Volume 3, Issue 3, 2016
15 Available online at www.ijiere.com
International Journal of Innovative and Emerging
Research in Engineering
e-ISSN: 2394 - 3343 p-ISSN: 2394 - 5494
Image Matching Using Contextual Features
Ashitosh Mestry, Pratik Kulkarni, Siddhesh Mhatre, Jignesh Sisodia Sardar Patel Institute of Technology, Mumbai, India.
Abstract:
We present a method to match images by registering image pairs that have captured the same scene but have large differences in their appearance owing to the differences in the time and the location from which the images were captured. Differences between images are encountered when they are collected over a period of time during which light conditions and scene content may have changed or by using a variety of cameras with different sensors, focal lengths, and exposure values. An approach which considers contextual features provides better performance than local feature matching techniques which cannot always handle these difficulties.
Keywords: Contextual features, Image matching
I. INTRODUCTION:
This project is based on the technique of Image Matching which matches images which have some visual discrepancies between them. Image Matching, or comparing images in order to obtain a measure of their similarity, is an important computer vision problem[13]. The visual discrepancies arise since they may have been collected over a period of time during which light conditions and scene content may have changed. If the visual discrepancies are due to changes in lighting, camera exposure values, scale, scene content, and artistic styles such images are not matched successfully always by the conventional matching methods[1].Hence by means of this project we intend to solve this problem which cannot be solved efficiently and accurately by the existing local matching methods by using regional and local similarities to take into account the contextual features. Our method also provides better performance than local as well as regional feature matching techniques.
Several methods already exist for detecting and matching sets of pixels using image intensity patterns but many will encounter difficulties when images are captured under highly varying conditions[1]. All features have their own strengths and weaknesses and each may be more well-suited for specific tasks than others. On one hand, defining features on a very local scale can create a relatively large set of keypoints that are highly informative for matching and invariant to certain amounts of perspective and content changes. However, limiting the amount of visual information accounted for in a descriptormay obscure the differences in these local keypoint descriptors.
We propose a system that builds upon traditional keypoint matching techniques and uses contextual information to handle these challenging scenarios. Our results let us conclude that the extra regional information that we include helps to clear several ambiguities as compared to the existing methods. By combining local and regional information, we can achieve the best of both worlds by taking advantage of both precise local information and distinct regional data. Thus our framework allows us to utilize the scale invariant advantage of our keypoint extractor[9] and the advantage of identifying regions stable to intensity perturbations provided by MSER[2].
II. RELATED WORK:
Existing image matching systems employ various methods like local matching methods, regional matching methods and also use linear features to get a good matching technique for a pair of two images. Each of these methods have advantages and disadvantages. The local matching methods use relatively small window sizes which can be beneficial in many cases. These methods can distinguish between local areas accurately. However, a large window size may be required in cases where image pairs have large scale, lighting, and/or content changes to correctly highlight very distinct keypoint matches since the images will have many scenic differences[1].
Volume 3, Issue 3, 2016
16 lines by using spatially approximate features which means that two lines are considered to be a matching pair if they have similar distance ratios to neighboring keypoints that are known matches.[1]
On one hand, defining features on a very local scale can create a relatively large set of keypoints that contain excessive information for matching and are invariant to certain amounts of perspective and content changes. However, limiting the amount of visual information accounted for in a descriptor may diminish the differences in these local keypoint descriptors[6].This is especially true when highly different viewing conditions, clutter, and occlusions are present, causing local visual properties to change, making it difficult to match locally-defined keypoints correctly. Using a larger scale can help define more distinctive features. By combining local and regional information into one ensemble feature, the best of both worlds can be achieved by taking advantage of both precise local information and distinct regional data[1].
III. PROPOSED SYSTEM
The proposed system is a pipeline that builds upon traditional keypoint matching techniques and uses contextual information to handle challenging scenarios like changes in lighting, camera exposure values, scale, scene content, and artistic styles. Using this extra regional information can help clear up a great deal of the ambiguity presented by small scale gradient information to find a larger set of matches for registration purposes[1].
We use the keypoint extractor as a local matching method, MSER as a regional matching method and line-segment detector for detecting line segments.
IV. IMPLEMENTATION A. KEYPOINT EXTRACTOR AND DESCRIPTOR :
This algorithm helps to find and describe interest points invariant to scale, rotation, illumination and viewpoint. It generates many features that densely cover the image over the full range of scales and locations[9]. The features are first extracted from a set of reference images and stored in a database. A new image is matched by individually comparing each feature from the new image to this previous database and finding candidate matching features based on Euclidean distance of their feature vectors[9]. It takes the original image, and generates progressively blurred out images. Then, the original image is resized to half. And blurred images are generated again. This procedure is kept repeating."Blurring" is mathematically equivalent to the convolution of the Gaussian operator and the image. Gaussian blur has an "operator" that is applied to each pixel. What results is the blurred image.
Steps for extracting keypoints using keypoint extractor :
1.
Scale space peak selection: Potential locations for finding features.2.
Keypoint localization: Accurately locating the feature keypoints.3.
Orientation assignment: Assigning orientation to the keypoints.4.
Keypoint descriptor: Describing the keypoint as a high dimensional vector.Figure 1. Keypoint Extractor result pipeline from original image to final scale invariant feature transformed image
Volume 3, Issue 3, 2016
17 Figure 3: Portion of the first image detected in the second image
B. MSER:
MSERs are regions that are either darker, or brighter than their surroundings, and that are stable across a range of thresholds of the intensity function[10].
The MSERs are a subset of extremal regions, namely those whose area and thus the shape of the boundary is stable with respect to an intensity perturbation. MSER and its necessary complimentary are defined below[2]: The MSER algorithm performs the following steps:
1. The source image is converted to binary image by applying thresholding using several thresholds from minimum threshold value (inclusive) to maximum threshold value (exclusive) with distance Threshold Increment between neighboring thresholds.
2. Extract connected components from every binary image by finding contours and calculate their centers.
3. Cluster centers from several binary images by their coordinates. Close centers form one group that corresponds to one blob, which is controlled by the Minimum Distance Between Blobs parameter.
4. From the clusters, estimate final centers of blobs and their radiuses and return as locations and sizes of keypoints.[11] In the proposed system, MSER’s are used to find homogeneous areas in images that contain distinctive information that is useful for matching. An ideal neighborhood needs to contain enough regional information to clear up any ambiguity at the local keypoint level but not include so much information that no regions actually match[1]. The results of MSER are shown below.
Figure 2. MSER result pipeline from original image to contoured image
C. Line Segment Detection:
Line Segment Detector is aimed at detecting locally straight contours on images. These are called line segments. Regions of the image where the gray level is changing fast enough from dark to light or the opposite are called contours. The input given to the LSD algorithm is a gray-level image and the output is a list of detected line segments[4].The results of line segment detector are shown below. Given a grayscale image, the algorithm detects line segments via the following four steps:
1. Edge map extraction
A Canny edge detector is parameter free and is proposed to extract the edge map from an input image, which can adapt itself to adjust the low and high thresholds of the Canny operator based on the gradient magnitude of the input image, and which can ensure the completeness of the image's structure information.
2. Edge linking and splitting
This process is started from the edge pixel with the greatest gradient magnitude andthe linking process collects pixels on the edge map with a direction control. Therefore, an efficient splitting process is conducted to get short initial line segments.
3. Line segments extending and merging
The more edge pixels are collected by extending the line segments in both the directions and merged with other collinear line segments around.
Volume 3, Issue 3, 2016
18 All the above detected lines segments are then drawn on the original image using specific color to distinguish them from image.[12]
Figure 3. LSD result pipeline from original image to lines extracted image
D. Combining the three algorithms:
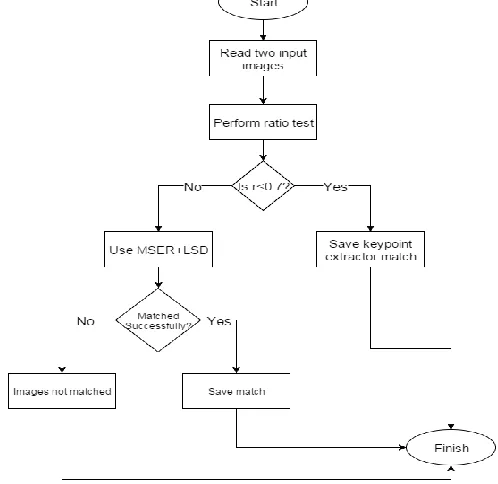
First, our image matching framework uses keypoint extractor algorithm to determine whether the two images match using the distinctiveness ratio of the two keypoint descriptors and determining whether it is less than 0.7.If it is, then the match is saved i.e. the images are considered to be matched. If not, then a combination of MSER and Line Segment Detector Algorithms are used to test whether the two images match to take into account the contextual features. If they do the images are considered to be matched and the match is saved. If not, then the two images are considered to have not matched. This framework can be described by the following flowchart:
Figure 4. Flow of the two images to be matched
Volume 3, Issue 3, 2016
19 V. RESULTS:
The following results were achieved using our framework:
Reduction in the Type 1 errors caused by incorrectly classifying image pairs as un-identical and increasing the matching probability.
Extracting highly distinct interest points and obtaining a large number of correspondences for matching images Combining the local, regional, global, and structural matching methods and using contextual features to achieve image
matching.
Improving the accuracy, precision and the number of matches of the image matching methods in current use.
VI. CONCLUSION:
The proposed system combines the local and the regional matching methods to incorporate the contextual features of an image to better match the images. Our system gives better accuracy, precision and number of matches compared to the conventional matching methods. Thus it can be used as an alternative to the local matching methods or the regional matching methods used. The system resolves the ambiguity in matching many types of images particularly those which require consideration of both local and regional features in which the traditional methods fail apart from correctly matching the images which are successfully matched by the traditional methods. Thus our system provides better matching results and can work on images containing a variety of architectural styles, man-made features, and natural content.
ACKNOWLEDGEMENT:
We would like to thank our guide Prof. Jignesh Sisodia Sir for advising,motivating and giving valuable feedback.We would also like to thank Prof. Dr. Radha Shankarmani for giving significant suggestions and helping to make the project successful.
REFERENCES:
[1] Brittany Morago, Giang Bui, and Ye Duan, “An Ensemble Approach to Image Matching Using Contextual Features,”
IEEE Transactions on Image Processing, Vol. 24, No. 11, November 2015.
[2] Michal Perd’och, “Maximally Stable Extremal Regions and Local Geometry for Visual Correspondences,” August
31, 2011.
[3] Daniel Cabrini Hauagge,Noah Snavely, “Image Matching using Local Symmetry Features,” Cornell University.
[4] R. G. von Gioi, J. Jakubowicz, J.-M. Morel, and G. Randall, “LSD: A line segment detector,”Image Process. Line,
vol. 2, pp. 35–55, Mar. 2012.
[5] B. Fan, F. Wu, and Z. Hu, “Line matching leveraged by point corre-spondences,” in Proc. IEEE Comput. Vis. Pattern Recongnit., pp. 390–397,Jun. 2010 .
[6] T. Tuytelaars and K. Mikolajczyk, “Local invariant feature detectors: A survey,” Found. Trends Comput. Graph. Vis., vol. 3, no. 3, pp. 177–280, 2008.
[7] J. Sivic, B. C. Russell, A. A. Efros, A. Zisserman, and W. T. Freeman, “Discovering objects and their location in images,” in Proc. 10th IEEE Int. Conf. Comput. Vis., vol. 1.,pp. 370–377,Oct. 2005 .
[8] Z. Wu, Q. Ke, M. Isard, and J. Sun, “Bundling features for large scale partial-duplicate Web image search,” in Proc. IEEE Conf. Comput. Vis. Pattern Recongnit., pp. 25–32 ,Jun. 2009.
[9] D. G. Lowe, “Distinctive image features from scale- invariant keypoints,” Int. J. Comput. Vis., vol. 60, no. 2, pp. 91– 110, 2004.
[10] P.-E. Forssen and D. G. Lowe, “Shape descriptors for maximally stable extremal regions,” in Proc. IEEE 11th Int. Conf. Comput. Vis., pp. 1–8,Oct. 2007.
[11] Doxygen,”CV::SimpleBlobDetectorClassReference”,http://docs.opencv.org/trunk/d0/d7a/classcv_1
_1SimpleBlobDetector.html#gsc.tab=0,February 23,2016.
[12] Xiaohu Lu, Jian Yao, Kai Li, and Li Li, “CannyLines: A Parameter-Free Line Segment Detector”, in Image Processing (ICIP), 2015 IEEE International Conference on , vol., no., pp.507-511, 27-30 Sept. 2015.
[13] Pinaki Pratim Acharjya, Dibyendu Ghoshal,”An Image Matching Method for Digital Images Using Morphological