McMPI
Managed-code MPI library in Pure C#
Dr D Holmes, EPCC
Outline
•
Yet another MPI library?
•
Managed-code, C#, Windows
•
McMPI, design and implementation details
•
Object-orientation, design patterns,
communication performance results
•
Threads and the MPI Standard
Why Implement MPI Again?
•
Parallel program, distributed memory => MPI library
• Most (all?) MPI libraries written in C
•
MPI Standard provides C and FORTRAN bindings
• C++ can use the C functions
•
Other languages can follow the C++ model
• Use the C functions
•
Alternatively, MPI can be implemented in that language
• Removes inter-language function call overheads but … • May not be possible to achieve comparable performance
Why Did I Choose C#?
•
Experience and knowledge I gained from my career in
software development
•
My impression of the popularity of C# in commercial
software development
•
My desire to bridge the gap between high-performance
programming and high-productivity programming
•
One of the UK research councils offered me funding for a
C# Myths
•
C# only runs on Windows
• Not such a bad thing – 3 of the Top500 machines use Windows • Not actually true – Mono works on multiple operating systems
•
C# is a Microsoft language
• Not such a bad thing – resources, commitment, support, training • Not actually true – C# follows ECMA and ISO standards
•
C# is slow like Java
• Not such a bad thing – expressivity, readability, re-usability • Not actually true – no easy way to prove this conclusively
•
C# and its ilk are not things we need to care about
• Not such a bad thing – they will survive/thrive, or not, without us • Not actually true – popularity trumps utility
McMPI Design & Implementation
•
Desirable features of code
• Isolation of concerns -> easier to understand
• Human readability -> easier to maintain
• Compiler readability -> easier to get good performance
•
Object-orientation can help with isolation of concerns
• So can modularisation and judiciously reducing LOC per code file
•
Design patterns can help with human readability
• So can documentation and useful in-code comments
•
Choice of language & compiler can help with performance
• So can coding style and detailed examination of compiler output
Communication Layer
•
Abstract class factory design pattern
• Similar to plug-ins
• Enables addition of new functionality without re-compilation of the rest of the library
•
All communication modules:
• Implement the same Abstract Device Interface (ADI)
• Isolate the details of their implementation from other layers
• Provide the same semantics and capabilities • Reliable delivery
• Ordering of delivery
• Preservation of message boundaries
Protocol Layer
•
Bridge design pattern
• Enables addition of new functionality without re-compilation of the rest of the library
•
All protocol messages:
• Implement inherit from the same base class
• Isolate the details of their implementation from other layers
• Modify state of internal shared data structures independently
•
Shared data structures (message ‘queues’)
• Unexpected queue – message envelope at receiver before receive • Request queue – receive called before message envelope arrival • Matched queue – at receiver waiting for message data to arrive • Pending queue – message data waiting at sender
Interface Layer
•
Simple façade design pattern
• Translates MPI Standard-like syntax into protocol layer syntax
•
Will become adapter design pattern
• For example, when custom data-types are implemented
•
Current version of McMPI covers parts of MPI 1 only
• Initialisation and finalisation
• Administration functions, e.g. to get rank and size of communicator
• Point-to-point communication functions • ready, synchronous, standard (not buffered)
• blocking, non-blocking, persistent
• Previous version had collectives • Implemented on top of point-to-point
Performance Results
– Introduction 1
•
Shared-memory results – hardware details
• Number of Nodes: 1 Armari Magnetar server
• CPUs per Node: 2 Intel Xeon E5420
• Threads per CPU: 4 Quad-core, no hyper-threading
• Core Clock Speed: 2.5GHz Front-side bus 1333MHz
• Level 1 Cache: 4x2x32KB Data & instruction per core
• Level 2 Cache: 2x6MB One per pair of cores
• Memory per Node: 16GB DDR2 667MHz
• Network Hardware: 2xNIC Intel 82575EB Gigabit Ethernet
Performance Results
– Introduction 2
•
Distributed-memory results – hardware details
• Number of Nodes: 18 Dell PowerEdge 2900
• CPUs per Node: 2 Intel Xeon 5130 Fam 6 mod 15 step 6
• Threads per CPU: 2 Dual-core, no hyper-threading
• Core Clock Speed: 2.0GHz Front-side bus 1333MHz
• Level 1 Cache: 2x2x32KB Data & instruction per core
• Level 2 Cache: 1x4MB One per CPU
• Memory per Node: 4GB DDR2 533MHz
• Network Hardware: 2xNIC BCM5708C NetXtreme II GigE
Shared-memory – Latency
0 1 2 3 4 5 6 1 2 4 8 16 32 64 128 256 512 1,024 2,048 4,096 8,192 16,384 32,768 Late n cy ( µs )Message Size (bytes)
MPICH2 Shared Memory MS-MPI Shared Memory McMPI thread-to-thread
Shared-memory – Bandwidth
0 10,000 20,000 30,000 40,000 50,000 60,000 70,000 4,096 8,192 16,384 32,768 65,536 131,072 262,144 524,288 1,048,576 B an d wi d th (M b it/ s)Message Size (bytes)
McMPI thread-to-thread MPICH2 shared-memory MS-MPI shared-memory
Distributed-memory
– Latency
0 50 100 150 200 250 300 350 400 450 500 550 600 1 2 4 8 16 32 64 128 256 512 1,024 2,048 4,096 8,192 16,384 32,768 Late n cy ( µs )Message Size (bytes)
McMPI Eager MS-MPI
Distributed-memory
– Bandwidth
0 250 500 750 1,000 4,096 8,192 16,384 32,768 65,536 131,072 262,144 524,288 1,048,576 B an d wi d th (M b it/ s)Message Size (bytes)
McMPI Rendezvous McMPI Eager MS-MPI
Thread-as-rank – Threading Level
•
McMPI allows MPI_THREAD_AS_RANK as input for the
MPI_INIT_THREAD function
•
McMPI creates new threads during initialisation
• Not needed – MPI_INIT_THREAD must be called enough times
•
McMPI uses thread-local storage to store ‘rank’
• Not needed – each communicator handle can encode ‘rank’
•
Thread-to-thread message delivery is zero-copy
• Direct copy from user send buffer to user receive buffer
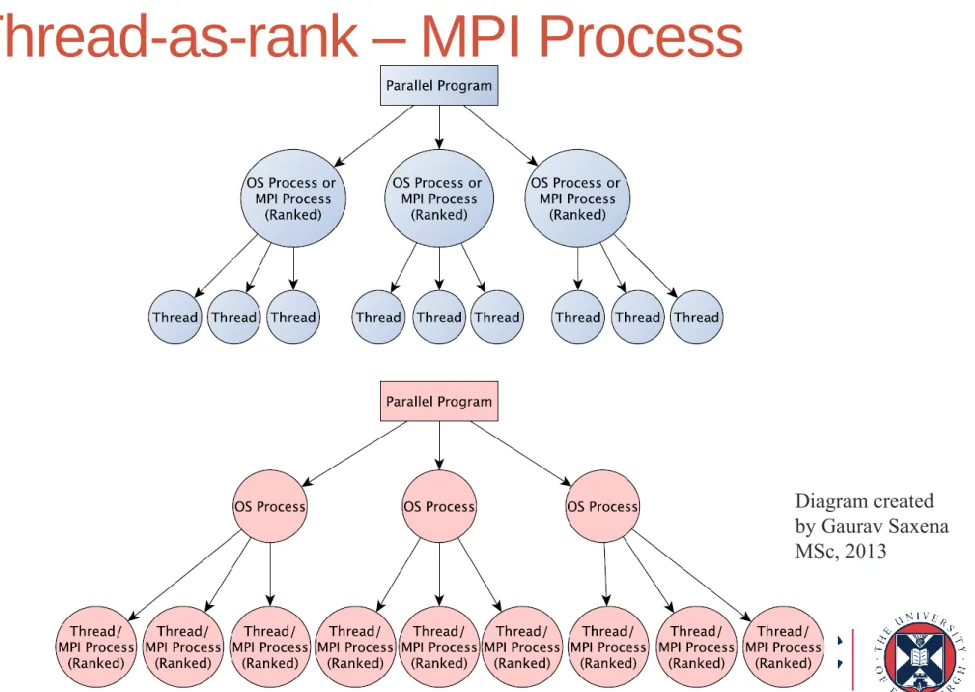
Thread-as-rank – MPI Process
Diagram created by Gaurav Saxena MSc, 2013
Thread-as-rank – MPI Standard
•
Is thread-as-rank compliant with the MPI Standard?
•
Does the MPI Standard allow/support thread-as-rank?
• Ambiguous/debatable at best
•
The MPI Standard assumes MPI process = OS process
• Call MPI_INIT or MPI_INIT_THREAD twice in one OS process • Erroneous by definition or results in two MPI processes?
•
MPI Standard “thread compliant” prohibits thread-as-rank
• To maintain a POSIX-process-like interface for MPI process • End-points proposal violates this principle in exactly the same way
Thread-as-rank – End-points
•
Similarities
• Multiple threads can communicate reliably without using tags
• Thread ‘rank’ can be stored in thread-local storage or handles
• Most common use-case likely requires MPI_THREAD_MULTIPLE
•
Differences
• Thread-as-rank part of initialisation and active until finalisation
• End-points created after initialisation and can be destroyed
• Thread-as-rank has all possible ranks in MPI_COMM_WORLD
• End-points only has some ranks in MPI_COMM_WORLD
• Thread-as-rank cannot create ranks but may need to merge ranks
Thread-as-rank
– MPI Forum Proposal?
•
Short answer: no
•
Long answer: not yet, it’s complicated
• More likely to be suggested amendments to end-points proposal
•
Thread-as-rank is a special case of end-points
• Standard MPI_COMM_WORLD replaced with an end-points communicator during MPI_INIT_THREAD
• Thread-safety implications are similar (possibly identical?)
• Advantages/opportunities similar
• Thread-to-thread delivery rather than process-to-process delivery