, user agent, and referrer are typically added.
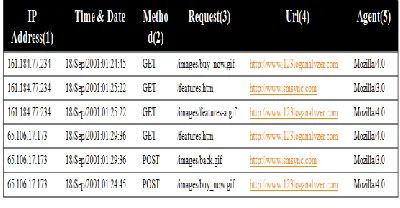
Figure 2: Sample Web Server Log
Common Log Format-
A typical configuration for the access log might look as follows.
161.184.77.234 - - [18/Sep/2001:01:24:45 +0000] "GET /images/buy_now-a.gif HTTP/1.1" 200 1388 http://www.123 loganalyzer.com /buy.htm "Mozilla/4.0 (compatible; MSIE 5.5; Windows 98)"
The format above is from an Apache log. Depending on the type of server the site is on, the log entries may look different. Thousands (or even hundreds of thousands) of entries such as the one above are placed into a plain text file, called the server log.
The above log entry includes the following information: IP address of the requesting computer
161.184.77.234. This is not the user's IP address, but rather the address of the Host machine they've connected to.
Date and time of the request: [18/Sep/2001:01:24:45].That's September 18, 2001 at 1:24:45 pm and the time zone is 5hours behind GMT, which is Eastern Standard Time in the USA (this is because the server is in that time zone, not the user.)
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, Volume 2, Issue 11, November 2012)752
a. Request method: GETb. Requested file: /images/buy_ now -a .gif c. HTTP Protocol version: HTTP/1.1
HTTP Response Code: 200. This particular code means the request was ok.
Response size: 1388 bytes. This is the size of the file that was returned.
Referring document: http://www.123loganalyzer.com /buy . htm.
User-Agent String (Browser & Operating system information):"Mozilla/4.0 ( compatible ; MSIE 5.5; Windows 98)"
B.Preprocessing of Web Access Log Data
[image:3.612.75.275.345.449.2]In preprocessing of web log data[7, 9], we remove parts of the original web log data that are not relevant in our mining process. After that we get the web log data as
Figure 3: Preprocessed Web Log Data
161.184.77.234 is the IP address (client) that can be used to mind personal usage and the result can be applied in Personalized Systems, Recommender Systems and Pre-fetched System.
18/Sep/2001:01:24:45 is the date time data that is intended to support the Web Site Maintainers, GET/images/buy_now.gif is full HTTP request which
contain HTTP request and file. It support web site developer to know about which keywords are frequently uses by the users.
http://www.123loganalyzer.com is the domain name. Our analyzer is to know which IP frequently uses which sites for which purposes.
Mozilla/4.0 is user agent. Our analyzer is to know which browser used by user.
C. Mining of usage Information –
The analyzer[1] identify different IP address request, different method, web browser used by user, No. of hit on the server etc.
To fulfill our purposes, we propose our own procedures that may be useful for various domain areas.
Procedure 1.1 find different IP address request to server
Input: Database D of transactions, Output: List of distinct IP address Method
string str = "select distinct IPAddress from D"; int i = 0;
while (dr.Read()) {
Ips.Capacity = i+1; Ips.Add(distinctIP); i = i + 1;
}
Return IPList;
The above procedure creates a list of different IPAddress which are navigate with the web server. This list help for user profiling to create a data set for particular user.
Procedure 1.2 finds different Agent used by user Input: Database D of transactions,
Output: List of distinct Agent Method
string str = "select distinct agent from tblInfo1 "; int i = 0;
while (dr.Read()) {
i = i + 1; }
Return AgentList;
The above procedure returns a list of user browser used by different user.
Procedure 1.3 find different session Input: Database D of transactions, Output: List of session
Method
string str = "select source from tblInfo1 where source='New'";
int i = 0;
while (dr.Read()) {
i = i + 1; }
Return session;
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, Volume 2, Issue 11, November 2012)753
D. User Profiling
[image:4.612.51.284.233.565.2]User Profile[6] contains the information related to user navigation with the web server. Different user session is maintained in user profile. It contain all the filled of user preprocessed data and one column to represent the session number. It creates a Dataset according to IP address of the user. It helps to process user navigation with deferent web site.
Figure 4: A general architecture for web usage mining
Procedure 1.4 find different session of user Input: Database D of transactions, Output: List of session
Method
string str = "select D where IPAddress="selected_IP";
int i = 0;
while (dr.Read()) {
dataset.Capacity = i+1; dataset.add(str);
i = i + 1; }
Return dataset;
The procedure help to identify different user session .it help to create user profile.
E.Web Log Classification
Decision Tree[7] is use to classifying data using attributes. The tree consists of decision nodes and leaf nodes. A decision node has two or more branches, each representing values for the attribute tested. A leaf node attribute produces a homogeneous result (all in one class), which does not require additional classification testing.
There are two different decision tree algorithms is used to classify user profiled data to identify the response of server for the user request.
ID3 and C4.5 decision tree algorithms[11,12] is used to predict the response of server ,they work over the Entropy and information gaining with respect to different attribute and generate a tree.
The working of ID3:-
ID3 is mathematical algorithm [11] for building the decision tree Invented by J. Ross Quinlan in 1979. It uses Information Theory invented by Shannon in 1948. Information Gain is used to select the most useful attribute for classification.
First the entropy of the total dataset is calculated. The dataset is then split on the different attributes. The entropy for each branch is calculated. Then it is added proportionally, to get total entropy for the split.
The resulting entropy is subtracted from the entropy before the split.
The result is the Information Gain, or decrease in entropy.
The attribute that yields the largest IG is chosen for the decision node.
A branch set with entropy of 0 is a leaf node. Otherwise, the branch needs further splitting to
classify its dataset.
The ID3 algorithm is run recursively on the non-leaf branches, until all data is classified.
The formula to calculate entropy and information gain: c
Entropy(s) = Σ Pi log2 Pi i=1
Gain (A) = E (Current set) – Σ E (all child sets)
The working of C4.5:-
Test – entropy:
If S is any set of samples, let freq (Ci, S) stand for the number of samples in S that belong to class Ci (out of
k possible classes), and S denotes the number of samples in the set S.
Then the entropy of the set S:
Info(S) = - ( (freq(Ci, S)/ S) log2 (freq(Ci, S)/ S))
After set T has been partitioned in accordance with n outcomes of one attribute test X
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, Volume 2, Issue 11, November 2012)754
Then Gain is identified with respect to attribute XGain(X) = Info(T) - Infox(T)
Criterion: select an attribute with the highest Gain value.
F.Mining frequent item set
Discovering, extracting the frequent pattern of clients’ usage, with respect to request, method, web sites, user agent. Web usage based mining algorithm for frequent pattern analysis [12,13] is used to identify different frequent pattern used by the user. First classical apriori algorithm is apply on user dataset .there are some problem with their performance observed then a new modify apriori algorithm is developed to increase the performance of analyzer and reduce the time requirement.
Itemset X = {x1, …, xk}
Find all the rules X Y with minimum support and confidence
◦ support, s:
support (X ⇒Y ) = (no of tuples contain X and Y) /( total no of tuples)
◦ confidence, c:
Confidence (X ⇒Y ) = (no of tuples contain X and Y) / ( total no of tuples contain X) AYL
Modify Apriori Algorithm -
The traditional Apriori algorithm [12] is most frequently used by different researchers and groups to mine log data. This algorithm has some problem with their performance we observe that when the item set are increased then the time and memory required is increased exponent manner. To overcome this problem we propose a new Apriori algorithm.
Apriori (T, ms, input set)
Initialize k← 1, C1←{1-itemsets} L1 ← {frequent 1-itemsets} K ← 2
While Lk-1 ≠ ∅ {
Ck ← {c| c=a U {b} ˄ a ϵ Lk-1 ˄ b ϵ ⋃Lk-1 ˄ b ∉ a}
For transactions t ϵ T {
If (t == input set) {
Ct ← { c | c ⊑ t ^ | c | = k } C ← { c | c ϵ Ck ˄ c ϵ Ct } Count[c] ← Count[c]+1 }
}
Lk ←{c |c ϵ Ck ˄ Count[c] ≥ ms} K ← K+1
}
Return ⋃ Lk k
V. IMPLIMENTATION RESULTS
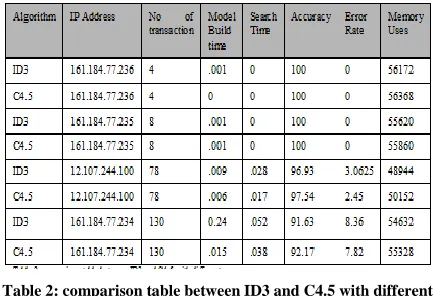
[image:5.612.335.552.411.559.2]The work focused on extracting different hidden information from web log file. User profiling helps to analyze different users and there navigation pattern among the web sites with more accuracy and less amount of time. Use of enhanced version of decision tree ID3 and C4.5 algorithm for classification provides accurate prediction for different request and response of server.
Table 2: comparison table between ID3 and C4.5 with different attribute
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, Volume 2, Issue 11, November 2012) [image:6.612.60.278.133.439.2]755
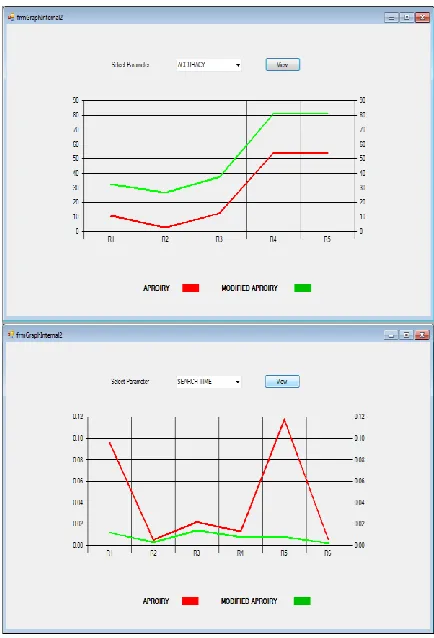
Figure 5 and 6: Modal build time and Search time Comparison between ID3 and C4.5 Algorithm
Improved Apriori algorithm of finding frequently accessed patterns reduces time consumption and improves accuracy.
The rules generated by modify apriori algorithm are:
1,0.8752 -user use GET method 87% of the time
3, 0.751-user use http://www.123loganalyzer .com 75% of the time.
4,0. 752 - user use Mozilla/4.0 75% of the time.
3 4, 0.75- user use http://www.123loganalyzer .com and use Mozilla/4.0 75% of the time.
1 2 4, 0.625 - user use GET method , /images/ buy_now.gif and Mozilla/4.0 75% of the time. 1 3 4, 0.752 - user use GET http://www.123log analyzer
.com and use Mozilla/4.0 75% of the time.
[image:6.612.335.552.138.266.2]Comparison between Traditional Apriori and Modify Apriori Algorithm
Table 2: comparison table between Traditional Apriori and Modify Apriori Algorithm with different attribute
The graph represents in between Traditional Apriori and Modify Apriori Algorithm with respect to accuracy and Search time.
Figure 7 and 8: Accuracy and Search time Comparison between Traditional Apriori and Modify Apriori Algorithm
[image:6.612.335.552.333.652.2]International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, Volume 2, Issue 11, November 2012)756
VI. CONCLUSIONThe work focused on extracting different hidden information from web log file. The new approach to mine web log data using User profiling helps to analyze different users and there navigation pattern among the web sites with more accuracy and less amount of time. Use of enhanced version of decision tree ID3 and C4.5 algorithm for classification provides accurate prediction for different request and response of the server. Improved Apriori algorithm of finding frequently accessed patterns reduces time consumption and improves the accuracy. Our system provide analyzed data for Web Site Maintainers, Web Site Developers, Personalization Systems, Pre-fetched Systems, Recommendation Systems and Web Site Analysts, etc to improve the performance of the web by preference to the patterns navigated by the regular interested users.
REFERENCE
[1 ] Theint Theint Shwe, Thida Myint , Framework for Multi -purpose Web Log Access Analyzer 978-1-4244- 63497/10/$26.00 _ 2010 IEEE V3-289
[2 ] Kosala, R., Blockeel, H., (2000). Web Mining Research: A Survey, ACM 2(1):1-15.
[3 ] Cooley, R., Mobasher, B. Srivastava, J., (1997). Web Mining: Information and Pattern Discovery on the World Wide Web, 9th
International Conference on Tools with Artificial Intelligence ICTAI ’ 97) , New Port Beach, CA, USA, IEEE Computer Society, 558-567.
[4 ] Brijendra Singh1, Hemant Kumar Singh2 WEB DATA MINING RESEARCH: A SURVEY 978-1-4244-5967-4/10/$26.00 ©2010 IEEE
[5 ] Karl Groves “The Limitations of Server Log Files for Usability Analysis” on 2007/10/24 |
[6 ] Georgios Lappas ,From Web Mining to Social Multimedia Mining 978-0-7695-4375-8/11 $26.00 © 2011 IEEE DOI10.1109ASONAM.2011
[7 ] Tasawar Hussain, Dr. Sohail Asghar, Dr. Nayyer Masood Web Usage Mining: A Survey on Preprocessing of Web Log File 978-1 4244-8003- 6/10/2010
[8 ] Aamshad Mobasher, Robert Cooley, and Jaideep Srivastava “Prsonalization Based On Web Usage Mining” August2000/Vol.43, No. 8 COMMUNICATIONS OF THE ACM
[9 ] Theint Theint Aye.” Web Log Cleaning for Mining of Web Usage Patterns” 978-1-61284-840-2/11/$26.00 ©2011 IEEE
[10 ]Peng Zhu, Ming-sheng Zhao Session Identification Algorithm for Web Log Mining, 978-1-4244-5326-9/10/$26.00 ©2010 IEEE [11 ]Stmik Amilkom yogyakarta ,”Implementation of C4.5 algorithm to
evaluate the cancellation possibility of new student application”at isbn 978-979-16338-0-2.
[12 ]Wei Peng, Juhua Chen and Haiping Zhou An Implementation of ID3 – Decision Tree Learning Algorithm
[13 ]Sandeep Singh Rawat , Lakshmi Rajamani,” Probability Apriori based Approach to Mine Rare Association Rules”978-1 61284-212-7/11/$26.00 ©2011 IEEE
[14 ]Huiping Peng “Discovery of Interesting Association Rules Based on Web Usage Mining” 978-0-7695-4136-5/10 $26.00 © 2010 IEEE [15 ]Yanyu Zhang, Yonggong Ren, A Method of Predicting Users`