The Thirty-Third AAAI Conference on Artificial Intelligence (AAAI-19)
Knowledge Distillation with
Adversarial Samples Supporting Decision Boundary
Byeongho Heo,
1∗Minsik Lee,
2∗Sangdoo Yun,
3Jin Young Choi
1{bhheo, jychoi}@snu.ac.kr, [email protected], [email protected]
1Department of ECE, ASRI, Seoul National University, Korea
2Division of EE, Hanyang University, Korea 3Clova AI Research, NAVER Corp, Korea
Abstract
Many recent works on knowledge distillation have provided ways to transfer the knowledge of a trained network for im-proving the learning process of a new one, but finding a good technique for knowledge distillation is still an open problem. In this paper, we provide a new perspective based on a deci-sion boundary, which is one of the most important component of a classifier. The generalization performance of a classifier is closely related to the adequacy of its decision boundary, so a good classifier bears a good decision boundary. There-fore, transferring information closely related to the decision boundary can be a good attempt for knowledge distillation. To realize this goal, we utilize an adversarial attack to dis-cover samples supporting a decision boundary. Based on this idea, to transfer more accurate information about the deci-sion boundary, the proposed algorithm trains a student classi-fier based on the adversarial samples supporting the decision boundary. Experiments show that the proposed method in-deed improves knowledge distillation and achieves the state-of-the-arts performance.
Introduction
Knowledge distillation is a method to enhance the train-ing of a new network based on an existtrain-ing, already trained network. In a teacher-student framework, the existing net-work is considered as a teacher and the new netnet-work be-comes a student. Hinton, Vinyals, and Dean (2015), a pi-oneer in knowledge distillation, proposed a loss minimiz-ing the cross-entropy between the outputs of the student and the teacher, which referred to as the knowledge distillation loss (KD loss). Due to the KD loss, the student network is trained to be a better classifier than the network trained with-out knowledge distillation. Although the goals of the knowl-edge distillation are diverse, recent studies (Yim et al. 2017; Chen et al. 2017) focus on improving a small student net-work using a large netnet-work as a teacher using a large teacher network. These studies aim to create a small network with the speed of a small network and the performance of a large network. This paper, too, focuses on knowledge distillation in the respect of enhancing the performance of a small net-work using a large netnet-work.
∗
Authors contributed equally.
Copyright c2019, Association for the Advancement of Artificial Intelligence (www.aaai.org). All rights reserved.
Many of recent studies are focusing on manipulating the KD loss for various purposes. Romero et al. (2015) and Zagoruyko and Komodakis (2016) proposed new distilla-tion losses to transfer the hidden layer response of the net-work and used it with the KD loss. Chen et al. (2017) and Wang and Lan (2017) designed new distillation losses for other applications based on the KD loss. In contrast to these existing approaches that concentrate on how to manipulate various parts of a network in order to improve the effect of knowledge distillation, in this paper, we investigate informa-tive samples for an effecinforma-tive knowledge transfer. In general, samples near the decision boundary of a classifier have a larger impact on the performance than those far apart from it (Cortes and Vapnik 1995). Therefore, if we can generate samples close to the decision boundary, the knowledge of a teacher network would be transferred more effectively by utilizing those samples.
To obtain the informative samples close to the deci-sion boundary, we utilize an adversarial attack (Goodfellow, Shlens, and Szegedy 2015; Moosavi-Dezfooli, Fawzi, and Frossard 2016). An adversarial attack is a technique to tam-per with the result of a classifier by adding a small tam- pertur-bation to an input image. Although an adversarial attack is not particularly aimed at finding a decision boundary, they are closely related to each other (Cao and Gong 2017). An adversarial attack tries to find a small modification that can change the class of a sample, i.e., it tries to move the sam-ple beyond a nearby decision boundary. Inspired by this fact, we propose to perform knowledge distillation with the help of an adversarial attack. To get samples beneficial to knowl-edge distillation, we modify an attack scheme to search an adversarial sample supporting a decision boundary. The re-sulting sample is referred to as the boundary supporting sam-ple (BSS) in this paper. A new loss function using BSSs is suggested for knowledge distillation that transfers decision boundary to a student classifier. In order to verify whether the proposed method actually transfers the decision bound-aries, we also propose two similarity metrics that compares the decision boundaries of two classifiers and use these met-rics to examine the decision boundaries of a teacher and a student.
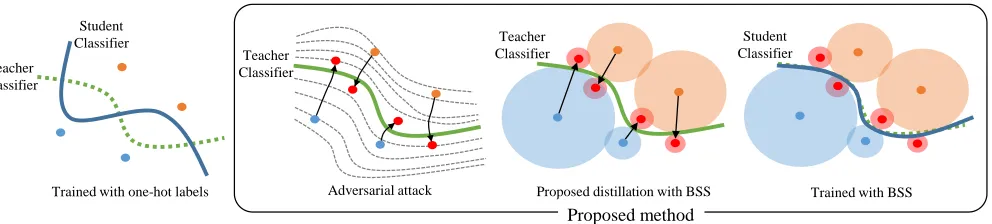
Adversarial attack Proposed distillation with BSS Trained with BSS Trained with one-hot labels
Proposed method
Student Classifier Teacher
Classifier
Teacher Classifier
Teacher Classifier
Student Classifier
Figure 1: The concept of knowledge distillation using samples close to the decision boundary. The dots in the figure represent the training sample and the circle around a dot represents the distance to the nearest decision boundary. The samples close to the decision boundary enable more accurate knowledge transfer.
Dean (2015) in an image classification problem. After this, we perform more experiments to examine the generalization performance of the proposed method, of which the result in-dicates that the proposed method has better generalization performance, and as a result, it can provide good results with less training samples. Finally, we analyze the proposed method with various experiments.
Related Works
Many studies have been conducted for knowledge distilla-tion since Hinton, Vinyals, and Dean (2015) proposed the first knowledge distillation method based on class probabil-ity. Romero et al. (2015) used the hidden layer response of a teacher network as a hint for a student network to improve knowledge distillation. Zagoruyko and Komodakis (2016) found the area of activated neurons in a teacher network and transferred the activated area to a student network. In the case of Yim et al. (2017), the channel response of a teacher network was transferred for knowledge distillation. Xu, Hsu, and Huang (2017) proposed a knowledge distilla-tion method based on the framework of generative adversar-ial network (Goodfellow et al. 2014). Some studies (Chen et al. 2017; Wang and Lan 2017; Chen, Wang, and Zhang 2017) extended knowledge distillation to computer vision applications. Knowledge distillation has been studied in var-ious directions, but most of the studies are focused on ma-nipulating the hidden layer response of a network or chang-ing the loss appropriately for the purpose. As far as we know, the proposed method is the first method to improve knowl-edge distillation by changing the samples used for training.
In the meantime, Szegedy et al. (2014) found that a clas-sifier based on a neural network could be fooled easily by a small noise. This work gave rise to a new research topic in neural networks called an adversarial attack, which is about finding a noise that can deceive a neural network. Moosavi-Dezfooli, Fawzi, and Frossard (2016) proposed a method to optimize a classifier based on a linear approxi-mation to find the closest adversarial example. Goodfellow, Shlens, and Szegedy (2015) proposed the adversarial train-ing which trains a classifier with adversarial samples in or-der to make the network robust to an adversarial attack. Cao
and Gong (2017) found that an adversarial sample was lo-cated near the decision boundary, and used this property to defense an adversarial attack. There have also been some works that connect an adversarial attack to another research topic. Papernot et al. (2016) found that a network trained by knowledge distillation is robust to adversarial attacks. The relationship between an adversarial attack and a deci-sion boundary was used to prevent an adversarial attack in Cao and Gong (2017). Knowledge distillation was also used to prevent an adversarial attacks in Papernot et al. (2016). Our study is closely related to these approaches, except that we take an opposite direction to them: We use adversarial at-tacks to find decision boundary to enhance knowledge distil-lation, which is a novel approach that has not been attempted yet.
Method
Adversarial attack for knowledge distillation
An adversarial attack is to change a sample in a class into an adversarial sample in another class for a given classifier. In our paper, the given sample for the adversarial attack is referred to as the base sample. In this section, we present an idea to utilize the adversarial attack in knowledge dis-tillation. The idea is about using adversarial samples near a decision boundary to transfer the knowledge related with the boundary. In the following sections, we first explain the defi-nition ofboundary supporting sample(BSS) and its benefits in knowledge distillation, and then we provide an iterative procedure to find BSSs.
its knowledge to the classifier we are to train, i.e., the stu-dent (Hinton, Vinyals, and Dean 2015; Romero et al. 2015; Zagoruyko and Komodakis 2016; Yim et al. 2017). If we train the student without knowledge distillation, then its per-formance may not as good as the teacher, which indicates that a decision boundary of the teacher is likely better than that of the student, as shown in Figure 1. On the other hand, knowledge distillation can enhance the performance of the student, which suggests that the decision boundary of the student is getting improved by knowledge distillation.
However, existing works do not explicitly address that the information about the decision boundary is transferred by knowledge distillation. In our paper, inspired by this motiva-tion, we utilize adversarial samples obtained from the train-ing samples to transfer the glimpse of a more accurate deci-sion boundary. A boundary supporting sample (BSS) is de-fined in this respect, it is an adversarial sample that lies near the decision boundary of a teacher classifier. Since BSSs are labeled samples near decision boundary as depicted in the second picture of Figure 1, they contain the information about the decision boundary. Hence, using BSSs in knowl-edge distillation can provide a more accurate transfer of de-cision boundary information. An BSS in our work is ob-tained by a gradient descent method based on a classifica-tion score funcclassifica-tions, and it contains informaclassifica-tion about both the distance and the path direction from the base sample to the decision boundary. In conclusion, BSSs could be bene-ficial to improve the decision boundary, and hence the gen-eralization performance, of a student classifier in knowledge distillation.
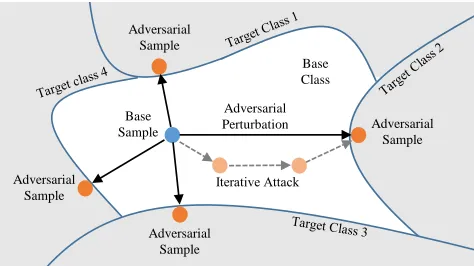
Iterative Scheme to find a BSS For a given sample, as shown in Figure 2, there exist many BSSs over all classes except the base class that contains the base sample. To find a BSS, we define a loss function based on classification scores produced by a classifier. Then, we search a BSS in the gra-dient direction of the loss function based on the method in (Moosavi-Dezfooli, Fawzi, and Frossard 2016) with a mod-ified update rule.
Given a sample vectorxin a base class, its correspond-ing adversarial samples are calculated based on an iterative procedure. First, a sample is initialized toxk
0=x, and then
it is iteratively updated to a target classk,k =,1,2,· · ·K. Here, the adversarial sample after the i-th iteration is de-noted byxki. Assume that the classifierf produces classifi-cation scores for all classes, where the class of a sample is determined by the class having the maximum score. Then, letfb(x)andfk(x)be the classification scores for the base
class and the target classk, respectively.
The goal of the adversarial attack is to decrease the score for the base class while increasing the score for the target class. To this end, the loss function for the attack to the target classkis defined by
Lk(x) =fb(x)−fk(x). (1)
This loss becomes zero at a point on the decision boundary, positive at a point within the base class, and negative at an adversarial point within the target class. To find an adversar-ial sample, we move the sample to the direction minimizing
Class A
Base Sample
Adversarial
Perturbation Adversarial Sample Adversarial
Sample
Adversarial Sample Adversarial
Sample
Base Class
Figure 2: Iterative scheme to find BSSs for a base sample
the loss by the iterative scheme in (2), until the loss becomes negative.
xki+1=xki −η Lk(xki) +
∇Lk(xki)
∇Lk(xki) 2
, (2)
where ∇Lk(xki) refers to the gradient of Lk(xki). The
step size of the Moosavi-Dezfooli et al. (Moosavi-Dezfooli, Fawzi, and Frossard 2016) is abnormally large due to a small gradient. To prevent this, we introduce a learning rate η which is used together with the loss function to control the step size. Note that the loss is large at the initial point and small near the decision boundary. In addition,derives the sample to cross the decision boundary as shown in the fol-lowing.
If we derive the first-order Taylor series approximation of
Lk(xki+1)atxki and substitute (2) to remove(xki+1−xki),
then we have
Lk(xki+1)≈Lk(xki) 1−η
∇Lk(xki) 2
−η∇Lk(xki)
2. (3)
Let us assume that we have chosen a small enoughηso that η∇Lk(xki)
2<1. Then, if the sample approaches a deci-sion boundary,Lk(xki)becomes small. In this case, without
the last term in (3) that exists due to the introduction ofin (2), the loss converges to zero but does not become negative which means the sample does not cross the decision bound-ary. By introducingin (2), the loss can become negative due to the second term in (3).
To lead the adversarial sample to a location near the de-cision boundary, we establish the stop conditions. The itera-tion stops if one of the following condiitera-tions occurs:
(a) Lk(xki+1)<0andLk(xki)>0,
(b) There exists any¯ksuch that
f¯k(xki+1)>max(fb(xki+1), fk(xki+1)), (c) i+ 1≥Imax,
whereImaxis a predefined number of maximum iterations.
decision boundary. If (a) is satisfied, then the attack is suc-cessful and the resulting sample is regarded as an BSS. On the other hand, conditions (b) and (c) are about failure cases and we discard the sample if one of them is satisfied. Condi-tion (b) means that the sample has stepped into a class that is not the target. This case occurs when there exists a non-target class between the base class and the non-target class. Con-dition (c) happens if the decision boundary is too far from the base sample.
Knowledge distillation using BSS
As mentioned in the previous section, BSSs of a teacher are beneficial for improving the generalization performance of a student classifier. In this section, we present a method to enhance knowledge distillation by transferring information on decision boundary more precisely using BSSs.
Loss function for BSS distillation From a training batch, our distillation scheme uses a set of base sample pairs
{(xn, cn)|n= 1,· · ·, N}wherecndenotes the class index
ofxn. A set of BSSs is denoted by{˚xkn|n= 1,· · · , N;k= 1,· · · , K}. Let the teacher and the student classifiers be de-noted byftandfsrespectively. For a samplexn, the class probability vectors are denoted by qt
n = σ(ft(xn)) and
qs
n = σ(fs(xn)), whereσ(·) refers to the softmax
func-tion. The desired class label forxis denoted by a one-hot label vector ytrue of which the element is either one for
the ground-truth class or zero for the other classes. The pro-posed loss function to train the student classifier combines three losses; a classification lossLcls, the knowledge
distil-lation lossLKD in (Hinton, Vinyals, and Dean 2015), and
an boundary supporting lossLBS:
L(n) =Lcls(n) +αLKD(n) +β K X
k
pknLBS(n, k). (4)
If we define the entropy function asJ(a,b) = −aTlogb, whereaandbare column vectors andlogis the element-wise logarithm, each loss is defined by
Lcls(n) =J(ytruen , σ(fs(xn))), (5)
LKD(n) =J(σ f
t(xn) T
, σ
f s(xn)
T
), (6)
LBS(n, k) =J(σ
ft(˚xkn) T
!
, σ fs(˚x k n) T
! ). (7)
Note thatT, the ‘temperature’, is a design parameter to prevent the loss from becoming too large (Hinton, Vinyals, and Dean 2015). pkn in the third term of (4) is the proba-bility of class k being selected as the target class, which is introduced to sample target classes stochastically during training. The definition ofpk
ncan be found in (10). The
lin-early decaying weights are used forαandβ, following the common practice in existing knowledge distillation (Romero et al. 2015; Zagoruyko and Komodakis 2016) techniques. Note that theLcls transfers direct answers (one-hot labels)
for the training samples, whereasLKDtransfers
probabilis-tic labels (Hinton, Vinyals, and Dean 2015). In contrast, the boundary supporting lossLBSis introduced to transfer the
information about the decision boundary directly.
Miscellaneous issues on using BSSs
Base sample selection for boundary supporting loss. To reduce the computation, we select N base samples out of Nbatch training samples according to a specific rule
ex-plained below and apply the boundary supporting loss only to the selected samples.
The base samples for generating the adversarial samples are selected from the training batchB = {(xn, cn)|n = 1,2,· · · , Nbatch}. A training sample pair (xn, cn) is
se-lected as the base sample for an adversarial attack if the class cn has the highest probability for both the teacher and the
student classifiers. That is, considering the probability vec-torsqtnandqsn, the base sample set is determined by
C={(xn,cn)|argmax c
(qtn,c)≡cn,
argmax c
(qsn,c)≡cn,(xn, cn)∈ B} (8)
whereqon,c(o=t, s) is thecth element ofqon. If the size of Cis smaller than a predefinedN, all the samples inCis used for the boundary supporting loss. If the size ofC is larger thanN, we selectN samples that have the highest distance betweenqt
nandqsn, i.e.,
dn=
qtn−qsn
2
2. (9)
Largednmeans that the probability vectorqtnof the teacher
and the probability vectorqsnof the student are largely
dif-ferent from each other at the base sample positionxn. Since
the reduction of dn matches the goal of knowledge
distil-lation, it is reasonable to choose a base sample with large dn.
Target class sampling. A BSS can target all classes ex-cept the base class. In the learning process, one of the classes is selected as the target class according to the following cri-teria and an BSS is generated by adversarial attacking to the selected target class. For the base samplexn, the
probabil-ity pk
n to sample the classk is defined based on the class
probabilityqtnof the teacher as follows:
pkn = 0,
ifk=cn
qt
n,k/(1−q t
n,cn), otherwise.
(10)
This is motivated from that it is important to precisely transfer the knowledge on the decision boundary between two classes that are hard to discriminate from each other.
qt
n,k6=cnhaving high value means that the classkis hard to discriminate from the base classcnfor the base samplexn.
Therefore, the target class is sampled with priority given to the class with a highqt
n,(·)forxn.
Metrics for similarity of decision boundaries
Table 1: Comparison on CIFAR-10 dataset
Student Original Hinton (2015)
FITNET (2015) +Hinton
AT (2016) +Hinton
FSP (2017)
+Hinton Proposed
FSP (2017) +Proposed
ResNet 8 86.02% 86.66% 86.73% 86.86% 87.07% 87.32% 87.52%
ResNet 14 89.11% 89.75% 89.72% 89.84% 89.92% 90.34% 90.13% ResNet 20 90.16% 90.77% 90.46% 90.81% 90.27% 91.23% 90.19%
Given thenth base samplexn, the perturbation vector to
attack the target classkfor the teacher classifier is obtained by
¯
xk,tn =˚xk,tn −xn. (11)
Likewise,x¯k,s
n denotes the perturbation vector for the
stu-dent classifier. Using a set of perturbation vector pairs
{(¯xk,tn ,x¯k,sn )|n= 1,2,· · ·, N;k = 1,· · ·, K}, the
simi-larity between the two decision boundaries is defined by two metrics: TheMagnitude Similarity (MagSim)in (12) and the
Angle similarity (AngSim)in (13):
M agSim= 1
N K N X
n=1 K X
k=1
min(kx¯k,t n k2,kx¯
k,s n k2) max(k¯xk,tn k2,kx¯k,sn k2)
(12)
AngSim= 1
N K N X
n=1 K X
k=1
<x¯k,t n ,x¯k,sn > kx¯k,tn k2× kx¯k,sn k2
. (13)
These two metrics have values in the range of [0,1] and higher values represent more similar decision boundaries.
Note thatMagSimrepresents the similarity with respect to the distance from the base sample to the decision boundary.
andAngSim depicts that with respect to the path direction
from the base sample to the boundary. Since the path is ob-tained by the gradient of the classification score function,
AngSim reflects the similarity with respect to the surface
shape of the class score function which affects the shape of decision boundary. Hence, we can say that the decision boundaries of two classifiers have become more similar if either of the metrics increases.
Experiments
Through experiments, we show that the proposed method is a way to enhance the performance of knowledge distilla-tion. In order to increase the reliability of the experiment, we performed the training 10 times for the same condition, and displayed the average of the results. Experiments were performed on the CIFAR-10 (Krizhevsky 2009), ImageNet 32×32 (Chrabaszcz, Loshchilov, and Hutter 2017) and Tiny-ImageNet datasets using a variety of residual networks (He et al. 2016).
Performance on image classification
The performance of the proposed method is verified by im-age classification on the CIFAR-10, Imim-ageNet 32×32, and TinyImageNet datasets. We trained the student classifiers in seven different ways. The first method is denoted as ‘origi-nal’, which uses only the classification loss for training. The second method is denoted as ‘Hinton’. Using the classifi-cation loss and the KD loss, ‘Hinton’ was implemented in
the same way as in Hinton et al. (Hinton, Vinyals, and Dean 2015). The next three methods are the latest knowledge dis-tillation methods implemented with the KD loss. The ‘FIT-NET’ (Romero et al. 2015) transfers the response of the in-termediate layer. The method denoted as ‘AT’ is transfer-ring the spatial attention of the teacher classifier to the stu-dent classifier (Zagoruyko and Komodakis 2016). The ‘FSP’ simplifies the layer response of the teacher into a channel-wise correlation matrix, which is used as the medium of knowledge transfer (Yim et al. 2017). Since the three meth-ods use the KD loss, they are labeled together with ‘+ Hin-ton’. The last two methods are; the proposed method which is denoted as ‘proposed’ and the proposed method imple-mented together with the ‘FSP’ method which is denoted as ‘FSP+proposed’. The performance of all classifiers was measured in terms of accuracy.
CIFAR-10. The CIFAR-10 is a classification dataset with 10 classes and 32x32 resolution, consisting of 50k training images and 10k test images. ResNet26 with 92.55% accu-racy is used as a teacher classifier. Meanwhile, ResNet8, ResNet14 and ResNet20 are used as student classifiers. All classifiers were trained over 80 epochs. ‘FITNET’ and ‘FSP’, which require two-stage learning scheme, were learned over 80 epochs after using 40 epochs for initializa-tion. Table 1 shows the result. The proposed method shows improved performance compared to Hinton. Also, the per-formance improvement of the proposed method is better than the existing state-of-the-arts. This confirms that the ad-ditional samples of the proposed method is useful for the knowledge distillation.
ImageNet 32×32. ImageNet 32×32 is a 32×
32-downsampled version of the ImageNet dataset (Rus-sakovsky et al. 2015) This dataset is a classification dataset with 1000 classes, consisting of 1,281k training images and 50k validation images. ResNet32 with 48.04% top-1 accuracy and 73.22% top-5 accuracy is used as a teacher classifier and ResNet8 is used as a student classifier. All classifiers were trained over 40 epochs. ‘FITNET’ and ‘FSP’ spent 4 epochs for initialization. Table 2 shows the result. The proposed method shows better performance than Hinton method and shows comparable performance with other state-of-the-arts. When combined with ‘FSP’, the proposed method shows better performance for top-5 accuracy.
Table 2: Comparison on ImageNet 32×32
Original Hinton (2015)
FITNET (2015) +Hinton
AT (2016) +Hinton
FSP (2017)
+Hinton Proposed
FSP (2017) +Proposed
Top1 acc 31.94% 32.43% 32.60% 32.61% 32.66% 32.69% 32.72%
Top5 acc 56.21% 56.99% 57.02% 57.14% 57.14% 57.17% 57.27%
Table 3: Comparison on TinyImageNet
Original Hinton (2015)
FITNET (2015) +Hinton
AT (2016) +Hinton
FSP (2017)
+Hinton Proposed
FSP (2017) +Proposed
Top1 acc 50.68% 52.35% 53.52% 52.74% 53.43% 52.99% 53.86%
Top5 acc 76.14% 77.67% 78.10% 77.82% 78.15% 78.38% 78.49%
and 78.71% top-5 accuracy. ResNet10 is selected for the stu-dent classifier. Classifiers were trained for 80 epochs. ‘FIT-NET’ and ‘FSP’ spent 10 epochs for initialization. The re-sult is described in Table 3. The proposed method shows better results than Hinton and ‘AT’. Although the proposed method shows lower top-1 accuracy than ‘FITNET’ and ‘FSP’ which require additional learning steps, it has higher top-5 accuracy than other state-of-the-arts. Also, the pro-posed method shows performance superior to those of other algorithms when combined with ‘FSP’.
Generalization of the classifier
The proposed method improves the generalization perfor-mance of a student classifier using the samples support-ing the decision boundary obtained from a teacher clas-sifier. Through an experiment, we verified that the gener-alization performance of the student classifier actually in-creases by the proposed method. In order to measure the generalization performance, the experiment was repeated while reducing the number of training samples from 100% to 20%. The CIFAR-10 dataset was used in this experiment, and ResNet26 trained on the whole dataset was used as the teacher classifier while ResNet14 was used as the student classifier. All methods were trained on the same training data for fairness.
Figure 4 shows the performance improvement from the original method for the size of the dataset. Here, we can see that the performance improvement of the other methods does not change much regardless of the size of data. On the other hand, the proposed method shows bigger performance im-provement for less training data. In a situation where it is difficult to achieve generalization due to insufficient data, the proposed method shows a large performance improve-ment, which means that the proposed method improves the generalization of the student classifier.
Analysis with similarity measure
We conducted an experiment to analyze the effect of the pro-posed method on the decision boundary of the network. The experiment is to measure the similarity metrics (MagSim,
AngSim) of trained student and teacher. Two similarity
met-rics reflect the similarity of decision boundaries. Thus, high
similarity metrics mean that decision boundary is transferred by knowledge distillation. Experiment was performed in a CIFAR-10 test set. ResNet 8 and Resnet 14 were used. ‘Original’, ‘Hinton’, and the proposed method were tested. The experimental results are shown in Figure 3. Compared with ‘original’, the Hinton method mainly increasesMagSim
andAngSimchanges are small. In other words, the Hinton
method transfers only the distance to the decision boundary and does not consider the direction. On the other hand, the proposed method increases bothMagSimandAngSimwhen compared to ’original’. Therefore, the proposed method transfers both distance and direction of decision boundary. The experiment show that the proposed method transfers the decision boundary more accurately and explains the reason for the high performance in the previous experiments.
Self-comparison
Table 4: Comparison of knowledge distillation using various types of adversarial samples.
Baseline Random noise L2 minimize FGSM (2015) DeepFool (2016) Proposed
Accuracy 86.66% 86.73% 86.94% 87.06% 86.95% 87.32%
ResNet8 – CIFAR 10 ResNet14 – CIFAR 10
0.52 0.6938 0.7038 0.5 0.55 0.6 0.65 0.7 0.75
Original Hinton Proposed
0.1839 0.1827 0.2021 0.175 0.185 0.195 0.205 0.215
Original Hinton Proposed
0.6577 0.7478 0.763 0.65 0.7 0.75 0.8
Original Hinton Proposed
0.2131 0.2234 0.2518 0.2 0.22 0.24 0.26
Original Hinton Proposed
MagSim AngSim MagSim AngSim
Figure 3: Evaluation of proposed method for decision boundary similarities (MagSim,AngSim). Percentage of used training samples in CIFAR-10
A ccu racy i m p ro v em en t 0.0% 0.5% 1.0% 1.5% 2.0% 2.5% 3.0%
100% 80% 60% 40% 20% Hinton Proposed 0.00% 0.50% 1.00% 1.50% 2.00% 2.50% 3.00%
100% 80% 60% 40% 20%
Hinton [12] FITNET [16]
AT [22] FSP [21]
Proposed A ccu racy i m p ro v em en t
Percentage of used training samples in CIFAR-10
0.00% 0.50% 1.00% 1.50% 2.00% 2.50% 3.00%
100% 80% 60% 40% 20%
Hinton [12] FITNET [16] AT [22] FSP [21] Proposed A ccu rac y i m p ro v em en t
Percentage of used training samples in CIFAR-10
A ccu racy i m p ro v em en t
Percentage of used training samples in CIFAR-10
0.00% 0.50% 1.00% 1.50% 2.00% 2.50% 3.00%
100% 80% 60% 40% 20%
Hinton FITNET
AT FSP
Proposed
Figure 4: Generalization of the classifier. The smaller the number of training samples are, the larger improvement the proposed method shows.
improvement. The gradient-based methods except the pro-posed method show similar performance improvement. On the other hand, the proposed method using BSS shows the greatest improvement, showing that a BSS is more suitable for knowledge distillation.
Experiment on miscellaneous issues is presented in Ta-ble 5. ’Proposed’ shows the performance of the proposed method using base sample selection and target class sam-pling. ’All selection’ shows performance when all samples are used as base samples, and ’Random selection’ shows performance when base samples are randomly selected with-out the proposed scheme. Two results show that the pro-posed base sample selection not only reduces computation but also contributes to performance. The performance when the target class is selected randomly without the proposed sampling is shown in ’Random target class’. The result im-plies that the proposed sampling according to the class prob-ability is reasonable and effective method.
Implementation details
All the experiments were performed using residual net-works (He et al. 2016). The channel sizes of ResNet were set to 16, 32, and 64 for CIFAR-10, and 32, 64, and 128 for ImageNet 32×32. For TinyImageNet, ResNet with four block was used with channel size of 16, 32, 64, and 128.
Table 5: Self-comparison on base sample selection and tar-get class selection.
Proposed All sample selection
Random selection
Random
target class Original
87.32% 87.18% 87.10% 87.08% 86.02%
We used random crop and random horizontal flip for data augmentation and normalized an input image based on the mean and the variance of the dataset. The temperatures of the KD loss and the adversarial loss were fixed to 3 in all experiments. The parameterαin (4) was initialized to 4 and linearly decreased to 1 at the end of training. Theβ in (4) was set to 2 initially and linearly decreased to 0 at the 75% of the whole training procedure, based on our empirical ob-servations: Whenβ was not zero at the final training stage, the performance was degraded. The learning process was performed with 256 batch size, with a learning rate which started at 0.1 and decreased to 0.01 at half of the maximum epoch and to 0.001 in 3/4 of the maximum epoch. The mo-mentum used in the study was 0.9 and the weight decay was 0.0001.η = 0.3was used for the adversarial attack in the proposed method and the maximum number of iteration was set to 10 for knowledge distillation. For the boundary sup-porting loss,Nadv= 64was selected among 256 batch
sam-ples.
Conclusion
in terms of sample manipulation is a new direction that has not been attempted in the past studies. It is also a new ap-proach to utilize an adversarial attack to find and transfer the information about the decision boundary. Therefore, this work can be useful for future research on knowledge distil-lation and on the application of an adversarial attack.
Acknowledgement
This work was supported by Next-Generation ICD Program through NRF funded by Ministry of S&ICT [2017M3C4A7077582] and ICT R&D program of MSIP/IITP [No.B0101-15-0552, Predictive Visual In-telligence Technology].
References
Bishop, C. M. 2006. Pattern recognition and Machine
Learning. Springer.
Cao, X., and Gong, N. Z. 2017. Mitigating evasion attacks to deep neural networks via region-based classification. CoRR
abs/1709.05583.
Chen, G.; Choi, W.; Yu, X.; Han, T.; and Chandraker, M. 2017. Learning efficient object detection models with knowledge distillation. In Neural Information Processing
Systems (NIPS).
Chen, Y.; Wang, N.; and Zhang, Z. 2017. Darkrank: Ac-celerating deep metric learning via cross sample similarities transfer.CoRRabs/1707.01220.
Chrabaszcz, P.; Loshchilov, I.; and Hutter, F. 2017. A down-sampled variant of imagenet as an alternative to the CIFAR datasets.CoRRabs/1707.08819.
Cortes, C., and Vapnik, V. 1995. Support-vector networks.
Machine Learning20(3):273–297.
Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; and Bengio, Y. 2014. Generative adversarial nets. InNeural Information
Processing Systems (NIPS). 2672–2680.
Goodfellow, I.; Shlens, J.; and Szegedy, C. 2015. Explain-ing and harnessExplain-ing adversarial examples. InInternational
Conference on Learning Representations (ICLR).
He, K.; Zhang, X.; Ren, S.; and Sun, J. 2016. Deep resid-ual learning for image recognition. InIEEE Conference on
Computer Vision and Pattern Recognition (CVPR).
Hinton, G.; Vinyals, O.; and Dean, J. 2015. Distilling the knowledge in a neural network. InNIPS Deep Learning and
Representation Learning Workshop.
Krizhevsky, A. 2009. Learning multiple layers of features from tiny images. Technical report.
Moosavi-Dezfooli, S.; Fawzi, A.; and Frossard, P. 2016. Deepfool: A simple and accurate method to fool deep neu-ral networks. InIEEE Conference on Computer Vision and
Pattern Recognition (CVPR).
Papernot, N.; McDaniel, P.; Wu, X.; Jha, S.; and Swami, A. 2016. Distillation as a defense to adversarial perturbations against deep neural networks. InIEEE Symposium on
Secu-rity and Privacy (SP), 582–597.
Romero, A.; Ballas, N.; Kahou, S. E.; Chassang, A.; Gatta, C.; and Bengio, Y. 2015. Fitnets: Hints for thin deep nets. Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; Berg, A. C.; and Fei-Fei, L. 2015. ImageNet Large Scale Vi-sual Recognition Challenge. International Journal of
Com-puter Vision (IJCV)115(3):211–252.
Szegedy, C.; Zaremba, W.; Sutskever, I.; Bruna, J.; Erhan, D.; Goodfellow, I. J.; and Fergus, R. 2014. Intriguing prop-erties of neural networks. InInternational Conference on
Learning Representations (ICLR).
Wang, C., and Lan, X. 2017. Model distillation with knowl-edge transfer in face classification, alignment and verifica-tion. CoRRabs/1709.02929.
Xu, Z.; Hsu, Y.; and Huang, J. 2017. Learning loss for knowledge distillation with conditional adversarial net-works. CoRRabs/1709.00513.
Yim, J.; Joo, D.; Bae, J.; and Kim, J. 2017. A gift from knowledge distillation: Fast optimization, network mini-mization and transfer learning. InIEEE Conference on
Com-puter Vision and Pattern Recognition (CVPR).
Zagoruyko, S., and Komodakis, N. 2016. Paying more attention to attention: Improving the performance of con-volutional neural networks via attention transfer. CoRR