Fully Secure Unbounded Inner-Product and
Attribute-Based Encryption
Tatsuaki Okamoto NTT
[email protected] Katsuyuki Takashima
Mitsubishi Electric
[email protected] November 28, 2012
Abstract
In this paper, we present the first inner-product encryption (IPE) schemes that are
unboundedin the sense that the public parameters do not impose additional limitations on the predicates and attributes used for encryption and decryption keys. All previous IPE schemes werebounded, or have a bound on the size of predicates and attributes given public parameters fixed at setup. The proposed unbounded IPE schemes are fully (adaptively) secure and fully attribute-hiding in the standard model under a standard assumption, the decisional linear (DLIN) assumption. In our unbounded IPE schemes, the inner-product relation is generalized, where the two vectors of inner-product can be different sizes and it provides a great improvement of efficiency in many applications. We also present the first
Contents
1 Introduction 3
1.1 Background . . . 3
1.2 Our Results . . . 5
1.3 Key Techniques . . . 7
1.4 Notations . . . 9
2 Dual Pairing Vector Spaces by Direct Product of Symmetric Pairing Groups 9 3 Decisional Linear (DLIN) Assumption 10 4 Definitions of Generalized Inner-Product Encryption (IPE) and Attribute-Based Encryption (ABE) 11 4.1 Generalized Inner-Product Encryption . . . 11
4.2 Attribute-Based Encryption with Non-Monotone Access Structures . . . 12
5 Proposed IPE Schemes 15 5.1 Type 1 IPE Scheme . . . 15
5.2 Type 2 IPE Scheme . . . 30
5.3 Type 0 IPE Scheme . . . 31
6 Proposed ABE Schemes 32 6.1 Basic KP-ABE Scheme . . . 32
6.2 Modified KP-ABE Scheme with Arbitrary Degree . . . 37
6.3 Basic CP-ABE Scheme . . . 39
7 Consistent Randomness Amplification (Proof Outline of Lemma 24) 40 7.1 Basic Changes . . . 40
7.2 Combinations of Basic Changes . . . 42
7.3 Highlighted Transformation for the Proof of Lemma 24 . . . 44
Appendices 48 A Proofs of Lemmas 48 A.1 Proofs of Lemmas 3 and 4 in Section 5.1.4 . . . 48
A.2 Proofs of Lemmas 9–13 in Section 5.1.6 . . . 49
A.3 Proofs of Lemmas 15–21 in Section 5.1.8 . . . 55
A.4 Proofs of Lemmas 23 and 24 in Section 6.1.3 . . . 62
A.5 Proofs of Lemmas 25–29 in Section 6.1.4 . . . 82
B Proposed Fully Secure Unbounded Anonymous HIBE Scheme 87 B.1 Construction . . . 88
1
Introduction
1.1 Background
1.1.1 IPE and ABE
The notions ofinner-product encryption(IPE) andattribute-based encryption(ABE) introduced by Katz, Sahai and Waters [7] and Sahai and Waters [20] constitute an advanced class of en-cryption,functional encryption (FE), and provide more flexible and fine-grained functionalities in sharing and distributing sensitive data than traditional symmetric and public-key encryption as well as identity-based encryption (IBE).
In FE, there is a relation R(v, x), that determines whether a secret key associated with a parameter v can decrypt a ciphertext encrypted under another parameterx. The parameters for IPE are expressed as vectorsx(for encryption) andv(for a secret key), whereR(v, x) holds, i.e., a secret key with v can decrypt a ciphertext with x, iff v·x = 0. (Here, v·x denotes the standard inner-product.) In ABE systems, either one of the parameters for encryption and secret key is a set of attributes, and the other is an access policy (structure) or (monotone) span program over a universe of attributes, e.g., a secret key for a user is associated with an access policy and a ciphertext is associated with a set of attributes, where a secret key can decrypt a ciphertext, iff the attribute set satisfies the policy. If the access policy is for a secret key, it is called key-policy ABE (KP-ABE), and if the access policy is for encryption, it is ciphertext-policy ABE (CP-ABE).
For some applications, the parameters for encryption are required to be hidden from cipher-texts. To capture the security requirement, Katz, Sahai and Waters [7] introduced attribute-hiding (based on the same notion for hidden vector encryption (HVE) by Boneh and Waters [5]), a security notion for FE that is stronger than the basic security requirement, payload-hiding. Roughly speaking, attribute-hiding requires that a ciphertext conceal the associated parameter as well as the plaintext, while payload-hiding only requires that a ciphertext conceal the plaintext. A weaker notion of attribute-hiding than the original one [7] was given by [8]. The weaker notion is calledweakly attribute-hiding, and the original one isfully attribute-hiding. Informally, in the fully attribute-hiding, the secrecy of attribute x is ensured even against an adversary having a secret key with v such that R(v, x) holds (i.e., no information is released on x except R(v, x) holds), while it is ensured only whenR(v, x) does not hold in the weakly attribute-hiding (see Definition 5 for the definition of the fully attribute-hiding).
To the best of our knowledge, the widest class of attribute-hiding FE is IPE [7, 8, 14, 16] (KSW08, LOS+10, OT10 and OT12 schemes). Inner-products for IPE represent a fairly wide class of relations including equality tests as the simplest case (i.e., anonymous IBE and HVE are very special classes of attribute-hiding IPE), disjunctions or conjunctions of equality tests, and, more generally, CNF or DNF formulas. We note, however, that inner-product relations are less expressive than a class of relations (on span programs) for ABE, while existing ABE schemes for such a wider class of relations are not attribute-hiding but only payload-hiding.
Among the existing IPE schemes, only the OT12 IPE scheme [16] achieves thefull (adaptive)
1.1.2 Unbounded IPE and ABE
All previous constructions of IPE and ABE except the Lewko-Waters ABE scheme [11] have restriction, or arebounded, in the choice of the parameters for secret key and encryption once the public parameters have been set. The onlyunbounded ABE scheme [11], however, is selectively
secure, while they presented an unbounded hierarchical identity-based encryption (HIBE) that isfully securein the standard model. NounboundedIPE scheme has been presented. Therefore, no fully secureandunbounded scheme for an advanced class of encryption like IPE or ABE has been presented.
In practice, it is highly desirable that the parameters for secret key and encryption should be flexible or unbounded by the public parameters fixed at setup, since if we set the public pa-rameters for a possible maximum size (e.g., the maximum dimension of predicate and attribute vectors for IPE), the size of the public parameters should be huge.
Removing the restrictions for fully secure IPE and ABE, however, is quite challenging. As mentioned above, nofully secureandunboundedscheme for an advanced class of encryption like IPE or ABE has been presented. The difficulty resides in the existing techniques for proving thefull (or adaptive) security of such an advanced class of encryption.
The only known technique to prove the full security of an (attribute-hiding) IPE or ABE system is the dual system encryption by Waters [21] and its extension [16]. In the techniques, information theoretical arguments (e.g., conceptual change due to the same distribution and the independent randomness of two distributions etc.) over some (hidden) parts of a secret-key and challenge ciphertext play a key role in the security proof, provided that the adversary follows the secret-key-query condition in the security games. To execute a security proof based on the information theoretical arguments, an appropriate distribution of randomness consistent with the key-query condition should be supplied in the proof games transformed from the original proof game.
As for bounded IPE and ABE schemes, the public parameters can supply immanent ran-domness enough for the arguments, since the size of parameters for secret-keys and encryption is bounded by the public parameters. For example, when the dimension of vectors for IPE is required to be n, the public parameters whose size is O(n) with respect to n should be given in bounded IPE, and the size of secret randomness to generate the public parameter is O(n2). Such an amount of randomness can be enough for the arguments overn-dimensional vectors.
1.1.3 Restriction on IPE
The existing IPE schemes have another restriction on the parameters (i.e., vectors) for secret key and encryption that the dimensions of x (for encryption) and v (for a secret key) should be equivalent. Such a restriction may be considered to be inevitable for the inner-product relation onv·x, but it is required to be relaxed in various applications to improve the efficiency, especially inunboundedIPE systems where the setup (public) parameters give no restriction on the dimensions of vectors.
Let us consider an example on a genetic profile data of an individual. It is desirable that such a sensitive data be treated as encrypted data even for data processing and retrievals. Although a genetic profile may include a large amount of information, only a part of the profile is examined in many applications. For example, let X1, . . . , X100 be variables of 100 genetic properties andx1, . . . , x100 be Alice’s values of these variables. To evaluate iff(x1, . . . , x100) = 0 for any examination (multivariate) polynomial f with degree 3, or the truth value of the corresponding predicateφf(x1, . . . , x100), the attribute vector x of Alice should be a monomial vector of Alice’s values with degree 3,x:= (1, x1, . . . , x100, x21, x1x2, . . . , x2100, x31, x21x2, . . . , x3100), whose dimension is around 106. A predicate vectorv for a secret key can be associated with predicateφf.
To ensure the private data processing of x, it should be encrypted (say cfor a ciphertext of
x) by afully attribute-hidingIPE scheme, since whetherφf(x1, . . . , x100) holds can be examined with releasing no other information by checking whether c can be decrypted by a secret key withv (i.e.,R(v, x) holds). Here, if cis encrypted by fully attribute-hiding IPE, it releases no information onxexcept thatR(v, x) holds, orφf(x1, . . . , x100) holds, however, if it is encrypted by weaklyattribute-hiding IPE, such desirable security cannot be ensured.
Let a predicate for v be ((X5 = a) ∨(X16 = b))∧(X57 = c), which focuses only three factors, X5, X16, X57, among the 100 genetic properties. It can be represented by a polynomial equation,r1(X5−a)(X16−b) +r2(X57−c) = 0 (where r1, r2←UFq), i.e., (r1ab−r2c)−r1bX5− r1aX16+r2X57+r1X5X16= 0. In order thatr1(x5−a)(x16−b) +r2(x57−c) = 0 iffv·x= 0, vector v should be ((r1ab−r2c),0, . . . ,0,−r1b,0, . . . ,0,−r1a,0, . . . ,0, r2,0, . . . ,0, r1,0, . . . ,0), whose dimension is equivalent to that ofx, i.e., around 106, although the effective dimension of v is just 5. This is due to the above-mentioned restriction on the inner-product relation of the existing IPE schemes. The size of secret key forvthen should be in proportion to the dimension of v (andx), around 106. This example shows us a strong practical motivation, especially for
unbounded IPE schemes, to relax this restriction on the inner-product relation and to shorten the length of the secret key to that in proportion to the effective dimension, e.g., 5, instead of around 106.
1.2 Our Results
1. This paper introduces a new concept of IPE, generalized IPE, which relaxes the above-mentioned restriction of IPE and consists of three types of IPE, Types 0, 1 and 2. Here the notion of Types 1 and 2 is introduced in this paper, and Type 0 is the traditional one (see Remark below).
ap-Table 1: Comparison of attribute-hiding IPE schemes, where |G|and |GT|represent size of an element of G and that of GT, respectively. AH, IP, PK, SK, CT, GSD and eDDH stand for attribute-hiding, inner-product, master public key (public parameters), secret key, ciphertext, general subgroup decision [3] and extended decisional Diffie-Hellman [8], respectively. And, n:=Iv andn :=Ix. (Then, n=n except for the proposed unbounded IPE schemes.)
KSW08 [7] LOS+10 [8] OT10 [14] OT12 [16] Proposed IPE
(basic) (variant) (type 1 or 2) Section 5.1
(type 0) Section 5.3
Bounded or
Unbounded bounded bounded bounded bounded unbounded
Restriction on
IP relation restricted
∗ restricted restricted restricted relaxed restricted
Security selective & fully-AH
adaptive & weakly-AH
adaptive & weakly-AH
adaptive & fully-AH
adaptive & fully-AH Order
ofG composite prime prime prime prime
Assump. 2 variants
of GSD n-eDDH DLIN DLIN DLIN
PK size O(n)|G| O(n2)|G| O(n2)|G| O(n2)|G| O(n)|G| O(1)|G| O(1)|G| SK size (2n+ 1)|G| (2n+ 3)|G| (3n+ 2)|G| (4n+ 2)|G| 11|G| (15n+ 5)|G| (21n+ 9)|G|
CT size (2n+ 1)|G| +|GT|
(2n+ 3)|G| +|GT|
(3n+ 2)|G| +|GT|
(4n+ 2)|G| +|GT|
(5n+ 1)|G| +|GT|
(15n+ 5)|G| +|GT|
(21n+ 9)|G| +|GT|
* It can be easily relaxed.
plication. Here note that we abuse the same vector notation, v, for the new expres-sion as well as for the conventional one, (v1, . . . , vn). In the above-mentioned exam-ple, x := {(1,1),(2, x1), . . . ,(101, x100),(102, x21),(103, x1x2), . . . ,(n, x3100)} where Ix := {1,2, . . . , n}, and v := {(1, r1ab− r2c),(6,−r1b),(17,−r1a),(58, r2),(517, r1)} where Iv:={1,6,17,58,517}. The generalized inner-product ofvoverxis defined byt∈I
vvtxt
ifIv⊆Ix. Otherwise, it is undefined. By using the generalized inner-product notion, the secret key size can be in proportion to the effective dimension (e.g., 5 instead of around 106).
We then introduce three types of IPE schemes. For Type 1, relation R(v, x) holds iff the generalized inner-product of v over x is 0, while for Type 2 it holds iff the generalized inner-product of x overv is 0. We call Type 0 for the conventional inner-products, i.e., relationR(v, x) is defined by the standard inner-product ofv and x, wherev and x have the same dimension (in other words, the inner-product for Type 0 is defined iff these dimensions are equivalent.)
2. We present the first unbounded inner-product encryption (IPE) schemes. The proposed unbounded IPE schemes are fully (adaptively) secure and fully attribute-hiding in the standard model under a standard assumption, the decisional linear (DLIN) assumption. The proposed unbounded IPE schemes consist of the above-mentioned types of generalized IPE, Types 0, 1 and 2, For comparison of attribute-hiding IPE schemes, see Table 1.
Table 2: Comparison ofKP-ABE Schemes, where|G|represents the size of an element ofG, and PK, SK, CT and GSD stand for master public key (public parameters), secret key, ciphertext and general subgroup decision [3], respectively. And, d, n, nmax, and kmax are the number
of sub-universes of attributes, the number of attributes for a CT, the maximum number of attributes for a CT, the row size of an access policy matrix for a SK and the maximum value of the degree of access policies, respectively.
LW11 [11] LOS+10 [8] OT10 [14] Proposed KP-ABE
(basic) (modified) (basic) (modified) (basic) Section 6.1
(modified) Section 6.2
Bounded or
Unbounded unbounded bounded bounded unbounded
Security selective full full full
Order of G composite composite prime prime
Assump. GSD GSD DLIN DLIN
Degree of
access policies arbitrary 1 arbitrary 1 arbitrary 1 arbitrary
PK size O(1)|G| O(nmax)|G| O(d)|G| O(1)|G|
SK size O()|G| O()|G| O()|G| O()|G|
CT size O(n)|G| O(n)|G| O(kmaxn)|G| O(n)|G| O(kmaxn)|G| O(n)|G| O(kmaxn)|G|
payload-hiding) in the standard model. The proposed unbounded ABE schemes are fully secure under the DLIN assumption, and are for a wide class of relations, non-monotone access structures. See Table 2 for comparison of KP-ABE schemes.
Remark: Similarly to the existing fully secure ABE schemes in the standard model [8, 14, 10] except [12], our basic ABE scheme (Section 6.1) has a restriction that the degree of access policies is 1 1. A modified KP-ABE scheme is shown in Section 6.2 to relax the restriction or to achieve an arbitrary degree kof access policies with preserving the fully secure and unbounded property. It, however, shares a shortcoming of the existing fully secure (modified) ABE schemes [8, 14, 10] that the ciphertext size grows linearly withk. Here, a (maximum) value ofkcan be determined in each application of our ABE scheme, while the public parameters are fixed and commonly shared by all applications and users.
1.3 Key Techniques
As mentioned above, the difficulty of realizing a fully secure unbounded IPE or ABE scheme arises from the hardness of supplying an unbounded amount of randomness consistent with the complicated key-query condition for the (dual system encryption) security arguments on IPE or ABE. To overcome this difficulty, we develop novel techniques, indexing and consistent randomness amplification, on the dual system encryption and the dual pairing vector spaces (DPVS). Roughly speaking, the indexing technique is for supplying a source of unbounded amount of randomness and theconsistent randomness amplificationtechnique is for amplifying the randomness of the source through a computational assumption (e.g., the DLIN assumption
in our case) and the randomness of hidden bases as well as for adjusting the distribution of the amplified randomness to be consistent with a condition. This methodology could provide a general framework for proving the security in unbounded situations.
In DPVS, a pair of dual (or orthonormal) bases for N-dimensional linear spaces, B := (b1, . . . ,bN) and B∗ := (b∗1, . . . ,b∗N), are randomly generated using a secret random linear transformation X (random N ×N matrix) (see Section 2). In a typical application of DPVS to cryptography, a part of B(say ˆB) is used as a public key (public parameters), andB∗ as a secret key, where X is the top level secret key and the source of randomness.
In a typical construction of bounded IPE schemes [8, 14, 16] which are based on DPVS, once a basis of DPVS, a part of the basis of a N-dimensional space is published as public parameters, the dimension n of predicate and attribute vectors for secret key and encryption is bounded or fixed, e.g., n ≤ N/4 (i.e., N = O(n)). The full security is proven through the information theoretical arguments, and the randomness of secret matrixX (e.g., the amount of the randomness isO(n2)) supplies enough randomness for the arguments.
In contrast, the dimension, n, of the predicate and attribute vectors is not bounded by the public parameters inunboundedIPE. For example, in one of the proposed IPE schemes (Section 5), the public parameters consist of a constant number of elements, 9 elements of bases (or 105 pairing group elements), B0 := (b0,1,b0,3,b0,5) and B := (b1, . . . ,b4,b14,b15), where random matrices of constant sizes, X0 ←U F5q×5 and X1 ←U F15q ×15, are employed to generate the public parameters. The randomness of the public parameters, just a constant amount with respect to n, is clearly insufficient for the (dual system encryption) arguments on the proof of full security. To supply additional randomness for the purpose, in our IPE schemes, we introduce a tech-nique calledindexing, where two-dimensional index vectors,σt(1, t) andμt(t,−1) are embedded into ciphertextctand secret keyk∗t, respectively, whereσtandμtare freshly random for each t. In our IPE scheme (Section 5) wheren=n for simplicity, for example, secret key (k∗1, . . . ,k∗n) forv:= (v1, . . . , vn) can be expressed by a coefficient vector, (μt(t,−1), δvt, . . .), fort= 1, . . . , n, over basis B∗, i.e., kt∗ := (μt(t,−1), δvt, . . .)B∗ and ciphertext (c1, . . . ,cn) for x := (x1, . . . , xn) can be expressed by ct:= (σt(1, t), ωxt, . . .)B fort= 1, . . . , n, whereδ, ω are randomly selected. While the size of the public parameters or its randomness is constant in n, an unbounded amount of randomness, {μt}t=1,...,n,{σt}t=1,...,n, can be supplied to secret key and ciphertext. This is a key idea of theindexing technique.
Although the technique supplies an unbounded amount of randomness, i.e., O(n)-size of randomness, it is not enough for our purpose. We need more and a specific distribution of randomness. This is because: in the proof of full security on dual system encryption and the extension, such arealrandomness provided by the indexing technique should be expanded into a hidden part in spaces over bases B and B∗, and the distribution should be also adjusted to (or consistent with) the key-query condition for IPE or ABE. For this purpose, i.e., in order to amplify the randomness to a hidden subspace and to adjust it to a specific distribution, we develop another technique,consistent randomness amplification.
hidden subspaces. For example, as mentioned above, a real secret key {k∗t} and ciphertext {ct} are expressed by k∗t := (μt(t,−1), δvt, st, 07 , . . .)B∗ and ct := (σt(1, t), ωxt, ω, 07 , . . .)B. This technique provides a transformation (for the dual system encryption technique and the extension) to the following forms: k∗t := (μt(t,−1), δvt, st, 04,(πvt, at)·Ut,0, . . .)B∗ and ct:= (σt(1, t), ωxt, ω, . . . , (τ xt,τ)·Zt, 0, . . .)B, where Zt is an independently random 2×2 ma-trix for each t and Ut := (ZtT)−1, and other new variables are random. Here, the box-framed parts are the information theoretically hidden subspaces, the randomness of the hidden parts is amplified and the distribution of (πvt, at)·Utand (τ xt,τ)·Zt is consistent with the key-query condition.
The consistent randomness amplification technique is composed of several computational and conceptual (information theoretical) transformations. One of the key tricks of the trans-formations is to amplify a source of randomness to a hidden part by applying a computational assumption, the DLIN assumption. Another computational trick is to swap two vectors in different positions under DLIN. Information theoretical key tricks are inter-subspace and intra-subspace types of conceptual transformations (see Section 7 for more details).
The security proofs of our IPE and ABE schemes are hierarchically constructed in a modular manner. The very top level of the security proof is based on the dual system encryption and its extension. Several problems in the middle level support the top level arguments. Our key techniques, the indexing and consistent randomness amplification techniques, which are also constructed in a hierarchical manner, are employed in the lowest level to reduce the hardness of the middle level problems to the DLIN assumption. The top level of the security proof of our IPE scheme (forκ= 1) is outlined in Section 5.1.7, and that of our ABE scheme is outlined in the upper part of Figure 2 in Appendix A.4.
1.4 Notations
When A is a random variable or distribution, y ←R A denotes that y is randomly selected from A according to its distribution. When A is a set, y ←U A denotes that y is uniformly selected from A. We denote the finite field of order q by Fq, Fq \ {0} by Fq×, and the set of positive integers by N. A vector symbol denotes a vector representation over Fq, e.g., x denotes (x1, . . . , xn) ∈ Fqn. The vector 0 is abused as the zero vector in Fqn for any n. XT denotes the transpose of matrix X. I and 0 denote the × identity matrix and the × zero matrix, respectively. A bold face letter denotes an element of vector space V, e.g., x∈V. When bi ∈V(i= 1, . . . , n),spanb1, . . . ,bn ⊆V(resp. spanx1, . . . , xn ) denotes the subspace generated by b1, . . . ,bn (resp. x1, . . . , xn). For basesB:= (b1, . . . ,bN) and B∗ := (b∗1, . . . ,b∗N), (x1, . . . , xN)B := Ni=1xibi and (y1, . . . , yN)B∗ := Ni=1yibi∗. e1 and e2 denote the canonical basis vectors inF2q, i.e.,e1 := (1,0) ande2:= (0,1). GL(n,Fq) denotes the general linear group of degree noverFq.
2
Dual Pairing Vector Spaces by Direct Product of Symmetric
Pairing Groups
Definition 1 “Symmetric bilinear pairing groups” (q,G,GT, G, e) are a tuple of a prime q, cyclic additive group Gand multiplicative group GT of order q, G= 0∈G, and a polynomial-time computable nondegenerate bilinear pairing e:G×G→GT i.e.,e(sG, tG) =e(G, G)st and e(G, G)= 1. Let Gbpg be an algorithm that takes input 1λ and outputs a description of bilinear
Definition 2 “Dual pairing vector spaces (DPVS)”(q,V,GT,A, e) by a direct product of sym-metric pairing groups (q,G,GT, G, e) are a tuple of prime q, N-dimensional vector space V:=
N
G× · · · ×G over Fq, cyclic group GT of order q, canonical basis A := (a1, . . . ,aN) of V,
where ai := ( i−1 0, . . . ,0, G,
N−i
0, . . . ,0), and pairing e : V×V → GT. The pairing is defined by
e(x,y) := Ni=1e(Gi, Hi) ∈ GT where x := (G1, . . . , GN) ∈ V and y := (H1, . . . , HN) ∈ V. This is nondegenerate bilinear i.e., e(sx, ty) =e(x,y)st and if e(x,y) = 1 for all y∈V, then
x = 0. For all i and j, e(ai,aj) = e(G, G)δi,j where δ
i,j = 1 if i = j, and 0 otherwise, and e(G, G)= 1∈GT. DPVS generation algorithm Gdpvs takes input 1λ (λ∈N) and N ∈N, and
outputs a description ofparamV:= (q,V,GT,A, e)with security parameterλandN-dimensional
V. It can be constructed by using Gbpg.
For matrix W := (wi,j)i,j=1,...,N ∈FqN×N and element x:= (G1, . . . , GN) in N-dimensional
V, xW denotes (Ni=1Giwi,1, . . . ,Ni=1Giwi,N) =(Ni=1wi,1Gi, . . . ,Ni=1wi,NGi) by a natural multiplication of a N-dim. row vector and a N ×N matrix. Thus it holds an associative law, i.e., (xW1)W2 =x(W1W2).
For the asymmetric version of DPVS, see Appendix A.2 in [14]. We describe random dual orthonormal basis generator Gob, which is used as a subroutine in our IPE and ABE schemes.
Gob(1λ,(Nt)t=0,1) :paramG := (q,G,GT, G, e)
R
← Gbpg(1λ), ψ U
←F×
q , fort= 0,1, paramVt := (q,Vt,GT,At, e) :=Gdpvs(1λ, Nt,paramG),
Xt:= (χt,i,j)i,j=1,...,Nt ←UGL(Nt,Fq), Xt∗ := (ϑt,i,j)i,j=1,...,Nt :=ψ·(XtT)−1, hereafter,
χt,i andϑt,i denote the i-th rows of Xt and Xt∗ fori= 1, . . . , Nt, respectively,
bt,i := (χt,i)At =Nj=1t χt,i,jat,j fori= 1, . . . , Nt, Bt:= (bt,1, . . . ,bt,Nt), b∗t,i := (ϑt,i)At =Nj=1t ϑt,i,jat,j fori= 1, . . . , Nt, B∗t := (b∗t,1, . . . ,b∗t,Nt), gT :=e(G, G)ψ, param:= ({paramVt}t=0,1, ψG, gT), return (param,B,B∗).
We note that gT =e(bt,i,b∗t,i) for t= 0,1;i= 1, . . . , Nt. Hereafter, for simplicity, we denote N :=N1,V:=V1,A:=A1,B:=B1 and B∗ :=B∗1 for variables witht= 1.
3
Decisional Linear (DLIN) Assumption
Definition 3 (DLIN: Decisional Linear Assumption [4]) The DLIN problem is to guess
β ∈ {0,1}, given (paramG, G, ξG, κG, δξG, σκG, Yβ)← GR βDLIN(1λ), where
GDLIN
β (1λ) :paramG := (q,G,GT, G, e)
R
← Gbpg(1λ),
κ, δ, ξ, σ←UFq, Y0 := (δ+σ)G, Y1←UG, return (paramG, G, ξG, κG, δξG, σκG, Yβ),
forβ ← {U 0,1}. For a probabilistic machineF, we define the advantage ofF for the DLIN
prob-lem as: AdvDLINF (λ) := Pr
F(1λ, )→1 ←GR 0DLIN(1λ)
−Pr
F(1λ, )→1 ←GR 1DLIN(1λ).
The DLIN assumption is: For any probabilistic polynomial-time adversary F, the advantage
4
Definitions of Generalized Inner-Product Encryption (IPE)
and Attribute-Based Encryption (ABE)
4.1 Generalized Inner-Product Encryption
This section defines generalized inner product encryption (IPE) and its security.
The parameters of generalized inner-product predicates are expressed as a vector x := {(t, xt)|t ∈ Ix, xt ∈ Fq} \ {0} with finite index set Ix ⊂ N for encryption and a vector v := {(t, vt)|t ∈ Iv, vt ∈Fq} \ {0} with finite index set Iv ⊂ N for a secret key, respectively. Here there are three types of unbounded IPE with respect to the decryption condition. For Type 1, R(v, x) = 1 iff Iv ⊆ Ix and t∈I
vvtxt = 0. For Type 2, R(v, x) = 1 iff Iv ⊇ Ix and
t∈Ixvtxt= 0.
We will consider Type 0 inner-product predicate only for conventional prefix type vectors v:= (v1, . . . , vn) and x := (x1, . . . , xn). For Type 0, R(v, x) = 1 iff n = n and v ·x :=
n
t=1vtxt= 0.
Definition 4 An inner product encryption scheme (for generalized inner-product relationR(v, x)) consists of probabilistic polynomial-time algorithmsSetup,KeyGen,Enc andDec. They are given as follows:
Setuptakes as input security parameter1λ. It outputs public parameterspkand (master) secret key sk.
KeyGen takes as input public parameters pk, secret key sk, and vector v. It outputs a corre-sponding secret keyskv.
Enc takes as input public parameters pk, message m in some associated message space, msg, and vector x. It returns ciphertext ctx.
Dec takes as input the master public keypk, secret key skv and ciphertextctx. It outputs either
m ∈msg or the distinguished symbol ⊥.
A generalized IPE scheme should have the following correctness property: for all (pk,sk)←R
Setup(1λ), all vectors v and x, all secret keys skv ←R KeyGen(pk,sk, v), all messages m, all ciphertext ctx ←R Enc(pk, m, x), it holds thatm=Dec(pk,skv,ctx) if R(v, x) = 1. Otherwise, it holds with negligible probability.
Definition 5 The model for defining the adaptively fully-attribute-hiding security ofIP E against adversary A(under chosen plaintext attacks) is given by the following game:
Setup The challenger runs the setup algorithm, (pk,sk)←R Setup(1λ), and gives public
param-eters pk to A.
Phase 1 A may adaptively make a polynomial number of key queries for vectors, v, to the challenger. In response, the challenger gives the corresponding keyskv ←R KeyGen(pk,sk, v)
to A.
Challenge A submits challenge vectors (x(0), x(1)) with the same index set Ix(0) = Ix(1) (or n(0) = n(1) for Type 0) and challenge messages (m(0), m(1)), subject to the following restrictions:
• Two challenge messages are equal, i.e., m(0) =m(1), and any key queryv in Phase 1 satisfies R(v, x(0)) =R(v, x(1)).
The challenger flips a coinb← {U 0,1}, and gives ctx(b) ←REnc(pk, m(b), x(b)) to A.
Phase 2 Phase 1 is repeated with the above restriction for key queryvand challenge,(x(0), x(1))
and (m(0), m(1)).
Guess A outputs a bit b, and wins if b =b.
The advantage of A in the above game is defined as AdvIPEA ,AH(λ) := Pr[A wins ]−1/2 for any security parameter λ. An IPE scheme is adaptively fully-attribute-hiding (AH) against cho-sen plaintext attacks if all probabilistic polynomial-time adversaries A have at most negligible advantage in the above game. For each run of the game, the variable s is defined as s := 0 if
m(0) =m(1) for challenge messages m(0) and m(1), and s:= 1 otherwise.
4.2 Attribute-Based Encryption with Non-Monotone Access Structures
4.2.1 Span Programs and Non-Monotone Access Structures
Definition 6 (Span Programs [2]) Let {p1, . . . , pn} be a set of variables. A span program over Fq is a labeled matrixMˆ := (M, ρ) where M is a (×r) matrix overFq and ρis a labeling of the rows ofM by literals from{p1, . . . , pn,¬p1, . . . ,¬pn}(every row is labeled by one literal), i.e., ρ:{1, . . . , } → {p1, . . . , pn,¬p1, . . . , ¬pn}.
A span program accepts or rejects an input by the following criterion. For every input sequenceδ ∈ {0,1}n define the submatrix Mδ of M consisting of those rows whose labels are set to 1 by the input δ, i.e., either rows labeled by somepi such thatδi = 1 or rows labeled by some
¬pi such that δi = 0. (i.e., γ :{1, . . . , } → {0,1} is defined by γ(j) = 1 if [ρ(j) =pi]∧[δi = 1]
or [ρ(j) =¬pi]∧[δi= 0], and γ(j) = 0otherwise. Mδ := (Mj)γ(j)=1, where Mj is thej-th row of M.)
The span program Mˆ acceptsδ if and only if1∈spanMδ , i.e., some linear combination of the rows ofMδ gives the all one vector1. (The row vector has the value 1 in each coordinate.) A span program computes a Boolean functionf if it accepts exactly those inputsδ where f(δ) = 1. A span program is called monotone if the labels of the rows are only the positive literals
{p1, . . . , pn}. Monotone span programs compute monotone functions. (So, a span program in general is “non”-monotone.)
We assume that no row Mi (i= 1, . . . , ) of the matrix M is0. We now introduce a non-monotone access structure with evaluating map γ that is employed in the proposed attribute-based encryption schemes.
Definition 7 (Access Structures) Ut (t = 1, . . . , d and Ut ⊂ {0,1}∗) is a sub-universe, a set of attributes, each of which is expressed by a pair of sub-universe id and value of attribute, i.e., (t, v), where t∈ {1, . . . , d} and v∈Fq.
We now define such an attribute to be a variable pof a span programMˆ := (M, ρ), i.e.,p:= (t, v). An access structureS is span program Mˆ := (M, ρ) along with variablesp:= (t, v), p := (t, v), . . ., i.e., S:= (M, ρ) such that ρ:{1, . . . , } → {(t, v),(t, v), . . . ,¬(t, v),¬(t, v), . . .}.
Let Γ be a set of attributes, i.e., Γ :={(t, xt)|xt ∈Fq,1≤t≤d}, where 1≤t≤d means that tis an element of some subset of {1, . . . , d}.
When Γ is given to access structure S, map γ :{1, . . . , } → {0,1} for span program Mˆ := (M, ρ)is defined as follows: Fori= 1, . . . , , setγ(i) = 1if[ρ(i) = (t, vi)]∧[(t, xt)∈Γ]∧[vi =xt]
We now construct a secret-sharing scheme for a non-monotone access structure or span program.
Definition 8 A secret-sharing scheme for span programMˆ := (M, ρ) is:
1. Let M be ×r matrix. Let column vector fT := (f1, . . . , fr)T ←UFqr. Then, s0 :=1·fT= r
k=1fk is the secret to be shared, and sT := (s1, . . . , s)T := M ·fT is the vector of
shares of the secret s0 and the share si belongs to ρ(i).
2. If span program Mˆ := (M, ρ) accept δ, or access structure S := (M, ρ) accepts Γ, i.e.,
1 ∈ span(Mi)
γ(i)=1 with γ : {1, . . . , } → {0,1}, then there exist constants {αi ∈ Fq | i∈I} such that I ⊆ {i ∈ {1, . . . , } | γ(i) = 1} and i∈Iαisi =s0. Furthermore, these constants {αi} can be computed in time polynomial in the size of matrixM.
4.2.2 Key-Policy Attribute-Based Encryption
In key-policy attribute-based encryption (KP-ABE), encryption (resp. a secret key) is associated with attributes Γ (resp. access structure S). Relation R for KP-ABE is defined asR(S,Γ) = 1 iff access structureS accepts Γ.
Definition 9 (Key-Policy Attribute-Based Encryption: KP-ABE) A key-policy attribute-based encryption scheme consists of probabilistic polynomial-time algorithmsSetup,KeyGen,Enc
and Dec. They are given as follows:
Setup takes as input security parameter 1λ. It outputs public parameters pk and master secret key sk.
KeyGen takes as input public parameters pk, master secret key sk, and access structure S := (M, ρ). It outputs a corresponding secret key skS.
Enc takes as input public parameters pk, message m in some associated message space msg, and a set of attributes, Γ :={(t, xt)|xt∈Fq,1≤t≤d}. It outputs a ciphertext ctΓ.
Dec takes as input public parameters pk, secret key skS for access structure S, and ciphertext
ctΓ that was encrypted under a set of attributes Γ. It outputs either m ∈ msg or the distinguished symbol ⊥.
A KP-ABE scheme should have the following correctness property: for all (pk,sk) ←R
Setup(1λ), all access structures S, all secret keys skS ←R KeyGen(pk, sk,S), all messages m, all attribute sets Γ, all ciphertextsctΓ←R Enc(pk, m,Γ), it holds thatm=Dec(pk,skS,ctΓ) if S accepts Γ. Otherwise, it holds with negligible probability.
Definition 10 The model for defining the adaptively payload-hiding security of KP-ABE under chosen plaintext attack is given by the following game:
Setup The challenger runs the setup algorithm, (pk,sk)←R Setup(1λ), and gives public param-eters pk to the adversary.
Challenge The adversary submits two messagesm(0), m(1) and a set of attributes,Γ, provided that no S queried to the challenger in Phase 1 accepts Γ. The challenger flips a coin
b← {U 0,1}, and computes ct(Γb)←R Enc(pk, m(b),Γ). It gives ct(Γb) to the adversary.
Phase 2 Phase 1 is repeated with the restriction that no queried S accepts challenge Γ.
Guess The adversary outputs a guess b of b, and wins if b =b.
The advantage of adversaryAin the above game is defined asAdvKPA -ABE,PH(λ) := Pr[Awins ]− 1/2 for any security parameter λ. A KP-ABE scheme is adaptively payload-hiding secure if all polynomial time adversaries have at most a negligible advantage in the above game.
4.2.3 Ciphertext-Policy Attribute-Based Encryption
Definition 11 (Ciphertext-Policy Attribute-Based Encryption : CP-ABE) A ciphertext-policy attribute-based encryption scheme consists of four algorithms.
Setup takes as input security parameter. It outputs the public parameters pk and a master key
sk.
KeyGen takes as input a set of attributes, Γ := {(t, xt)|xt ∈ Fq,1 ≤ t ≤ d}, pk and sk. It outputs a decryption key.
Enc takes as input public parameters pk, message m in some associated message space msg, and access structure S:= (M, ρ). It outputs the ciphertext.
Dec takes as input public parameters pk, decryption key skΓ for a set of attributes Γ, and ciphertext ctS that was encrypted under access structure S. It outputs either m ∈msg or the distinguished symbol ⊥.
A CP-ABE scheme should have the following correctness property: for all (pk,sk) ←R
Setup(1λ), all attribute sets Γ, all decryption keys skΓ ←R KeyGen(pk,sk,Γ), all messages m, all access structures S, all ciphertexts ctS ←R Enc(pk, m,S), it holds that m =Dec(pk,skΓ,ctS) with overwhelming probability, ifS accepts Γ.
Definition 12 The model for proving the adaptively payload-hiding security of CP-ABE under chosen plaintext attack is:
Setup The challenger runs the setup algorithm, (pk,sk) ←R Setup(1λ), and gives the public parameters pk to the adversary.
Phase 1 The adversary is allowed to issue a polynomial number of queries, Γ, to the challenger or oracle KeyGen(pk,sk,·) for private keys, skΓ associated with Γ.
Challenge The adversary submits two messages m(0), m(1) and an access structure, S := (M, ρ), provided that the S does not accept any Γ sent to the challenger in Phase 1.
The challenger flips a random coin b← {U 0,1}, and computes ct(Sb) ←R Enc(pk, m(b),S). It gives ct(Sb) to the adversary.
Guess The adversary outputs a guess b of b.
The advantage of an adversaryAin the above game is defined asAdvCPA -ABE,PH(λ) := Pr[b= b]−1/2 for any security parameter λ. A CP-FE scheme is adaptively payload-hiding secure if all polynomial time adversaries have at most a negligible advantage in the above game.
We note that the model can easily be extended to handle chosen-ciphertext attacks (CCA) by allowing for decryption queries in Phase 1 and 2.
5
Proposed IPE Schemes
5.1 Type 1 IPE Scheme
5.1.1 Construction Idea for Our Type 1 and 2 IPE Schemes
In the existing constructions [13, 8, 14, 15, 16, 17] of IPE on DPVS, around cn (c ≥ 1) di-mensional vector spaces are used for n-dimensional attribute and predicate vectors. Here, the vectors are encoded in an n-dimensional subspace. Although this is a typical strategy of con-structing IPE on DPVS, we cannot employ this idea in the unbounded setting, where we can use only constant dimensional spaces. In our construction, each component xt of x (resp.vt of v) is encoded in a constant dimensional space. In order to meet the decryption condition, we employ the indexing technique and n-out-of-n secret sharing trick. For example, in Type 1 construction, 4-dimensional vector (μt(t,−1), δvt, st) is encoded in key k∗t, and (σt(1, t), ωxt,
ω) is encoded in ciphertext ct. The first 2-dimension is used for indexes, andst in the fourth component of k∗t is for the secret sharing. Informally, a ciphertext can be decrypted if all n pieces of shares st are recovered. A Type 2 IPE scheme can be constructed from our Type 1 scheme by setting the secret-sharing mechanism in the ciphertext side instead of the secret key side.
5.1.2 Construction
Let d := poly(λ), where poly(·) is an arbitrary polynomial. Random dual basis generator Gob(1λ,(Nt)t=0,1) is defined at the end of Section 2. We refer to Section 1.4 for notations on DPVS.
Setup(1λ) : (param,(B0,B∗0),(B,B∗))← GR ob(1λ,(N0 := 5, N := 15)),
B0 := (b0,1,b0,3,b0,5), B := (b1, ..,b4,b14,b15),
B∗
0 := (b∗0,1,b0∗,3,b∗0,4), B∗ := (b∗1, ..,b∗4,b∗12,b∗13), return pk:= (1λ,param,B0,B), sk:= (B∗0,B∗).
KeyGen(pk, sk, v:={(t, vt)|t∈Iv ⊆ {1, . . . , d}}) :st, δ, η0 ←U Fq fort∈Iv, s0 :=t∈I
vst,
k0∗:= ( −s0, 0, 1, η0, 0 )B∗ 0,
4
7 2 2
fort∈Iv, μt, ηt,1, ηt,2 ←UFq, k∗t := ( μt(t, −1), δvt, st, 07, ηt,1, ηt,2, 02 )B∗, return skv:= (Iv,k∗0,{k∗t}t∈Iv).
Enc(pk, m, x:={(t, xt)|t∈Ix⊆ {1, . . . , d}}) : ω,ω, ζ, ϕ0 ←UFq, c0:= ( ω, 0, ζ, 0, ϕ0 )B0, cT :=gζTm,
4
7 2 2
return ctx:= (Ix,c0,{ct}t∈Ix, cT).
Dec(pk, skv := (Iv,k∗0,{kt∗}t∈Iv), ctx := (Ix,c0,{ct}t∈Ix, cT)) : if Iv⊆Ix, K:=e(c0,k∗0)· t∈I
ve(ct,k∗t), returnm :=cT/K,
else return⊥.
[Correctness] If Iv ⊆Ix and t∈I
vvtxt= 0, e(c0,k0∗)· t∈Ive(ct,k∗t) =
g−Tωs0e +ζ· t∈I
vg
δωvtxt+eωst
T =gT−ωs0e +ζ·g
δω(Pt∈Ivvtxt)+eω(Pt∈Ivst)
T =gT−ωs0e +ζ+ωs0e =gζT.
5.1.3 Security
Theorem 1 The proposed Type 1 IPE scheme is adaptively fully-attribute-hiding against chosen plaintext attacks under the DLIN assumption.
For any adversaryA, there exist probabilistic machinesF’s, whose running times are essen-tially the same as that ofA, such that for any security parameterλ, the advantage AdvIPEA ,AH(λ)
is upper-bounded by the sum of the right hand of Eq. (1) and the right hand of Eq. (2). The sum is given by the total of (ν(12d2+ 6d+ 3) + 4d+ 6) advantages of DLIN forF algorithms, which are F machines with parameters (h, ι, p, j, l) as described in Lemmas 1 and 2. Here, ν is the maximum number ofA’s key queries.
Theorem 1 is proven based on Lemmas 1 and 2.
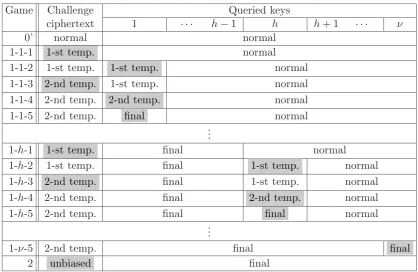
Proof. First, we execute a preliminary game transformation from Game 0 (original security
game in Definition 5) to Game 0’, which is the same as Game 0 except that flips a coinκ← {U 0,1} before setup, and the game is aborted in step 3 ifκ=s. We define thatAwins with probability 1/2 when the game is aborted (and the advantage in Game 0’ is Pr[A wins ]−1/2 as well). Sinceκ is independent froms, the game is aborted with probability 1/2. Hence, the advantage in Game 0’ is a half of that in Game 0, i.e., AdvAIPE,AH,0(λ) = 1/2·AdvIPEA ,AH(λ). Moreover, Pr[Awins] = 1/2·(Pr[Awins|κ= 0] + Pr[Awins|κ= 1]) in Game 0’ sinceκis uniformly and independently generated. As for the conditional probability withκ= 0, i.e., Pr[Awins|κ= 0], Lemma 1 (Eq. (1)) holds. As for the conditional probability withκ= 1, i.e., Pr[Awins|κ= 1], Lemma 2 (Eq. (2)) holds. Since AdvIPEA ,AH(λ) = 2·AdvAIPE,AH,0(λ) = Pr[A wins | κ = 0] + Pr[A wins | κ = 1]−1 = (Pr[Awins|κ = 0]−1/2) + (Pr[Awins|κ = 1]−1/2), we obtain
Theorem 1 from Lemmas 1 and 2.
Lemma 1 The proposed Type 1 IPE scheme is adaptively fully-attribute-hiding against chosen plaintext attacks under the DLIN assumption when κ= 0.
For any adversaryA, there exist probabilistic machinesF1-0,F1-1,F1-2,F2-1,F2-2-1, . . . ,F2-2-5, F3, whose running times are essentially the same as that of A, such that for any security pa-rameter λ,
Pr[A wins in Game 0 | κ= 0]−1/2≤AdvDLINF1-0(λ) +AdvDLINF1-1(λ) +dp=12j=1AdvDLINF1-2-p-j(λ) ν
h=1
AdvDLINF2-h-1(λ) +dp=12j=1
AdvDLINF2-h-2-p-1-j(λ) +AdvDLINF2-h-2-p-2-j(λ)+
l=1,...,d; l=p
AdvDLINF
2-h-2-p-3-j-l(λ) +Adv DLIN
F2-h-2-p-4-j-l(λ)
+AdvDLINF
2-h-2-p-5-j(λ)
+ 2
j=1AdvDLINF3-j (λ) +, (1)
where F1-2-p-j(·) :=F1-2(h, p, j,·),F2-h-1(·) :=F2-1(h,·),F2-h-2-p-1-j(·) :=F2-2-1(h, p, j,·),
Proof outline (resp. proof) of Lemma 1 is given in Section 5.1.5 (resp. 5.1.6).
Lemma 2 The proposed Type 1 IPE scheme is adaptively fully-attribute-hiding against chosen plaintext attacks under the DLIN assumption when κ= 1.
For any adversaryA, there exist probabilistic machinesF1-0,F1-1,F1-2,F2-1,F2-2-1, . . . ,F2-2-5, F2-3-1, . . . ,F2-3-5,F2-4, whose running times are essentially the same as that of A, such that for any security parameter λ,
Pr[A wins in Game 0 | κ= 1]−1/2≤AdvDLINF1-0(λ) +AdvDLINF1-1(λ) +dp=12j=1AdvDLINF1-2-p-j(λ) ν
h=1
AdvDLINF2-h-1(λ) +ι3=2dp=12j=1
AdvDLINF2-h-ι-p-1-j(λ) +AdvDLINF2-h-ι-p-2-j(λ)+
l=1,...,d; l=p
AdvDLINF2-h-ι-p-3-j-l(λ) +AdvDLINF2-h-ι-p-4-j-l(λ)
+AdvDLINF2-h-ι-p-5-j(λ)
+ 2
j=1AdvDLINF2-4-j(λ)
+, (2)
where F1-2-p-j(·) :=F1-2(h, p, j,·),F2-h-1(·) :=F2-1(h,·),F2-h-ι-p-1-j(·) :=F2-ι-1(h, p, j,·),
F2-h-ι-p-2-j(·) :=F2-ι-2(h, p, j,·),F2-h-ι-p-3-j-l(·) :=F2-ι-3(h, p, j, l,·),F2-h-ι-p-4-j-l(·) :=F2-ι-4(h, p, j, l,·),F2-h-ι-p-5-j(·) :=F2-ι-5(h, p, j,·)forι= 2,3,F2-4-j(·) :=F2-4(j,·), νis the maximum number of A’s key queries and := (40d2ν+ 20dν+ 10ν+ 10d+ 10)/q.
Proof outline (resp. proof) of Lemma 2 is given in Section 5.1.7 (resp. 5.1.8).
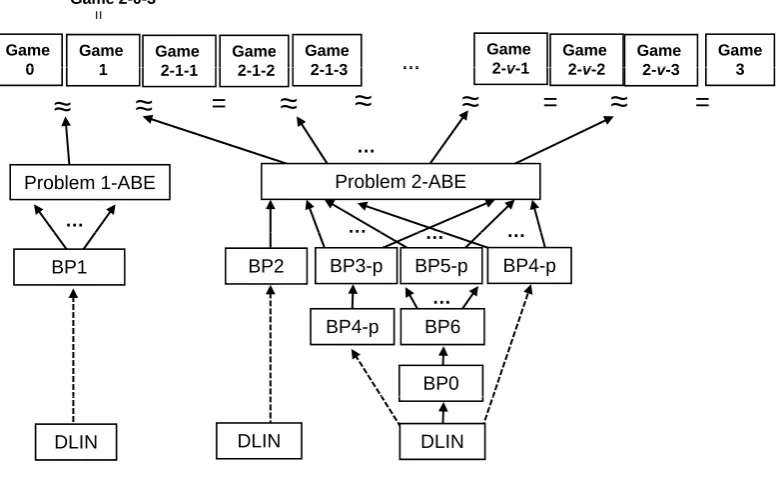
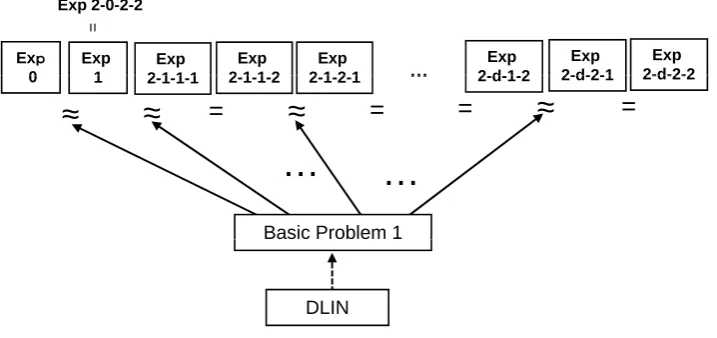
5.1.4 Lemmas (and Problems) for the proof of Lemmas 1 and 2
Computational Problems and Assumptions for Proofs of Lemmas 1 and 2 While our IPE scheme uses 15 dimensional spaceV, our KP-ABE in Section 6.1 uses 14 dimensionalV. This 1-dimensional difference arises from the difference of the required security, fully-attribute-hiding for IPE but only payload-fully-attribute-hiding for KP-ABE. The security of our KP-ABE is proven using Problem 1-ABE and 2-ABE. Note that while these problems are made for KP-ABE, they are also key techniques or basic building blocks for the security proof of IPE. The security proofs for Problems 1-ABE and 2-ABE (Lemmas 23 and 24) are given in Appendix A.4. The security proofs of IPE and ABE are reduced to the security (intractability) of these problems.
We will introduce 5 computational problems on DPVS for our IPE, Problems 1-IPE, . . ., 5-IPE. These are classified into 3 types, ones based on Problem 1-ABE, ones based on Problem 2-ABE, and ones directly reduced from DLIN. Since the security of Problems 1-ABE and 2-ABE is proven using the indexing and consistent randomness amplification techniques, the security of the former two types essentially depends on these techniques.
The security lemma of Problem 1-IPE for unbounded IPE is reduced to that of Problem 1-ABE (Lemma 32 in Appendix A.1.1), and the security lemmas of Problems 2-IPE and 4-IPE are reduced to that of Problem 2-ABE (Lemma 33 in Appendix A.1.2). The security proofs of the other problems (Problems 3-IPE and 5-IPE) are not based on Problems 1-ABE or 2-ABE, but can be directly reduced from the DLIN assumption.
Definition 13 (Problem 1-IPE) Problem 1-IPE is to guess β, given (param,B0,B∗0,B,B∗, eβ,0,{eβ,t,i}t=1,...,d;i=1,2,eβ,1,e2)← GR βP1-IPE(1λ, d), where
GP1-IPE
β (1λ, d) : (param,(B0,B∗0),(B,B∗))
R
← Gob(1λ,(N0 := 5, N := 15)),
ϕ0, ω ←UFq, τ ←UFq×,
B0 := (b0,1,b0,3,b0,5), B:= (b1, ..,b4,b14,b15),
B∗
![Table 1: Comparison ofattribute-hiding, inner-product, master public key (public parameters), secret key, ciphertext,general subgroup decision [3] and extended decisional Diffie-Hellman [8], respectively.n andelement of attribute-hiding IPE schemes, where](https://thumb-us.123doks.com/thumbv2/123dok_us/7883222.1307987/6.595.73.539.167.402/comparison-ofattribute-parameters-ciphertext-decisional-respectively-andelement-attribute.webp)
![Figure 1: Structures of Reductions: The upper one is that used in [16], and the lower one isthat used in the proof of Lemma 2.](https://thumb-us.123doks.com/thumbv2/123dok_us/7883222.1307987/24.595.99.501.74.389/figure-structures-reductions-upper-lower-isthat-proof-lemma.webp)