2364
A Comparative Study Between The Application Of
The Existing MDP And The Enhanced MDP Model
In Modeling Students Comprehension In A
Multimedia Learning Environment
Achi Ifeanyi Isaiah, Agwu Chukwuemeka Odi, Alo Uzoma Rita, Ogbu Nwani Henry
Abstract: The analysis of an existing process or model in order to discover the weakness and then developing an improved version of that same process or model has become one of the best practices of software engineering in recent times. The (Markov Decision Process) MDP is an effective mathematical modeling tool used for Sequential Decision Making (SDM) under uncertainty and has been used in many other fields such as manufacturing, industrial, medicine and so on but has been underutilized in the Decision Making Process (DMP) of the educational sector. Therefore, this research paper provides a comparative study on the application of the existing (standard) MDP and the improved MDP model s in modeling the student’s comprehension in a multimedia learning environment under uncertainty. The improved Markov decision processes integrate the decision making process in the model to ensure that multiple decisions are made in a shorter time. Hence, the significant advantages over the standard MDP. This paper compares the improved MDPs model to the standard MDP models by solving the problem of modeling students in a multimedia modeling system in order to assign the optimal learning style to the learning student using both models. Both models result, when comp ared to each other, is the same in providing the optimal policy for obtaining and assigning the optimal learning style to the learning students but different in the time of arriving at a decision. The result obtained from the experiment performed shows that the computation time for sol ving the improved MDP model is significantly smaller than that of solving with the standard MDP model.
Keywords: Markov decision processes, decision analysis, Markov processes
————————————————————
1. INTRODUCTION
The MDP model has been an integral part of solving critical problems of decision-making process in the field of artificial intelligence especially in the aspect of machine learning [1]. This complex problem requires the use of a more advanced MDP model. Previously, problems were solved using the existing, standard MDP model. This model has some setbacks especially in their inability to model and solve very complex outcomes or events (problems) in a shorter time, especially when outcomes or events occur (or may reoccur) over a range of time. As a result of these setbacks, this paper profers a solution by proposing the enhanced MDP as a better mathematical modeling tool than the existing standard existing MDP model. This enhanced MDP model could model recurrent problems faced within the learning environment states and future events. Since the introduction of the existing MDP for solving real-life problems by Berkenkamp F, Turchetta M, Schoellig A, and Krause A., [2] the model has become more popular and their usage has grown so much especially in modeling states in a learning environment. Hence, the need for the improvement of this standard existing MDP by proposing the enhanced MDP that is more effective than the existing MDP in problem solving not only in the learning domain but to the world at large.
However, the existing, standard MDP model cannot be used in a very complex sequential decision-making process[3] whereby problems are represented in steps of the iteration process. This implies that a large number of embedded decision nodes will be generated along the path of the decision making process[4]. Again, computation done by the existing MDP model is impractical most especially when there are large numbers of possible embedded decisions. This is because each iteration in a standard existing MDP model can evaluate only one set of decision rules at a time [4] as against the improved or enhanced MDP model. For example, consider a learning system whereby each learning student is assigned a learning style based on one time modeling process of a sample student as against the enhanced model where each individual student is sequentially or dynamically modeled so as to assign the optimal learning style to each student from the available three learning styles as presented in this paper. The purpose of this paper is to provide a comparative study between the existing MDP model and the enhanced MDP model and to demonstrate the use of both the existing and the enhanced MDP model to solve a decision based problem with sequential decisions that must be made under uncertainty. MDP is a very vital mathematical modeling tool which has been used in various areas such as industries, financial institutions, manufacturing and inventory control system[5] just to mention but a few. It has been used in the field of education and in a learning environment but not to the extent of dynamically modeling students in learning environment which is the focuses of this paper. This paper presents three learning styles to each learning students and we did apply both existing and the enhanced MDP in modeling students' comprehension state. The three learning styles presented in this paper are as follows audio, visual(textual) and hybrid learning style. For each learning style, one out of the three is expected to be the optimal learning style for the learning student. In this paper, both the existing and the enhanced models were subjected to the same modeling process and then the outcome from both
______________________
Achi I. I. is currently pursuing a doctorate degree program in Computer Science, University of Nigeria, Nsukka, Nigeria, PH-2347039147549, Email: [email protected]
AGWU C.O., is a PhD holder in Computer Science Department, Ebonyi State University, Abakaliki, Nigeria. PH-2348033954892, Email: [email protected]
Alo R. U., is a PhD holder in Computer Science, Alex Ekwueme Federal University, Ndufu-Alike, Nigeria, PH-2347034477250, Email: [email protected]
2365 processes was evaluated. We conclude from our result that the
enhanced MDP model is a better model tool than that the existing MDP model.
2. Review of Existing MDP Application in
Modeling
This research paper explores MDP applications in modeling generally prior to its application in modeling student comprehension in a multimedia learning environment as described in this paper. Among these, is the work done by Mota et al [5] given a set of available learning materials, this approach enables the ITS to track the students’ difficulties and provide the right material at the right time. They modeled the learning process using the existing MDP, the Partially Observable Markov Decision Process (POMDP), where the hidden information corresponds to the student’s familiarity with each of the topics to be learned. After teaching, quiz and tests are used to monitor the comprehension state of the learning students.Their performance in those test exercises now forms the basis for which the ITS uses to determines the optimum learning material for the student. John W. Coffey [6] in his work came up with intelligent or adaptive tutoring systems which focused on how to determine what resources to present to students as they make their way through a course of study. This decision on how to determine the best resource to present to the student was achieved using the existing MDP model. Zhu X, et al [7] presented in their work a theoretical study of machine teaching in the setting where the teacher must use the same training set to teach multiple learners. This problem is a theoretical abstraction of the real-world classroom setting in which the teacher delivers the same lecture to academically diverse students. They defined a minimax teaching criterion to guarantee the performance of the worst learner in the class. They also proved that the teaching dimension increases with class diversity. They concluded that effort and time required to ramp-up a system is largely dependent on the effectiveness of the human decision-making process to select the most promising sequence of steps that will provide the optimum performance required by the system. Doltsinis et al [8] in their work used the existing MDP based model to choose the best sequence of action that improves the system by producing the desired output irrespective of the time involved. Hasibuan et al[9] in their work used the existing MDP to model a system that enables the user to choose the best learning approach from the two options given-data driven and literature base. It depends on the learner's prior knowledge to attain accuracy in choosing the learning style for each learning students. Both approaches focus on retrieving data from the interaction of learners from the system and use it as the basis for selecting the optimum learning style. However, according to researchers, the learner interaction approach to this system only has an accuracy value below 80 %. Hamtini in his work [10] describes a dynamic technique that used MDP model for identifying learners best learning styles based on their behavior in the learning environment influenced by the literature approach. Allen, L et al [11] based their research om an existing system called the iSTART which was used to model student reading comprehension ability. In their work,they determined student reading comprehension based on evaluating the student on how the student can explain the content read to another person.This was achieved using the self-explanation performance algorithm and does not adapt content based on reading ability. This decision was arrived at
using the MDP modeling tool which helped to determine the best way the student can achieve comprehension. The self-explanatory algorithm on its own is based on the natural language processing technique of artificial intelligence which was used to build models of students' comprehension ability from the linguistic properties of their self-explanations. Yahya et al [12] in their work, adopted a decision support system based on MDP in e-learning in order to model the visual-auditory-kinesthetic learning style focusing on learning disabilities children. Hence, proposed an e-learning decision support system architecture to estimate students’ learning style automatically using the literature-based method. The calculation to estimate each of the student’s learning styles is based on number of visits and the time spent on learning objects with respect to the visual-auditory-kinesthetic learning style.is ok
3. THE EXISTING MDP MODEL
A Markov decision process (MDP) is a discrete-time stochastic decision process that provides a mathematical model for modeling both simple and complex decision making in situations where outcomes could be partly random(Partially observable MDP) and partly under the control(Constrained MDP) of a decision maker. MDP is a four-tuple (S,A,Pa,Ra) [13] where
S is a finite set of states
A is a finite set of actions available from state s Pa(s.S’) = Pr(St+1= s’|St = s, at=a) is the probability that
action a in state s in time t will lead to s’ in time t+1 Ra(s,S’)is the immediate reward (or expected
immediate reward) received after transitioning from state s to S’ due to action a
The aim of MDPs is to [14]
i. Obtain the value function for a state s which is defined in terms of the well known Bellman equations and ii. to find an optimal policy that maximizes the value
function in each state of the MDP, typically the expected discounted sum over a potentially infinite horizon:
1 0
( , ) ( \ _ \ _{} ( ), . .
t
t
a t t t t
t
R s s where we choose displaystyle a t pi s t a s i e actions given by the policy
Where
the discount is a factor and satisfies0
1
(for example
1 / (1
r
)
when the discount rate is r.).
is typically close to 1[14]. The essence of the discount factor is to ensure that the decision maker takes action early and does not postpone them indefinitely.This MDP aim could be achieved via a. dynamic programming
b. Value iteration Process and c. Policy Iteration Process
This research adopted the Policy iteration Process to achieve that goal.
2366
4. Solving for MDP
In solving MDP, the solution is a policy that describes the best action for each state in the MDP, known as the optimal policy [16]. The best action is the one that has the highest reward value. This optimal policy can be found through a variety of methods, but this research is focused on using the Policy iteration method.
The algorithm for solving the Policy Iteration Process is summarized in two steps[16]:
i. Value Update which is achieved by solving the equation below
( ) ( )
( ) :
s( , )
s( , )
( )
s
V s
P
s s
R
s s
V s
ii. Policy Update is also obtained using the equation below
( ) : argmaxa ( , ) ( , ) ( )
s
s P s s a R s s a V s
∣ ∣ The elaborate version of the algorithm is as follows[16]: a. Initialization
Choose an arbitrary policy π’ and compute using the equation
b. Policy Evaluation using the equation
( ) ( )
( ) :
s( , )
s( , )
( )
s
V s
P
s s
R
s s
V s
Repeat Until v = V’ c. Policy Improvement
( ) : argmax
a(
, )
(
, )
( )
s
s
P s s a R s s a
V s
∣
∣
Repeat Until π = π’ Else Go to b d. End
5. THE ENHANCED MDP MODEL
The enhanced MDP shares several attributes with the standard, existing MDP like the same framework (component), same goal. The difference is on how each model achieves the set goal. The goal of an MDP is to obtain the value function via value iteration process for a state s which is defined in terms of the well known Bellman equations and to find an optimal policy that maximizes the value function in each state of the MDP via policy iteration process, typically the expected discounted sum over a potentially infinite horizon [17]:
6. COMPARING BOTH MODELS
The difference between the enhanced MDP and the standard, existing MDP is on how both models perform the MDP goal that is in obtaining the value function for each state which is achieved by value iteration, dynamic programming and policy iteration. In this paper, the policy iteration process algorithm was used to calculate the value function
i. Value Function
In order to get the value function in the enhanced MDP modeling, the π in the equation for solving for value function in the existing MDP model is not used in the enhanced MDP model instead the value of π(s) is calculated within V(s) whenever it is needed. Substituting π(s) in the calculation of
V(s)} ensures that there is no continuous repetition of steps until convergence which is really time-consuming. Bellow is the enhanced MDP model
1
( ) : max
( , )
( , )
( ) ,
i a a a i
s
V
s
P s s R s s
V s
Where i is the iteration number. Value iteration starts at i = 0 and V0 as a guess of the value function. It then iterates, repeatedly computing Vi+1 for all states s, until V converges with the left-hand side equal to the right-left-hand side which was included as a special case of the value iteration method for MDPs.
ii. Policy Iteration
In the standard, existing policy iteration process, step one is performed once, and then step two is repeated until it converges [18]. If there is no convergence, then step one is again performed once and so on, until convergence is achieved. But in the enhanced policy iteration process, instead of repeating step two to convergence, it may be formulated and solved as a set of linear equations. These equations are merely obtained by making s = s’ in step two equation[13].Thus, repeating step two to convergence can be interpreted as solving the linear equations by Relaxation (iterative method). This variation has the advantage that the process is not infinite.That the process has a definite stopping condition: which is when the array π does not change in the course of the iteration process ,which is done by applying step 1 to all states until convergence is attained and then completing the algorithm. This condition in the enhanced MDP model policy iteration process is usually why the enhanced MDP model is preferred to the existing MDP model. This is because the enhanced MDP model is faster than the existing, standard MDP model especially for a large number of possible states. Below is the algorithm of the enhanced policy iteration process:
i. Initialization
Students Modeling Time(minutes)
(Existing Model)
Modeling Time(minutes) (Enhanced Model)
LS1 LS2 LS3 Total LS1 LS
2
LS3 Total
Student A
26 31 33 90 12 20 11 43
Student B
21 15 24 60 10 12 12 34
Student C
44 38 18 100 19 13 16 48
Student D
33 15 17 65 11 12 10 31
Student E
2367 starts at i = 0 and V0’ and compute using the equation
ii. Policy Evaluation using the equation
1
( ) : max
( , )
( , )
( )
,
i a a a i
s
V
s
P s s
R s s
V s
iii. Policy Execution iv. End
7. Evaluating the modeling Processes
To further validate our findings on both modeling processes, an experiment was performed which exposed both modeling process to two lecturers, from two universities in Nigeria. One from Ebonyi State University (EBSU) and the other from Alex Ekwueme Federal University Ndufu Alike, Ikwo(AE-FUNAI), that is each lecturer used both the enhanced and the standard existing MDP model in modeling learning students from both institutions of higher learning. This paper allowed each lecturer to select five students each at random from both institutions, irrespective of their age, level, and department. Both models presented a multimedia system with three learning styles. The idea is to find out the optimum learning style, that is the learning style that best suit each learning student. The learning styles presented by these models are audio, video(textual) and hybrid (audio and video) learning style. The focus of this paper is to compare both models and find out the advantage(s) of the enhanced MDP model over the standard existing MDP model. As well stated in the previous section, the advantage is time-based. The enhanced MDP model is faster in solving complex problems than the existing MDP model. The result obtained in the experiment has also validated that fact. The experiment is based on modeling the various students by teaching them an introductory course in Biology using the proposed three learning styles - audio, visual (textual) and hybrid. The result of the data collected from the experiment is shown below:
i. Lecturer (From EBSU) has the following data
Table 1: Showing data obtained from EBSU modeling
Below is the graph that compares the total minutes spent on the modeling process against each student for both model for EBSU:
0 20 40 60 80 100 120
Existing Model
Enhanced Model
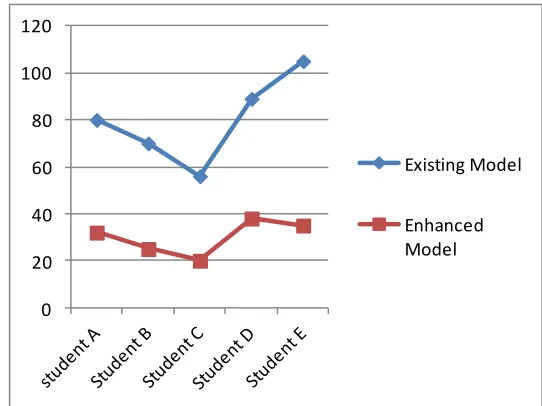
ii. Data from the lecturer from AE-FUNAI
From the table below LS1, LS2, LS3 represents Learning Style 1,2 and 3 respectively.
Table 2: Showing the data obtained from AE-FUNAI
StudeStudents
Modeling Time(minutes) (Existing Model)
Modeling Time(minutes) (Enhanced Model)
L S 1
LS
2 LS3
Tota l
LS 1
LS 2
LS
3 Total
Student
A 30 29 21 80 11 10 11 32
Student
B 23 22 25 70 08 09 08 25
Student
C 19 18 19 56 07 06 07 20
Student
D 44 33 22 89 12 12 14 38
Student
E 46 37 22 105 12 11 12 35
Below is the graph that compares the total minutes spent on the modeling process against each student for both model for AE-FUNAI:
0 20 40 60 80 100 120
Existing Model
Enhanced Model
CONCLUSION
This paper compared the existing MDP model with the enhanced MDP model and highlighted the weakness of the existing MDP and the strength of enhanced MDP modeling tool and to recommend the enhanced MDP modeling tool as a better mathematical modeling tool for solving problem of modeling student in a multimedia learning environment. In the world of today, time is everything. No one wants to continue solving a problem with a tool that is time-consuming. The MDP model is an Artificial intelligence, Reinforcement learning-based tool used to solve complex problems, especially in decision-making domain. From our study which was validated by the experiment performed, we can come to this conclusion that the enhanced MDP model is preferred to the existing MDP model because it consumes less time than the existing MDP model.
2368 [1] Henderson P., Islam R., Bachman P., Pineau J., Precup D.,
and Meger D., (2017). Deep reinforcement learning that matters. arXiv:1709.06560 [cs.LG]
[2] Berkenkamp F., Turchetta M., Schoellig A., and Krause A., (2017). Safe model-based reinforcement learning with stability guarantees. In Advances in Neural Information Processing Systems 30, ed.
[3] Islam R., Henderson P., Gomrokchi M., Precup D., (2017). Reproducibility of benchmarked deep reinforcement learning tasks for continuous control. In: Proceedings of the ICML 2017 workshop on Reproducibility in Machine Learning (RML). doi: https://arxiv.org/pdf/1708.04133.pdf [4] Rosolia U., and Borrelli F., (2018). Learning model
predictive control for iterative tasks. A data-driven control framework. IEEE Trans. Autom. Control 63: 1883–96 [5] Mota P., Francisco S. M., and Lu´ısa C.,. (2015). Modeling
students self-studies behaviors. In Proceedings of the 14th International Conference on Autonomous Agents and Multiagent Systems, pages 1521–1528.
[6] John W. C., (2016). A Framework for a Multi-Faceted, Educational, Knowledge-Based Recommender System, Systemics, Cybernetics, and Informatics, Volume 14 - Number 4, ISSN: 1690-4524
[7] Zhu X., Liu J., and Lopes M., (2017). No Learner Left Behind: On the Complexity of Teaching Multiple Learners Simultaneously. Proceedings of the Twenty-Sixth International Joint Conference on Artificial Intelligence
(IJCAI-17). pages 3588-3594. doi:
https://doi.org/10.24963/ijcai.2017/502
[8] Doltsinis S., Ferreira P., and Lohse N., (2014). An MDP model-based reinforcement learning approach for production station ramp-up optimization: Q-learning analysis, IEEE Trans. Syst. Man Cybern. Syst., vol. 44, no. 9, pp. 1125-1138.
[9] Hasibuan M. S., Nugroho L. E., Santosa P. I., Hasibuan M. S., Nugroho L. E., and Santosa P. I., (2018). 4th International Conference on Science and Technology (ICST): 7-8 Aug. 2018,18233754.
[10] Said H. M., Edi N. L., and Insap S. P., (2018). Model E-learning MDP for Learning Style Detection Using Prior Knowledge. International Journal of Engineering &
Technology, 7(4.40), 118-122. doi:
http://dx.doi.org/10.14419/ijet.v7i4.40.24416118-122 [11] Allen, Laura & Snow, Erica & McNamara, Danielle.
(2015). Are you reading my mind?: modeling students' reading comprehension skills with natural language processing techniques. 246-254.
[12] Yahya W. F. F., and Noor N. M. M., (2015), Decision Support System for Learning Disabilities Children in Detecting Visual-Auditory-Kinesthetic Learning Style, 7th International Conference on Information Technology, pp. 667-671, doi: 10.15849/icit.2015.0115
[13] Compare M., Marelli P., Baraldi P., and Zio E., (2018). A markov decision process framework for optimal operation of monitored multi-state systems, Proceedings of the Institution of Mechanical Engineers Part O Journal of Risk and Reliability.
[14] Li H., Wei T., Ren A., Zhu Q., and Wang Y., (2017). Deep reinforcement learning: Framework, applications, and embedded implementations: Invited paper. 2017 IEEE/ACM International Conference on Computer-Aided
Design (ICCAD), pages 847-854. doi:
https://arxiv.org/pdf/1710.03792.pdf
[15] Carrilho E., Cardoso M., Ferreira M. M., Marto C.M., Paula A.B., & Coelho A.S., (2019). 10-MDP Based Dental Adhesives: Adhesive Interface Characterization and Adhesive Stability — A Systematic Review. Materials. doi:10.3390/ma12050790
[16] Zhang X., Wu B., and Lin H., (2016). Assume-guarantee reasoning framework for MDP-POMDP, in CDC, IEEE, pp. 795-800.
[17] Zheng W., Wu B., and Lin H., (2018). POMDP model learning for human robot collaboration, arXiv:1803.11300v1 [cs.HC].