The English-Swedish-Turkish Parallel Treebank
Full text
Figure
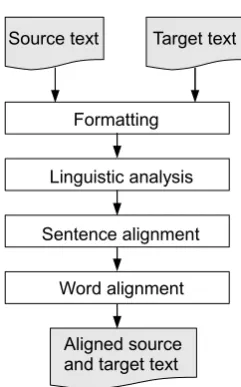
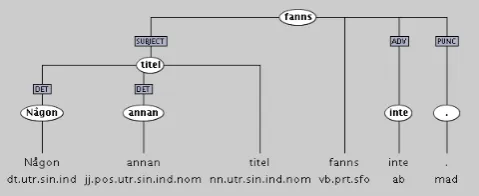

Related documents
The scheme was open to all BPL families having girl children but the benefit can be availed by. the first two girls in the family whose birth has been registered and are in the 0-3
Duyar: University of Ondokuz Mayis, Faculty of Art and Sciences, Department of Mathematics, Samsun, Turkey. E-mail address
The SAK -property has been generalized and modified by several authors in dif- ferent directions whereby several generalizations and modifications of the notion of the β-dual has
Articles were selected according to the following inclu- sion criteria: (1) diagnosis of PJI based on a definition, including clinical signs of infection, presence of sinus tract
Due to the special properties of the nonconvex surrogate function, the algorithm in this study iteratively has a closed form solution to solving a weighted singular value
Het grootste gedeelte van de kosten komen voort uit verlichting, sauna en koffieapparaat. Op deze gebieden zijn vele besparingen te behalen en kunnen ook vrij gemakkelijk
Door de mensen die zich niet thuis voelen, wordt het vaakst aangegeven dat er andere activiteiten aangeboden moeten worden en er meer leeftijdsgenoten moeten zijn om zich wel te
The observation that rhythmic bursts continue in the depressor motor neurons even when there appears to be no activity in the elevator motor neurons indicates that the mechanism for
