Computer Science and Artificial Intelligence Laboratory
Technical Report
MIT-CSAIL-TR-2013-026
November 1, 2013
OpenTuner: An Extensible Framework for
Program Autotuning
Jason Ansel, Shoaib Kamil, Kalyan
OpenTuner: An Extensible Framework for Program Autotuning
Jason Ansel
Shoaib Kamil
Kalyan Veeramachaneni
Una-May O’Reilly
Saman Amarasinghe
Massachusetts Institute of Technology
{jansel, skamil, kalyan, unamay, saman}@csail.mit.edu
Abstract
Program autotuning has been shown to achieve better or more portable performance in a number of domains. How-ever, autotuners themselves are rarely portable between projects, for a number of reasons: using a domain-informed search space representation is critical to achieving good re-sults; search spaces can be intractably large and require ad-vanced machine learning techniques; and the landscape of search spaces can vary greatly between different problems, sometimes requiring domain specific search techniques to explore efficiently.
This paper introduces OpenTuner, a new open source framework for building domain-specific multi-objective pro-gram autotuners. OpenTuner supports fully-customizable configuration representations, an extensible technique rep-resentation to allow for domain-specific techniques, and an easy to use interface for communicating with the program to be autotuned. A key capability inside OpenTuner is the use of ensembles of disparate search techniques simultaneously; techniques that perform well will dynamically be allocated a larger proportion of tests. We demonstrate the efficacy and generality of OpenTuner by building autotuners for 6 dis-tinct projects and 14 total benchmarks, showing speedups over prior techniques of these projects of up to2.8×with little programmer effort.
OpenTuner can be downloaded from:
http://opentuner.org/
1. Introduction
Program autotuning is increasingly being used in domains such as high performance computing and graphics to op-timize programs. Program autotuning augments traditional human-guided optimization by offloading some or all of the search for an optimal program implementation to an auto-mated search technique. Rather than optimizing a program directly, the programmer expresses a search space of possi-ble implementations and optimizations. Autotuning can of-ten make the optimization process more efficient as auto-tuners are able to search larger spaces than is possible by hand. Autotuning also provides performance portability, as the autotuning process can easily be re-run on new machines
which require different sets of optimizations. Finally, multi-objective autotuning can be used to trade off between per-formance and accuracy, or other criteria such as energy con-sumption and memory usage, and provide programs which meet given performance or quality of service targets.
While the practice of autotuning has increased in popu-larity, autotuners themselves often remain relatively simple and project specific. There are three main challenges which make the development of autotuning frameworks difficult.
The first challenge is using the right configuration rep-resentation for the problem. Configurations can contain pa-rameters that vary from a single integer for a block size to a much more complex type such as an expression tree rep-resenting a set of instructions. The creator of the autotuner must find ways to represent their complex domain-specific data structures and constraints. When these data structures are naively mapped to simpler representations, such as a point in high dimensional space, locality information is lost which makes the search problem much more difficult. Pick-ing the right representation for the search space is critical to having an effective autotuner. To date, all autotuners that have used a representation other than the simplest ones have had custom project-specific representations.
The second challenge is the size of the valid configura-tion space. While some prior autotuners have worked hard to prune the configuration space, we have found that for many problems excessive search space pruning will miss out on non-intuitive good configurations. We believe providing all the valid configurations of these search spaces is better than artificially constraining search spaces and possibly missing optimal solutions. Search spaces can be very large, up to 103600 possible configurations for one of our benchmarks. Full exhaustive search of such a space will not complete in human lifetimes! Thus, intelligent machine learning tech-niques are required to seek out a good result with a small number of experiments.
The third challenge is the landscape of the configuration space. If the configuration space is a monotonic function, a search technique biased towards this type of search space (such as a hill climber) will be able to find the optimal con-figuration. If the search space is discontinuous and haphaz-ard an evolution algorithm may perform better. However, in practice search spaces are much more complex, with
discon-tinuities, high dimensionality, plateaus, hills with some of the configuration parameters strongly coupled and some oth-ers independent from each other. A search technique that is optimal in one type of configuration space may fail to locate an adequate configuration in another. It is difficult to provide a robust system that performs well in a variety of situations. Additionally, many application domains will have domain-specific search techniques (such as scheduling or blocking heuristics) which may be critical to finding an optimal solu-tion efficiently. This has caused most prior autotuners to use customized search techniques tailored to their specific prob-lem. This requires machine learning expertise in addition to the individual domain expertise to build an autotuner for a system. We believe that this is one of the main reasons that, while autotuners are recognized as critical for performance optimization, they have not seen commodity adoption.
In this paper we present OpenTuner, a new framework for building domain-specific program autotuners. OpenTuner features an extensible configuration and technique represen-tation able to support complex and user-defined data types and custom search heuristics. It contains a library of pre-defined data types and search techniques to make it easy to setup a new project. Thus, OpenTuner solves the custom configuration problem by providing not only a library of data types that will be sufficient for most projects, but also exten-sible data types that can be used to support more complex domain specific representations when needed.
A core concept in OpenTuner is the use of ensembles
of search techniques. Many search techniques (both built in and user-defined) are run at the same time, each testing candidate configurations. Techniques which perform well by finding better configurations are allocated larger budgets of tests to run, while techniques which perform poorly are allo-cated fewer tests or disabled entirely. Techniques are able to share results using a common results database to construc-tively help each other in finding an optimal solution. To allo-cate tests between techniques we use an optimal solution to themulti-armed banditproblem using area under the curve credit assignment. Ensembles of techniques solve the large and complex search space problem by providing both a ro-bust solutions to many types of large search spaces and a way to seamlessly incorporate domain specific search tech-niques.
1.1 Contributions
This paper makes the following contributions:
•To the best of our knowledge, OpenTuner is the first to introduce a general framework to describe complex search spaces for program autotuning.
•OpenTuner introduces the concept of ensembles of search techniques to program autotuning, which allow many search techniques to work together to find an optimal solution.
•OpenTuner provides more sophisticated search tech-niques than typical program auotuners. This enables ex-panded uses of program autotuning to solve more com-plex search problems and pushes the state of the art for-ward in program autotuning in a way that can easily be adopted by other projects.
•We demonstrate the versatility of our framework by building autotuners for 6 distinct projects and demon-strate the effectiveness of the system with 14 total bench-marks, showing speedups over existing techniques of up to2.8×.
•We show that OpenTuner is able to succeed both in mas-sively large search spaces, exceeding 103600 possible configurations in size, and in smaller search spaces using less than 2% of the tests required for exhaustive search.
2. Related Work
Package Domain Search Method
Active Harmony [30] Runtime System Nelder-Mead
ATLAS [33] Dense Linear Algebra Exhaustive
FFTW [14] Fast Fourier Transform Exhaustive/Dynamic Prog.
Insieme [19] Compiler Differential Evolution
OSKI [32] Sparse Linear Algebra Exhaustive+Heuristic
PATUS [9] Stencil Computations Nelder-Mead or Evolutionary
PetaBricks [4] Programming Language Bottom-up Evolutionary
Sepya [21] Stencil Computations Random-Restart Gradient Ascent
SPIRAL [27] DSP Algorithms Pareto Active Learning
Figure 1. Summary of selected related projects using auto-tuning
A number of offline empirical autotuning frameworks have been developed for building efficient, portable libraries in specific domains; selected projects and techniques used are summarized in Figure 1. ATLAS [33] utilizes empirical autotuning to produce an optimized matrix multiply routine. FFTW [14] uses empirical autotuning to combine solvers for FFTs. Other autotuning systems include SPIRAL [27] for digital signal processing PATUS [9] and Sepya [21] for sten-cil computations, and OSKI [32] for sparse matrix kernels.
The area of iterative compilation contains many projects that use different machine learning techniques to optimize lower level compiler optimizations [1, 2, 15, 25]. These projects change both the order that compiler passes are ap-plied and the types of passes that are apap-plied.
In the dynamic autotuning space, there have been a num-ber of systems developed [5, 6, 8, 16, 18, 22] that focus on creating applications that can monitor and automatically tune themselves to optimize a particular objective. Many of these systems employ a control systems based autotuner that operates on a linear model of the application being tuned. For example, PowerDial [18] converts static configuration parameters that already exist in a program into dynamic knobs that can be tuned at runtime, with the goal of trad-ing QoS guarantees for meettrad-ing performance and power us-age goals. The system uses an offline learning stus-age to con-struct a linear model of the choice configuration space which
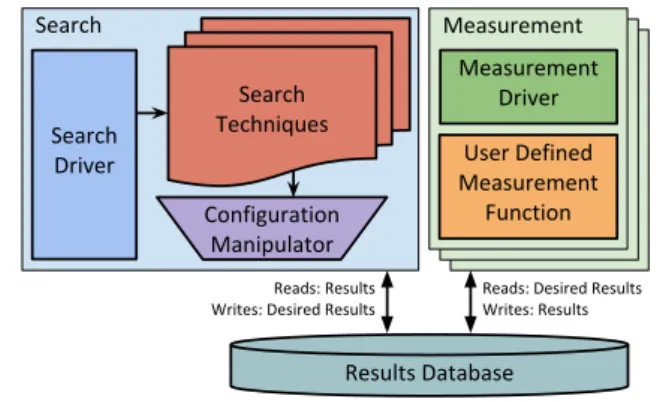
Results Database Search Techniques Search Driver Search Reads: Results Writes: Desired Results
Measurement User Defined Measurement Function Measurement Driver Configuration Manipulator
Reads: Desired Results Writes: Results
Figure 2. Overview of the major components in the Open-Tuner framework.
can be subsequently tuned using a linear control system. The system employs the heartbeat framework [17] to pro-vide feedback to the control system. A similar technique is employed in [16], where a simpler heuristic-based con-troller dynamically adjusts the degree of loop perforation performed on a target application to trade QoS for perfor-mance.
3. The OpenTuner Framework
Our terminology reflects that the autotuning problem is cast as a search problem. The search space is made up of config-urations, which are concrete assignments of a set of param-eters. Parameters can beprimitivesuch as an integer or com-plexsuch as a permutation of a list. When the performance, output accuracy, or other metrics of a configuration are mea-sured (typically by running it in a domain-specific way), we call this measurement a result. Search techniques are methods for exploring the search space and make requests for measurement called desired results. Search techniques can change configurations using a user-definedconfiguration manipulator, which also includesparameterscorresponding directly the parameters in the configuration. Some parame-ters includemanipulators, which are opaque functions that make stochastic changes to a specific parameter in a config-uration.
Figure 2 provides an overview of the major compo-nents in OpenTuner. Thesearchprocess includes techniques, which use the user defined configuration manipulator in or-der to read and write configurations. Themeasurement pro-cesses evaluate candidate configurations using a user defined measurement function. These two components communi-cate exclusively through aresults databaseused to record all results collected during the tuning process, as well as the providing ability to perform multiple measurements in parallel.
3.1 OpenTuner Usage
To implement an autotuner with OpenTuner, first, the user must define the search space by creating a configuration manipulator. This configuration manipulator includes a set
of parameter objects which OpenTuner will search over. Second, the user must define arunfunction which evaluates the fitness of a given configuration in the search space to preduce a result. These must be implemented in a small Python program in order interface with the OpenTuner API. Figure 3 shows an example of using OpenTuner to search over the space of compiler flags to GCC in order to minimize execution time of the resulting program. In Section 4, we present results on an expanded version of this example which obtains up to 2.8x speedup over-O3.
This example tunes three types of flags to GCC. First it choses between the four optimization levels-O0,-O1,-O2,
-O3. Second, for 176 flags listed on line 8 it decides between turning the flag on (with-fFLAG), off (with-fno-FLAG), or omitting the flag in order to let default value to take prece-dence. Including the default value as a choice is not neces-sary for completeness, but speeds up convergence and results in shorter command lines. Finally, it assigns a bounded inte-ger value to the 145 parameters on line 15 with the--param NAME=VALUEcommand line option.
The method manipulator (line 23), is called once at startup and creates aConfigurationManipulatorobject which defines the search space of GCC flags. All accesses to configurations by search techniques are done through the configuration manipulator. For optimization level, an
IntegerParameterbetween 0 and 3 is created. For each flag, aEnumParameteris created which can take the values
on,off, anddefault. Finally, for the remaining bounded GCC parameters, anIntegerParameteris created with the appropriate range.
The methodrun(line 40), implements the measurement function for configurations. First, the configuration is real-ized as specific command line tog++. Next, thisg++ com-mand line is run to produce an executable,tmp.bin, which is then run usingcall program.Call programis a con-vince function which runs and measures the execution time of the given program. Finally, aResultis constructed and returned, which is a database record type containing many other optional fields such astime,accuracy, andenergy. By default OpenTuner minimizes thetime field, however this can be customized.
3.2 Search Techniques
To provide robust search, OpenTuner includes techniques that can handle many types of search spaces and runs a collection of search techniques at the same time. Tech-niques which perform well are allocated more tests, while techniques which perform poorly are allocated fewer tests. Techniques share results through the results database, so that improvements made by one technique can benefit other techniques. OpenTuner techniques are meant to be ex-tended. Users can define custom techniques which imple-ment domain-specific heuristics and add them toensembles
1 import o p e n t u n e r
2 from o p e n t u n e r import C o n f i g u r a t i o n M a n i p u l a t o r
3 from o p e n t u n e r import EnumParameter
4 from o p e n t u n e r import I n t e g e r P a r a m e t e r 5 from o p e n t u n e r import M e a s u r e m e n t I n t e r f a c e 6 from o p e n t u n e r import R e s u l t 7 8 GCC FLAGS = [ 9 ’ a l i g n−f u n c t i o n s ’, ’ a l i g n−jumps ’, ’ a l i g n−l a b e l s ’,
10 ’ branch−count−r e g ’, ’ branch−p r o b a b i l i t i e s ’,
11 # . . . (176 t o t a l )
12 ]
13
14 # ( name , min , max )
15 GCC PARAMS = [ 16 (’ e a r l y−i n l i n i n g−i n s n s ’, 0 , 1000) , 17 (’ gcse−c o s t−d i s t a n c e−r a t i o ’, 0 , 1 0 0 ) , 18 # . . . (145 t o t a l ) 19 ] 20 21 c l a s s GccFlagsTuner ( M e a s u r e m e n t I n t e r f a c e ) : 22 23 def m a n i p u l a t o r ( s e l f ) : 24 ””” 25 Define t h e s e a r c h s pa ce by c r e a t i n g a 26 C o n f i g u r a t i o n M a n i p u l a t o r 27 ””” 28 m a n i p u l a t o r = C o n f i g u r a t i o n M a n i p u l a t o r ( ) 29 m a n i p u l a t o r . a d d p a r a m e t e r ( 30 I n t e g e r P a r a m e t e r (’ o p t l e v e l ’, 0 , 3 ) ) 31 f o r f l a g in GCC FLAGS : 32 m a n i p u l a t o r . a d d p a r a m e t e r ( 33 EnumParameter ( f l a g , 34 [’ on ’, ’ o f f ’, ’ d e f a u l t ’] ) )
35 f o r param , min , max in GCC PARAMS:
36 m a n i p u l a t o r . a d d p a r a m e t e r (
37 I n t e g e r P a r a m e t e r ( param , min , max ) )
38 return m a n i p u l a t o r
39
40 def run ( s e l f , d e s i r e d r e s u l t , i n p u t , l i m i t ) :
41 ”””
42 Compile and run a giv en c o n f i g u r a t i o n t h e n
43 r e t u r n performance 44 ””” 45 c fg = d e s i r e d r e s u l t . c o n f i g u r a t i o n . d a t a 46 gcc cmd = ’ g++ r a y t r a c e r . cpp −o . / tmp . bi n ’ 47 gcc cmd += ’ −O{0}’. f o r m a t ( c fg [’ o p t l e v e l ’] ) 48 f o r f l a g in GCC FLAGS : 49 i f c f g [ f l a g ] == ’ on ’: 50 gcc cmd += ’ −f{0}’. f o r m a t ( f l a g ) 51 e l i f c f g [ f l a g ] == ’ o f f ’: 52 gcc cmd += ’ −fno−{0}’. f o r m a t ( f l a g )
53 f o r param , min , max in GCC PARAMS:
54 gcc cmd += ’ −−param {0}={1}’. f o r m a t ( 55 param , c f g [ param ] ) 56 57 c o m p i l e r e s u l t = s e l f . c a l l p r o g r a m ( gcc cmd ) 58 a s s e r t c o m p i l e r e s u l t [’ r e t u r n c o d e ’] == 0 59 r u n r e s u l t = s e l f . c a l l p r o g r a m (’ . / tmp . b i n ’) 60 a s s e r t r u n r e s u l t [’ r e t u r n c o d e ’] == 0
61 return R e s u l t ( time = r u n r e s u l t [’ time ’] )
62
63 i f n a m e == ’ m a i n ’:
64 a r g p a r s e r = o p e n t u n e r . d e f a u l t a r g p a r s e r ( )
65 GccFlagsTuner . main ( a r g p a r s e r . p a r s e a r g s ( ) )
Figure 3. GCC/G++ flags autotuner using OpenTuner.
Ensembles of techniques are created by instantiating a
meta technique, which is a technique made up of a collec-tion of other techniques. The OpenTuner search driver inter-acts with a singleroottechnique, which is typically a meta technique. When the meta technique gets allocated tests, it incrementally decides how to divide theses tests among its sub-techniques. OpenTuner contains an extensible class hi-erarchy of techniques and meta techniques, which can be combined together and used in autotuners.
3.2.1 AUC Bandit Meta Technique
In addition to a number of simple meta techniques, such as round robin, OpenTuner’s core meta technique used in re-sults is themulti-armed bandit with sliding window, area under the curve credit assignment(AUC Bandit) meta tech-nique. A similar technique was used in [24] in the different context of online operator selection. It is based on an optimal solution to the armed bandit problem [12]. The multi-armed bandit problem is the problem of picking levers to pull on a slot machine with many arms each with an unknown payout probability. It encapsulates a fundamental trade-off betweenexploitation(using the best known technique) and
exploration(estimating the performance of all techniques). The AUC Bandit meta technique assigns each test to the technique,t, defined by the formula
arg max
t (AUCt+C
s
2 lg|H|
Ht )
where|H|is the length of the sliding history window,Htis
the number of times the technique has been used in that his-tory window, C is a constant controlling the exploration/ex-ploitation trade-off, andAUCtis the credit assignment term
quantifying the performance of the technique in the sliding window. The second term in the equation is the exploration term which gets smaller the more often a technique is used.
The area under the curve credit assignment mechanism, based on [13], draws a curve by looking at the history for a specific technique and looking only at if a technique yielded a new global best or not. If the technique yielded a new global best, a upward line is draw, otherwise a flat line is drawn. The area under this curve (scaled to a maximum value of 1) is the total credit attributed to the technique. This credit assignment mechanism can be described more precisely by the formula:
AUCt=|V 2 t|(|Vt|+ 1) |Vt| X i=1 iVt,i
whereVtis the list of uses oftin the sliding window history.
Vt,i is 1 if using technique t the ith time in the history
resulted in a speedup, otherwise 0. 3.2.2 Other Techniques
OpenTuner includes implementations of the techniques: dif-ferential evolution; many variants of Nelder Mead and
Torc-Parameter
Primitive Complex
Integer Float ScaledNumeric
LogInteger LogFloat PowerOfTwo
Switch Enum Permutation
Schedule
Selector Boolean
Figure 4. Hierarchy of built in parameter types. User de-fined types can be added at any point below Primitive or
Complexin the tree.
zon hillclimbers; a number of evolutionary mutation tech-niques; pattern search; particle swarm optimization; and random search. OpenTuner also includes a bandit mutation technique which uses the same AUC Bandit method to de-cide which manipulator function across all parameters to call on the best known configuration. These techniques span a range of strategies and are each biased to perform best in different types of search spaces. They also each contain many settings which can be configured to change their be-havior. Each technique has been modified so that with some probability it will use information found by other techniques if other techniques have discovered a better configuration.
The default meta technique, used in results in this paper and meant to be robust, uses an AUC Bandit meta technique to combine greedy mutation, differential evolution, and two hill climber instances.
3.3 Configuration Manipulator
The configuration manipulator provides a layer of abstrac-tion between the search techniques and the raw configura-tion structure. It is primarily responsible for managing a list of parameter objects, each of which can be used by search techniques to read and write parts of the underlying config-uration.
The default implementation of the configuration manip-ulator uses a fixed list of parameters and stores the config-uration as a dictionary from parameter name to parameter-dependant data type. The configuration manipulator can be extended by the user either to change the underlying data structure used for configurations or to support a dynamic list of parameters that is dependant on the configuration in-stance.
3.3.1 Parameter Types
Figure 4 shows the class hierarchy of built-in parameter types in OpenTuner. Each parameter type is responsible for interfacing between the raw representation of a parameter in the configuration and standardized view of that parameter presented to the search techniques. Parameter types can be extended both to change the underlying representation, and to change the abstraction provided to search techniques to cause a parameter to be search in different ways.
From the viewpoint of search techniques there are two main types of parameters, each of which provides a different abstraction to the search techniques:
Primitive parameters present a view to search techniques of a numeric value with an upper and lower bound. These upper and lower bounds can be dependant on the configura-tion instance.
The built in parameter typesFloatandLogFloat(and similarly Integer and LogInteger) both have identical representations in the configuration, but present a differ-ent view of the underlying value to the search techniques.
Floatis presented directly to to search techniques, while
LogFloatpresents a log scaled view of the underlying pa-rameter to search techniques. To a search technique, halving and doubling a log scaled parameter are changes of equal magnitude. Log scaled variants of parameters are often bet-ter for paramebet-ters such as block sizes where fixed changes in values have diminishing effects the larger the parameter be-comes.PowerOfTwois a commonly used special case, sim-ilar toLogInteger, where the legal values of the parameter are restricted to powers of two.
Complex parameters present a more opaque view to
search techniques. Complex parameters have a variable set of manipulation operators (manipulators) which make stochastic changes to the underlying parameter. These ma-nipulators are arbitrary functions defined on the parameter which can make high level type dependant changes. Com-plex parameters are meant to be easily extended to add do-main specific structures to the search space.
The built in parameter typesBoolean,Switch, andEnum
could theoretically also be represented as primitive param-eters, since they each can be translated directly to a small integer representation. However, in the context of search techniques they make more sense as complex parameters. The reason for this is that for primitive parameters search techniques will attempt to follow gradients. These parame-ter types are unordered collections of values for which no gradients exist. Thus, the complex parameter abstraction is a more efficient representation to search over.
The Permutationparameter type assigns an order to a given list of values and has manipulators which make various types of random changes to the permutation. ASchedule
parameter is a Permutation with a set of dependencies that limit the legal order. Schedules are implemented as a permutation that gets topologically sorted after each change. Finally, aSelectorparameter is a special type of tree which is used to define a mapping from an integer input to an enumerated value type.
In addition to these primary primitive and complex ab-stractions for parameter types, there are a number of derived ways that search techniques will interact with parameters in order to more precisely convey intent. These are additional methods on parameter which contain default implementa-tions for both primitive and complex parameter types. These methods can optionally be overridden for specific parame-ters types to improve search techniques. Parameter types will
work without these methods being overridden, however im-plementing them can improve results.
As an example, a common operation in many search techniques is to add the difference between configurationA andB to configurationC. This is used both in differential evolution and many hill climbers. Complex parameters have a default implementation of this indent which compares the value of the parameter in the 3 configurations: ifA = B, then there is no difference and the result is C; similarly, ifB = C, thenA is returned; otherwise a change should be made so random manipulators are called. This works in general, however for individual parameter types there are often better interpretations. For example with permutations, one could calculate the positional movement of each item in the list an calculate a new permutation by applying these movements again.
3.4 Objectives
OpenTuner supports multiple user defined objectives. Re-sult records have fields fortime,accuracy,energy,size,
confidence, and user defined data. The default objective is to minimize time. Many other objectives are supported, such as: maximize accuracy; threshold accuracy while min-imizing time; and maximize accuracy then minimize size. The user can easily define their own objective by defining comparison operators and display methods on a subclass of Objective.
3.5 Search Driver and Measurement
OpenTuner is divided into two submodules, search and mea-surement. The search driver and measurement driver in each of these modules orchestrate most of the framework of the search process. These two modules communicate only through the results database. The measurement module is minimal by design and is primarily a wrapper around the user defined measurement function which creates results from configurations.
This division between search and measurement is moti-vated by a number of different factors:
•To allow parallelism between multiple search measure-ment processes, possibly across different machines. Par-allelism is most important in the measurement processes since in most autotuning applications measurement costs dominate. To allow for parallelism the search driver will make multiple requests for desired results without wait-ing for each request to be fulfilled. If a specific technique is blocking waiting for results, other techniques in the en-semble will used to fill out requests to prevent idle time. •The separation of the measurement modules is desirable
to support online learning and sideline learning. In these setups, autotuning is not done before deployment of an application, but is done online as an application is run-ning or during idle time. Since the measurement module is minimal by design, it can be replaced by an domain
specific online learning module which periodically ex-amines the database to decide which which configuration to use and records performance back to the database. •Finally, in many embedded or mobile settings which
re-quire constrained measurement environments it is de-sirable to have a minimal measurement module which can easily be re-implemented in other languages without needing to modify the majority of the OpenTuner frame-work.
3.6 Results Database
The results database is a fully featured SQL database. All major database types are supported, and SQLite is used if the user has not configured a database type so that no setup is required. It allows different techniques to query and share results in a variety of ways and is useful for introspection about the performance of techniques across large numbers of runs of the autotuner.
4. Experimental Results
Project Benchmark Possible Configurations
GCC/G++ Flags all 10806 Halide Blur 1052 Halide Wavelet 1044 HPL n/a 109.9 PetaBricks Poisson 103657 PetaBricks Sort 1090 PetaBricks Strassen 10188 PetaBricks TriSolve 101559 Stencil all 106.5 Unitary n/a 1021
Figure 5. Search space sizes in number of possible config-urations, as represented in OpenTuner.
We validated OpenTuner by using it to implemented auto-tuners for six distinct projects. This section describes these six projects, the autotuners we implemented, and presents results comparing to prior practices in each project.
Figure 5 lists, for each benchmark, the number of distinct configurations that can be generated by OpenTuner. This measure is not perfect because some configurations may be semantically equivalent and the search space depends on the representation chosen in OpenTuner. It does, however, provide a sense of the relative size of each search space, which is useful as a first approximation of tuning difficulty. 4.1 GCC/G++ Flags
The GCC/G++ flags autotuner is described in detail in Sec-tion 3.1. There are a number features that were omitted from the earlier example code for simplicity, which are included in the full version of the autotuner.
First, we added error checking to gracefully handle the compiler or the output program hanging, crashing, running out of memory, or otherwise going wrong. Our tests uncov-ered a number of bugs in GCC which trigguncov-ered internal com-piler errors and we implemented code to detect, diagnose,
0.8 0.85 0.9 0.95 1 0 300 600 900 1200 1500 1800
Execution Time (seconds)
Autotuning Time (seconds) gcc -O1 gcc -O2 gcc -O3 OpenTuner (a) fft.c 0.1 0.15 0.2 0.25 0.3 0 300 600 900 1200 1500 1800
Execution Time (seconds)
Autotuning Time (seconds) g++ -O1 g++ -O2 g++ -O3 OpenTuner (b) matrixmultiply.cpp 0.4 0.45 0.5 0.55 0.6 0.65 0.7 0.75 0 300 600 900 1200 1500 1800
Execution Time (seconds)
Autotuning Time (seconds) g++ -O1 g++ -O2 g++ -O3 OpenTuner (c) raytracer.cpp 0.4 0.45 0.5 0.55 0.6 0 300 600 900 1200 1500 1800
Execution Time (seconds)
Autotuning Time (seconds) g++ -O1 g++ -O2 g++ -O3 OpenTuner
(d) tsp ga.cpp
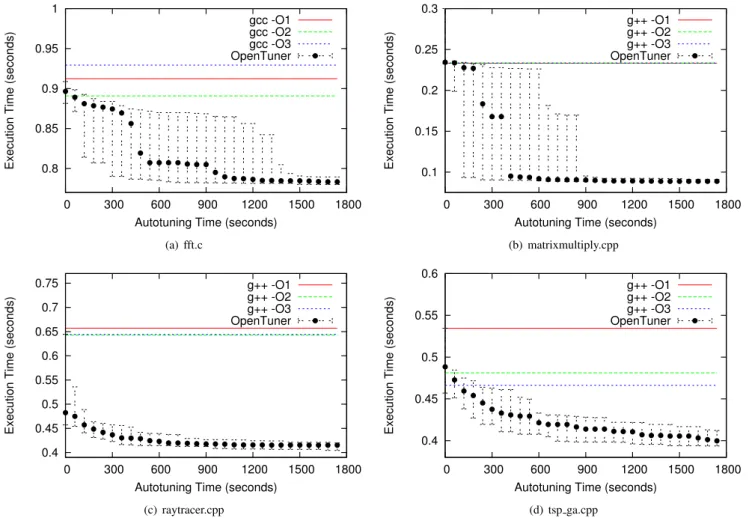
Figure 6. GCC/G++ Flags: Execution time (lower is better) as a function of autotuning time. Aggregated performance of 30 runs of OpenTuner, error bars indicate median, 20th, and 80th percentiles. Note that in (b) the O1/O2/O3 and in (c) the O2/O3 lines are on top of each other and may be difficult to see.
and avoid error-causing sets of flags. We are submitting bug reports for these crashes to the GCC developers.
Second, instead of using a fixed list of flags and pa-rameters (which the example does for simplicity), our full autotuner automatically extracts the supported flags from
g++ --help=optimizers. Parameters and legal ranges are extracted automatically fromparams.def in the GCC source code.
Additionally, there were a number of smaller features such as: time limits to abort slow tests which will not be optimal; use ofLogIntegerparameter types for some val-ues; asave final configmethod to output the final flags; and many command line options to autotuner behavior.
We ran experiments usinggcc 4.7.3-1ubuntu1, on an 8 total core, 2-socket Xeon E5320. We allowed flags such a
-ffast-mathwhich can change rounding / NaN behavior of floating point numbers and have small impacts on pro-gram results. We still observe speedups with these flags re-moved.
For target programs to optimize we used: A fast Fourier transform in C, fft.c, taken from the SPLASH2 [34]
bench-mark suite; A C++ template matrix multiply,
matrix-multiply.cpp, written by Xiang Fan [11] (version 3); A C++ ray tracer, raytracer.cpp, taken from the scratch-pixel website [26]; and a genetic algorithm to solve the trav-eling salesman program in C++,tsp ga.cpp, by Kristoffer Nordkvist [23], which we modified to run deterministically. These programs were chosen to span a range from highly optimized codes, like fft.c which contains cache aware tiling and threading, to less optimized codes, like matrix-multiply.cppwhich contains only a transpose of one of the inputs.
Figure 6 shows the performance for autotuning GC-C/G++ flags on four different sample programs. Final speedups ranged from1.15×for FFT to 2.82×for matrix multiply. Examining the frequencies of different flags in the final configurations, we can see some patterns and some differ-ences between the benchmarks. In all programs -funsafe-math-optimizations (and related flags) and -O3 flags were very common. There were a number of flags that were only common only in specific benchmarks:
•matrixmultiply.cpp:-fvariable-expansion-in-unrollerand
-ftree-vectorize
•raytracer.cpp:-fno-reg-struct-return
•fft.c:--param=allow-packed-store-data-races=1,
-frerun-cse-after-loop, and-funroll-all-loops
•tsp ga.cpp:--param=use-canonical-types=1and
-fno-schedule-insns2.
However these most common flags alone do not account for all of the speedup. Full command lines found contained typically 200 to 300 options and are difficult understand by hand.
4.2 Halide
Halide [28, 29] is a domain-specific language and com-piler for image processing and computational photography, specifically targeted towards image processingpipelinesthat contain several stages. Halide separates the scheduling of the image processing stages from the expression of the kernels themselves, allowing expert programmers to dictate complex schedules that result in high performance.
The Halide project originally integrated an autotuner, which was removed from the project because it became too complex to maintain and was rarely used in practice. We hope that our new OpenTuner-based autotuner for Halide, presented here, will be easier to maintain, both because it benefits from some of the lessons learned from the original autotuner and because it provides a clear separation between the search techniques and the definition of the search space. Unfortunately, the original Halide autotuner cannot be used as a baseline to compare against, because the Halide code base has changed too much since its removal.
The autotuning problem in Halide is to synthesize execu-tion schedules that control how Halide generates code. As an example, the hand-tuned schedule (against which we com-pare our autotuner) for the blur example is:
b l u r y . s p l i t ( y , y , yi , 8) . p a r a l l e l ( y ) . v e c t o r i z e ( x , 8 ) ; b l u r x . s t o r e a t ( b l u r y , y ) . c o m p u t e a t ( b l u r y , y i ) . v e c t o r i z e ( x , 8 ) ;
blur y(x, y)andblur y(x, y)are Halide functions in the program. The scheduling operators which the autotuner can use to synthesize schedules are:
•splitintroduces a new variable and loop nest by adding a layer of blocking. This operator makes the search space theoretically infinite; however, we limit the number of splits to at most 4 per dimension of each function, which is sufficient in practice. We represent each of these splits as a PowerOfTwoParameter, where setting the size of the split to 1 corresponds to not using the split operator. •parallel,vectorize, andunrollcause the loop nest
associated with a given variable in the function to be executed in parallel, SSE vectorized, or unrolled. Open-Tuner represents these operators as anEnumParameter
8.6 8.65 8.7 8.75 8.8 8.85 8.9 8.95 9 9.05 0 200 400 600 800 1000 1200 1400 1600 1800
Execution Time (seconds)
Autotuning Time (seconds) Vendor-optimized
OpenTuner
Figure 8. High Performance Linpack: Execution time (lower is better) as a function of autotuning time. Aggre-gated performance of 30 runs of OpenTuner, error bars indi-cate median, 20th, and 80th percentiles.
for each variable/function pair including temporary vari-ables possibly introduced by splits to decide on an oper-ator, including no operator as a choice.
•reorder / reorder storage take a list of variables and reorganizes the loop nest order or storage order for those variables. We represent this is as a Permutation-Parameter, which includes all possible variables intro-duced by splits.
•compute at / store at cause the execution or stor-age for a given function to be embedded inside of the loop nest of a different function. We represent this as anEnumParameterwith all legal function/variable pairs and special tokens for global and inline as options. The most difficult parameter to search iscompute at be-cause most choices combinations for this parameter will cre-ate invalid schedules are are rejected by the compiler. We created a custom domain specific technique which attempted to create more legal schedules by biasing the search of the parameter.
Figure 7 presents results for blur and the inverse Daubechies wavelet transform written in Halide. For both of these exam-ples OpenTuner is able to create schedules that beat the hand optimized schedules shipping with the Halide source code. Results were collected on an 8-core Core i7 920 processor using a development build of Halide.
4.3 High Performance Linpack
The High Performance Linpack benchmark [10] is used to evaluate floating point performance of machines ranging from small multiprocessors to large-scale clusters, and is the evaluation criterion for the Top 500 [31] supercomputer benchmark. The benchmark measures the speed of solving a large random dense linear system of equations using dis-tributed memory. Achieving optimal performance requires tuning about fifteen parameters, including matrix block sizes and algorithmic parameters. To assist in tuning, HPL
0.001 0.002 0.003 0.004 0.005 0.006 0 600 1200 1800 2400 3000 3600
Execution Time (seconds)
Autotuning Time (seconds) Hand-optimized OpenTuner (a) Blur 0.005 0.006 0.007 0.008 0.009 0.01 0 600 1200 1800 2400 3000 3600
Execution Time (seconds)
Autotuning Time (seconds) Hand-optimized
OpenTuner
(b) Wavelet
Figure 7. Halide: Execution time (lower is better) as a function of autotuning time. Aggregated performance of 30 runs of OpenTuner, error bars indicate median, 20th, and 80th percentiles.
cludes a built in autotuner that uses exhaustive search over user-provided discrete values of the parameters.
We run HPL on a 2.93 GHz Intel Sandy Bridge quad-core machine running Linux kernel 3.2.0, compiled with GCC 4.5 and using the Intel Math Kernel Library (MKL) 11.0 for optimized math operations. For comparison pur-poses, we evaluate performance relative to Intel’s optimized HPL implementation1. We encode the input tuning
param-eters for HPL as na¨ıvely as possible, without using any machine-specific knowledge. For most parameters, we uti-lizeEnumParameterorSwitchParameter, as they gener-ally represent discrete choices in the algorithm used. The major parameter that controls performance is the blocksize of the matrix; this we represent as anIntegerParameter
to give as much freedom as possible for the autotuner for searching. Another major parameter controls the distribution of the matrix onto the processors; we represent this by enu-merating all 2D decompositions possible for the number of processors on the machine.
Figure 8 shows the results of 30 tuning runs using Open-Tuner, compared with the vendor-provided performance. The median performance across runs, after 1200 seconds of autotuning, exceeds the performance of Intel’s optimized parameters. Overall, OpenTuner obtains a best performance of 86.5% of theoretical peak performance on this machine, while exploring a miniscule amount of the overall search space. Furthermore, the blocksize chosen is not a power of two, and is generally a value unlikely to be guessed for use in hand-tuning.
4.4 PetaBricks
PetaBricks [3] is an implicitly parallel language and com-piler which incorporates the concept of algorithmic choice into the language. The PetaBricks language provides a
1Available at http://software.intel.com/en-us/articles/
intel-math-kernel-library-linpack-download.
framework for the programmer to describe multiple ways of solving a problem while allowing the autotuner to deter-mine which of those ways is best for the user’s situation. The search space of PetaBricks programs is both over low level optimizations and over different algorithms. The au-totuner is used to synthesizepoly-algorithmswhich weave many individual algorithms together by switching dynami-cally between them at recursive call sites.
The primary components in the search space for PetaBricks programs arealgorithmic selectorswhich are used to synthe-size instances of poly-algorithms from algorithmic choices in the PetaBricks language. A selector is used to map in-put sizes to algorithmic choices, and is represented by a list of cutoffs and choices. As an example, the selector [InsertionSort,500,QuickSort,1000,MergeSort]would cor-respond to synthesizing the function:
void S o r t ( L i s t& l i s t ) { i f( l i s t . l e n g t h < 500) I n s e r t i o n S o r t ( l i s t ) ; e l s e i f( l i s t . l e n g t h < 1000) QuickSort ( l i s t ) ; e l s e MergeSort ( l i s t ) ; }
whereQuickSortandMergeSortrecursively callSortso the program dynamically switches between sorting methods as recursive calls are made on smaller and smaller lists. We used the generalSelectorParameterto represent this choice type, which internally keeps track of the order of the algorithmic choices and the cutoffs. PetaBricks programs contain many algorithmic selectors and a large number of other parameter types, such as block sizes, thread counts, iteration counts, and program specific parameters.
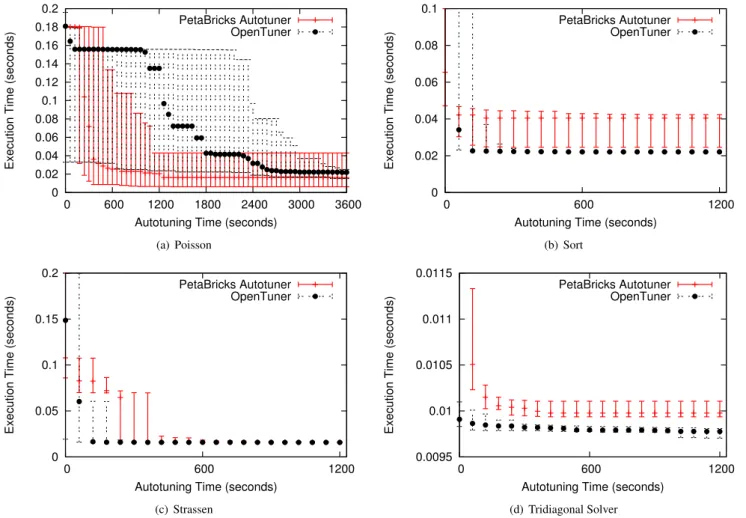
Results using OpenTuner compared to the built-in PetaBricks autotuner are shown in Figure 9. The PetaBricks autotuner uses a different strategy that starts with tests on very small problem inputs and incrementally works up to full sized inputs [4]. In all cases, the autotuners arrive at similar
0 0.02 0.04 0.06 0.08 0.1 0.12 0.14 0.16 0.18 0.2 0 600 1200 1800 2400 3000 3600
Execution Time (seconds)
Autotuning Time (seconds) PetaBricks Autotuner OpenTuner (a) Poisson 0 0.02 0.04 0.06 0.08 0.1 0 600 1200
Execution Time (seconds)
Autotuning Time (seconds) PetaBricks Autotuner OpenTuner (b) Sort 0 0.05 0.1 0.15 0.2 0 600 1200
Execution Time (seconds)
Autotuning Time (seconds) PetaBricks Autotuner OpenTuner (c) Strassen 0.0095 0.01 0.0105 0.011 0.0115 0 600 1200
Execution Time (seconds)
Autotuning Time (seconds) PetaBricks Autotuner
OpenTuner
(d) Tridiagonal Solver
Figure 9. PetaBricks: Execution time (lower is better) as a function of autotuning time. Aggregated performance of 30 runs of OpenTuner, error bars indicate median, 20th, and 80th percentiles.
tions, and for Strassen, the exact same solution. For Sort and Tridiagonal Solver, OpenTuner beats the native PetaBricks autotuner, while for Poisson the PetaBricks autotuner arrives at a better solution, but has much higher variance.
The Poisson equation solver (Figure 9(a)) presents the most difficult search space. The search space for Poisson in PetaBricks is described in detail in [7]. It is a variable accuracy benchmark where the goal of the autotuner is to find a solution that provides8-digits of accuracy while min-imizing time. All points in Figure 9(a) satisfy the accu-racy target, so we do not display accuaccu-racy. OpenTuner uses theThresholdAccuracyMinimizeTimeobjective described in Section 3.4. The Poisson search space selects between direct solvers, iterative solvers, and multigrid solvers where the shape of the multigrid V-cycle/W-cycle is defined by the au-totuner. The optimal solution is a poly-algorthm composed of multigrid W-cycles. However, it is difficult to obtain 8-digits of accuracy with randomly generated multigrid cycle shapes, but is easy with a direct solver (which solves the problem exactly). This creates a large “plateau” which is dif-ficult for the autotuners to improve upon, and is shown near 0.16. The native PetaBricks autotuner is less affected by this
plateau because it constructs algorithms incrementally bot-tom up; however the use of these smaller input sizes causes larger variance as mistakes early on get amplified.
4.5 Stencil
In [20], the authors describe a generalized system for auto-tuning memory-bound stencil computations on modern mul-ticore machines and GPUs. By composing domain-specific transformations, the authors explore a large space of imple-mentations for each kernel; the original autotuning method-ology involves exhaustive search over thousands of imple-mentations for each kernel.
We obtained the raw execution data, courtesy of the au-thors, and use OpenTuner instead of exhaustive search on the data from a Nehalem-class 2.66 GHz Intel Xeon machine, running Linux 2.6. We compare against the optimal perfor-mance obtained by the original autotuning system through exhaustive search. The search space for this problem in-volves searching for parameters for the parallel decompo-sition, cache and thread blocking, and loop unrolling for each kernel; to limit the impact of control flow and cache misalignment, these parameters depend on one another (for
2e+07 4e+07 6e+07 8e+07 1e+08 1.2e+08 1.4e+08 1.6e+08 1.8e+08 2e+08 0 10 20 30 40 50 60
Execution Time (cycles)
Tests Optimal OpenTuner (a) Laplacian 1e+08 2e+08 3e+08 4e+08 5e+08 6e+08 0 10 20 30 40 50 60
Execution Time (cycles)
Tests
Optimal OpenTuner
(b) Divergence
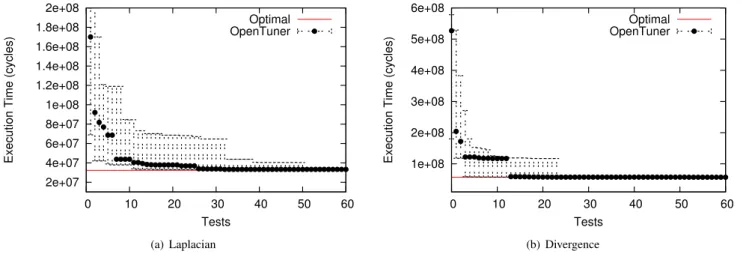
Figure 10. Stencil: Execution time (lower is better) as a function of tests. Aggregated performance of 30 runs of OpenTuner, error bars indicate median, 20th, and 80th percentiles.
example, the loop unrolling will be a small integer divi-sor of the thread blocking). We encode these parameters as
PowerOfTwoParameters but ensure that invalid combina-tions are discarded.
Figure 10 shows the results of using OpenTuner for the Laplacian and divergence kernel benchmarks, showing the median performance obtained over 30 trials as a function of the number of tests. OpenTuner is able to obtain peak performance on Laplacian after less than 35 tests of can-didate implementations and 25 implementations for diver-gence; thus, using OpenTuner, less than 2% of the search space needs to be explored to reach optimal performance. These results show that even for problems where exhaustive search is tractable (though it may take days), OpenTuner can drastically improve convergence to the optimal performance with little programmer effort.
4.6 Unitary Matrices
As a somewhat different example, we use OpenTuner in an example from physics, namely the quantum control prob-lem of synthesizing unitary matrices in SU(2) in optimal time, using a finite control set composed of rotations around two non-parallel axes. (Such rotations generate the complete spaceSU(2).)
Unlike other examples, which use OpenTuner as a tradi-tional autotuner to optimize a program, the Unitary example uses OpenTuner to perform a search over the problem space as a subroutine at runtime in a program. The problem has a fixed set of operators (or controls), represented as matrices, and the goal is to find a sequence of operators that, when multiplied together, produce a given target matrix. The ob-jective function is an accuracy value defined as a function of the distance of the product of the sequence to the goal (also called thetrace fidelity).
Figure 11 shows the performance of the Unitary example on both easy and hard instances of the problem. For both types of problem instance OpenTuner is able to meet the
0.99 0.992 0.994 0.996 0.998 1 0 10 20 30 40 50 60 Accuracy
Autotuning Time (seconds) OpenTuner (easy problem instances) OpenTuner (hard problem instances)
Figure 11. Unitary: Accuracy (higher is better) as a func-tion of autotuning time. Aggregated performance of 30 runs of OpenTuner, error bars indicate median, 20th, and 80th percentiles.
accuracy target within the first few seconds. This is example shows that OpenTuner can be used for more types of search problems than just program autotuning.
5. Conclusions
We have shown OpenTuner, a new framework for building domain-specific multi-objective program autotuners. Open-Tuner supports fully customizable configuration representa-tions and an extensible technique representation to allow for domain-specific techniques. OpenTuner introduces the con-cept of ensembles of search techniques in autotuning, which allow many search techniques to work together to find an optimal solution and provides a more robust search than a single technique alone.
While implementing these six autotuners in OpenTuner, the biggest lesson we learned reinforced a core message of this paper of the need for domain-specific representations
and domain-specific search techniques in autotuning. As an example, the initial version of the PetaBricks autotuner we implemented just used a point in high dimensional space as the configuration representation. This generic mapping of the search space did not work at all. It produced final config-urations an order of magnitude slower than the results pre-sented from our autotuner that uses selector parameter types. Similarly, Halide’s search space strongly motivates domain specific techniques that make large coordinated jumps, for example, swapping scheduling operators onxandyacross all functions in the program. We were able to add domain-specific representations and techniques to OpenTuner at a fraction of the time and effort of building a fully custom system for that project. OpenTuner was able to seamlessly integrate the techniques with its ensemble approach.
OpenTuner is free and open source and as the community adds more techniques and representations to this flexible framework, there will be less of a need to create a new representation or techniques for each project and we hope that the system will work out-of-the-box for most creators of autotuners. OpenTuner pushes the state of the art forward in program autotuning in a way that can easily be adopted by other projects. We hope that OpenTuner will be an enabling technology that will allow the expanded use of program autotuning both to more domains and by expanding the role of program autotuning in existing domains.
Acknowledgments
We would like to thank Clarice Aiello for contributing the Unitary benchmark program. We gratefully acknowledge Jonathan Ragan-Kelley and Connelly Barnes for helpful discussions and bug fixes related to autotuning the Halide project.
This work is partially supported by DOE award DE-SC0005288 and DOD DARPA award HR0011-10-9-0009. This research used resources of the National Energy Re-search Scientific Computing Center, which is supported by the Office of Science of the U.S. Department of Energy un-der Contract No. DE-AC02-05CH11231.
References
[1] F. Agakov, E. Bonilla, J. Cavazos, B. Franke, G. Fursin, M. F. P. O’boyle, J. Thomson, M. Toussaint, and C. K. I. Williams. Using machine learning to focus iterative optimiza-tion. InInternational Symposium on Code Generation and Optimization, pages 295–305, 2006.
[2] L. Almagor, K. D. Cooper, A. Grosul, T. J. Harvey, S. W. Reeves, D. Subramanian, L. Torczon, and T. Waterman. Find-ing effective compilation sequences. In LCTES’04, pages 231–239, 2004.
[3] J. Ansel, C. Chan, Y. L. Wong, M. Olszewski, Q. Zhao, A. Edelman, and S. Amarasinghe. PetaBricks: A language and compiler for algorithmic choice. In PLDI, Dublin, Ire-land, Jun 2009.
[4] J. Ansel, M. Pacula, S. Amarasinghe, and U.-M. O’Reilly. An efficient evolutionary algorithm for solving bottom up problems. InAnnual Conference on Genetic and Evolutionary Computation, Dublin, Ireland, July 2011.
[5] W. Baek and T. Chilimbi. Green: A framework for supporting energy-conscious programming using controlled approxima-tion. InPLDI, June 2010.
[6] V. Bhat, M. Parashar, . Hua Liu, M. Khandekar, N. Kan-dasamy, and S. Abdelwahed. Enabling self-managing appli-cations using model-based online control strategies. In Inter-national Conference on Autonomic Computing, Washington, DC, 2006.
[7] C. Chan, J. Ansel, Y. L. Wong, S. Amarasinghe, and A. Edel-man. Autotuning multigrid with PetaBricks. In Supercomput-ing, Portland, OR, Nov 2009.
[8] F. Chang and V. Karamcheti. A framework for automatic adaptation of tunable distributed applications. Cluster Com-puting, 4, March 2001. ISSN 1386-7857.
[9] M. Christen, O. Schenk, and H. Burkhart. Patus: A code generation and autotuning framework for parallel iterative
stencil computations on modern microarchitectures. In
IPDPS, pages 676–687. IEEE, 2011. ISBN
978-1-61284-372-8. URL http://dblp.uni-trier.de/db/conf/ipps/
ipdps2011.html#ChristenSB11.
[10] J. J. Dongarra, P. Luszczek, and A. Petitet. The LIN-PACK Benchmark: past, present and future.Concurrency and Computation: Practice and Experience, 15(9):803–820, 2003.
ISSN 1532-0634. . URLhttp://dx.doi.org/10.1002/
cpe.728.
[11] X. Fan. Optimize your code: Matrix multiplication. https:
//tinyurl.com/kuvzbp9, 2009.
[12] A. Fialho, L. Da Costa, M. Schoenauer, and M. Sebag. Ana-lyzing bandit-based adaptive operator selection mechanisms. Annals of Mathematics and Artificial Intelligence – Special Issue on Learning and Intelligent Optimization, 2010. . [13] A. Fialho, R. Ros, M. Schoenauer, and M. Sebag.
Comparison-based adaptive strategy selection with bandits in differential evolution. In R. S. et al., editor,PPSN’10: Proc. 11th International Conference on Parallel Problem Solving from Nature, volume 6238 ofLNCS, pages 194–203. Springer, September 2010. ISBN 978-3-642-15843-8. .
[14] M. Frigo and S. G. Johnson. The design and implementation of FFTW3.IEEE, 93(2), February 2005. Invited paper, special issue on “Program Generation, Optimization, and Platform Adaptation”.
[15] G. Fursin, C. Miranda, O. Temam, M. Namolaru, E. Yom-Tov, A. Zaks, B. Mendelson, E. Bonilla, J. Thomson, H. Leather, C. Williams, M. O’Boyle, P. Barnard, E. Ashton, E. Courtois, and F. Bodin. MILEPOST GCC: machine learning based research compiler. InProceedings of the GCC Developers’ Summit, Jul 2008.
[16] H. Hoffmann, S. Misailovic, S. Sidiroglou, A. Agarwal, and M. Rinard. Using code perforation to improve performance, reduce energy consumption, and respond to failures. Tech-nical Report MIT-CSAIL-TR-2209-042, Massachusetts Insti-tute of Technology, Sep 2009.
[17] H. Hoffmann, J. Eastep, M. D. Santambrogio, J. E. Miller, and A. Agarwal. Application heartbeats: a generic interface for specifying program performance and goals in autonomous computing environments. InICAC, New York, NY, 2010. [18] H. Hoffmann, S. Sidiroglou, M. Carbin, S. Misailovic,
A. Agarwal, and M. Rinard. Power-aware computing with dynamic knobs. InASPLOS, 2011.
[19] H. Jordan, P. Thoman, J. J. Durillo, S. Pellegrini, P. Gschwandtner, T. Fahringer, and H. Moritsch. A multi-objective auto-tuning framework for parallel codes. In Pro-ceedings of the International Conference on High Perfor-mance Computing, Networking, Storage and Analysis, SC ’12, pages 10:1–10:12, Los Alamitos, CA, USA, 2012. IEEE Com-puter Society Press. ISBN 978-1-4673-0804-5. URLhttp:
//dl.acm.org/citation.cfm?id=2388996.2389010.
[20] S. Kamil, C. Chan, L. Oliker, J. Shalf, and S. Williams. An auto-tuning framework for parallel multicore stencil compu-tations. InInternational Symposium on Parallel Distributed Processing (IPDPS), pages 1–12, 2010.
[21] S. A. Kamil. Productive High Performance Parallel Pro-gramming with Auto-tuned Domain-Specific Embedded Lan-guages. PhD thesis, EECS Department, University of Califor-nia, Berkeley, Jan 2013.
[22] G. Karsai, A. Ledeczi, J. Sztipanovits, G. Peceli, G. Simon, and T. Kovacshazy. An approach to self-adaptive software based on supervisory control. In International Workshop in Self-adaptive software, 2001.
[23] K. Nordkvist. Solving TSP with a genetic algorithm in C++.
https://tinyurl.com/lq3uqlh, 2012.
[24] M. Pacula, J. Ansel, S. Amarasinghe, and U.-M. O’Reilly. Hy-perparameter tuning in bandit-based adaptive operator selec-tion. InEuropean Conference on the Applications of Evolu-tionary Computation, Malaga, Spain, Apr 2012.
[25] E. Park, L.-N. Pouche, J. Cavazos, A. Cohen, and P. Sadayap-pan. Predictive modeling in a polyhedral optimization space. InIEEE/ACM International Symposium on Code Generation and Optimization, pages 119 –129, April 2011.
[26] S. Pixel. 3D Basic Lessons: Writing a simple raytracer.
https://tinyurl.com/lp8ncnw, 2012.
[27] M. P¨uschel, J. M. F. Moura, B. Singer, J. Xiong, J. R. Johnson, D. A. Padua, M. M. Veloso, and R. W. Johnson. Spiral: A generator for platform-adapted libraries of signal processing alogorithms.IJHPCA, 18(1), 2004.
[28] J. Ragan-Kelley, A. Adams, S. Paris, M. Levoy, S. Amaras-inghe, and F. Durand. Decoupling algorithms from schedules for easy optimization of image processing pipelines. ACM Trans. Graph., 31(4):32:1–32:12, July 2012. ISSN 0730-0301.
[29] J. Ragan-Kelley, C. Barnes, A. Adams, S. Paris, F. Durand, and S. Amarasinghe. Halide: a language and compiler for optimizing parallelism, locality, and recomputation in im-age processing pipelines. In Proceedings of the 34th ACM SIGPLAN conference on Programming language design and implementation, PLDI ’13, pages 519–530, New York, NY, USA, 2013. ACM. ISBN 978-1-4503-2014-6.
[30] C. Tapus, I.-H. Chung, and J. K. Hollingsworth. Active har-mony: Towards automated performance tuning. InIn Proceed-ings from the Conference on High Performance Networking and Computing, pages 1–11, 2003.
[31] Top500. Top 500 supercomputer sites.
http://www.top500.org/, 2010.
[32] R. Vuduc, J. W. Demmel, and K. A. Yelick. OSKI: A library of automatically tuned sparse matrix kernels. In Scientific Discovery through Advanced Computing Conference, Journal of Physics: Conference Series, San Francisco, CA, June 2005. [33] R. C. Whaley and J. J. Dongarra. Automatically tuned linear algebra software. InSupercomputing, Washington, DC, 1998. [34] S. Woo, M. Ohara, E. Torrie, J. Singh, and A. Gupta. The SPLASH-2 programs: characterization and methodological considerations. Inproceedings of 22nd Annual International Symposium on Computer Architecture News, pages 24–36, June 1995.