An Efficient Analysis of Web Server Log Files for
Session Identification using Hadoop Mapreduce
Savitha K1 and Vijaya MS2
1 MPhil Research Scholar, Department of Computer Science, PSGR Krishnammal College for Women,
Coimbatore, India. Email: [email protected]
2
Associate Professor, GR Govindarajulu School of Applied Computer Technology, Coimbatore, India. Email: [email protected]
Abstract— As the growth of data increases over years, storage and analysis becomes incredible, this in turn increases the processing time and cost efficiency. Though various techniques and algorithms are used in distributed computing the problem remains still idle. To overcome this issue Hadoop Mapreduce is used, to process large number of files in a parallel manner. The use of World Wide Web emits data in larger quantity as users are more interested in performing their day to day activities through online. Users interaction in a website is analyzed through web server log files, a computer generated data in semi structured format. This paper presents an analysis of web server log files using Hadoop Mapreduce to preprocess the log files and to explore the session identification and network anomalies. The experimental results reveal the time efficiency and processing speed when compared to the existing one.
Index Terms— Analytics, Hadoop, Log mining, Parallel processing, Session identification. I.INTRODUCTION
A World Wide Web (WWW) is a system of interlinked hypertext documents accessed through the Internet. WWW is a combination of text documents, videos, images scattered all around. The use of internet access increases drastically, making human more comfort. Also, the communication gap between users decreases by sharing the knowledge, information, business dealings and each other’s interest. According to a current survey 90% of data in the world is generated within last two years. Usage of a specific website or social media by the users mostly tends to increase the data.
The digital data generated by the web servers are access log files which contain all of the requests made to the server. Most of the data are semi structured format by which querying through relational database is not possible. Data Mining can process Weblog records to find sequential patterns, association patterns, and current trends in web access using Web usage mining. Analyzing and exploring of such records is used in Marketing campaign analysis, e-commerce sites.
Web Usage Mining has the ability to predict user behaviour by interacting with the web or with web site to improve the quality of the service. Users activity in a website is registered as log files. A social or a commercial site holds Gigabytes or Terabytes of log data generated on each day. Analysis of such log files to predict user behaviour or to detect anomalies requires external drive for storage and hours of computing too.
© Elsevier, 2014
This research work associates the existing techniques of data preprocessing technique in order to clean the data that contains robots.txt, missing values which are irrelevant for analysis. Session identification algorithm tracks all the pages accessed by the IP address which is a unique identity, on web server log files. Apache Hadoop Mapreduce is used to perform this work in pseudo distributed mode that examines NASA website log files of more than 500MB stored in HDFS. It effectively identifies the session utilized by the web surfer to recognize the unique user, pages accessed by the users along with extraction of visitors at a specific time. The results of the proposed work are compared with the existing java environment to reveal better time efficiency, storage and processing speed.
II.RELATED WORK
Hadoop an open source distributed Apache software framework is used for analysis and transformation of large datasets using Mapreduce paradigm [2]. It process large amounts of structured and semi structured data in parallel across cluster of machines in a reliable and fault tolerant manner. Hadoop comprises of two components, the HDFS (Hadoop Distributed File System) and Mapreduce.
HDFS allows storage of files around clusters with high throughput. HDFS consists of two elements namely Namenode and Datanode. Namenode stores file system metadata and Datanode stores application data separately on other server. HDFS uses master/slave architecture [15] with single Namenode and multiple DataNodes usually one per cluster. The files stored in HDFS can be replicated across multiple machines. All servers connect and communicate with each other using TCP based protocols.
MapReduce is a distributed computation technique that works on top of Hadoop API, an open source cloud based system [3]. It is a divide-and-conquer program model that consists of “Map” and “Reduce” phase. The input to the MapReduce is broken down into a list of key/value pairs. The map and reduce task processes jobs of data on all nodes stored in a local machine [4]. MapReduce suits applications where data is written once and read many times. It works well on structured and semi structured data. Mapreduce consists of two elements Jobtracker to manage the clusters and Tasktracker a slave node to accept the task and to execute the task received by Jobtracker [5].
The major role of preprocessing the web logs is to find the most frequently visited user and session identification. Natheer Khasawneh et al., [6] suggested a trivial algorithm and active user based user identification algorithm to analyze different sessions. The trivial user identification algorithm gets the input of n web log records and incorporates the users last date time access and idle time to produce a list of users. To overcome the time complexity of the above algorithm active user based identification is preferred which uses idle time and active time of the users.
A log file mostly of semi structure in format is analyzed for user access patterns. Bayir et al., [7] proposed a smart miner framework that find user sessions and frequent navigation patterns. Smart Miner used Apriori algorithm to utilize the structure of web graph. The framework also used the MapReduce to process server logs of multiple sites simultaneously.
Detection of network anomalies proposed by Srininvasa Rao et al., [8] identifies unauthorized users by extracting IP address and URL. The processing is carried out in a cluster of 4 machines that removes redundant IP address resulting in efficient memory utilization. Sayalee Narkhede et al., [9] explained the HMR log analyzer which identifies the individual fields by preprocessing the log files. It also presented the removal of redundant log entries that evaluates the total hits from each city.
A distributed document clustering is incorporated in [10] by Jian Wan et.al. The document is preprocessed by parsing the documents and stemming it along which tfidf weight is calculated. The k-means algorithm is used in Mapreduce to cluster the document of same category. Muneto Yamamoto et.al [4] introduced processing of image database in pseudo distributed mode. This methodology converts the original image into grayscale image in parallel. The features are extracted from the grayscale image using hadoop streaming in parallel. III.PROPOSED WORK
Big Data Analytics is a new generation technology designed to extract large volumes of a wide variety of data. All this huge data are available in WWW, where most of them are log files generated at a speed of 1-10Mb/s in a single machine. This vast amount of data cannot be effectively processed, captured and analyzed by traditional database and search tools in reasonable amount of time. So Hadoop rides the big data, where the usage of Hadoop a parallel computation framework results in an efficient time consuming and storage of data.
The proposed work aims on processing the session accessed by the user in log files which is the main part of analysis. It focuses on the total time span exhausted by the user for each requested page. Based on the results of the time spent in each page of a website, path tracking modifications can be done on the structure of the site. This framework implements MapReduce model that incorporates batch processing in commodity hardware. The main principle of this work is to move computation on data rather than moving data over the computation. The log files collected from NASA Kennedy Space centre [11] website holds the entire HTTP request for more than a year. It is an ASCII file with one line per request with columns indicating host, timestamp, request, HTTP reply code and bytes in the reply. This semi structured file of more than 50,00,000 request lines cannot be handled in traditional database as data is not relational type and the size creates big pressure.
The log file imported in HDFS is partitioned into 12 blocks, as HDFS is a block structured file [12] system that breaks files into blocks of same size in a single jvm in which maps and reduce task is performed on each block in parallel. The map task administers all the 12 blocks, by considering one request at a time and converts it into key and value. Once all the map task is completed to 100% its output of text files is feed back to reduce task to aggregate all the key and values.
A. Preprocessing
The log data accumulated from NASA web server contains incomplete, noisy, and inconsistent values. Analysis of logs with these properties results in inconsistencies. Log preprocessing is carried out to filter and minimize the original size of data. The log file that resides in HDFS is given as input to the MapReduce job through FileInputFormat which is an abstract class. In map phase, the Mapreduce task collects the data from HDFS and feed it to the map function as Long Writable [13] and reduce phase is set to zero as there is no need for aggregation of values. TextInputFormat works as input for text files and files are broken into lines as it consists of new line character. The key to the map is the IP address and remaining all the fields in the log line are considered as values.
Pattern Matching of HTTP logs is used to separate fields, and only log line of status count 200 (successful transmission) [14] is confirmed for further processing. The processed line is again checked to throw output that has ‘GET’ method and records containing the name “robots.txt” in the requested resource name (URL) are identified and removed. Also the referred URL containing empty values are removed. The log line that satisfy all the above constraints are considered as values for an IP address. The value also includes the timestamp, date, browser version and total bytes sent for a particular request.
The output of map task appended to the HDFS. The preprocessed file of cleaned data is analyzed to find access of the site on unique date followed by time, in single Mapreduce. The referred URL in the log is classified either as Html, jpg, gif fields and the total count on these extensions are identified and stored in HDFS as text file which is further drilled down to make a decision. Preprocessing reduces the size and memory access of the file which holds cleaned and consistent data. The semi structured log file before preprocessing encloses around 545 MB of data comprising in four files. The preprocessed result exist in localhost consist of only 466 MB of data resulting in less storage of memory.
B. Session Identification
The session identification splits all the pages visited by the IP address based on unique identity and timeout, when the time between page requests exceeds a certain time limit. Assuming that the user has started a new session for a particular IP address, the total time accessed by the user must not exceed 30 minutes. If the specified limit is exceeded a new session is considered for the same IP address. This calculation is carried on the preprocessed data using only the map task.
The session is based on IP address, timestamp and URL referred. These fields are extracted from the preprocessed data already collected in HDFS and the same file can be used for other processing too as HDFS contains read once write many times property. For a unique IP that has logged in the server, all the total timestamp is collected along with referred URL. Using the Date function the timestamp is split into hours, minutes and seconds. The session length is calculated first by finding difference between the timestamp of same IP, tracked from login till logout. If the calculated length exceeds 30 minutes all the log line with same IP are given a session number. All other logs of same IP take a different session number. The output of map contains the session number as key and all the fields in log line as values, the number of reduce task is assigned to zero and logs with the processed values are appended to the text files in HDFS.
IV.EXPERIMENT AND RESULTS
The proposed session identification algorithm uses the Mapreduce approach for efficient processing of log files. The log files enclose HTTP request made on the site, for a period of one year nine months, collected on discrete time period. The process is carried out in Ubuntu 12.04 OS with Apache Hadoop-0.20.2 [16] in pseudo distributed mode. In this mode all the elements of Mapreduce and HDFS run in its own JVM of single machine.
The Hadoop a java based framework is capable of processing petabytes of data by splitting into independent blocks of same size. The projected work is carried out in single jvm of Sun jdk1.6 with Eclipse IDE, thereby the jobs of Mapreduce task is performed using java. All the daemons are started in safe mode and data is placed in the localhost where HDFS resides [17]. The preprocessing of logs is carried out in map task and the results are verified in the Hadoop Web interfaces.
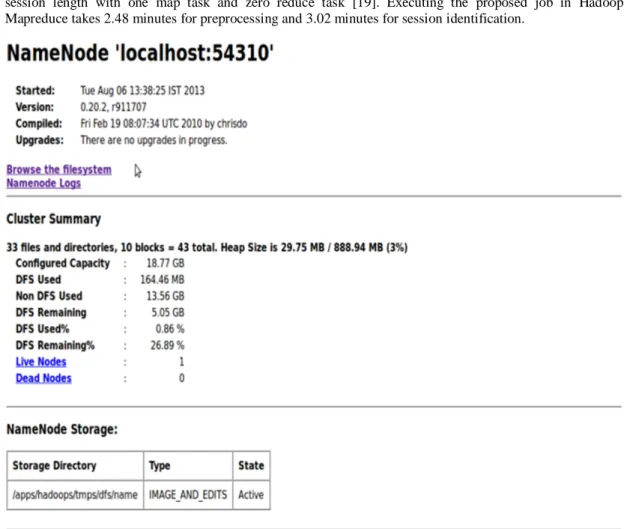
The default web interface of Namenode daemon in localhost 50070 shown Figure 1 illustrates the cluster summary of total heap size, blocks and usage of DFS. The namenode logs and the files can also be downloaded from the localhost for further analysis. The preprocessed data is again scrutinized to find the session length with one map task and zero reduce task [19]. Executing the proposed job in Hadoop Mapreduce takes 2.48 minutes for preprocessing and 3.02 minutes for session identification.
Figure 1. Web interface of default NameNode daemon
The non hadoop approach of processing log files is performed on java 1.6 in single jvm. The log file is loaded as text, which is stored as table. The file is then preprocessed to clean the inconsistent data to which session algorithm is performed. Preprocessing the 40MB data of log file including the session identification is made in 0.47 minutes. Executing the work for the whole dataset takes around 6.15 minutes. In pseudo distributed mode all the five nodes start in a separate JVM which can be viewed in logs directory.
The text file stored in HDFS is retrieved and analyzed in R to produce a statistical result. The output file of session identification algorithm is loaded into R console as a table [18] using R commands.
The unique count of ip address made in map reduce task is analyzed by storing the files as comma separated values and sorted using the order command and count > 10000 is retrieved and copied to another file for further analysis.
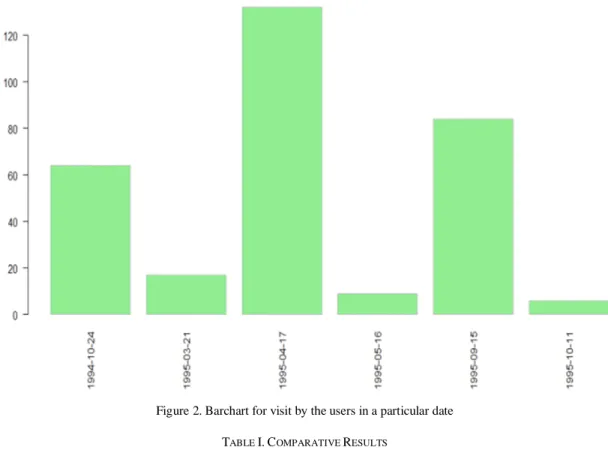
The column fields are separated by space, and so pattern matching is set to retrieve the date, time and total visit made by the users on the particular date. Bar chart is plotted for the above specified fields to have a deeper analysis as shown in Figure 2.
Figure 2. Barchart for visit by the users in a particular date TABLE I.COMPARATIVE RESULTS
Total 516 MB of NASA server logs Milliseconds Minutes
Java 369391 6.15
HMR 330001 5.50
From the above results it is proved that processing of text files in single jvm on java takes more time than processing the same file in Hadoop Mapreduce. Even though HMR process the same job in java the data is handled line by line which is the predefined functionality of map reduce. This function is capable to do the processing in less amount of time when compared to java.
From Table I it is observed that the time to execute 516 MB of dataset in both the environment shows a difference of 25 seconds. When scaling the dataset to terabytes or petabytes the time difference would vary in minutes or hours. Extending the same work in cluster still reduces the efficiency in time.
V.CONCLUSION
With the growing speed of data in the web, a framework is needed to process and store the data. This paper elucidates the analysis of log files using Hadoop Mapreduce framework which incorporates the major preprocessing task and session identification algorithm to handle vast amount of log data. From the results it is concluded that processing a huge file in distributed fashion reduces the time and data transfer cost, without moving the data. The text files can be screwed in order to produce a statistical report for better understanding of users view. Also performing the same task for multiple files of large volume of data reduces the memory utilization, CPU load and other factors that results the process in easy head.
REFERENCES
[1] Thanakorn Pamutha, Siriporn Chimphlee and Chom Kimpan, “Data Preprocessing on Web Server Log Files for Mining Users Access Patterns” .International Journal of Research and Reviews in Wireless Communications of Vol. 2, No. 2, ISSN: 2046-6447 ,June 2012.
[2] Konstantin Shvachko, Hairong Kuang, Sanjay Radia, Robert Chansler, “The Hadoop Distributed File System” Yahoo, IEEE, 2010.
[3] Chris Sweeney, Liu Liu, Sean Arietta and Jason Lawrence, “HIPI: A Hadoop Image Processing Interface for Image-based MapReduce Tasks”, University of Virginia,2010.
[4] Mohamed H. Almeer, “Cloud Hadoop Map Reduce For Remote Sensing Image Analysis” Journal of Emerging Trends in Computing and Information Sciences, Vol. 3, No. 4, ISSN 2079-8407, April 2012.
[5] Muneto Yamamoto and kunihiko Kaneko, “Parallel Image Database Processing With Mapreduce And Performance Evaluation In Pseudo Distributed Mode” International Journal of Electronics Commerce Studies, Vol.3,No.2,pp.211-228,doi: 10.7903/ijecs.1092, 2012.
[6] Natheer Khasawneh and Chien-Chung Chan, “Active User-Based and Ontology-Based Web Log Data Preprocessing for Web Usage Mining” Proceedings of the 2006, IEEE International Conference on Web Intelligence.
[7] Murat Ali Bayir, Ismail Hakki Toroslu, “Smart Miner: A New Framework for Mining Large Scale Web Usage Data”WWW 2009, Madrid, Spain.ACM 978-1-60558-487-4/09/04, April 20–24, 2009.
[8] P. Srinivasa Rao, K. Thammi Reddy and MHM. Krishna Prasad, “A Novel and Efficient Method for Protecting Internet Usage from Unauthorized Access Using Map Reduce”. I.J. Information Technology and Computer Science, 03, 49-55, 2013.
[9] Sayalee Narkhede and Tripti Baraskar, “HMR Log Analyzer: Analyze Web Application Logs over Hadoop MapReduce”, International Journal of UbiComp (IJU) vol.4, No.3, July 2013.
[10]Jian Wan, Wenming Yu and Xianghua Xu, “Design and Implement of Distributed Document Clustering Based on MapReduce”, Proceedings of the second Symposium International Computer Science and Computational Technology (ISCSCT ’09), pp.278-280, 26-28 Dec.2009.
[11]Http://ita.ee.lbl.gov/html/contrib/NASA-HTTP.html, NASA Logs Files. [12]DougCutting “Hadoop Overview”, http://research.yahoo.com/node/2116.
[13]Michael Cardosa, “Exploring MapReduce Efficiency with Highly-Distributed Data”. MapReduce’11, ACM, USA June 2011.
[14]Ramesh Rajamanickam and C. Kavitha, “Fast Real Time Analysis of Web Server Massive Log Files Using an Improved Web Mining Architecture”. Journal of Computer Science 9 (6): 771-779,ISSN: 1549-3636, 2013. [15]Jeffy Dean, Sanjay Ghemawat. “MapReduce: Simplified Data Processing on Large Clusters”, OSDI04: Sixth
Symposium on Operating System Design and Implemention, Ssn Francisco, CA, December, 2004. [16]“Hadoop”, http://hadoop.apache.org.
[17]Tom White, Hadoop: The Definitive Guide, Third Edition, ISBN: 978-1-449-31152-0 1327616795, 2012. [18]John M. Quick, Statistical Analysis with R, Packt Publishing, ISBN 978-1-849512-08-4, October 2010. [19]Jason Vanner, “Pro Hadoop”, Isbn-13(pbk):978-1-402-1942-2, 2009.