Distributed Data Analysis for Large-Scale Social Networks
Shaik Allabagash1, C Bhanupraksh2
1
Dept. of CSE, J.N.T.U Anantapur, Udayagiri, Andhra Pradesh, India, [email protected]
2
Dept. of CN, J.N.T.U Anantapur, Nellore, Andhra Pradesh, India
Abstract
Informal organization examination is utilized to concentrate components of human groups and turns out to be exceptionally instrumental in an assortment of investigative spaces. The dataset of an informal community is regularly so huge that a cloud information examination administration, in which the calculation is performed on a parallel stage in the could, turns into a decent decision for specialists not experienced in parallel programming. In the cloud, an essential test to proficient information examination is the calculation and correspondence skew (i.e., load lopsidedness) among PCs created by humankind's gathering conduct (e.g., temporary fad impact). Conventional burden adjusting systems either require huge push to re-equalization loads on the hubs, or can't well adapt to stragglers. In this paper, we propose a general straggler-mindful execution approach, SAE, to bolster the examination administration in the cloud. It offers a novel computational disintegration strategy that variable straggling component extraction forms into all the more fine-grained sub-processes, which are then circulated over bunches of PCs for parallel execution. Trial results demonstrate that SAE can accelerate the examination by up to 1.77 times contrasted and best in class arrangements.
Keywords: Digest, SSPA, DSSA, DWA, CMS, Case Control.
1. Introduction
Interpersonal organization examination is utilized to separate features, such as neighbors and positioning scores, from informal community datasets, which comprehend human social orders. With the rise and fast advancement of social applications and models, for example, malady modeling, marketing, recommender frameworks, web crawlers and spread of impact in informal organization, interpersonal organization examination is turning into an undeniably essential administration in the cloud. For instance, k-NN is utilized in closeness inquiry, measurable grouping, recommendation frameworks, web advertising et cetera. Another sample is k-implies, which is generally utilized as a part of business sector division, choice backing etc. Different calculations incorporate associated part, Katz metric, adsorption, Page Rank SSSP et cetera. These calculations frequently need to rehash the same procedure round by round until the figuring fulfills a merging or halting condition. With a specific end goal to quicken the execution, the information articles are disseminated over groups to accomplish parallelism.
1.1Existig System
Load adjusting is a critical issue for parallel execution of informal organization examination in the cloud. Mutt rent answers for this issue either concentrate on undertaking level burden adjusting or on specialist level adjusting. At the errand level, these arrangements segment the information set by burden cost, or utilize Power-Graph for static diagram, which segments edges of every vertex to get equalization among undertakings.
At the laborer level, the best in class arrangements, to be specific steadiness based burden balancers (PLB) and retentive work taking (RWS), can progressively adjust load by means of undertakings redistribution/taking as indicated by the profiled load from the past emphases. The main drawbacks are:
This technique is very costly, as it needs to
occasionally profile load expense of every information object.
It can just statically parcel calculation for
diagrams with settled conditions and along these lines can't adaptively redistribute sub-forms over hubs to boost the usage of calculation assets.
Cannot support the calculation de-creation of
straggling FEPs.
The assignment apportioning for them for the
most part considers equity of information size, thus the comparing undertakings may not be adjusted in burden. This might bring about genuine computational and correspondence skew amid the execution of project.
2. Proposed System
parallelizes the real piece of straggling FEPs to quicken the meeting of highlight computation, additionally viably utilizes the unmoving time of PCs when accessible.
Meanwhile, the remaining non-decomposable part of a straggling FEP is unimportant which minimizes the straggling impact.
2.1
Advantages
A general way to deal with supporting productive
interpersonal organization examination, utilizing the reality the FEP is to a great extent decomposable.
The approach incorporates a strategy to recognize
straggling FEPs, a procedure to figure FEP sub forms and to adaptively circulate these sub-forms over PCs.
A programming model alongside a usage of the
runtime framework, which productively backings such a methodology.
SAE can accelerate informal community
investigation over the current arrangements
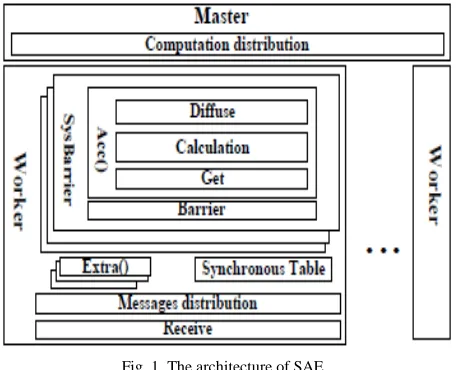
3. System Architecture
Fig. 1. The architecture of SAE.
Fig.1 The architecture of SAE. And this architecture contains number of modules. They are Decomposition, Identification and Decomposition of Straggling FEPs, and Adaptive computation distribution.
3.1 Decomposition
A noteworthy module, called the decomposable module, of the calculation errand in a FEP is decomposable, in light of the fact that every component can be seen as an aggregate
commitment from a few information objects. Hence, each FEP can be considered into a few sub forms which compute the estimation of every information protest independently. This permits us to plan a general way to deal with keep away from the effect of burden skew through a straggler mindful execution strategy.
3.2 Identification and Decomposition of Straggling
FEPs
Thus the quantity of qualities required by every
element at the handling cycle can be effectively gotten, and can likewise recognize each straggling component for consequent emphases.
Based on this perception, we can intermittently
profile load cost in past emphases, and afterward utilize this data to recognize straggling elements, and
To guide the deterioration and dissemination of
each straggling element for consequent cycles.
This way, it not just decreases runtime overheadbrought about by burden cost profiling, piece parceling and conveyance, additionally has little effect on the heap assessment and dissemination for these cycles, in light of the fact that the profiled load cost from the past emphasis might stay legitimate for the present cycle.
3.3 Adaptive computation distribution
The above computational decay just endeavors to
make more risks for straggling FEPs to be handled with generally adjusted burden among errands.
After the disintegration, a few specialists might be more vigorously stacked than others.
Redistribute hinders among specialists taking intoaccount the past burden circulation to make the heap expense of all laborers adjusted and to quicken the meeting of the remaining FEPs.
4. SAE
goal to diminish correspondence cost, SAE likewise totals these messages that are sent to the same node. Each laborer stacks a subset of information articles into memory for preparing. All information objects on a specialist are kept up in a nearby in-memory key-esteem store, namely state table. Every table section relates to fields. The primary field stores the key quality j of an information protest, the second its worth; and the third the list relating to its component recorded in the accompanying table. To store the estimation of elements, an element table is additionally required, which is ordered by the key of elements. Each table passage of this table contains four fields. The principal field stores the key worth j of a component, the second its cycle number, the third its quality in the present emphasis; and the fourth the property list.
At the principal emphasis, SAE just partitions all information objects into similarly measured parcels. At that point it can get the heap of each FEP from the completed emphasis. With this data, in the ensuing cycles, every laborer can distinguish straggling elements and parcel their related worth set into an appropriate number of squares as indicated by the capacity of every specialist. In this way, it can make more risks for the straggling FEPs to be executed and accomplish unpleasant burden parity among errands. In the meantime, the expert identifies whether there is need to redistribute obstructs as indicated by its picked up advantages and the related expense, subsequent to accepting the profiled remaining heap of every laborer, or when a few specialists get to be sit out of gear. Note that the remaining heap of every specialist can be effectively acquired by checking the quantity of natural squares and the quantity of qualities in these pieces in an inexact way. While the new cycle continues as follows in a no concurrently route without the completion of square redistribution, on the grounds that just the natural pieces are relocated. At the point when a diffused message is gotten by a worker, it triggers an Extra () operation and makes it prepare a piece of qualities contained in this message. After the finish of every Extra (), it sends its outcomes to the laborer w, where the element's unique data is recorded on this current laborer's component table. After getting this message, specialist w records the accessibility of this square on its synchronization table and stores the outcomes, where these records will be utilized by Barrier() in SysBarrier() to figure out if every required quality are accessible for related features. Then SysBarrier () is activated on this laborer. At the point when every required characteristic are accessible for a predetermined highlight, the related Acc() contained in SysBarrier() is activated and used to gather every figured aftereffect of conveyed decomposable parts for this feature. Then Acc () is utilized to ascertain another estimation of this component for the
following cycle. After the end of this cycle, this present element's new esteem is diffused to determined different elements for the following emphasis to process. At the same time, to wipe out the correspondence skew happened at the worth dissemination organize, these new values are diffused hierarchically. In this way, the correspondence expense is likewise equally dispersed over bunches at the quality dissemination stage.
5. Literature Survey
5.1 Studies about K-Nearest Neighbor Search for
Moving Query Point
This paper addresses the issue of discovering k closest neighbors for moving question point (we call it k-NNMP). It is a vital issue in both portable registering exploration and genuine applications. The issue expects that the inquiry point is not static, as in k-closest neighbor issue, but rather differs its position after some time. In this paper, four distinct techniques are proposed for taking care of the issue. Talk about the parameters influencing the execution of the calculations is likewise introduced. A succession of examinations with both manufactured and genuine point information sets is concentrated on. In the tests, our calculations dependably outflank the current ones by getting 70% less plate pages. In a few settings, the sparing can be as much as one request of size.
5.2 Studies about an Efficient k-Means Clustering
Algorithm: Analysis and Implementation
In k-implies bunching, we are given an arrangement of n information focuses in d-dimensional space Rd and a whole number k and the issue is to decide an arrangement of k focuses in Rd, called focuses, in order to minimize the mean squared separation from every information point to its closest focus. A mainstream heuristic for k-implies grouping is Lloyd's calculation. In this paper, we exhibit a straightforward and effective execution of Lloyd's k-implies bunching calculation, which we call the separating calculation. This calculation is anything but difficult to actualize, requiring a kd-tree as the main real information structure. We build up the down to earth effectiveness of the sifting calculation in two ways. To start with, we display an information delicate investigation of the calculation's running time, which demonstrates that the calculation runs speedier as the detachment between
groups’ increments. Second, we display various
applications in shading quantization, information pressure, and picture division.
6. Simulated Result
Fig. 3. The scalability of CCom algorithm executed on SAE for different Data sets.
Fig. 2 portrays the speedup of CCom calculation executed on SAE with various numbers of centers. It is evident that SAE can get a decent versatility. This is on account of that the computational skew and correspondence skew of SAE can be effectively guaranteed to be extremely low. The calculations executed on SAE can proficiently adventure the underneath groups.
8. Related Work
Load adjusting is a vital issue for parallel execution of interpersonal organization investigation in the cloud. Current answers for this issue either concentrate on task level load adjusting or on specialist level balancing. Task-level burden adjusting. Skew Reduce is a best in class answer for diminishing burden irregularity among undertakings, in perspective that in some exploratory applications, different allotments of the information object set take vastly diverse measures of time to run regardless of the fact that they have an equivalent size. It proposes to utilize client characterized fetched capacity to control the division of the information object set into similarly stacked, as opposed to similarly sized, data parcels. Be that as it may, with a specific end goal to guarantee low load unevenness for interpersonal organization examination, it needs to pay huge overhead to occasionally profile load cost for every information object and to partition the entire information set in emphases. To precisely assess load cost, Pearce et al. proposed a component mindful burden model
in view of utilization components and their interactions.PowerGraph considers the heap unevenness issue of circulated diagram applications with an attention on apportioning and handling edges for each vertex over the machines. Yet, it can just statically segment calculation for chart with altered conditions furthermore cannot adaptively redistribute sub processes over PC group to misuse the unmoving time with the execution of interpersonal organization examination.
sub-forms over PCs, intending to parallelize the decomposable piece of straggling FEP and to quicken its merging.
7. Conclusion and Future Work
For informal community examination, the merging of straggling FEP might need to encounter noteworthy quantities of emphases furthermore needs a lot of calculation and correspondence in every cycle, actuating genuine burden lopsidedness. Be that as it may, for this issue, current arrangements either require noteworthy overhead, or cannot abuse underutilized PCs when a few components joined in early cycles, or perform ineffectively in light of the high load awkwardness among introductory undertakings. This paper recognizes that the most computational piece of straggling FEP is decomposable. In light of this perception, it proposes a general way to deal with element straggling FEP into a few sub-forms alongside a technique to adaptively disseminate these sub-forms over specialists keeping in mind the end goal to quicken its convergence. Later, this paper additionally gives a programming model alongside a proficient runtime to backing this methodology. Trial results demonstrate that it can incredibly enhance the execution of interpersonal organization investigation against cutting edge approaches. In future work, we will concentrate how to utilize our methodology hierarchically to lessen the memory overhead and assess its execution pick up.
References
[1] Z. Song and N. Roussopoulos, “K-nearest neighbor search for moving query point,” Lecture Notes in Computer Science, vol.2121, pp. 79–96, July 2001.
[2] X. Yu, K. Q. Pu, and N. Koudas, “Monitoring k-nearest neighbor queries over moving objects,” in Proceedings of the 21st International Conference on Data Engineering. IEEE, 2005, pp.631–642.
[3] T. Kanungo, D. M. Mount, N. S. Netanyahu, C. D. Piatko,R. Silverman, and A. Y. Wu, “An efficient k-means clustering algorithm: Analysis and implementation,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 24, no. 7, pp. 881–892, July 2002. [4] L. Di Stefano and A. Bulgarelli, “A simple and efficient connected components labeling algorithm,” in Proceedings of the International Conference on Image Analysis and Processing. IEEE,1999, pp. 322–327. [5] E. Deelman, G. Singh, M.-H. Su, J. Blythe, Y. Gil, C. Kesselman, G. Mehta, K. Vahi, G. B. Berriman, J. Good et al., “Pegasus:A framework for mapping complex scientific workflows onto distributed systems,” Scientific Programming, vol. 13, no. 3, pp.219–237, January 2006. [6] L. Katz, “A new status index derived from sociometric analysis,” Psychometrika, vol. 18, no. 1, pp. 39–43, March 1953.
[7] D. Liben-Nowell and J. Kleinberg, “The link prediction problem for social networks,” in Proceedings of the 12th international conference on
Information and knowledge management. ACM, 2003, pp. 556–559. [8] S. Baluja, R. Seth, D. Sivakumar, Y. Jing, J. Yagnik, S. Kumar, D. Ravichandran, and M. Aly, “Video suggestion and discovery for youtube: taking random walks through the view graph,” in Proceedings of the 17th international conference on World Wide Web. ACM, 2008, pp. 895–904.
[9] S. Brin and L. Page, “The anatomy of a large-scale hyper textual web search engine,” Computer networks and ISDN systems, vol. 30, no. 1, pp. 107–117, April 1998.
[10] S. Baluja, R. Seth, D. Sivakumar, Y. Jing, J. Yagnik, S. Kumar, D. Ravichandran, and M. Aly, “Video suggestion and discovery for youtube: taking random walks through the view graph,” in Proceedings of the 17th international conference on World Wide Web. ACM, 2008, pp. 895–904.
Shaik Allabagash received the B.Tech Degree in Computer Science and Engineering from Mekapati Rajamohan Reddy Institute of Technology & Science, University of JNTUA in 2013.He is currently working towards the Master’s Degree in Computer Science, in AITS University of JNTUA. He interest lies in the areas of Web Development Platforms, SQL, and Cloud Computing Technology.