Department of Computer Science & Engineering
2010-10
Middleware Support for Real-Time Tasks on Distributed and Multicore
Platforms
Authors: Yuanfang Zhang
Abstract: While traditional real-time middleware such as Real-Time CORBA have shown promise as distributed software platforms for systems with time constraints, existing middleware systems lack (1) schedulability analysis and run-time enforcement mechanisms needed to give online real-time guarantees for aperiodic tasks, (2) flexible configuration mechanisms needed to manage end-to-end timing easily for a wide range of dfferent distributed real-time systems with both periodic and aperiodic tasks, and (3) support for scheduling soft real-time tasks on multicore platforms while guaranteeing their time constraints will be satisfied. To address the limitations of current generation real-time middleware, this dissertation makes three major contributions to the state of the art in real-time middleware: we have developed (1) the first instantiation of an integrated scheduling framework supporting both periodic and aperiodic tasks (on TAO, a widely used Real-Time CORBA middleware); (2) the first configurable component middleware services for admission control and load balancing of periodic and aperiodic tasks in distributed real-time systems (on CIAO, a Component-Integrated Real-Time middleware); and (3) MC-ORB, the first real-time object request broker (ORB) designed to exploit the features of multicore
platforms, with admission control and task allocation services that can provide schedulability guarantees for soft real-time tasks on multicore platforms.
Type of Report: PhD Dissertation
copyright by Yuanfang Zhang
ABSTRACT OF THE DISSERTATION
Middleware Support for Real-Time Tasks on Distributed and Multicore Platforms
by
Yuanfang Zhang
Doctor of Philosophy in Computer Science Washington University in St. Louis, 2008 Professor Christopher D. Gill, Chairperson
While traditional real-time middleware such as Real-Time CORBA have shown promise as distributed software platforms for systems with time constraints, existing middle-ware systems lack (1) schedulability analysis and run-time enforcement mechanisms needed to give online real-time guarantees for aperiodic tasks, (2) flexible configu-ration mechanisms needed to manage end-to-end timing easily for a wide range of different distributed real-time systems with both periodic and aperiodic tasks, and (3) support for scheduling soft real-time tasks on multicore platforms while guaran-teeing their time constraints will be satisfied. To address the limitations of current generation real-time middleware, this dissertation makes three major contributions to the state of the art in real-time middleware: we have developed (1) the first instantiation of an integrated scheduling framework supporting both periodic and aperiodic tasks (on TAO, a widely used Real-Time CORBA middleware); (2) the first configurable component middleware services for admission control and load bal-ancing of periodic and aperiodic tasks in distributed real-time systems (on CIAO, a
Component-Integrated Real-Time middleware); and (3) MC-ORB, the first real-time object request broker (ORB) designed to exploit the features of multicore platforms, with admission control and task allocation services that can provide schedulability guarantees for soft real-time tasks on multicore platforms.
Acknowledgments
I gratefully acknowledge the guidance of my two research advisors: Dr. Christopher D. Gill and Dr. Chenyang Lu. They both introduced me to the challenging world of real-time systems. Without their guidance and encouragement in my Ph.D. research, I can not successfully complete my dissertation. I wish to thank Donald K. Krecker and Gautam H. Thaker from Lockheed Martin Advanced Technology Laboratories for being great collaborators. Parts of my work are funded by DARPA program and are the result of my collaboration with them. I am indebted to Dr. Patrick Crowley, Dr. Ron K. Cytron, Dr. Shirley Dyke, Dr. Anir¨uddh¯a Gokh¯al´e, Dr. Christopher D. Gill and Dr. Chenyang Lu for serving on my dissertation committee, and for insightful discussions and helpful advice. I also take this chance to thank everyone in the department of computer science and engineering at Washington University for helping my everyday student life.
Yuanfang Zhang
Washington University in Saint Louis August 2008
Contents
Abstract . . . ii
Acknowledgments . . . iv
List of Tables . . . viii
List of Figures . . . ix
1 Introduction . . . 1
1.1 Motivation . . . 1
1.2 Design and Implementation Challenges . . . 3
1.3 Contributions . . . 5
1.3.1 Middleware Support for End-to-End Periodic and Aperiodic Tasks . . . 5
1.3.2 Configurable Component Middleware . . . 6
1.3.3 Middleware for Multicore Platforms . . . 6
1.4 Chapter Organization . . . 6
2 Background . . . 8
2.1 Task Model . . . 8
2.2 Shipboard Computing System Model . . . 9
2.3 Inter-processor Synchronization Protocol . . . 10
2.4 Schedulability Test . . . 12
2.4.1 Time-Demand Analysis . . . 12
2.4.2 Aperiodic Utilization Bound . . . 13
2.5 Real-Time ORBs . . . 14
2.6 Event Channel . . . 14
2.7 Component Middleware . . . 16
2.8 Middleware Services . . . 17
2.8.2 Admission Control . . . 18
2.9 Linux Kernel . . . 19
3 Middleware Support for End-to-End Periodic and Aperiodic Tasks 20 3.1 Integrated Scheduling Framework . . . 20
3.1.1 Scheduling and Dispatching Middleware Services . . . 21
3.1.2 Admission Control Service . . . 23
3.2 Time-Demand Analysis Approach . . . 26
3.2.1 Schedulability Analysis . . . 26
3.2.2 Release Guard Mechanism for End-to-End Periodic Tasks . . . 29
3.2.3 Deferrable Server Mechanism for Aperiodic Tasks . . . 32
3.3 Aperiodic Utilization Bound Approach . . . 36
3.4 Empirical Evaluation . . . 36
3.4.1 Deferrable Server Overhead . . . 37
3.4.2 Admission Control Overhead . . . 39
3.4.3 Acceptance Ratio Comparisons . . . 40
3.5 Conclusion . . . 43
4 Configurable Component Middleware . . . 45
4.1 Mapping DRS Characteristics to Middleware Strategies . . . 46
4.1.1 DRS Characteristics . . . 46
4.1.2 Admission Control (AC) Strategies . . . 47
4.1.3 Idle Resetting (IR) Strategies . . . 48
4.1.4 Load Balancing (LB) Strategies . . . 49
4.1.5 Combining AC, IR and LB Strategies . . . 50
4.2 Component Implementation . . . 50
4.3 Middleware Architecture . . . 54
4.4 Deployment and Configuration . . . 56
4.5 Experimental Evaluation . . . 59
4.5.1 Random Workloads . . . 60
4.5.2 Imbalanced Workloads . . . 61
4.5.3 Overheads of Service Components . . . 63
5 Real-Time Performance and Middleware on Multicore Linux
Plat-forms . . . 66
5.1 Experimental Study of Linux on Multicore Platforms . . . 66
5.1.1 Clock Differences between Cores . . . 67
5.1.2 Load Balancing Between Cores . . . 70
5.1.3 Thread Migration Between Cores . . . 73
5.2 Middleware Design . . . 77 5.3 Middleware Evaluation . . . 81 5.3.1 Overhead Measurement . . . 82 5.3.2 Real-Time Performance . . . 83 5.4 Conclusion . . . 86 6 Related Work . . . 87
6.1 Aperiodic Scheduling Approaches . . . 87
6.2 Component Middleware . . . 88
6.3 QoS-aware Middleware . . . 88
6.4 QoS-aware Component Middleware . . . 89
6.5 Linux Deficiencies . . . 90
6.6 Real-Time Operating System . . . 90
7 Conclusions . . . 92
List of Tables
3.1 Mean/Max Overhead of Deferrable Server Mechanisms (µs) . . . 38
3.2 Admission Control Step Delays (µs) . . . 40
4.1 Criteria and Middleware Strategies . . . 47
4.2 Service Overheads (µs) . . . 64
5.1 Round Trip Delay Measured on Two Cores . . . 68
5.2 Offset Between Cores . . . 70
5.3 Overhead of Load Balancing Checks during Each 5-minutes Run . . . 73
5.4 Thread Migration Overhead Comparison . . . 76
5.5 Overhead of MC-ORB Extensions . . . 83
5.6 Average Acceptance Ratio when Total Utilization is 1.6 and Balance Factor is Increased from 0.1 to 0.5 . . . 86
List of Figures
2.1 Federated Event Channel Structure . . . 16
3.1 Dispatching Framework for DS with RG . . . 22
3.2 Dispatching Framework for AUB . . . 23
3.3 Admission Control Mechanisms . . . 24
3.4 Release Guard Mechanism . . . 30
3.5 Scheduling with Greedy Protocol . . . 31
3.6 Scheduling with Release Guard . . . 31
3.7 Deferrable Server Operations . . . 34
3.8 Acceptance Ratio Comparison . . . 41
3.9 Effect of Criticality-aware Admission Control . . . 43
4.1 Middleware Services and Strategies . . . 51
4.2 Component Implementation . . . 52
4.3 Distributed Middleware Architecture . . . 55
4.4 Dynamic Configuration Process . . . 57
4.5 Configuration Interface . . . 58
4.6 Accepted Utilization Ratio . . . 61
4.7 LB Strategy Comparison . . . 62
4.8 Sources of Overhead/Delay . . . 63
5.1 Round Trip Delay . . . 68
5.2 Clock Offset Measurement . . . 69
5.3 Offset Between Cores . . . 69
5.4 Offset Between Cores After Reversing The Signs Of Values Collected On Core 0 . . . 70
5.5 Self Migration . . . 75
5.6 Running Thread Migration . . . 75
5.8 Single Manager Thread Architecture . . . 78
5.9 Misses when Total Utilization is 1.4 . . . 84
5.10 Misses when Total Utilization is 1.5 . . . 85
Chapter 1
Introduction
1.1
Motivation
Supporting the quality of service (QoS) demands of real-time applications requires middleware that is flexible, efficient and predictable. These days, addressing that chal-lenge has become increasingly complicated. Real-time applications (1) contain both periodic and aperiodic tasks, (2) require diverse services with configurable strategies, and (3) are more likely deployed on multicore platforms even today. Existing mid-dleware, which only considers the requirements of real-time periodic tasks on unicore processors, can not satisfy such needs. This dissertation addresses the gap between new properties of applications and platforms, and state-of-the-art middleware support for aperiodic task scheduling, configurable services and multicore platforms.
First, many distributed real-time systems must handle a mix of periodic and aperiodic tasks, including aperiodic tasks with end-to-end deadlines whose assurance is critical to the correct behavior of the system. For example, in an industrial plant monitoring system, an aperiodic alert event may be generated when a series of periodic sensor readings meets certain hazard detection criteria. This event must be processed on multiple processors within an end-to-end deadline. User inputs and sensor readings may trigger various other real-time aperiodic tasks. A key challenge in such sys-tems is providing on-line real-time guarantees to critical aperiodic tasks that arrive dynamically.
In such systems, schedulability analysis is essential for achieving predictable real-time properties. Aperiodic scheduling has been studied extensively in real-time schedul-ing theory. Earlier work on aperiodic servers has integrated schedulschedul-ing of periodic and aperiodic tasks [56, 50, 30, 52, 45, 46, 31, 13, 53], and new schedulability tests based on aperiodic utilization bounds [2] and a new admission control approach [5] were introduced recently. However, despite significant theoretical results on aperiodic scheduling, these results have not been applied to the standards-based middleware that is increasingly being used for developing distributed real-time applications. For example, current implementations of Real-Time CORBA (RT-CORBA) [39] do not provide any of the schedulability tests or run-time mechanisms required by aperiodic servers. As a result, those middleware implementations are currently unsuitable for applications with real-time aperiodic tasks. Admission control has been proposed as an effective approach to handle dynamic real-time tasks in distributed operating systems [54, 51]. However, those kernel-level mechanisms cannot be ported to dis-tributed middleware that lacks fine-grained resource control. Admission control also has been implemented in real-time middleware services [3], but they do not support aperiodic end-to-end tasks, which are essential to many distributed real-time appli-cations. It is thus essential to develop mechanisms in middleware that can provide predictability to critical aperiodic tasks.
Second, existing middleware systems lack the flexibility needed to support distributed real-time systems (DRS) with diverse application semantics and requirements. For example, load balancing is an effective mechanism for handling variable real-time workloads in a DRS. However, its suitability for DRS highly depends on their applica-tion semantics. Some digital control algorithms (e.g., proporapplica-tional-integral-derivative control) for physical systems are stateful and hence not amenable for frequent task re-allocation caused by load balancing, while others (e.g., proportional control) do not have such limitations. Similarly, job skipping (skipping the processing of cer-tain instances of a periodic task) is an admission control strategy for dealing with transient system overload. However, job skipping is not suitable for certain critical control applications in which missing one job may cause catastrophic consequences on the controlled system. In contrast, other applications ranging from video reception to telecommunications may be able to tolerate varying degrees of job skipping [29]. As a result, middleware should provide services with a variety of strategies that can be configured flexibly.
Third, as evidenced by recent products from major CPU vendors, multicore processors (which include several cores on a single chip) are poised to dominate the real-time and embedded systems development space. Dual-core chips are popular in today’s market, and many CPU vendors have released designs with more than two cores. Applications that process large numbers of transactions with soft real-time constraints are likely deployed on multicore platforms even today. However, standard operating systems such as Linux can not effectively schedule soft real-time workloads on such platforms. Moreover, the real-time performance of Linux primitives on multicore platforms has not been systematically evaluated. Benchmarking the real-time performance of Linux primitives is essential for developing predictable real-time applications on multicore platforms.
While traditional real-time middleware such as Real-Time CORBA [40] object re-quest brokers (ORBs) have shown promise for distributed systems with soft real-time constraints, existing middleware lacks support for guaranteeing such constraints on multicore platforms. For example, existing admission control (AC) and task allo-cation (TA) services do not consider thread CPU affinity and migration issues that arise with a multicore architecture. Processors are the minimum granularity for task assignment in existing middleware. However, on a multicore platform once a task is assigned to a processor, it could be executed on any core or even migrated among cores in that processor, which is not controlled by existing middleware. Any AC based on such an imprecise assignment necessarily loses its reliability. To support soft real-time tasks on multicore platforms, real-time middleware should therefore be able to provide AC and TA services not only among separate processors, but also among cores within each processor.
1.2
Design and Implementation Challenges
To fulfill these new requirements of real-time applications and to overcome the defi-ciencies of existing middleware in the previously mentioned areas, the following design and implementation challenges must be resolved:
(1) Providing on-line real-time guarantees to critical aperiodic tasks that arrive dy-namically:
although aperiodic scheduling theories exist, applying those theories to a real-world middleware environment still faces several important challenges as it requires (a) consideration of the specific requirements of the system model in applying that theory, and (b) highly efficient design and implementation of the run-time mechanisms on standard operating system platforms.
(2) Developing a flexible middleware infrastructure that can be easily configured to support the diverse requirements of different DRS:
specifically, middleware services such as load balancing and admission control must support a variety of strategies. Furthermore, the configuration of those strategies must be supported in a flexible yet principled way, so that system developers are able to explore alternative configurations but invalid configurations cannot be chosen by mistake. Providing middleware services with configurable strategies thus faces several important challenges: (a) services must be able to provide configurable strategies, and configuration tools must be added or extended to allow configuration of those strate-gies; (b) the specific criteria that distinguish which service strategies are preferable must be identified, and applications must be categorized according to those criteria; and (c) appropriate combinations of services’ strategies must be identified for each such application category, according to its characteristic criteria.
(3) Making full use of all cores while guaranteeing time constraints of real-time tasks on multicore platforms:
getting a real-time application running on a multicore processor is, in many cases, fairly easy. The real challenge is getting the application to make full use of all cores while guaranteeing its time constraints. Migration to multicore platforms creates sig-nificant challenges and complexity for middleware developers as it requires (a) the solid understanding of how Linux supports new multicore platforms and its corre-sponding deficiencies in doing so, and (b) how to overcome those deficiencies efficiently in middleware while guaranteeing time constraints of real-time tasks. For example, a real-time ORB should not only take advantage of multicore capabilities, but should also significantly reduce the complexity of multicore application development.
1.3
Contributions
To address these challenges in three areas, this dissertation makes three major con-tributions to the state-of-the-art of real-time middleware.
1. To provide on-line real-time guarantees to critical aperiodic tasks that arrive dynamically, Section 1.3.1 describes our integrated scheduling framework for supporting both periodic and aperiodic task scheduling.
2. To support diverse requirements of different DSR, Section 1.3.2 describes our configurable component middleware services supporting multiple admission con-trol and load balancing strategies for handling periodic and aperiodic tasks. 3. To make full use of all cores while guaranteeing time constraints of real-time
tasks on multicore platforms, Section 1.3.3 describes the first real-time ORB for multicore platforms, with AC and TA services that enforce real-time task constraints on multicore platforms.
1.3.1
Middleware Support for End-to-End Periodic and
Ape-riodic Tasks
To support end-to-end periodic and aperiodic tasks in dynamic distributed real-time systems, we have developed an integrated scheduling framework for end-to-end peri-odic and aperiperi-odic task scheduling in The ACE ORB (TAO) [25]. We have developed what are to our knowledge the first middleware-layer (1) mechanisms for deferrable servers and release guards, in TAO’s federated event service [23]; and (2) on-line ad-mission control service supporting both periodic and aperiodic end-to-end tasks. Our work bridges an important gap between aperiodic scheduling theory and state-of-the-art real-time middleware. Our empirical results on a Linux testbed demonstrate the success of our approach in supporting deferrable servers and on-line admission control for both periodic and aperiodic end-to-end tasks, efficiently in middleware.
1.3.2
Configurable Component Middleware
To support diverse DRS with periodic and aperiodic tasks, in this work we have (1) developed what is to our knowledge the first set of configurable component middle-ware services supporting multiple admission control and load balancing strategies for handling periodic and aperiodic tasks; (2) developed a novel component configuration pre-parser and interfaces to configure real-time admission control and load balancing services flexibly at system deployment time; (3) defined categories of distributed real-time applications according to specific characteristics, and related them to suitable combinations of strategies for our services; and (4) provided a case study that applies different configurable services to a domain with both periodic and aperiodic tasks, offers empirical evidence of the overheads involved and the trade-offs among service configurations, and demonstrates the effectiveness of our approach in that domain. Our work thus significantly enhances the applicability of real-time middleware as a flexible infrastructure for DRS.
1.3.3
Middleware for Multicore Platforms
To address the limitations of current generation real-time middleware in supporting soft real-time tasks on multicore platforms, we have: (1) provided an experimen-tal analysis of the real-time performance for vanilla Linux on multicore platforms, the results of which are valuable for both time middleware developers and real-time application developers alike; (2) developed what is to our knowledge the first real-time ORB for multicore platforms (MC-ORB), with AC and TA services that enforce real-time task constraints on multicore platforms; and (3) performed an em-pirical evaluation of MC-ORB, the results of which demonstrate the efficiency and effectiveness of our middleware on multicore platforms.
1.4
Chapter Organization
The rest of this dissertation is organized as follows. Chapter 2 surveys background information on the real-time systems, middleware and the Linux kernel. Chapter 3
presents a new integrated scheduling framework based on TAO’s federated event ser-vice [23] for a representative mix of end-to-end periodic and aperiodic tasks. Chapter 4 describes the first configurable component middleware services for admission control and load balancing for handling periodic and aperiodic tasks in a DRS. Chapter 5 first presents a new experimental analysis of real-time performance for vanilla Linux primitives on multicore platforms, and then describes MC-ORB, the first real-time ORB specifically intended for multicore platforms. Chapter 6 presents a survey of related work. Finally, Chapter 7 offers concluding remarks.
Chapter 2
Background
2.1
Task Model
We consider distributed real-time systems, potentially connected to or integrated with physical systems, generating periodic and aperiodic events that must be processed on distributed computing platforms within specified to end-to-end deadlines. Henceforth the processing of a sequence of related events is referred to as a task. A task Ti is
composed of a chain of subtasksTi,j(1≤j ≤ni) located on different processors. The
release of the first subtaskTi,1 of a taskTi is triggered by a periodic timer event or an
aperiodic event generated by the physical system. Upon completion, a subtask Ti,j
pushes another event which triggers the release of its successor subtask Ti,j+1. Each
release of a subtask is called one subjob, and each release of a task is a job composed of a chain of subjobs. Every job of a task must be completed within an end-to-end deadline that is its maximum allowable response time. The period of a periodic task is the interarrival time of consecutive subjobs of the first subtask of the periodic task. An aperiodic task does not have a period. The interarrival time between consecutive subjobs of its first subtask may vary widely and, in particular, can be arbitrary small. The worst-case execution time of every subtask, the end-to-end deadline of every task, and the period of every periodic task in the system are known.
2.2
Shipboard Computing System Model
Military shipboard computing [60] is moving toward a common computing and net-working infrastructure that hosts the mission execution, mission support and quality of life systems required for shipboard operations. The objective of the middleware architecture presented in Chapter 3 is to ensure that in the complex large-scale dis-tributed real-time computing environments envisioned, mission critical and safety critical tasks will meet their real-time performance requirements, even in the pres-ence of a myriad of other competing non-critical real-time tasks.
The physical system architecture consists of a number of display consoles that host primarily human/computer interface software, and are connected by a real-time net-work to a large number of inter-connected servers that host the software that delivers much of the system’s mission computing capability. The software running on this distributed infrastructure comprises a mix of periodic and aperiodic tasks, which are subject to a mix of critical and non-critical performance requirements.
On the servers, many tactical applications are implemented as end-to-end tasks each consisting of multiple subtasks that may be located on different processors. An ex-ample of such an application is sensor data processing, which consists of multiple subtasks. The majority of this data processing is periodic and non-critical. However, if a series of sensor reports meets certain threat criteria, an urgent self defense mode may be enabled. Further processing of the data becomes a critical aperiodic task with a deadline, i.e., to make an engagement decision. Should the decision be to engage, a critical periodic task is then launched, i.e., to manage countermeasures.
The shipboard computing system model is representative of many other complex dis-tributed real-time systems. In general, such a system is composed of a set of periodic and aperiodic tasks. A task is composed of a chain or a graph of subtasks which may be located on multiple processors. A subtask cannot be released until its predecessor has been completed. A task is subject to an end-to-end deadline which may be criti-cal or non-criticriti-cal. Since new periodic and aperiodic tasks may arrive dynamicriti-cally, it is impossible to provide realistic off-line guarantees of the schedulability of the sys-tem. Instead, an admission control strategy is needed to provide on-line guarantees to aperiodic tasks. Our middleware architecture described in Chapter 3 is designed
to support this general system model, though some of the specific policies supported by our current implementation are driven by the characteristics of the shipboard computing system model in particular.
2.3
Inter-processor Synchronization Protocol
For every end-to-end periodic task, its first subtask is released at the beginning of each period. When the subjobs in the subsequence sibling subtasks are released, they critically affect the schedulability, completion-time jitter, and average response time of end-to-end tasks. We call a protocol that governs when the schedulers on different processors release the subjobs of sibling subtasks aninter-processor
synchroniza-tion protocol. Such a synchronization protocol is correct if it (1) never releases
subjobs in any first subtask before the end-to-end release times of the subjobs and (2) never allows the violation of any precedence constraint among sibling subtasks. Except for these criteria, the scheduler of each processor has the freedom to advance or delay the release of the subjobs on the processor. There are two types of syn-chronization protocols: greedy and nongreedy. The release guard synsyn-chronization protocol [59] is one of a number of nongreedy synchronization protocols. Since only a greedy synchronization protocol and a release guard synchronization protocol are used in this dissertation, we introduce them here as background to discussions based on them.
Greedy Synchronization Protocol. The greedy synchronization protocol simply
releases a subjob as soon as the subjob’s immediate predecessor completes. Since every subjob is released and becomes ready for execution at the earliest possible instant, the greedy synchronization protocol yields the shortest average end-to-end response time of all tasks, compared with nongreedy protocols [58]. However, the interrelease intervals of consecutive subjobs in a later subtask (i.e., a subtask other than the first one) can be shorter than the period of the subtask. The bursty nature of the later subtasks thus may have undesirable effects on the schedulability of end-to-end tasks in a priority-driven system [59].
Release Guard Synchronization Protocol. This protocol [59] ensures that the time between two consecutive subjobs of the same periodic subtask is not less than the period. This guarantees that the release of periodic subtasks remains as periodic as possible. This behavior adds little overhead since the protocol only needs to know the period of a task and the last time the subtask was released. As Sun mentioned in his doctoral thesis [58], the following three rules are used to update release guard
g for subtask T.
1. g is initially equal to 0.
2. When a subjob of subtask T is released, update g to the current time plus the periodp of T.
3. Update g to the current time if the current time is a processor idle point on the processor whereT executes.
The release guard protocol releases subjob T at a time equal to g, or when the immediate predecessor of T completes, whichever is later.
Comparison of the Two Protocols. The greedy synchronization protocol is
un-suitable for hard real-time applications because tasks thus synchronized may have extremely large end-to-end response times when scheduled on a fixed-priority basis because of clumping effects [59]. Furthermore, with the current analysis techniques we can derive less than or equal end-to-end response time upper bounds under the release guard (RG) protocol than under the greedy protocol. Calculating the upper bound on the end-to-end response time (EERT) for each task is a kind of schedu-lability analysis approaches. If the upper bound on the EERT for each task is no greater than the task’s deadline, the system is schedulable. Thus lower upper bounds on the EERTs imply better schedulability of the system. This fact motivated us to use the RG protocol in real-time systems. However, this upper bound for the EERT may not occur in the real systems, because the upper bounds produced by the cur-rent analysis technique are not tight. It is therefore very possible that the system which is not schedulable under the schedulability test is in fact schedulable. For the RG and Greedy protocols, there is no precise conclusion which one is better in real
scheduling, but RG leads to a better schedulability analysis results with the current analysis techniques.
2.4
Schedulability Test
In real-time systems, meeting time constraints is crucial, as missing deadlines may cause disastrous failures. As a consequence, providing reliable certification evidence for those systems is essential. We call a test for validating that the given applica-tion can indeed meet all its hard deadlines when scheduled according to the chosen scheduling algorithm, a schedulability test. The schedulability test can be done ei-ther off-line before the system executes or on-line during when the system executes. The schedulability test is based on the knowledge of the release times and the exe-cution times of all tasks. The off-line schedulability test is useful when the system is highly deterministic, meaning that the release times and the execution times of all tasks are known, and either do not vary or vary only slightly. However, for systems in which tasks may arrive dynamically at run time, it is impossible to provide an off-line schedulability test. On-line admission controllers can perform the schedula-bility test at tasks’ arrival times in dynamic systems. Two popular schedulaschedula-bility test approaches for end-to-end real-time tasks are time-demand analysis and schedulable utilization analysis.
2.4.1
Time-Demand Analysis
Earlier work on aperiodic servers has integrated scheduling of periodic and aperiodic tasks [56, 50, 30, 52, 45, 46, 31, 13, 53]. On each processor, one (or multiple) aperi-odic servers executes all aperiaperi-odic subtasks on that processor. The use of aperiaperi-odic servers is intended to bound the influence of aperiodic tasks and make the time de-mand analysis for periodic tasks and aperiodic tasks feasible. In this dissertation, we choose deferrable server (DS) [56] instead of other more sophisticated servers be-cause it allows a simple and efficient implementation at the middleware layer. Here, we introduce the DS approach.
Deferrable Servers. In the DS approach, one (or sometimes multiple) server ex-ecutes all aperiodic subtasks on a processor. Each server has a budget and a period. The budget is replenished at the beginning of each period. The budget decreases whenever the server is executing an aperiodic subtask, and it is preserved till the end of the current period when the server is idle. A server can execute aperiodic subtasks as long as its budget has not been exhausted. The time demand analysis for independent periodic and aperiodic tasks on a single processor based on the DS is given in [33] and [8]. The analysis often must be adapted to accommodate different scheduling policies.
2.4.2
Aperiodic Utilization Bound
Aperiodic utilization bound (AUB) [2] is a kind of schedulable utilization analysis. It provides sufficient utilization conditions for accepting hard deadline periodic and aperiodic work while guaranteeing that all deadlines of those tasks will be met. Ac-cording to AUB analysis, a system achieves its highest schedulable synthetic utiliza-tion bound under the end-to-end deadline monotonic scheduling (EDMS) algorithm. Under EDMS, a subtask has a higher priority if it belongs to a task with a shorter end-to-end deadline. The subtasks of a given task are synchronized by a greedy syn-chronization protocol, because the AUB analysis does not require their inter-release times to be bounded. Note that AUB does not distinguish aperiodic from periodic tasks. All tasks are scheduled using the same scheduling algorithm. In the AUB anal-ysis, the set of currenttasksS(t) at any timet is defined as the set of tasks that have released but whose deadlines have not expired. Hence, S(t) ={Ti|Ai ≤t < Ai+Di},
where Ai is the release time of the first subtask of task Ti, and Di is the deadline of
task Ti. The synthetic utilization of processor j, Uj(t), is defined as the sum of
indi-vidual subtask utilizations on this processor, accrued over all current tasks. Under EDMS task Ti will meet its deadline if the following condition holds [2]:
ni X j=1 UVij(1−UVij/2) 1−UVij ≤1 (2.1)
whereVij is thejth processor that taskTi visits. All completed jobs are also counted
of the AUB analysis, a resetting rule is introduced in [2]. When a processor becomes idle, the contribution of all completed aperiodic subtasks to the processor’s synthetic utilization is removed.
2.5
Real-Time ORBs
The OMG’s Real-Time CORBA specification [40] provides standard policies and mechanisms that support quality-of-service requirements end-to-end, which enhances the effectiveness of distributed object computing middleware for performance-sensitive systems. ORBs send requests between clients and servers transparently. A real-time ORB end-system provides standard interfaces so that applications can specify their resource requirements. The policy framework defined by the CORBA Messaging spec-ification [37] lets applications configure ORB end-system resources, such as thread pri-orities, buffers for message queuing, transport-level connections, and network signal-ing, to control ORB behavior end-to-end. TAO [25] is a real-time CORBA ORB that is compliant with the Real-time CORBA specification [40]. Our integrated schedul-ing framework for end-to-end periodic and aperiodic task schedulschedul-ing in Chapter 3 is based on TAO. nORB [57] is a light weight real-time ORB for memory-constrained networked embedded systems. nORB is developed and maintained at Washington University and achieves comparable real-time performance to TAO, while reducing footprint significantly. We developed our MC-ORB implementation, and its AC and TA middleware services for multicore platforms, by extending nORB.
2.6
Event Channel
The CORBA [42] Event Service [23] implements the Mediator design pattern [18]. The nodes of the resulting distributed communication network are classified as suppliers and consumersaccording to their roles in using each Event Channel (EC). Suppliers register the types of events which they produce (supply), with an EC. Consumers subscribe to the types of events on which they rely. The Event Channel acts as an
intermediary between suppliers and consumers so that they do not need to know explicitly about each other.
The concept of an Event Service has been extended in the context of RT-CORBA to account for the quality-of-service (QoS) requirements of real-time systems [42]. The QoS parameters of suppliers and consumers may be specified to the EC so that it can distribute events according to those requirements. The TAO Event Channel [23] applies the RT features described in [42] to the CORBA Event Service [36]. The TAO EC adds guarantees for real-time event dispatching and scheduling, through the Kokyu Dispatching Framework [20]; centralized event filtering and correlation; and periodic processing support for the CORBA Event Service [23].
A Federated Event Channel [23] is used to coordinate the processors in which subtasks execute. Each processor has its own EC, and the ECs exchange events via a Gateway, as described in [23]. The Event Channels for a subtask’s supplier and consumer exchange events through a Gateway, which acts as a Consumer of the supplier’s events and a Supplier of the consumer’s events. The Gateway can reside in either processor, but for our implementation it is on the supplier side.
Each subtask is implemented as a supplier-consumer pair. The supplier publishes events which trigger the subtask execution in a single consumer. If the subtask is the first subtask in a task, then the supplier has an associated timeout handler registered with the EC to receive timeout events. When the timeout handler receives a timeout event, it triggers the supplier to publish an event to the consumer. If the subtask is not the first subtask, then when a consumer finishes executing its predecessor, the consumer notifies the supplier for this subtask, which behaves as if the supplier had been triggered by a timeout handler. Of course, the final subtask’s consumer has no supplier for the next subtask.
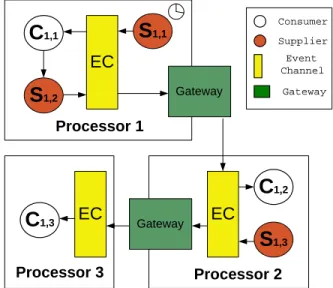
For example, consider a simple task chain which contains three subtasks. The struc-ture of timers, suppliers, and consumers in the processors P1,P2, and P3 is shown in
Figure 2.1. In processor P1, a supplier S1,1 with a timer (depicted as a clock) pushes
events (arrows) to a consumer C1,1, which then executes subtask T1,1 and pushes
another event to the processor P2 through another supplier S1,2. Processor P2’s
consumer executes the final subtask, T1,3. This sequence of events may happen more
than once, every time the timer determines that it is time for T1 to execute again.
EC Gateway EC Gateway Processor 1 Processor 2 Processor 3
C
1,1S
1,2S
1,1C
1,3C
1,2S
1,3 Consumer Supplier Event Channel Gateway ECFigure 2.1: Federated Event Channel Structure
2.7
Component Middleware
Component middleware platforms are an effective way of achieving customizable reuse of software artifacts. In these platforms,components are units of implementation and composition that collaborate with other components via ports. The ports isolate the components’ contexts from their actual implementations. Component middle-ware platforms provide execution environments and common services, and support additional tools to configure and deploy the components.
In Chapter 3, to support periodic and aperiodic task scheduling, we developed the first instantiation of a middleware admission control service [67] (on TAO, a widely used Real-Time CORBA middleware). However, this original admission control service only included a fixed set of strategies. As is shown in Section 4.1, a more diverse and configurable set of inter-operating services and strategies is needed to support DRS with different application semantics. Unfortunately, it is difficult to extend implementations that rely directly on distributed object middleware, such as our admission control service in Chapter 3. Specifically, in those middleware systems
changing the supported strategy requires explicit changes to the service code itself, which can be tedious and error-prone in practice.
The Component-Integrated ACE ORB (CIAO) [24] implements the Light Weight CORBA Component Model (CCM) specification [41] and is built atop the TAO [25] real-time CORBA object request broker (ORB). CIAO abstracts common real-time policies as installable and configurable units. However, CIAO does not provide direct support for aperiodic task scheduling, admission control or load balancing. To develop a flexible infrastructure for DRS, in Chapter 4 we develop new admission control and load balancing services, each with a set of alternative strategies on top of CIAO. Furthermore, we have extended CIAO to configure and manage both services. DAnCE [16] is a QoS-enabled component deployment and configuration engine that implements the Object Management Group (OMG)’s Light Weight CCM Deploy-ment and Configuration specification [41]. DAnCE parses component configura-tion/deployment descriptions and automatically configures and deploys ORBs, con-tainers, and server resources at system initialization time, to enforce end-to-end QoS requirements. However, DAnCE does not provide certain essential features needed to configure our admission control and load balancing services correctly, e.g., to dis-allow invalid combinations of our service strategies. We therefore provide a specific configuration engine that acts as a front-end to DAnCE, to configure our services for application developers who require configurable aperiodic scheduling support.
2.8
Middleware Services
2.8.1
Task Scheduling
Traditionally, there have been two main approaches for scheduling tasks on multipro-cessors: partitioning and global scheduling. In global scheduling, all eligible tasks are stored (at least abstractly) in a single priority-ordered queue. The global scheduler selects for execution the highest priority tasks from this queue. All tasks thus com-pete for the use of all processors. Unfortunately, using this approach with optimal
uniprocessor scheduling algorithms, such as the rate-monotonic (RM) and earliest-deadline-first (EDF) algorithms, may result in arbitrarily low processor utilization in multiprocessor systems. In partitioning, each task is assigned to a single processor, on which each of its jobs will execute, and processors are scheduled independently. The main advantage of partitioning approaches is that they reduce a multiprocessor scheduling problem to a set of uniprocessor ones. Unfortunately, partitioning has two negative consequences. First, finding an optimal assignment of tasks to processors is a bin-packing problem, which is NP-hard in the strong sense. Thus, tasks are usually partitioned using non-optimal heuristics. Second, task systems exist that are schedu-lable if and only if tasks arenot partitioned. Still, partitioning approaches are widely used by system designers, e.g., task allocation among multiprocessors. In addition to the above approaches, we consider a new intermediate approach in which each job is assigned to a single processor, while a task is allowed to migrate. In other words, inter-processor task migration is permitted but only at job boundaries.
2.8.2
Admission Control
On-line admission control also offers significant advantages to real-time applications. When a new task arrives at an application processor, the application processor can release the task only if the admission controller verifies that its execution on multi-ple application processors can meet its end-to-end deadline and will not affect the schedulability of all previous accepted tasks. The responsibility of the admission con-troller is to guarantee all admitted tasks can meet their deadlines, but it can not guarantee all critical tasks will be admitted if their workload exceeds the schedulable region. However, it may be acceptable to eject non-critical tasks in order to accept new critical tasks. There are two main alternative admission control (AC) architec-tures: central AC and distributed AC. A key advantage of the central AC architecture is that it does not require synchronization among distributed ACs. In contrast, in a distributed architecture the ACs on multiple processors may need to coordinate and synchronize with each other in order to make correct decisions, because admitting an end-to-end task may affect the schedulability of other tasks located on the multiple affected processors. A potential disadvantage of the centralized architecture is that the AC may become a communication bottleneck and thus affect scalability. Which
architecture is more suitable depends on the application characteristics and the actual system properties.
2.9
Linux Kernel
Kernel support for multicore processors was introduced in Linux 2.0, but it wasn’t until the 2.6 kernel that the power of multicore processors was fully realized. The pre-2.6 scheduler used a single runqueue for all cores in a multicore processor. This meant that a task could be scheduled on any core, which can be good for load balancing but could disrupt memory caches. The pre-2.6 scheduler also used a single runqueue lock, so that in a multicore processor even the selection of which task to execute locked out any other cores from manipulating the runqueues, resulting in idle cores awaiting release of the runqueue lock and accordingly decreasing efficiency.
The 2.6 kernel [1, 6] introduced a new O(1) scheduler that included better support for multicore platforms. Since the 2.6 kernel maintains a runqueue for each core, the number of running threads on each of the cores in the processor can be balanced. At regular intervals, the kernel tries to redistribute threads to maintain a balance in the number of running threads per core, across the core complex. In addition, with a runqueue per core, a thread generally shares affinity with a core and can better utilize the core’s hot cache.
The better support for multicore architectures in Linux 2.6 moves it closer to be-ing an efficient soft real-time operatbe-ing system on those platforms. However, Linux still can not fulfill important real-time requirements, such as guaranteeing system schedulability. Chapter 5 therefore focuses on characterizing the timing of Linux fea-tures on multicore platforms, and then on providing necessary AC and TA services in middleware for real-time systems.
Chapter 3
Middleware Support for
End-to-End Periodic and
Aperiodic Tasks
In this chapter, we first introduce a new integrated framework for scheduling end-to-end periodic and aperiodic tasks. Our framework can be configured to support two different aperiodic scheduling approaches: deferrable server and aperiodic utilization bound. Each of them requires different supporting mechanisms in the middleware. We evaluate the performance of our framework and characterize the different overheads introduced by two approaches.
3.1
Integrated Scheduling Framework
To support end-to-end aperiodic tasks, we have developed a new middleware ar-chitecture based on TAO’s Federated Event Service [23]. The key feature of our architecture is an integrated scheduling framework for a mix of critical/non-critical and aperiodic/periodic tasks. Our integrated scheduling framework is composed of two key components: (1)end-to-end middleware servicesfor scheduling and dispatch-ing both periodic and aperiodic tasks; and (2) an admission controller that provides on-line admission control and schedulability tests for tasks that arrive dynamically at run time.
Our integrated end-to-end scheduling framework can be configured to support either the aperiodic utilization bound (AUB) or the deferrable server (DS) approach. If the middleware is configured to support the AUB approach, the end-to-end schedul-ing service schedules all tasks usschedul-ing the end-to-end deadline monotonic schedulschedul-ing (EDMS) policy, and the admission control service uses the AUB analysis to make admission decisions. On the other hand, if the middleware is configured to support the DS approach, the end-to-end scheduling service runs the EDMS algorithm with the DS mechanisms, and the admission control service uses the corresponding DS analysis to make admission decisions.
3.1.1
Scheduling and Dispatching Middleware Services
To host TAO’s Federated Event Service, each processor has its own event channel (EC), and the ECs exchange remote events via Gateways, as described in [23]. Sub-tasks are implemented as event suppliers and consumers. Each supplier pushes events which trigger subtask execution in a consumer. Upon the completion of the subtask, the Gateway located on the supplier side pushes an event to the processor where the next subtask is located.
To provide integrated scheduling of both periodic and aperiodic tasks, careful design of middleware dispatching mechanisms is needed. The Kokyu dispatching frame-work [20] is used in our system to provide such real-time dispatching of events to functions that execute the corresponding subtask processing.
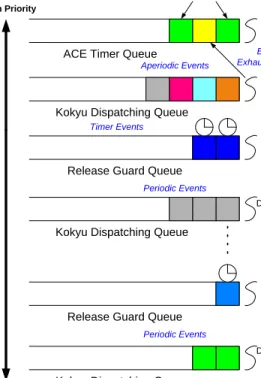
When the DS approach is used, Kokyu is configured to use the preemptive EDMS algorithm to schedule periodic tasks. As shown in Figure 3.1, each periodic event is assigned to a specific dispatching queue according to its end-to-end deadline, such as the two bottom queues in Figure 3.1. Each dispatching queue has a thread whose priority is determined by the end-to-end deadline of the events in its queue based on the EDMS policy. Each dispatching thread removes the event from the head of its queue and runs its subtask function until it completes or is preempted by a higher priority thread. To enable end-to-end response time analysis for the periodic tasks, we implemented release guards for the event channels [68] as an extension to the Kokyu dispatching framework. The implementation detail is discussed in Section 3.2.2. The
release guard mechanism is enabled only for periodic tasks. One release guard (RG) queue and a RG thread are added for each Kokyu dispatching queue (as shown in Figure 3.1) which help to implement release guard mechanism in middleware. A single server thread is used to dispatch aperiodic events on each processor in our approach, and runs at a higher priority than any of the periodic tas dispatching threads. The server thread collaborates with one budget manager thread to implement the DS mechanism on each processor, as we discuss in more detail in Section 3.2.3.
When the aperiodic utilization bound approach is used, Kokyu is configured to use the preemptive EDMS algorithm to schedule both periodic and aperiodic tasks. It uses similar dispatching mechanisms to the DS approach, but there is no server thread and the release guard mechanism is disabled because it is not needed for AUB. The comparable dispatching framework for AUB is shown in Figure 3.2.
ACE Timer Queue
Kokyu Dispatching Queue
Budget Manager Thread Server Thread Aperiodic Events Replenish Timers Budget Exhausted Timer Periodic Events
Kokyu Dispatching Queue
Dispatching Thread High Priority
Low Priority
Timer Events
Release Guard Queue
RG Thread
Release Guard Queue
RG Thread
Periodic Events
Kokyu Dispatching Queue
Dispatching Thread
Periodic Events
Kokyu Dispatching Queue
Periodic Events
Kokyu Dispatching Queue
Dispatching Thread Dispatching Thread High Priority Low Priority
Figure 3.2: Dispatching Framework for AUB
3.1.2
Admission Control Service
On-line admission control offers significant advantages to distributed real-time sys-tems by (1) providing on-line schedulability guarantees to tasks arriving dynamically and (2) (re)allocating resources based on task criticality1
. Our admission control ser-vice adopts a centralized architecture, which employs a central admission controller (AC) running on a separate processor from the application processors (APs). The AC and APs communicate through a Federated Event Service. When a new task arrives at an AP, the AP can release the task only if the AC verifies that its execution on multiple APs can meet its end-to-end deadline without violating the schedulability of the system. Applications register every task’s scheduling-related information, includ-ing its deadline, period (if it is periodic), and its subtasks’ locations and execution times, to the AC at system deployment time. In our current implementation, we assume no dependence between different end-to-end tasks. A key advantage of the centralized architecture is that it does not require synchronization among distributed admission controllers. In contrast, in a distributed architecture the ACs on multi-ple APs may need to coordinate and synchronize with each other in order to make correct decisions, because admitting an end-to-end task may affect the schedulability of other tasks located on multiple APs. A potential disadvantage of the centralized architecture is that the AC may become a communication bottleneck and affect scal-ability. However, this is not a concern in many distributed real-time systems, in which processors are connected by high-speed real-time networks. Furthermore, the computation times of both schedulability analyses are significantly lower than task execution times in typical distributed real-time applications. As our empirical results
1
Although the EDMS scheduling policy does not consider task criticality, our on-line admission control service can guarantee the preference of critical tasks over non-critical tasks.
in Section 3.4.2 show, the AC overheads are acceptable and are dominated by the communication delays.
Admission Control Process. Our integrated middleware architecture may be
configured to support either the AUB or DS approach. In the following, we describe the interactions between the AC and the APs assuming the middleware is configured to support the AUB approach. The admission control process with the DS approach is similar except that the admission controller uses a different schedulability analysis (as is described in Section 2.4).
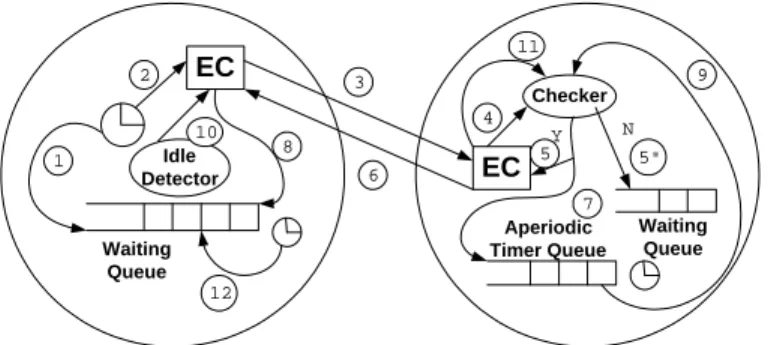
EC Checker Y Aperiodic Timer Queue Waiting Queue N 3 7 5 5" 6 9 4 11 Admission Controller (AC) EC 1 8 2 12 Idle Detector 10 Waiting Queue Application Processor (AP)
Figure 3.3: Admission Control Mechanisms
Figure 3.3 shows a detailed view of the interactions between the AC and APs, and of the mechanisms that support them. When a task arrives at its first AP, the AP does not release the task immediately. Instead, it holds the task in a waiting queue (step 1) and sends an “Accept?” event to the AC to notify it (step 2). The AP also sets a timer that will fire when the laxity of the task reaches zero. When the “Accept?” event is delivered to the AC by the Federated Event Channel (step 3), the AC performs schedulability analysis (step 4). If all admitted task can still meet their deadlines if the new task is admitted, the AC sends back a “Release” event to the AP (steps 5 and 6) and sets a timer to fire at the deadline of new admitted aperiodic task (step 7). Upon receiving the “Release” event, the AP dequeues the waiting task and releases it (step 8). If the system would be unschedulable if the new task was admitted, the AC holds its request in a waiting queue (step 5). All tasks in the waiting queue are ordered by their increasing laxity. When the number of active tasks in the system is decreased – at the admitted aperiodic task deadlines (step 9) or
when any processor becomes idle (steps 10 and 11) – the AC analyzes schedulability and may release waiting tasks with lower laxity if the system becomes schedulable. The AP rejects a task by removing it from the waiting queue when its laxity reaches zero (step 12).
Admission Control Strategy. Our middleware performs the admission test
when-ever an aperiodic task or a periodic task arrives, which is called AC per Task. However, it may incur significant overhead to apply the admission test to every job of a periodic task. To reduce admission overhead our middleware only performs ad-mission test the first time a periodic task arrives. Once a periodic task passes the admission test, all its jobs are allowed to be released immediately when they arrive. However, this optimization improves middleware efficiency at the cost of increasing the pessimism of the admission test, as the system effectively reserves a portion of the system resource for periodic tasks.
Criticality-awareness Policy. It is important to consider criticality in admission
control in many distributed real-time systems, which includes both critical and non-critical tasks. When the AC finds the system would be unschedulable if it accepted a new critical task, the admission controller may eject non-critical periodic tasks previously admitted into the system. In our current implementation, the middleware does not stop the current job of the non-critical periodic task to be ejected if it has already been released. This is because terminating a running job in a distributed middleware setting may incur significant overhead and risk of error. Instead, our AC employs a light-weight ejection policy. The AC sends an “Eject” event to the AP hosting the first subtask of the task to be ejected. When the ejected periodic task tries to release its next job, it is required to go through the admission control process again. There are many possible policies for selecting the tasks to be ejected from the system. Our AC currently randomly chooses the victims from all accepted non-critical periodic tasks. While our current admission control policy only considers two classes of tasks (critical vs. non-critical), it may also be extended to support more sophisticated optimization techniques to maximize total system utility (e.g., [3, 44]).
Delay Accounting. Three types of delays should be considered in the admission tests for both AUB and DS. The first type of delay is the round trip delay between an AP and the AC, which includes delays in both the middleware and the network. The second type of delay is the time a task stays in the waiting queue on the AC. Note that we do not consider the waiting time as part of the round trip delay, because it is caused by system overload instead of by the AC mechanism itself. Finally, the third type of delay is the event communication delay between subtasks located on different APs. Our admission test accounts for these delays by deducting them from the end-to-end deadline when assessing the schedulability of a task.
3.2
Time-Demand Analysis Approach
We choose deferrable server (DS) [56] instead of more sophisticated server techniques because it allows a simple and efficient implementation at the user level. The idea of DS is to incorporate aperiodic tasks in a periodic scheduling framework, then use the time-demand analysis to do the schedulability analysis for mixed task set. For end-to-end periodic tasks, release guard synchronization protocol is required to govern the inter-releasing time of subsequent subtasks. The end-to-end response time of a periodic task is thus the sum of the response times of all its subtasks. For end-to-end aperiodic tasks, the DS which is a special periodic task on each processor is required to serve aperiodic subtasks on that processor. With the help of the release guard and the DS, we can analysis the time demand for both periodic and aperiodic end-to-end tasks in the system.
3.2.1
Schedulability Analysis
In our DS implementation, a periodic task called the deferrable server is responsible for executing all aperiodic subtasks on the same processor.2
The server executes aperiodic subtasks in the order of their end-to-end deadlines in a non-preemptive fashion. The server on processorj has abudgetBs
j, and aperiodPjs. To fairly compare
2
In general multiple deferrable servers may be used on a processor. We chose to use one server per processor to simplify schedulability analysis.
with the alternative approach (aperiodic utilization bound), all periodic tasks and the server itself are scheduled by a preemptive end-to-end deadline monotonic scheduling (EDMS) policy. The subtasks of each aperiodic task are synchronized by a greedy synchronization protocol. The subtasks of each periodic task are synchronized by the release guard synchronization protocol, so that the inter-release times of periodic subtasks are bounded by their periods. A heuristic method [64] is used to select the budgets and periods of deferrable servers.
We model a distributed system withmaperiodic tasks andnperiodic tasks executing on s processors. The m aperiodic and n periodic tasks are both indexed in non-decreasing order of their end-to-end deadlines separately. Task Ti is composed of a
chain of ni subtasks Tij, (1 ≤ j ≤ ni), allocated to multiple processors. The worst
execution time for each subtask Tij is Cij. Each task must be completed within an
end-to-end deadlineDi that is its maximum allowable response time. We distinguish
aperiodic and periodic tasks with superscriptsa andp: Ta
i (1≤i≤m) is an aperiodic
task and Tip (1≤i≤n) is a periodic task. Each periodic task T p
i is released at each
instance of period Pi. Each aperiodic task Tia is released only once.
Schedulability Analysis for Periodic Tasks
We apply the time demand method to determine whether all periodic tasks re-main schedulable in the presence of deferrable servers according to [56, 33]. For a job of periodic subtask Tijp released at a critical instant t0, we add the amount
min{Pmi=1C
a
ij, Bjs(1+d Rpij−Bjs
Ps
j e)}of processor time demanded by the deferrable server
in the interval [t0, t0+Rpij]. Hence, the response timeRpij of subtask Tijp is given by:
Rpij =min{ m X i=1 Ca ij, B s j(1 +d Rpij −Bs j Ps j e)} + i X k=1 Ckjp dR p ij Pk e(Bjs ≤R p ij ≤Pi) (3.1) Pi k=1C p ijd Rpij
Pke represents the interference from all periodic subtasks with priority no
Since a non-greedy synchronization protocol is used to synchronize the release of periodic subtasks, the end-to-end response time of a periodic task Tip is the sum of the response times of all its subtasks Tijp on different processors Pni
j=1R p ij. If Pni j=1R p ij ≤D p
i, then periodic task T p
i is schedulable.
Schedulability Analysis for Aperiodic Tasks
We adapt the analysis proposed in [8] to the case when all aperiodic subtasks on processor Pj arrive simultaneously. The worst-case response time for the aperiodic
tasks occurs when they arrive at the time instant when the server’s budget in the current period has just been exhausted, so that the initial delay of aperiodic requests is given by Ps j −Bjs. Then, since kBjs =b Pi k=1C a kj Bs j cB s
j is the total budget consumed
by aperiodic subtasks whose deadlines are no longer than Di in k DS periods, the
residual execution to be done in the next DS period is Ri = Pik=1C
a
kj −kBjs.After
substituting the initial delay, the consumed DS periods and the residual execution into the formula for the finish time in [8], we derive equation (3.2):
Ra ij =b Pi k=1C a kj Bs j cPs j + (P s j −B s j) + ( i X k=1 Ckja − b Pi k=1C a kj Bs j cBjs) (3.2)
An aperiodic end-to-end task is schedulable if the sum of its response times Pni
j=1R
a ij
on all processors that it visits is less than the deadline Da i.
Note that (3.2) is pessimistic when Bs
j can divide
Pi k=1C
a
kj because the residual
execution during the last period is exactlyBs
j. Hence we modify (3.2) for this special
case as follows. If Bs
j can divide
Pi k=1C
a
kj, the response time of subtaskTija becomes:
Ra ij = ( Pi k=1C a kj Bs j −1)Ps j + (P s j −B s j) +B s j (3.3)
Blocking Time Due to Nonpreemption. Formulas (3.2) and (3.3) assume all
it is difficult to implement that feature in middleware without kernel-level support. Therefore, all aperiodic tasks are scheduled by a nonpreemptive scheduling policy in our implementation. Consequently, when we want to determine the schedulability of an aperiodic task, we must also consider the maximum blocking time due to non-preemptive scheduling. The maximum blocking time of a subtask Ta
ij, bij, is the
longest execution time among all aperiodic subtasks that have longer deadlines than
Ta
ij and are located on the same processor. The response times of subtaskTija in (3.2)
and (3.3) should be changed to (3.4) and (3.5) respectively, to account for blocking.
Ra ij =b Pi k=1C a kj +bij Bs j cPs j + (P s j −B s j) + ( i X k=1 Ckja +bij − b Pi k=1C a kj+bij Bs j cBjs) (3.4) and Ra ij = ( Pi k=1C a kj +bij Bs j −1)Ps j + (Pjs−Bjs) +Bjs (3.5)
3.2.2
Release Guard Mechanism for End-to-End Periodic Tasks
Release guard synchronization protocol is introduced in Section 2.3. In this section, we describe how to integrated the release guard synchronization protocol with TAO’s Federated Event Channel (EC). Note that the release guard (RG) is not applied to all events traversing the EC. Although all supplier trigger events are passed through the EC, they are not subjected to the RG algorithm. Only the periodic events triggered by the gateway are subjected to the RG when passing through the EC. The notification of a consumer to the supplier of the next subtask does not go through the EC, so it does not go through the RG either. Because we are using Federated ECs, this means that an event traveling from one processor to another will be forced through the EC twice: once when it is pushed to the gateway through the local EC, and once when the gateway pushes it to the remote Consumer through the remote EC. It would be more appropriate to only perform the RG on the remote EC, because a RG only needs to be performed once to reduce jitter, and there is less time for jitter to accumulate again before the event reaches its destination if RG is performed within the EC of the destination processor. We modify the Kokyu framework [20] to distinguish between
these two cases, so we can restrict RG to performing only when dispatching gateway pushed events.
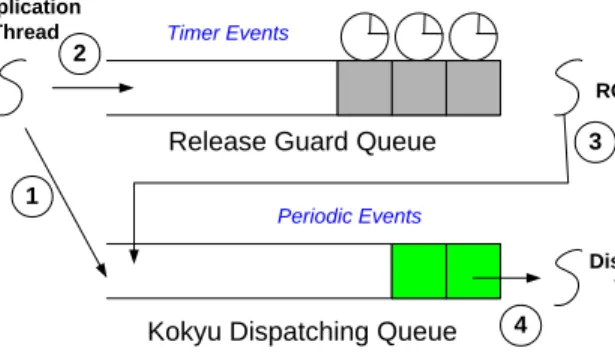
RG is implemented in the EC as a slight modification of the Kokyu Dispatching Framework [20]. Before a periodic event is enqueued in one of Kokyu’s dispatching queues, the RG checks that the event is being released at an appropriately periodic time. To avoid priority inversion, there is a RG Queue for each of the dispatching queues. Let ri be the latest release time of periodic event i (stored in a
mutex-protected map); then the target release time of ri+1 is ri +p, where p is the period
of the event. If the RG determines that the event is being released at an appropriate time, then it allows the event to be enqueued (step 1 in Figure 3.4); otherwise, the RG sets a timer to go off at ri +p and buffers the event in the RG Queue (step 2 in
Figure 3.4). When the timer goes off, a RG Thread with a higher priority removes the event from its queue and enqueues it in the Kokyu dispatching queue (step 3 in Figure 3.4). A Dispatch Thread with a lower priority always removes the event at the head of the queue and dispatches it (step 4 in Figure 3.4). Note that for the EC we have not implemented the RG behavior for the third rule (as is described in Section 2.3), since this third rule is not required for proper functioning of the RG (it is only an optimization for improving average response times).
Periodic Events
Kokyu Dispatching Queue
Dispatching Thread Timer Events
Release Guard Queue
RG Thread Application Thread 1 2 3 4
Figure 3.4: Release Guard Mechanism
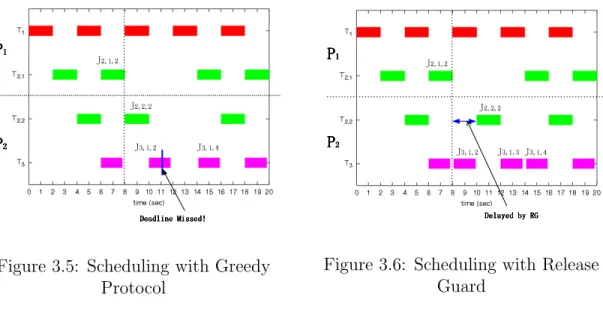
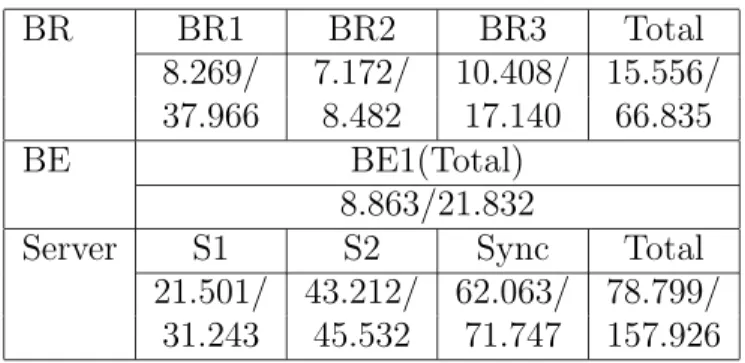
Effect of Release Guards. The following experiment shows how the RG works
in the middleware, to improve the predictability and schedulability of end-to-end tasks. The system in this example contains two processors and three periodic tasks. Each subtask Ti,k is represented by a tuple (ei,k, pi,k, ai,k), where ei,k is the worst case
Figure 3.5: Scheduling with Greedy Protocol
Figure 3.6: Scheduling with Release Guard
Ti, and ai,k is the phase of the subtask Ti,k (the default value of ai,k is 0). The phase
of Task Ti means the release time of the first subjob of its first subtask (ai,1). The
phase of any following subtask is zero. The relative end-to-end deadlines of the tasks are equal to their respective periods. Tasks T1 = (2,4,0) and T3 = (1.8,3,5.1) do
not have subtasks, and they execute on P1 and P2, respectively. Task T2 has two
subtasks: T2,1 = (2,6,0) executes on P1, and T2,2 = (2,6,0) executes on P2. The
subdeadline Di,k of each subtask Ti,k is equal to the end-to-end absolute deadline Di
of its parent task Ti. In this example, the nonpreemptive EDF scheduling policy is
used, and only the first two rules of the RG protocols in Sun’s thesis are enabled. Figure 3.5 shows the schedule of the tasks when they are synchronized according to the greedy protocol. In contrast, the schedule in Figure 3.6 is seen when the RG protocol is used.
As shown in these two schedules, the bi-directional arrow in Figure 3.6 denotes where the RG works. Job J2,2,2 was delayed by the RG in Figure 3.6. Otherwise Job J3,1,2
which had a higher priority but was released later could not begin to execute until the 10th second as shown in Figure 3.5. Finally Job J3,1,2 missed its deadline, and
the next job of that task was also cancelled because of the strict periodic restriction. Furthermore, The end-to-end response time of Task 2 was always 6 seconds in Fig-ure 3.6 while it can be 4 or 6 seconds when using the greedy synchronization protocol in Figure 3.5.
3.2.3
Deferrable Server Mechanism for Aperiodic Tasks
To support aperiodic tasks in middleware, we have integrated efficient support for deferrable servers within TAO’s Federated Event Service as is described in Section 2.6. In this section we present the design and implementation of the deferrable server mechanisms we have developed.
Design Challenges and Decisions. To simplify schedulability analysis and to
reduce implementation complexity and run-time overhead we chose to use one de-ferrable server per processor, though in general multiple dede-ferrable servers may be used on one processor to execute aperiodic tasks with different priorities. All aperi-odic subtasks on the same processor are executed by this server in non-preemptive EDMS order. It is challenging to implement bandwidth preserving servers efficiently on top of standard operating systems that do not support CPU reservations, because the budget and execution of the server must be managed in user space. We chose to implement our deferrable server mechanisms on ACE [26] and KURT-Linux, a Linux platform representative of standard operating systems that support fixed pri-ority scheduling. An importance advantage of our deferrable server mechanisms is that they are portable to COTS platforms used by many DRE applications.
Solution Approach. Our deferrable server mechanism is implemented by a pair
of threads on each processor: a server thread that processes aperiodic events and a bud