770 | P a g e
A Distributed Approach to Web Text Using Trust Based
Ranking
G.Pudhviraj
1, E. Raju
21
M.Tech,
2Associate professor
Dept. of Computer Science & Engineering, Dhruva Institute of Engineer and Technology (India)
ABSTRACT
Evaluative works on the Web have transformed into an essential wellspring of conclusions on things,
organizations, events, individuals, et cetera. Starting late, various researchers have thought such feeling
sources as thing reviews, gathering posts, and web diaries. Nevertheless, existing examination has been
revolved around portrayal and summary of evaluations using customary tongue planning and data mining
frameworks. A fundamental issue that has been neglected so far is conclusion spam or reliability of online
sentiments. In this paper, we inspect this issue as to thing overviews, which are notion rich and are
comprehensively used by clients and thing producers. In the past two years, a couple of new organizations in
like manner showed up which all out sentiments from thing reviews. It is along these lines high time to study
spam in overviews. To the best of our knowledge, there is still no conveyed study on this topic, regardless of the
way that Web spam and email spam have been investigated generally. We will see that conclusion spam is
completely special in connection to Web spam and email spam, and in this way requires particular revelation
methodology. In perspective of the examination of 5.8 million reviews and 2.14 million experts from
amazon.com, we exhibit that supposition spam in overviews is sweeping. This paper looks at such spam
practices and shows some novel techniques to recognize them.
Categories and Subject Descriptors H.3.3 [Information Storage and Retrieval]: Information Search and
Retrieval – Information filtering. H.2.8: [Database Management]: Database Applications – Data mining
General Terms Experimentation, Human Factors
Keywords Opinion Rating, review text, fake reviews, review analysis
1. INTRODUCTION
The Web has fundamentally changed the way that people impart and work together with others. They can now
post reviews of things at merchant destinations and express their points of view and speak with others by
method for online diaries and examinations. Such substance contributed by Web customers is all in all called the
customer made substance (rather than the substance gave by Web site proprietors). It is in a matter of seconds
especially seen that the customer made substance contains gainful information that can be abused for a few
applications. In this paper, we focus on customer reviews of things. In particular, we inquire about conclusion
spam in reviews. Overviews contain rich customer conclusions on things and organizations. They are used by
771 | P a g e
used by thing producers to recognize thing issues and/or to find promoting learning information about their
opponents [7].
In the past couple of years, there was a creating eagerness for mining evaluations in reviews from both the
informed group and industry. Regardless, the present work has been basically revolved around removing and
sketching out suppositions from reviews using normal tongue planning and data mining frameworks [7, 12, 19,
20, 22]. Little is pondered the characteristics of reviews and practices of examiners. There is moreover no
reported study on the reliability of suppositions in overviews. As a result of the path that there is no quality
control, anyone can create anything on the Web. This results in various low quality reviews, more deplorable
still overview spam.
Study spam resemble Web page spam. With respect to Web look for, due to the money related and/or notoriety
estimation of the rank position of a page returned by a web record, Web page spam is no matter how you look at
it [3, 5, 10, 12, 16, 24, 25]. Website page spam implies the usage of "illegitimate means" to help the rank
positions of some target pages in web look devices [10, 18]. With respect to studies, the issue is tantamount, also
extremely assorted.
It is in no time greatly fundamental for people to examine sentiments on the Web for a few reasons. Case in
point, if one needs to buy a thing and sees that the reviews of the thing are generally positive, one is subject to
buy the thing. If the reviews are generally negative, one is obligated to pick another thing. Constructive
conclusions can realize basic fiscal advantages and/or reputations for affiliations and individuals. This gives
extraordinary inspirations for review/conclusion spam. There are all things considered three sorts of spam
reviews:
Sort 1 (untruthful suppositions): Those that purposefully mislead perusers or evaluation mining structures by
giving undeserving positive overviews to some target articles remembering the finished objective to propel the
things (which we call hyper spam) and/or by giving unreasonable or poisonous negative reviews to some
distinctive things with a particular final objective to hurt their reputation (which we call defaming spam).
Untruthful overviews are in like manner consistently known as fake reviews or fake studies. They have
transformed into a genuine exchange subject in web diaries and social events. A late study by BursonMarsteller
(http://www.bursonmarsteller.com/Newsroom/Lists/BMNews/DispForm.aspx?ID=3645) found that a growing
number of customers are watchful about fake or uneven reviews at thing study destinations and dialogs. Articles
on such reviews moreover appeared in driving news media, for instance,CNN
(http://money.cnn.com/2006/05/10/news/associations/bogus_reviews/) and New York
Times(http://travel.nytimes.com/2006/02/07/business/07guides.html). These show that review spam has
transformed into a critical issue. Sort 2 (reviews on brands only): Those that don't comment on the things in
reviews especially for the things however simply the brands, the producers or the traders of the things.
Regardless of the way that they may be profitable, we consider them as spam since they are not engaged at the
specific things and are routinely uneven. Sort 3 (non-studies): Those that are non-reviews, which have two
essential sub-sorts: (1) advertisements and (2) other unessential reviews containing no suppositions (e.g.,
request, answers, and unpredictable compositions). In perspective of these sorts of spam, this paper reports an
examination of review spam revelation. Our examination relies on upon 5.8 million overviews and 2.14 million
772 | P a g e
activities are wide. Case in point, we found a broad number of duplicate and close duplicate studies made by the
same investigators on different things or by different observers (possibly unmistakable user-ids of the same
persons) on the same things or various things. The major duty of this paper is: It makes the primary try to
analyze supposition spam in reviews and proposes some novel strategies to study spam acknowledgment (except
for some wide trades on the subject in [15]). Overall, spam distinguishing proof can be seen as a portrayal issue
with two classes, spam and non-spam. Nevertheless,on account of the specific method for different sorts of
spam, we have to oversee them in a sudden way. For spam reviews of sort 2 and sort 3, we can recognize them
in perspective of ordinary gathering learning using physically checked spam and non-spam overviews in light of
the fact that these two sorts of spam reviews are obvious physically. The guideline errand is to find a course of
action of practical components for model building. In any case, for the essential sort of spam, manual stamping
by basically examining the reviews is hard, if not endless, in light of the way that a spammer can exactly make a
spam study to propel a target thing or to hurt the reputation of another thing that is much the same as some
different guiltless review. We then propose a novel way to deal with study this issue. We first discuss what sorts
of studies are ruinous. For example, a spam review that approvals a thing that every expert preferences (gives a
high assessing) is not incredibly hurting. In any case, a spam overview that scolds a thing that by far most like
can be extraordinarily risky. We then need to manufacture a model to examine only these likely dangerous
reviews. In any case, the issue is that there is no checked planning outline. Fortunately, we found a broad
number of duplicate and close duplicate reviews which are probably spam overviews. Using them to collect
spam acknowledgment models can envision those possible pernicious reviews in light of present circumstances.
Is essentially all the all the more captivating that we furthermore found a get-together of pundits who may have
made various spam reviews.
II. RELATED WORK
Analysis of on-line assessments transformed into a noticeable examination subject starting late. As we said in
the past portion, current studies are fundamentally based on mining evaluations in reviews and/or request studies
as positive or negative in light of the thoughts of the investigators [7, 12, 15, 29, 19, and 22]. This paper focuses
on considering feeling spam practices in reviews. Since we will likely recognize spam practices in reviews, we
discuss some flow take a shot at spam research. Possibly, the most broadly analyzed subject on spam is Web
spam. The objective of Web spam is to make web files to rank the target pages high with a particular deciding
objective to attract people to visit these pages. Web spam can be organized into two central sorts:Content spam
and association spam. Join spam can't avoid being spam on hyperlinks, which does not exist in reviews as there
is by and large no association among them. Content spam tries to incorporate irrelevant or remotely vital words
in target pages to trap web crawlers to rank the target pages high. Various masters have considered this issue
[e.g., 3, 5, 9, 10, 11, 12, 16, 23, 24, 25, and 26]. Review spam is exceptionally differing. Counting irrelevant
words is of minimal offer help. Or maybe, spammers make undeserving positive reviews to propel their target
things and/or malevolent negative studies to hurt the reputation of some other target objects. Another related
examination is email spam [8, 14, 21], which is in like manner extremely not exactly the same as review spam.
Email spam generally suggests unconstrained business advancements. In spite of the way that exist, sees in
773 | P a g e
4.2). Untruthful conclusion spam is much harder to oversee. Late studies on spam also contacted recommender
structures, where they are called attacks [17]. Regardless of the way that the objectives of strikes to
recommender structures resemble review spam, their essential contemplations are exceptionally particular. In
recommender structures, a spammer mixes some ambush profiles to the system with a particular finished
objective to get a couple of things progressively (or less) as frequently as could reasonably be expected
endorsed. A profile is a course of action of examinations (e.g., 1-5) for a movement of things. The recommender
structure uses the profiles to anticipate thing assessing of a singular customer or a social occasion of customers.
The spammer regularly does not see other customers' assessing profiles. With respect to thing reviews, there is
no comprehension of profiles. Each review is only for a particular thing, and is not used for any desire. In like
manner, the expert can see all overviews for everything. Rating is simply part of an overview and another
guideline part is the review content. [27] Considers the utility of reviews in perspective of standard vernacular
highlights. Spam is a considerably more broad thought including an extensive variety of flawed activities. Our
work in [14] introduced the issue of study spam, and sorted particular sorts of spam reviews. Nevertheless, it did
little study on perceiving untruthful reviews/suppositions.
III. OPINION DATA AND ANALYSIS
Before talking about how to recognize conclusion spam, let us first portray the information utilized as a part of
this study and demonstrate a few practices of the information.
3.1 Review Data from Amazon.com
In this work, we use reviews from amazon.com. The reason for using this data set is that it is tremendous and
covers a broad assortment of things. Amazon.com is seen as a champion amongst the best e-exchange Web
destinations with a by and large long history. It is in this way sensible to consider it as a representative from
amazon.com in June 2006.
Table 1.
Various features of different categories of products
We could isolate 5.8 million reviews, 2.14 observers and 6.7 million things (the watchful number of things
offered by amazon.com could be much higher since it just demonstrates a most great of 9600 things for each
sub-characterization). Each amazon.com's review includes 8 areas we used 4 essential classes of things in our
study, i.e., Books, Music, DVD and products (industry manufactured things like equipment, PCs, et cetera). The
amounts of studies, assessed things and pundits in each class in our study are given in Table 1. These genuine
774 | P a g e
Furniture and Décor which has around 60000 things (the fourth greatest) yet only 2100 examined things, were
rejected.
3.2 Reviews, Reviewers and Products
Before focusing on the review spam, let us first have some vital information about overviews, experts, things,
evaluations and feedback on reviews. We first look at overviews, observers and things. Specifically, we exhibit
the going with plots: 1. Number of overviews versus number of analysts 2. Number of overviews versus number
of things Note that we don't designate "number of experts versus number of things" as it is about the same as (2)
above in light of the way that all reviews for each thing were formed by unmistakable investigators
(notwithstanding the way that there are some duplicate studies for a thing as we will discover in Sections 4 and
5 when we explore spam practices in reviews). As anybody may expect, these associations all take after the
power law scattering. A power law relationship between two sums x and y can be formed as k y = ax, where an
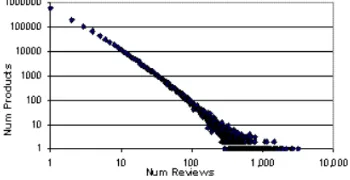
and k are constants. In case we take the log on both sides, we get a straight line on a log-log plot. Figure 1
exhibits the log-log plot of "number of overviews versus number of observers". We can see that a far reaching
number of analysts form only a couple overviews, and two or three investigators make innumerable. There are 2
experts with more than 15,000 reviews, and 68% of analysts created only 1 review. Only 8% of analysts formed
no under 5 reviews. Figure 2 exhibits the log-log plot of "number of overviews versus number of things". Yet
again, we can see that endless get not a lot of overviews and somewhat number of things get endless. Case in
point, half of things have only 1 study. Only 19% of the things have no under 5 reviews. Undoubtedly, the
relationship between the amount of reactions (perusers accommodate reviews to indicate whether they are
valuable) and the amount of overviews in like manner about takes after the power law spread. Figure 3 gives
this plot. The diagram is barely lower for the underlying few centers (diverged from an immaculate straight
line), which has overwhelmingly reviews with under 5 reactions. We can see thata large number of reviews get a
very smallnumber of feedbacks and a small number of reviews get a large number of feedbacks.
Figure 1. Log-log plot of number of reviews to number of members for amazon.
775 | P a g e
Figure 3.Log-log plot of number of reviews to number of feedbacks for amazon.
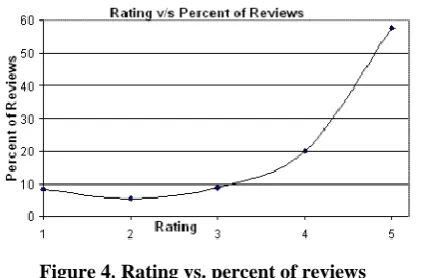
Figure 4.Rating vs. percent of reviews
3.3 Review Ratings and Feedbacks
The review rating and the review feedback are two of the most important items in reviews. This section briefly
discusses these two items.
Review Rating: Amazon uses a 5-point rating scale with 1 being the most recognizably horrendous and 5 being
the best. A larger piece of studies have high assessments. Figure 4 exhibits the rating movement. On amazon,
60% of the reviews have a rating of 5.0. Since a substantial bit of the reviews have high evaluations, most by far
of the things and people similarly have a high ordinary rating. Around 45% of things and 59% of people have a
typical rating of 5, which suggests that the rating of every review for these things and people is 5.
Review Feedbacks: Amazon grants perusers to give steadiness feedback to each review. As we see over, the
amount of reactions on reviews takes after a long tail scattering (Figure 3). All things considered, a review gets
7 inputs. The rate of positive reactions of a review reduces rapidly from the central overview of a thing to the
last. It tumbles from 80% for the primary overview to 70% for the tenth review. This shows the underlying few
overviews can be particularly convincing in picking the offer of a thing.
Beside rating and information, overview body, review title and review length are similarly basic things. On
account of space imperatives, we can't present their examinations. A bare essential study driven and examiner
driven examination is given in our specific report [13], which moreover fuses examination of various other
entrancing segments, e.g., rating deviations, observer situating, et cetera.
IV. SPAM DETECTION
Amazon grants perusers to give steadiness feedback to each review. As we see over, the amount of reactions on
reviews takes after a long tail scattering (Figure 3). All things considered, a review gets 7 inputs. The rate of
776 | P a g e
80% for the primary overview to 70% for the tenth review. This shows the underlying few overviews can be
particularly convincing in picking the offer of a thing.
Beside rating and information, overview body, review title and review length are similarly basic things. On
account of space imperatives, we can't present their examinations. A bare essential study driven and examiner
driven examination is given in our specific report [13], which moreover fuses examination of various other
entrancing segments, e.g., rating deviations, observer situating, et cetera.
Make a spam review which is much the same as whatever other genuine review. We endeavored to scrutinize
incalculable and were not capable constantly recognize sort 1 spam reviews physically. In like manner, diverse
courses must be examined remembering the deciding objective to find get ready case for perceiving possible
sort 1 spam reviews.
Peculiarly, in our examination, we discovered endless and close duplicate reviews. Our manual examination of
such studies shows that they certainly contain some compose 2 and sort 3 spam reviews. We are in like manner
sure that they contain sort 1 spam reviews as an aftereffect of the going with sorts of duplicates (the duplicates
join close duplicates):
1. Copies from various userids on the same item.
2. Copies from the same userid on various items. 3. Copies from various userids on various items
.
Figure 5. Similarity score and number of pairs of reviews for different sub-categories. Points on X axis
are intervals. For example, 0.5 means between interval [0.5, 0.6).
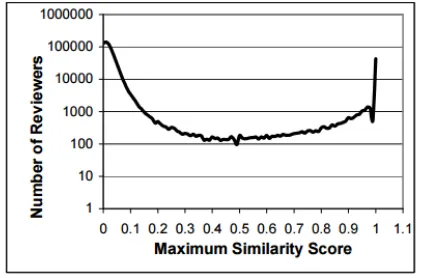
Figure 6. Maximum similarity score and number of members.
Most of such reviews (with sort 2 and sort 3 spam restricted) are probably untruthful conclusion spam (sort 1).
Note that duplicates from the same customer on the same thing may not be spam as we will see later.
Thus our review spam area takes the going with framework. In any case, we distinguish duplicates and close
777 | P a g e
checked cases. Finally, we endeavor to perceive untruthful evaluation spam (sort 1), which abuses the above
three sorts of duplicates and other germane information.
4.1 Detection of Duplicate Reviews
Duplicate and close duplicate (not exact) reviews can be recognized using the shingle system as a piece of [4].
In this work, we use 2-gram based overview content relationship. The similarity score of two reviews is the
extent of joining of their 2-grams to the union of their 2-grams of the two studies, which is regularly called the
Jaccard partition [6]. Review sets with similarity score of no under 90% were picked as duplicates.
Figure 5 plots the log of the amount of overview sets with the comparability score for four assorted Sub-classes:
each having a spot with one of the four foremost arrangements books, music, DVDs and mProducts. The
sub-classes are word composing (305894 reviews), dynamic music (65682 reviews), appear (177414 reviews), and
office electronic things (22020 overviews). All the sub-groupings carry on vaguely to each other. We also took a
gander at the studies of other sub-groupings. The practices are about the same. On account of space controls, we
can't show each one of them. Note that it doesn't look good to use greater classes since they contain absolutely
particular things and their reviews are unmistakably through and through various.
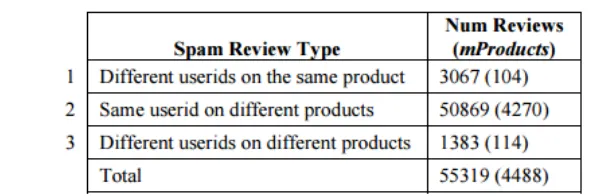
Table 2. Three sorts of copy spam audits on all items and on classification mProducts
From Figure 5, we watch that the amount of sets reductions as the likeness score increases. It rises after the
closeness score of 0.5 and 0.6. The climb is for the most part in light of the cases that people copied their
reviews on one thing to another or to the same thing (with minor changes).
Figure 6 plots the log of the amount of pundits with the most compelling closeness score. The best similarity
score is the most compelling of likeness scores between different reviews of an expert. For 90% of the reporters
with more than one overview, the most compelling likeness score is under 0.1 (10%), since they investigated
unmistakable things. The amount of experts augmentations after the best likeness score of 0.6. 6% of the
reporters with more than one review have a most great closeness score of 1, which is a sudden skip exhibiting
that various investigators copy reviews. In for the most part half of the cases, an expert displayed the same study
various times for a thing. There were moreover a few examples of different people (or the same people with
various userids) creating near overviews on the same or assorted things, however little in number.
Around 10% of the reporters with more than 1 review created more than one review on no short of what one
thing. In 40% of these cases, the overviews were made around the same time with the same rating, body and title
(exact duplicates). In 30% of the cases studies were made around the same time yet had some diverse qualities
that are unmistakable. In 8% of the cases, a man formed more than 2 reviews on a thing.
Note that all around if a man has more than one overview on a thing, most of these reviews are exact duplicates.
778 | P a g e
We checked the amazon.com site and discovered this was without a doubt possible. Some others are moreover
in view of amendment of mistakes in past passages.
For spam removal, we can delete all duplicate reviews which have a spot with any of the three sorts depicted
above, i.e., (1) duplicates from different userids on the same thing, (2) duplicates from the same userid on
different things, or (3) duplicates from different userids on different things. For various sorts of duplicates, we
may need to keep only the last copy and empty the rest. Table 2 shows the amounts of reviews in the above
three arrangements. The essential number of the second portion of each line is the amount of such reviews in the
whole review database. The second number inside "()" is the amount of such cases in the order mProducts. In
the going with study, we focus just onreviews in the order of mProduct, which has 228422 overviews. Studies in
various groupings can be focused nearly.
V. ANALYSIS OF TYPE 1 SPAM REVIEWS
From the presentation of Section 4, we can construe that sort 2 and sorts 3 spam reviews are truly easy to
perceive. Duplicates are easily found too. Recognizing sort 1 spam reviews is, in any case, outstandingly
troublesome as they are not easily unmistakable physically. Along these lines, we don't have physically stamped
get ready data for learning. With a particular finished objective to study sort 1 spam reviews, let us separate
what sorts of studies are dangerous and are at risk to be spammed.
Table 3. Spam reviews vs. product quality
Allow us to survey what sort 1 spam reviews hope to finish:
1. To propel some goal things, e.g., one's own specific things (development spam).
2. To hurt the reputation of some other target objects, e.g., aftereffects of one's opponents (scrutinizing spam).
To fulfill the above objectives, the spammer generally takes both or one of the exercises: (1) make undeserving
positive reviews for the target articles with a particular final objective to propel them; (2) create noxious
negative overviews for the target things to hurt their reputation. Table 4 gives a clear point of view of sort 1
spam. Spam studies in areas 1, 3 and 5 are customarily made by producers out of the thing or persons with direct
money related or distinctive premiums in the thing. They will probably propel the thing. Notwithstanding the
way that conclusions imparted in range 1 may be substantial, analysts don't report their hostile situation. Note
that awesome, dreadful and typical things can be portrayed in light of ordinary evaluations given to things.
Spam reviews in districts 2, 4, and 6 are inclined to be created by contenders.
Despite the way that emotions in reviews of locale 4 may be substantial, examiners don't report their hostile
circumstance and have malevolent intensions.
Clearly, spam studies in area 1 and 4 are not all that hurting, while spam reviews in regions 2, 3, 5 and 6 are
outstandingly risky. As needs be, spam acknowledgment systems should focus on recognizing overviews in
779 | P a g e
5.1 Model Building Using Duplicates
To ensure that duplicates can be used as a piece of desire, we ought to verify that the models gathered checking
them are to make certain judicious. We thusly performed tests using duplicates as positive planning delineations
and whatever is left of the reviews as negative get readycase to make logistic backslide models.
Table 4
.
AUC values on duplicate spam reviews.
In model building, we simply use reviews from the class mProducts. Thusly our data set has 4488 duplicate
spam studies (Table 2) and 218514 distinct reviews. We performed 10-fold cross endorsement on the data. It
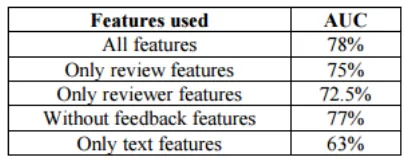
gives us the ordinary AUC estimation of 78% (Table 5) using every one of the segments portrayed as a piece of
Section 4.2.2 (no component overfit duplicates). This AUC worth is totally high considering that various no
duplicate studies may be spam and in like manner have practically identical probabilities as spam reviews. Table
5 furthermore gives the ordinary AUC estimations of different segment blends. Study driven segments are by
and large valuable. Using simply content parts gives only 63% AUC, which exhibits that it is to a great degree
difficult to recognize spam overviews using content substance alone. Going along with every one of the parts
gives the best result. This shows duplicates are obvious.
Clearly, amassing the logistic backslide model using duplicates and non-duplicates is not for distinguishing
duplicate spam since duplicates can be perceived easily using content examination (see Section 4.1). Our bona
fide configuration is to use the model to recognize sort 1 spam reviews that are not duplicated. The above
examination results show that the model is insightful of duplicate spam. To encourage assert its consistency, we
have to show that it is moreover insightful of reviews that will presumably be spam and are not duplicated, i.e.,
abnormality studies. That is, we use the logistic backslide model to check whether it can envision exemption
studies.
Abnormality reviews are those whose assessments go awry from the ordinary thing evaluating an amazing game
plan. They will most likely be spam studies than ordinary reviews since high assessing deviation is a principal
condition for a dangerous spam study (zones 2, 3, 5 and 6 in Table 4) however not satisfactory in light of the
fact that a couple of reporters may truly have various points of view from others. Along these lines, spam studies
are by and large those with special case assessments (clearly, the inverse is not legitimate) and fall in those
pernicious regions of Table 4. Note that a man may create a spam overview with a fair (dreadful) assessing to an
average (loathsome) thing so that his/her review will fall in region 1 (4) to escape being distinguished as an
irregularity in light of rating, however gives a horrendous (not too bad) review similarly as its substance. Such
cases are not inclined to be various in light of the way that reviews are in like manner scrutinized by human
customers who can without quite a bit of a stretch perceive such overviews as spam. Supposition plan
techniques [22] may be used to thusly consign a rating to an overview only in perspective of its review content.
In case our gathering model produced checking duplicates can predict special case overviews, figuratively
780 | P a g e
logistic backslide model amassed using duplicate spam reviews can be used to foresee spam reviews that are not
replicated. For the going with figures, the test data set, which is not used as a piece of get ready, involves only
those non-replicated reviews.
VI. CONCLUSIONS
This paper concentrated on conclusion spam in surveys, which to the best of our insight has not been
contemplated in the writing. The paperfor a dangerous spam study (zones 2, 3, 5 and 6 in Table 4) however not
satisfactory in light of the fact that a couple of reporters may truly have various points of view from
others.Along these lines, spam studies are by and large those with special case assessments (clearly, the inverse
is not legitimate) and fall in those pernicious regions of Table 4.Note that a man may create a spam overview
with a fair (dreadful) assessing to an average(loathsome) thing so that his/her review will fall in region 1 (4) to
escape being distinguished as an irregularity in light of rating,
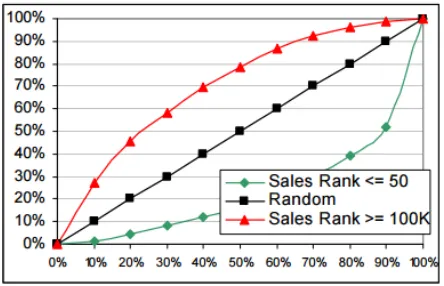
Figure 7. Lift curves for reviews corresponding to products with different sales ranks.
however gives a horrendous (not too bad) review similarly as its substance. Such cases are not inclined to be
various in light of the way that reviews are in like manner scrutinized by human customers who can without
quite a bit of a stretch perceive such overviews as spam. Supposition plan techniques [22] may be used to thusly
consign a rating to an overview only in perspective of its review content.
In case our gathering model produced checking duplicates can predict special case overviews, figuratively
speaking, (high lift, see underneath), we will have the ability to proclaim with some level of conviction that the
logistic backslide model amassed using duplicate spam reviews can be used to foresee spam reviews that are not
replicated. For the going with figures, the test data set, which is not used as a piece of get ready, involves only
those non-replicated reviews.
REFERENCES
[1]. E. Amitay, D. Carmel, A. Darlow, R. Lempel & A. Soffer. The connectivity sonar: detecting site functionality by structural patterns. Hypertext’03, 2003.
[2]. M. Andreolini, A. Bulgarelli, M. Colajanni & F. Mazzoni. Honeyspam: Honeypots fighting spam at the
source. In Proc. USENIX SRUTI 2005, Cambridge, MA, July 2005.
[3]. R. Baeza-Yates, C. Castillo & V. Lopez. PageRank increase under different collusion topologies.
781 | P a g e
[4]. A. Z. Broder. On the resemblance and containment of documents. In Proceedings of Compression and
Complexity of Sequences 1997, IEEE Computer Society, 1997.
[5]. C. Castillo, D. Donato, L. Becchetti, P. Boldi, S. Leonardi, M. Santini, S. Vigna. A reference collection for
web spam, SIGIR Forum’06, 2006.
[6]. S. Chakrabarti. Mining the Web: discovering knowledge from hypertext data. Morgan Kaufmann, 2003.
[7]. K. Dave, S. Lawrence & D. Pennock. Mining the peanut gallery: opinion extraction and semantic classification of product reviews. WWW’2003.
[8]. I. Fette, N. Sadeh-Koniecpol, A. Tomasic. Learning to Detect Phishing Emails. WWW2007.
[9]. D. Fetterly, M. Manasse& M. Najork. Detecting phraselevel duplication on the World Wide Web.
SIGIR’2005.
[10]. Z. Gyongyi& H. Garcia-Molina. Web Spam Taxonomy. Technical Report, Stanford University, 2004.
[11]. M. R. Henzinger: Finding near-duplicate web pages: a large-scale evaluation of algorithms. SIGIR’06,
2006.
[12]. M. Hu & B. Liu. Mining and summarizing customer reviews. KDD’2004.
[13]. N. Jindal and B. Liu. Product Review Analysis. Technical Report, UIC, 2007. [14]. N. Jindal and B. Liu.
Analyzing and Detecting Review Spam. ICDM2007.
[15]. W. Li, N. Zhong, C. Liu. Combining Multiple Email Filters Based on Multivariate Statistical Analysis.
ISMIS 2006.
[16]. B. Liu. Web Data Mining: Exploring hyperlinks, contents and usage data. Springer, 2007.
[17]. A. Metwally, D. Agrawal, A. Abbadi. DETECTIVES: DETEcting Coalition hiT Inflation attacks in
advertising Etworks Streams. WWW2007.
[18]. B. Mobasher, R. Burke & J. J Sandvig. Model-based collaborative filtering as a defense against profile
injection attacks. AAAI'2006.
[19]. A. Ntoulas, M. Najork, M. Manasse& D. Fetterly. Detecting Spam Web Pages through Content Analysis. WWW’2006.
[20]. B. Pang, L. Lee & S. Vaithyanathan. Thumbs up? Sentiment classification using machine learning
techniques. EMNLP’2002.
[21]. A-M. Popescu and O. Etzioni. Extracting Product Features and Opinions from Reviews. EMNLP’2005.
[22]. M. Sahami and S. Dumais and D. Heckerman and E. Horvitz. A Bayesian Approach to Filtering Junk
{E}-Mail. AAAI Technical Report WS-98-05, 1998.