International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, ISO 9001:2008 Certified Journal, Volume 8, Issue 1, January 2018)
243
Performance Evaluation of Materialized Query
Sonali Chakraborty
1, Dr. Jyotika Doshi
21Gujarat University, Ahmedabad, Gujarat, India 2
GLS University, Ahmedabad, Gujarat, India
Abstract—Enterprise decision making entails results extracted through OLAP queries. Enterprise data is stored in data warehouse and hence OLAP queries are fired on data warehouse. Performance of result retrieval from a data warehouse is a critical factor as the amount of data stored is high. Low query processing time is desired. Instead of executing the same OLAP query and accessing the data warehouse again and again for retrieving same results, our approach suggests storing queries along with its results, timestamp, threshold and frequency in materialized query database (MQDB). When the same query is fired next time, results are retrieved from MQDB assuming no incremental update in data warehouse. It is observed that query processing time is faster when results are fetched from materialized query database as compared to retrieving the results from data warehouse every time the query is fired.
Keywords—Data warehouse, Materialized query,
Performance evaluation, Query execution, Query results.
I. INTRODUCTION
For enterprise decision making, when an OLAP query is fired, results are extracted from the data stored in data warehouse. The amount of data in a data warehouse is huge; hence query processing time for result retrieval is high. When the same query is fired next time, data warehouse is accessed again
We propose a new approach of materializing and storing queries. When a query is executed first time, results are extracted from data warehouse as usual. Furthermore, we suggest storing query along with its result and other metadata information like timestamp, frequency, and threshold. These details are stored in database, named Materialized Query Database (MQDB). Next time if an equivalent query is fired, results are fetched from materialized query database. This eliminates the need to access data warehouse; hence saving query execution time leading to faster result retrieval.
In this paper, proposed approach does not consider incremental updates in data warehouse at present.
II. LITERATURE REVIEW
Authors Manuel Serranoa et al. [1] emphasized about the principal role and quality of data warehouse in making strategy decisions. They illustrated the method applied for obtaining valid and useful metrics along with its main five phases. They are; Identification, Creation, Metrics definition, Theoretical validation, Empirical validation. Adela Bara et al. [2] commented that business intelligence project may be compromised since low performance in case of data extraction from a data warehouse is critical aspect. System may take long time to run or the data may not be available for longer period. They presented a classification of types of data warehouse based on functional point namely central data warehouse, data mart, virtual data warehouse or views and performed a comparative analysis of different types of data warehouses.
Fahad Sultan, Abdul Aziz [3] discuss that the primary concern in case of ad hoc queries for a large data warehouse is that, query performance degrades since they have to go through large volumes of data after making multiple joins. Probability that same query is fired by multiple users is also high. Hence each time same query is fired all data warehouse data is analyzed. They introduced a strategy to minimize response time by storing queries and their corresponding results. When a similar query is fired again, cache memory is first examined to check if the query is already stored. If found, the result is obtained using cache. Otherwise the query is evaluated. Index is maintained to keep track of queries and their results. In case of data warehouse updates, it will search for those records which satisfy the criteria from onwards to that index. This non re-evaluation of queries which are already stored in cache saves significant time and enhances data warehouse performance. This query cache is maintained at warehouse level.
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, ISO 9001:2008 Certified Journal, Volume 8, Issue 1, January 2018)
244
Issues in management of read only data over longer time domain being critical for data warehouse is discussed by Srinath Srinivasa [5]. A good schema is required for integration of data from diverse sources along with removal of errors during reconciliation. Materialized views provide a way for accessing query results since they improve performance at the cost of redundancy of data, but this redundancy of data do not create any anomaly as data is read only. . Authors discussed some strategies for optimizing query processing. Data access optimization is achieved by various indexing as value list index, bitmap index, join index etc. and data modelling techniques.Panos Vassiliadis, Timos Sellis [6] focus on logical model for OLAP applications i.e. multidimensional data cubes. They provide the functionalities for summarizing, viewing, and consolidating the information available in data warehouses. They defined three categories of attributes of cube models. First group of attributes deals with the representation of the multidimensional space; second group of attributes deals with language issues; third group deals with the existence of physical mappings to relations and/or multidimensional arrays.
P .Karthik, G. Thippa Reddy, E. Kaari Vanan [7] through their paper discuss about the ways of tuning an SQL query such that it decreases the time consumed by the query during runtime. It filters certain keywords not needed in the query. The optimizer examines the input parsed SQL query and statistics about tables, indexes and columns used in the query and gives the query plan as output which is a compiled code. It contains ordered steps to carry out the query, access methods like table or index scan, types of joins to be used, order of join etc. It predicts the cost of using alternative access methods used to resolve a particular query using statistics on tables and indexes and finds the best query plan in terms of I/O cost.
Patrick O'Neil, Dallan Quass [8] present a review of indexing technology used to speed up queries in data warehouse environments. They introduced two approaches, namely; Bit-Sliced indexing which takes an orthogonal bit by bit view of the same data and Projection indexing which materializes values of a column in Row ID order. They performed comparison of the algorithms for feasibility with
these variant indexes against conventional index
algorithms. Analysis showed important performance advantages for variant indexes in few SQL aggregation, predicate evaluation and grouping.
Cost of four plans: Add from rows, Projection index, Value-list index, Bit-sliced index in terms of I/O and factors contributing to CPU, hardware cost are calculated.
Prasan Roy et al. [9] demonstrate that multi-query optimization using heuristics is both practical and beneficial. They discussed that many times the complex queries have lot of common sub expressions. Many of them are correlated nested queries in which some parts of inner subquery is not dependent on outer query variables. Authors addressed the problem of optimizing those sets of queries having common subexpressions referred to as multi-query optimization. Three cost based heuristic algorithms namely Volcano-SH, Volcano-RU based on modifications on Volcano search strategy and a greedy heuristic algorithm are used based on AND-OR DAG (Directed Acyclic graph) method for representing alternative query plans compactly and hence can be easily extended to handle new operators. Greedy strategy iteratively picks the subexpression which gives maximum benefit i.e. reduction in cost if the subexpression is materialized and reused.
III. PROPOSED APPROACH
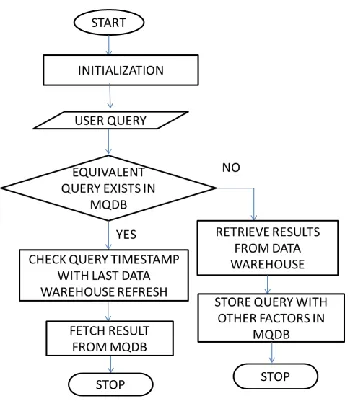
When user fires an OLAP query, results are retrieved from data warehouse. Next time when the same or equivalent query is fired, data warehouse is accessed for retrieving the same result again. Proposed approach suggests storing query with its results and other metadata in MQDB when the query is executed for the first time. When equivalent query is fired next time, results are retrieved
from MQDB instead of from data warehouse.
Suggested approach includes the following phases:
1. Initialization phase to generate identifiers based on existing tables. (During application load)
2. Storing query in MQDB if it is executed for the first time.
3. Checking for equivalent query in MQDB when a
query is fired. If not found, it performs phase 2 considering it as a new query. If an equivalent query is found in MQDB, then proceeds as follows:
a. Compare the timestamp of the equivalent
query from MQDB with timestamp of last data warehouse refresh.
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, ISO 9001:2008 Certified Journal, Volume 8, Issue 1, January 2018)
245
Fig. 1: Flowchart depicting the phases of proposed approach to retrieve from MQDB
To understand suggested approach, consider an example of a NGO working for improving primary education level in India. Data is collected from http://censusindia.gov.in/ (Office of the Registrar General & Census Commissioner, India, Ministry of Home Affairs, Government of India) It contains zone wise education details as described in dw_zones in Table 1.
Data warehouse stores data about the education level of males and females for different age groups in different towns all over India. Different types of education category as defined by the organization are:
Education category
Illiterate
Literate
Below Primary
Primary
Middle
Secondary
Higher Secondary
Diploma
Graduate
Unclassified
A. Initialization Phase
This is one-time initialization phase executed during application load time. Database tables are created for later processing by assigning identifiers to (a) tables (b) fields of each table (c) aggregate functions applied on the fields etc. Identifiers for tables and fields vary based on application / domain. For example considered here, the tables and their attributes are as shown in Table 1.
TABLE 1
TABLES AND THEIR ATTRIBUTES USED IN EXAMPLE
(i) Generating identifiers for tables
Identifiers assigned to the tables are as given in Table 2:
TABLE 2 TABLE IDENTIFIERS
(ii) Generating identifiers for fields of each table
TABLE 3
[image:3.612.82.257.131.332.2] [image:3.612.330.555.162.710.2] [image:3.612.355.548.427.715.2]International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, ISO 9001:2008 Certified Journal, Volume 8, Issue 1, January 2018)
246
Here, identifiers are assigned to fields of table ―dw_zones‖ for illustration. Identifiers (starting from 01 onwards) are assigned to fields of other tables also in a similar manner.(iii) Generating identifiers for aggregate functions
TABLE 4 FUNCTION IDENTIFIERS
B. Storing Materialized Queries when query is fired first time
To understand storing of materialized queries in MQDB, let us consider two queries
Finding average number of illiterate females according to different age groups.
SQL query formed for above query is:
Query 1
Select avg (illiterate_f) From dw_zones Group by age_code
finding “average number of illiterate females according to different age groups in different towns and states”
Query 2 (needs join)
SELECT avg (dw_zones.illiterate_f), dw_age.age_value, dw_town.town_name, dw_states.state_name
FROM dw_zones, dw_town, dw_states, dw_age WHERE dw_state.st_code= dw_zones.st_code AND
dw_states.st_code = dw_town.st_code AND dw_town.town_code = dw_zones.town_code
AND dw_zones.age_code= dw_age.age_code
GROUP BY dw_age.age_value,dw_town.town_name,
dw_states.st_name
ORDER BY dw_states.st_name desc
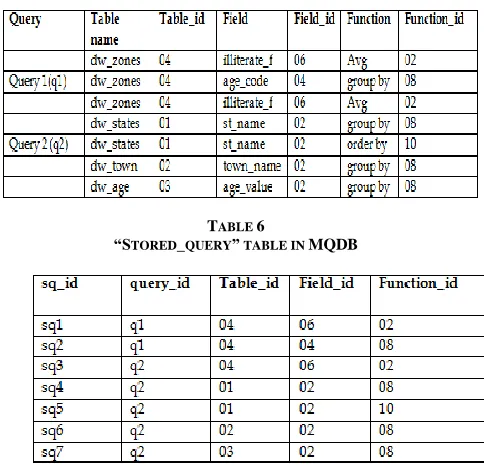
Assuming there is no equivalent query found in MQDB for Query 1 and Query 2, proposed approach will generate identifiers based on pre-defined identifiers for tables, fields and aggregate functions as depicted in Table 2, Table 3 and Table 4. The generated identifiers are stored in ―Stored_query‖ table as shown in Table 6. For better understanding, refer Table 5.
TABLE 5
IDENTIFIERS GENERATED FOR QUERY 1 AND QUERY2
TABLE 6
“STORED_QUERY” TABLE IN MQDB
Other factors about Query 1 and Query 2 such as query_date, query_frequency, query_threshold, number of records and result are stored in ―Materialized_query‖ table as shown in Table 7.
TABLE 7
[image:4.612.100.241.221.406.2] [image:4.612.326.568.301.538.2] [image:4.612.329.563.612.684.2]International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, ISO 9001:2008 Certified Journal, Volume 8, Issue 1, January 2018)
247
C. Processing of query when fired next timeWhen a query is fired, it is first searched in MQDB if an equivalent query exists. Two SQL queries are said to be equivalent if they fetch the same result. They are fired on same set of tables, fields, with same criteria applied on them.
For checking finding an equivalent query from MQDB, consider the following example.
Eq_query 1 (Change in the order of selected fields)
SELECT dw_age.age_value, dw_town.town_name,
dw_states.state_name, avg (dw_zones.illiterate_f)
FROM dw_zones, dw_town, dw_states, dw_age WHERE dw_state.st_code= dw_zones.st_code AND
dw_states.st_code = dw_town.st_code AND dw_town.town_code = dw_zones.town_code AND dw_zones.age_code= dw_age.age_code GROUP BY dw_age.age_value,dw_town.town_name, dw_states.st_name
ORDER BY dw_states.st_name desc
Identifiers generated for Eq_query 1 based on Table 2, Table 3 and Table 4 is shown in Table8:
TABLE 8
IDENTIFIERS GENERATED FOR EQ_QUERY 1
These identifiers are searched in ―Stored_query‖ table. Here, it is found that identifiers of Table 8 are matching with identifiers of query q2 (Query 2).
Hence, Query2 and Eq_query1 are considered equivalent.
Another equivalent query for Query 2 can be written as Eq_query2:
Eq_query2: (Change in order of tables involved)
SELECT dw_town.town_name, dw_states.state_name,
dw_age.age_value avg (dw_zones.illiterate_f) FROM dw_zones, dw_town, dw_states, dw_age
WHERE dw_state.st_code= dw_zones.st_code AND dw_states.st_code = dw_town.st_code AND
dw_town.town_code = dw_zones.town_code
AND dw_zones.age_code= dw_age.age_code
GROUP BY dw_age.age_value,dw_town.town_name,
dw_states.st_name
ORDER BY dw_states.st_name desc;
Consider some other queries along with their equivalent queries as follows. Note that each query is equivalent to itself.
Query 3: Finding number of males having unclassified education category grouped according to different age.
SELECT count (dw_zones.unclassified_m), dw_age.age_value
FROM dw_zones, dw_age
WHERE dw_zones.age_code= dw_age.age_code GROUP BY dw_age.age_value
Equivalent query: Eq_query 3
SELECT dw_age.age_value, count (dw_zones.unclassified_m) FROM dw_zones, dw_age
WHERE dw_zones.age_code= dw_age.age_code GROUP BY dw_age.age_value
Query 4: Finding average number of graduate females and males grouped by states.
SELECT avg (dw_zones.graduate_f), avg (dw_zones.graduate_m), dw_states.state_name FROM dw_zones, dw_states
WHERE dw_state.st_code= dw_zones.st_code AND GROUP BY dw_states.st_name
ORDER BY dw_states.st_name desc
Equivalent query: Eq_query4
SELECT avg (dw_zones.graduate_m), avg (dw_zones.graduate_f), dw_states.state_name FROM dw_zones, dw_states
WHERE dw_state.st_code= dw_zones.st_code GROUP BY dw_states.st_name
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, ISO 9001:2008 Certified Journal, Volume 8, Issue 1, January 2018)
248
Query 5: Number of males and females under the below primary level education category as per different towns.SELECT sum (dw_zones.belprimary_m), sum (dw_zones.belprimary_f), dw_town.town_name FROM dw_zones, dw_town
WHERE dw_zones.town_id= dw_town.town_id GROUP BY dw_town.town_name
Equivalent query : Eq_query5
SELECT dw_town.town_name , sum
(dw_zones.belprimary_f), sum (dw_zones.belprimary_m) FROM dw_zones, dw_town
WHERE dw_zones.town_id= dw_town.town_id GROUP BY dw_town.town_name
(i) Checking timestamp
When an equivalent query is found in MQDB, its timestamp is compared with last data warehouse refresh. Timestamp of a query refers to the date when it was fired last time. If timestamp value of the equivalent query found in MQDB is greater than or equal to last data warehouse refresh date, then the result of the stored equivalent query is fetched from MQDB. This indicates that there has been no data warehouse refresh since this query was fired last time.
(ii) Retrieving results from MQDB
Once an equivalent query is found, results are fetched from ―Materialized_query‖ table as given in Table 7. Here, query corresponds to query q2, hence result are fetched from q2_result.
IV. EXPERIMENTAL RESULTS
A data warehouse is populated with more than 10000 records collected from http://censusindia.gov.in about education level in different states. Implementation of suggested approach is using Python programming and MySQL database. Program is executed on a system with Windows 7, Intel (R) Core (TM) 2 Duo CPU E8400 @3 GHz, 3000 MHz and 2 GB RAM. Processing time of execution is recorded for first time executed queries as well as equivalent queries.
Processing time of query execution is considered applying Method A (retrieving from data warehouse) and Method B (retrieving from MQDB).
Method A: Generating results using data warehouse
Total time for retrieving query result = Time to execute the query + extracting results from data warehouse
Method B: Fetching results from MQDB
Total time for retrieving query result = Time taken to find equivalent query in the database + Checking timestamp with last data warehouse update + Fetching the result from MQDB.
Results are summarized in Table 9. Percentage (%) reduction in time is calculated using formula.
100 * (execution time of Method A – execution time of Method B) / execution time of Method A)
TABLE 9
COMPARING QUERY EXECUTION TIME USING METHODS A,B
Fig.2. Graphical representation of query execution time using Methods A, B
V. CONCLUSION
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, ISO 9001:2008 Certified Journal, Volume 8, Issue 1, January 2018)
249
It is obvious and observed that execution time of Method B depends upon number of results records in MQDB. Less the number of records of results in MQDB, Method B will take less execution time.REFERENCES
[1] Manuel Serranoa, Juan Trujillo, Coral Calero, Mario Piattini. ―Metrics for data warehouse conceptual models understandability‖. Information and Software Technology, Volume 49, Issue 8, August 2007, Pages 851–870.
[2] Adela Bara, Ion Lungu, Manole Velicanu, Vlad Diaconita, Iuliana Botha. Improving query performance in virtual data warehouses. WSEAS TRANSACTIONS on INFORMATION SCIENCE & APPLICATIONS, Issue 5, Volume 5, 2008, ISSN: 1790-0832.
[3] Fahad Sultan, Abdul Aziz. Ideal Strategy to Improve Data warehouse Performance. International Journal on Computer Science and Engineering Vol. 02, No. 02, 2010, 409-415.
[4] Sirirut Vanichayobon. Indexing Techniques for Data Warehouses’
Queries. [Online] Available:
http://www.cs.ou.edu/~database/documents/vg99.pdf [Accessed September 15, 2016]
[5] Srinath Srinivasa. Query Processing Issues in Data Warehouses. [Online]
Available:http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1. 42.9042&rep=rep1&type=pdf
[6] Panos Vassiliadis, Timos Sellis. A Survey of Logical Models for OLAP databases. ACM SIGMOD Record, Volume 28 Issue 4, Dec.1999, Pages 64 – 69.
[7] P. Karthik, G. Thippa Reddy, Mr. E.Kaari Vanan. Tuning the SQL Query in order to Reduce Time Consumption. IJCSI International Journal of Computer Science Issues, Vol. 9, Issue 4, No 3, July 2012, ISSN (Online): 1694-0814.
[8] Patrick O'Neil, Dallan Quass. Improved Query Performance with Variant Indexes. Proceedings of the 1997 ACM SIGMOD International Conference on Management of Data, Pages 38-49. [9] Prasan Roy, S. Seshadri, S. Sudarshan, Siddhesh Bhobe. Efficient