DYNAMIC SLOT ALLOCATION TECHNIQUE FOR MAPREDUCE CLUSTERS
#1
N.CHANDRAMOULI, Assistant Professor, #1
Dept of CSE,VAAGESWARI COLLEGE OF ENGINEERING,KARIMNAGAR. #2
Dr.V.BAPUJI, Associate Professor, #2
Dept of MCA, VAAGESWARI COLLEGE OF ENGINEER, KARIMNAGAR.
ABSTRACT: MapReduce is a famous parallel figuring worldview for expansive scale information handling in groups and server farms. Nonetheless, the space usage can be low, particularly when Hadoop Fair Scheduler is utilized, due to the pre-allocation of slots among outline lessen errands, and the request that guide undertakings taken after by diminish assignments in a run of the mill MapReduce condition. To address this issue, we propose to enable slots to be dynamically (re)allocated to either delineate diminish undertakings relying upon their genuine prerequisite. In particular, we have proposed two sorts of Dynamic Hadoop Fair Scheduler (DHFS), for two unique levels of decency (i.e., group and pool level). The test comes about demonstrate that the proposed DHFS can enhance the framework execution altogether (by 32% 55% for a solitary occupation and 44% 68% for various employments) while ensuring the reasonableness.
Keywords-MapReduce, Hadoop, Fair Scheduler, Dynamic Scheduling, Slots Allocation.
I. INTRODUCTION
As of late, MapReduce has turned into the parallel registering worldview of decision for extensive scale information preparing in groups and server farms. A MapReduce work comprises of an arrangement of guide and lessen undertakings, where diminish errands are performed after the guide assignments. Hadoop [1], an open source execution of MapReduce, has been sent in vast groups containing a great many machines by organizations, for example, Yahoo! what's more, Face book to help cluster preparing for vast employments submitted from various clients (i.e., MapReduce workloads). In a Hadoop group, the PC assets are dreamy into delineate (diminish) slots, which are essential figure units and statically arranged by executive ahead of time. Because of 1) the space allocation limitation suspicion that guide slots must be allotted to delineate and diminish slots must be designated to decrease assignments, and 2) the general execution requirements that guide errands are executed before lessen undertakings, we have two perceptions: (I). there are fundamentally unique
execution and framework use for a MapReduce workload under various occupation execution requests and guide/diminish slots setups, and (II). indeed, even under the ideal employment accommodation arrange and in addition the ideal guide/decrease slots setup, there can be many sit still lessen (or guide) slots while delineate (diminish) slots are insufficient amid the calculation, which antagonistically influences the framework usage and execution. In our work, we address the issue of how to enhance the use and execution of MapReduce bunch with no earlier learning or data (e.g., the arriving time of MapReduce employments, the execution time for
delineate diminish undertakings) about
assignments can utilize unallocated outline if the quantity of lessen errands is more noteworthy than the quantity of decrease slots. In this paper, we will concentrate particularly on Hadoop Fair Scheduler (HFS). This is on account of the bunch use and execution for the entire MapReduce employments under HFS are significantly poorer (or more genuine) than that under FIFO scheduler. In any case, it merits specifying that our answer can be utilized for FIFO scheduler also. HFS is a two-level chain of command, with errand slots allocation crosswise over "pools" at the best level, and slots allocation among numerous occupations inside the pool at the second level [2]. We propose two sorts of Dynamic Hadoop Fair Scheduler (DHFS), with the thought of various levels of decency (i.e., pool level and bunch level). They are as per the following:
Pool-free DHFS (PI-DHFS).
It considers the dynamic slots allocation from the bunch level, rather than pool-level. All the more accurately, it is a written stage based dynamic scheduler, i.e., the guide errands have need in the utilization of guide slots and lessen assignments have need to diminish slots (i.e., intra-stage dynamic slots allocation). Just when the individual stage slots necessities are met would excess be able to slots be utilized by the other stage (i.e., bury stage dynamic slots allocation).
Pool-subordinate DHFS (PD-DHFS).
It depends on the suspicion that each pool is narrow minded, i.e., each pool will dependably fulfill its own guide and decrease assignments with its common guide and lessen slots between its guide staged pool and diminish staged pool (i.e., intra-pool dynamic slots allocation) to begin with, before offering the unused slots to other over-burden pools (i.e., between pool dynamic slots allocation).
We have outlined and executed the two DHFSs over default HFS. We assess the execution and decency of our proposed calculations with manufactured workloads. The two schedulers, PI-DHFS and PD-PI-DHFS, have indicated promising outcomes. The exploratory outcomes demonstrate that the proposed DHFS can enhance the framework execution altogether (by 32% 55% for a solitary occupation and 44% 68% for various employments) while ensuring the decency.
II. Preparatory AND RELATED WORK
A. MapReduce
MapReduce is a prominent programming model for handling substantial informational indexes, at first proposed by Google [16]. Presently it has been a true standard for substantial scale information preparing on the cloud. Hadoop is an open-source java usage of MapReduce. At the point when a client submits occupations to the Hadoop group, Hadoop framework breaks each employment into various guide undertakings and diminishes errands. Each guide undertaking forms (i.e. outputs and records) an information piece and delivers middle of the road brings about the type of key-esteem sets. By and large, the quantity of guide assignments for a vocation is dictated by input information. There is one guide errand for each information square. The execution time for a guide errand is dictated by the information size of an info square.
The decrease assignments comprises of
quantity of lessen undertakings for an occupation to be 0.95 or 1.75 diminish assignments limit [17]. There are a few occupation schedulers for Hadoop, i.e., FIFO, Hadoop Fair Scheduler [2], Capacity Scheduler [18]. The employment planning for Hadoop is performed by the occupation Tracker (ace), which deals with an arrangement of assignment Trackers (slaves). Each taskTracker has a settled number of guide slots and decrease slots, arranged by the director ahead of time. Regularly, there is one opening for every CPU center keeping in mind the end goal to make CPU and memory administration on slave hubs simple [2]. The errand Trackers reports intermittently to the occupation Tracker the quantity of free slots and the advance of the running undertakings. The employment Tracker designates the free slots to the undertakings of running occupations. Specifically, the guide slots must be assigned to outline and diminish slots must be dispensed to lessen errands. Hadoop Fair Scheduler [2] is a multi-client MapReduce work scheduler that empowers associations to share an extensive group among numerous clients and guarantee that all occupations get around an equivalent offer of space assets at each stage. It composes employments into pools and offers assets reasonably over all pools in view of max-min decency [3]. Of course, every client is distributed a different pool and, in this manner, gets an equivalent offer of the group regardless of what number of occupations they submit. Each pool comprises of two sections: outline pool and diminish stage pool. Inside each guide/diminish stage pool, reasonable sharing is utilized to share delineate/slots between the running employments at each stage. Pools can likewise be offered weights to share the group no relatively in the arrangement document.
B. Related Work
There is an expansive assortment of research work that spotlights on the execution improvement for
MapReduce occupations. Comprehensively, it can be characterized into the accompanying two classifications.
•Data Access and Sharing Optimization.
Propose an arrangement of general low-level improvements including enhancing I/O speed, using records, utilizing fingerprinting for speedier key correlations, and piece measure tuning. In this way, they were centered around fine-grain tuning on various parameters to accomplish execution changes. Proposed a strategy to augment filter sharing by gathering MapReduce employments into groups so successive outputs of extensive records are shared among whatever number synchronous occupations as could be expected under the circumstances. MRShare is a sharing structure that gives three conceivable work-sharing open doors, including check work-sharing, mapped yields sharing, and Map work sharing over numerous MapReduce occupations, to abstain from performing repetitive work and in this way decrease add up to preparing time. MapReduce Online is such an altered MapReduce framework to help online conglomeration for MapReduce occupations that run constantly by pipelining information inside a vocation and between employments. LEEN tends to the decency and information areas. Every one of these investigations are correlative to our examination and our approach can be consolidated into these altered MapReduce structures (e.g., MRShare [6], MapReduce Online for encourage execution change. Conversely, our work has a place with the
calculation and planning advancement. In
particular, we concentrate on enhancing the
execution for MapReduce workloads by
augmenting the group calculation use.
•Computation and Scheduling Optimization.
our work consider work requesting streamlining for MapReduce workloads. They show the MapReduce as a two-organize half and half stream shop with multiprocessor assignments where distinctive employment accommodation requests will bring about differed bunch usage and framework execution. In any case, there is a suspicion that the execution time for outline decrease assignments for each occupation ought to be known ahead of time, which may not be accessible in some genuine applications. Also, it is appropriate for autonomous occupations, yet neglects to consider those employments with reliance, e.g., MapReduce work process. In correlation, our DHFS is not limitation by such suspicion and can be utilized for any sorts of MapReduce workloads (i.e., free and ward employments).
Hadoop design enhancement is another approach, including For instance, Starfish is a self tuning structure that can alter the Hadoop's arrangement consequently for a MapReduce employment with the end goal that the use of Hadoop bunch can be boosted, in light of the costbased model and examining strategy. Notwithstanding, even under
an ideal Hadoop setup, e.g., Hadoop
delineate/slots design, there is still space for execution change of a MapReduce occupation or workload, by augmenting the usage of guide and decrease slots.
Fig. 1: Example of the fairness-based slots allocation flow for PIDHFS. The dark bolt line and dash line indicate development of slots
between the guide stage pools and the decrease stage pools.
autonomous of pools. As appeared in Figure 1, it introduces the slots allocation stream for PI-DHFS. It is a written stage based dynamic slots allocation arrangement. The allocation procedure comprises of two sections, as appeared in Figure 1:
(1). Intra-Phase dynamic slots allocation. Each pool is part into two sub-pools, i.e., outline pool and decrease stage pool. At each stage, each pool will get its offer of slots. An over-burden pool, whose space request surpasses its offer, can dynamically get some unused slots from different pools of a similar stage. For instance, an over-burden outline Pool1 can acquire delineate from outline Pool 2 when Pool 2 is under-used, and the other way around.
(2). Between Phase dynamic slots allocation. After the intraphase dynamic slots allocation for both the guide stage and decrease stage, we would now be able to perform dynamic slots allocation crosswise over wrote stages. That is, when there are some unused diminish slots at the lessen stage and the quantity of guide slots at the guide stage is lacking for outline, it will get some sit out of gear decrease slots for delineate, to expand the bunch usage, and the other way around.
Case 2: When NM ¡ SM and NR SR, we fulfill diminish assignments for lessen slots first and after that utilization those sit still decrease slots for running guide errands.
Case 3: When NM SM and NR ¡ SR, we can plan those unused guide slots for running diminish assignments.
Case 4: When NM ¡ SM and NR ¡ SR, the framework ought to be in totally bustling state, and like (1), there will be no development of guide and lessen slots. Next, it will perform intra-stage dynamic slots allocation for those obtained
outline diminish slots utilizing max-min
reasonableness inside the stage.
The pseudo code for this calculation is appeared in Algorithm 1. At whatever point a pulse is gotten from a process hub, we initially figure the aggregate interest for delineate and decrease slots for the present Map Reduce workload. Especially, the interest for delineate is processed in light of the quantity of pending guide errands in addition to the aggregate number of as of now utilized guide slots, as opposed to the quantity of running guide undertakings. The reason is that in our dynamic opening allocation strategy, the guide slots can be utilized by lessen assignments, and guide errands can be running utilizing decrease slots. For each errand tracker, the quantity of utilized guide slots can be ascertained in view of the recipe: mint running Map T asks, tracker Map Capacity u max t running Reduce Tasks tracker Reduce Capacity, 0u. The equation is comparably utilized as a part of the calculation for diminish slots. We would then be able to process stack factors for outline and decrease errands. We next decide dynamically the need to get delineate
(diminish) slots for decrease (or guide)
assignments in light of the interest for outline lessen slots, as far as the over four situations. The particular number of guide (or lessen) slots to be acquired is resolved in light of the quantity of
unused diminish (or guide) slots and its guide (or decrease) slots required. To limit the conceivable starvation of slots for each stage, rather than obtaining all unused guide (or diminish) slots, we include setup factors rate Of Borrowed Map Slots and rate Of Borrowed Reduce Slots for the rate of unused guide and decrease slots that can be acquired. The refreshed guide (or diminish) stack factor can be registered with the consideration of acquired guide (or decrease) slots. At last, we can figure the quantity of accessible guide and diminish slots that ought to be designated for delineate decrease assignments at this pulse for that errand tracker, in view of the present guide and lessen slots limit and also utilized guide and diminish slots.
Fig. 2: Example of the fairness-based slots allocation flow for PDDHFS. The black arrow line and dash line show the get stream for slots crosswise over pools.
As opposed to PI-DHFS that considers the
decency in its dynamic slots allocation
autonomous of pools, yet rather crosswise over
wrote stages, there is another option
stage however much as could reasonably be expected before loaning them to different pools.
IV. EXPERIMENTAL EVALUATION
In this section, we evaluate the performance benefit of our proposed dynamic slot allocation techniques.
Fig. 3: The slot allocation flow for each pool under PD-DHFS.
A. Experiments Setup
We ran our examinations in a bunch comprising of 10 register hubs, each with two Intel X5675 CPUs (6 CPU centers for every CPU with 3.07 GHz), 24GB memory and 56GB hard plates. We design one hub as ace and namenode, and the other 9 hubs as slaves and datanodes. Also, we design 10 guide and 2 lessen slots for every slave hub. We produce our testbed workloads by utilizing three agent applications, i.e., wordcount application (registers the event recurrence of each word in a record), sort application (sorts the information in the information documents in a lexicon arrange) and grep application (finds the matches of a regex in the information documents). We take wikipedia article history dataset1 with four unique sizes, e.g., 10GB, 20GB, 30GB, 40GB as application input information. As there is one guide undertaking for each information hinder in Hadoop, we transfer every information into HDFS with various piece sizes of 64MB, 128MB, 256MB to have distinctive number of information squares and differed piece sizes. Table I records the occupation data for our testbed workloads. It is a combine of three benchmarks with various sizes of information and shifted piece sizes.
B. Execution Improvement Evaluation
presents the assessment comes about for our proposed DHFS for a solitary MapReduce work
and MapReduce workloads with different
employments, e.g., 5 occupations pJ1 J5q, 10 occupations pJ1 J10q and 20 employments pJ1 J20q. All speedups are computed concerning the first Hadoop. We can see that both PI-DHFS and PD-DHFS can enhance the execution of MapReduce occupations fundamentally, i.e., there are around 32% 55% for a solitary employment and 44% 68% for MapReduce workloads with various employments. For the conventional Hadoop, the guide/diminish space design has a major impact in the bunch usage and execution for MapReduce employments, while our DHFS is not affected by outline/opening setup.
C. Dynamic Tasks Execution Processes for PI-DHFS and PDPI-DHFS
intra-stage dynamic slots allocation). Later there are some unused guide slots from pool 2 and they are utilized by lessen undertakings from pool 1 from sixteenth to eighteenth time step(i.e., between stage dynamic slots allocation).
(a) A single MapReduce job
(b) MapReduce workloads with multiple jobs Fig. 4: The performance improvement with our dynamic scheduler for MapReduce workloads.
(a) PI-DHFS
(b) PD-DHFS
Fig. 5: The execution flow for the two DHFSs. There are two pools, with one running job each. Step, Some unused guide slots from pool 1 are respected pool 2 from 4 th to the 7 th time step. Be that as it may, from the 8 th to eleventh, each of the guide undertakings from pool 2 and the diminish assignments from pool 1 takes half of the aggregate slots, subject to the pool-level decency approach of PD-DHFS (i.e., intra-pool dynamic slots allocation). At long last, the unused slots from pool 1 start to respect pool 2 since twelfth time step (i.e., between pool dynamic slots allocation).
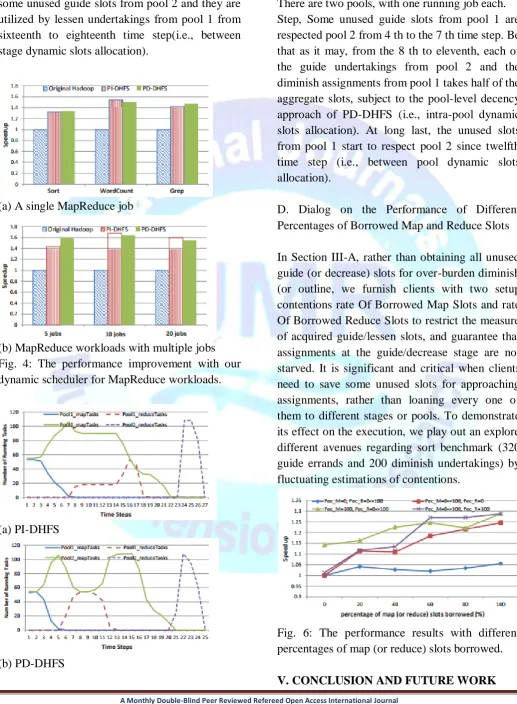
D. Dialog on the Performance of Different Percentages of Borrowed Map and Reduce Slots
In Section III-A, rather than obtaining all unused guide (or decrease) slots for over-burden diminish (or outline, we furnish clients with two setup contentions rate Of Borrowed Map Slots and rate Of Borrowed Reduce Slots to restrict the measure of acquired guide/lessen slots, and guarantee that assignments at the guide/decrease stage are not starved. It is significant and critical when clients need to save some unused slots for approaching assignments, rather than loaning every one of them to different stages or pools. To demonstrate its effect on the execution, we play out an explore different avenues regarding sort benchmark (320 guide errands and 200 diminish undertakings) by fluctuating estimations of contentions.
Fig. 6: The performance results with different percentages of map (or reduce) slots borrowed.
This paper proposes Dynamic Hadoop Fair Schedulers (DHFS) to enhance the usage and execution of MapReduce bunches while ensuring the decency. The center system is dynamically apportioning map (or lessen) slots to outline decrease assignments. Two sorts of DHFS are displayed, specifically, PI-DHFS and PD-DHFS, in view of reasonableness for bunch and pools, separately. The test comes about demonstrate that our proposed DHFS can enhance the execution and usage of the Hadoop group altogether. With respect to future work, we are keen on broadening our dynamic space allocation calculations to heterogeneous situations. Bunch/cloud has turned out to be heterogeneous with various models. We intend to stretch out our past examination [22] to deal with the opening design on CPUs and GPUs. The DHFS source code is openly accessible for
downloading at
http://sourceforge.net/ventures/dhfs/.
REFERENCES
[1] Hadoop. http://hadoop.apache.org.
[2] M. Zaharia, D. Borthakur, J. Sarma, K. Elmeleegy,S. Schenker,I. Stoica, Job Scheduling for Multi-client Mapreduce Clusters. Specialized Report EECS-2009-55, UC Berkeley Technical Report (2009).
[3] Max-Min Fairness (Wikipedia).
http://en.wikipedia.org/wiki/Maxmin reasonableness.
[4] D.W. Jiang, B.C. Ooi, L. Shi, and S. Wu.The Performance of MapReduce: An Indepth Study, PVLDB, 3:472-483, 2010.
[5] P. Agrawal, D. Kifer, and C. Olston. Planning Shared Scans of Large Data Files. In VLDB, 2008.
[6] T. Nykiel, M. Potamias, C. Mishra, G. Kollios, and N. Koudas. MRShare: Sharing Across Multiple Queries in MapReduce . Proc. of the 36th VLDB (PVLDB), Singapore, September 2010.
[7] T. Condie, N. Conway, P. Alvaro, J.M.
Hellerstein. MapReduce on the web. In
Proceedings of the seventh USENIX meeting on Networked frameworks plan and execution, pp. 21C21, 2010.
[8] B. Moseley, A. Dasgupta, R. Kumar, T. Sarl, On planning in outline and stream shops. SPAA, pp. 289-298, 2011.
[9] A. Verma, L. Cherkasova, R.H. Campbell, Orchestrating an Ensemble of MapReduce Jobs
for Minimizing Their Makespan, IEEE
Transaction on reliance and secure figuring, 2013.
[10] A. Verma, L. Cherkasova, R. Campbell. Two Sides of a Coin: Optimizing the Schedule of MapReduce Jobs to Minimize Their Makespan and Improve Cluster Performance. MASCOTS 2012.
[11] H. Herodotou, H. Lim, G. Luo, N. Borisov, L. Dong, F. B. Cetin, and S. Babu. Starfish: A Self-tuning System for Big Data Analytics. In CIDR, pages 261C272, 2011.
[12] H. Herodotou and S. Babu, Profiling, What-if
Analysis, and Costbased Optimization of
MapReduce Programs. in Proc. of the VLDB Endowment, Vol. 4, No. 11, 2011.
[14] J. Polo, C. Castillo, D. Carrera, et al. Asset mindful Adaptive Scheduling for MapReduce Clusters. Continuing Middleware'11 Proceedings
of the twelfth ACM/IFIP/USENIX global
gathering on Middleware, pp. 187-207, 2011.
[15] Z.H. Guo, G. Fox, M. Zhou, Y.
Ruan.Improving Resource Utilization in