International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459,ISO 9001:2008 Certified Journal, Volume 4, Issue 8, August 2014)
229
A Survey on Preprocessing of Web Log File in Web Usage
Mining to Improve the Quality of Data
R. Lokeshkumar
1, R. Sindhuja
2, Dr. P. Sengottuvelan
31Assistant Professor - (Sr.G), 2PG Scholar, 3Associate Professor, Department of Information Technology, Bannari Amman
Institute of Technology, Tamilnadu.
Abstract—Web mining is to discover and extract useful information. In the internet era web applications are increasing at enormous speed and the web users are increasing at exponential speed. As number of users grows, web site publishers are having increasing their information for attracting and satisfying users. it is possible to trace the users’ essence and interactions with web applications through web server log file and Web log file contains only (.txt) file. The data stored in the web log file consist of large amount of eroded, incomplete, and unnecessary information. Because of large amount of irrelevant data’s available in the web log file, an original log file can not be directly used in the web usage mining. So prepeocessing technique is applied to improve the quality and efficiency of a web log file. Different techniques are applied in preprocessing that is data cleaning, data fusion, data integration. In this paper we will survey different preprocessing technique to identify the issues in web log file and to improve web usage mining preprocessing for pattern mining and analysis.
Keywords— data cleaning, data fusion, data integration, Preprocessing technique, Web usage mining, web log file.
I. INTRODUCTION
Web mining is one of the important fields of data mining. To achieve performance, web personalization and schema modification of web site they applied technique called data mining on content, structure and log files.
Web log file is located in three different locations they are web server logs, Web proxy server and client browser. Web log file provides most complete and accurate usage of data to web server but the log file do not record cached pages visited. Web proxy server takes http request from user, gives them to web server, result passed to web server and return to web server.
In Client browser, log files can reside in client browser window itself, http cookies are used for client browsers, http cookies are piece of information gathered by a web server and stored in user’s computer, ready for further access. Web mining is divided into three types, they are web content mining, web structure mining, web usage mining. In web structure mining based on hyperlinks and intra links inside/outside the web pages we mine the structure of websites. In web content mining user getting useful information from the content of web site which may include text, images, video, audio, hyperlinks. To gather data for content mining they used search engines and web spiders like Web robots. Content server log file are of different types that is access log, agent log, error log and refer log.
Referrer log is used to recording the referrer enter, that a user came from the particular web site by using the user’s page link. In this google has implemented the page-rank algorithm for assigning the weight to referrer sites.
Error log file is used to record the error found on web sites especially when user clicks on particular link and the browser does not display the particular page or web site and the user receives error 404 not found.
Agent log file is used to record the information about user’s browser, browsers version and operating system. Different versions of different user’s browsing history are very helpful for designer and web site changes are made accordingly.
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459,ISO 9001:2008 Certified Journal, Volume 4, Issue 8, August 2014)
230
TABLE I
ATTRIBUTES OF LOG FILE AND DESCRIPTION
Attributes Description
Client IP Client machine IP Address
Client name Client Name if required by
server otherwise hyphen(-)
Date Date is recorded when User
Made access and transfer.
Time Time of transformation is
recorded
Server site name Internet service name as
appeared on client machine
Server Computer name Server name
Server IP Server IP provided by
internet service provider
Server port Server port configured for
data transformation Client server URL
stream Targeted default web page of web site
Client server URL
Query Client query which starts after “?”
Server client status Status code returned by
server link
Server client Bytes Number of bytes sent by
server to client
Client server Bytes Number of bytes received by
client
Client server methods Client method or model of
request can be Get, POST or HEAD
Time taken How much spent by client to
perform an action
Client server version Protocol version like HTTP
Client server host Host header name
User agent Browser type that client used
Cookies Contents of cookies
Referrer Link from where client jump
to this site Server client win32
status Windows status code
There are three main types of web server log file formats to capture the activities of user on web site. All the three log files should be in ASCII text format.
Log file act as health monitor for the web sites and are the main source of user access data and user feedback.
Web log file is a simple plain text file which records information about each user, display of log files data in three different forms namely, web server log formats namely Common log file format (NCSA), Extended log format (W3C), IIS log format.
W3C log format is default log file format on ASCII server. Field are separated by space, time is recorded as GMT (Green which Mean Time). It can be customized that is administrator can add or remove fields depending on the web server manager.
#software: Version of ASCII that is running #Version: The log file format
#Date: To record the date and time of first log entry #Fields: This is not standard format because the fields may change based on server.
#software: Microsoft Internet Information Server 7.5
#Version:1.0
#Date:2014-01-22 09:55:33
#Fields: date time cs-method cs-uri-stem c-ip sc-version sc-status example:
2014-01-13 5:34:11 GET/website/::1HTTP/1.1301 Fig 1 Example for W3C log file format
In fig 1. Field formats are date, time, client Ip address, Method, URL stream, protocol status, version
NCSA (National Centre for Supercomputing Application Format) is to record basic information about the user request such as user name, record host name, date, time, request type, HTTP status code and numbers of bytes send by server showed in Fig 2. NCSA is a fixed format, it cannot be changed.
::1—[20/feb/2014:11:02:44+05300 ”GET/website/HTTP/1.1”200 1107
Fig 2 Example for NCSA log file format
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459,ISO 9001:2008 Certified Journal, Volume 4, Issue 8, August 2014)
231
::1, -, 1/25/2012, 9:57:42, W3SVC1, JAY-PC, ::1, 3,
965, 1153, 200, 0, POST, /Web Site/default.aspx, -, Fig 3 Example for ASCII log file format
II. MOTIVATION
Preprocessing is the essential step fro web usade mining. Preprocessing phase will occus after creating a web log file. A web log file is an input of preprocessing phase of web usage mining. Web log file is large in large, contains number of raw datas, images, audio / video files. The main aim of preprocessing is to make an unstructures/ semistructured web log file data into a structured form by eliminating the unwanted datas from log. We came to a conclusion that preprocessing is very important in web usage mining. Preprocessing steps increases the quality of dada and improves the effictivenrss and efficiency of the othwr steps in web usage mining like pattern discovery and pattern analyais.
III. LITRATURE SURVEY
According to Murata and Saito (2006) user’s interests can be revealed through graph based on their web surfing. In this research, first authors collected the users’ accesses from the user search keyword and graph is generated from it. By applying PageRank algorithm mined from graph to assign importance to accessed pages. In next step, unwanted nodes and weak edges were removed from graph. At last, graph is decomposed into further sub graphs, which depict the behaviour of users surfing. The usage of client log file in WUM has become ineffective so it is important to mention that some sort of cleaning was performed to remove the inconsistent and noisy data. User’s interests can be mined in better way by grouping the interests based on page visited in a particular time interval.
According to Pabarskaite (2002) that preprocessing of web log file plays an important role in WUM. To remove the irrelevant links from log file, cleaning technique was used. A filtered web log is obtained by comparing the both raw web log and link table.
To obtain source code is sometimes difficult and web site designers usually have reservations on source code. Only for specific and limited analysis within a particular domain, this technique can be implemented. The authors performed data cleaning; but no other preprocessing technique was applied such as path completion, filtering, data integration and data grouping. Users and user sessions were not identified which play vital role in up coming steps of WUM.
According to Wahab, et al., (2008) proper analysis of log file is used for proper management of bandwidth and server capacity. Preprocessing step is complex and laborious task. Authors also discussed the various types of log file in detail based on 19 attributes. In this paper authors proposed algorithm two algorithms, first algorithm is to read the log file from any of the three given log file formats and convert the log file data into a database. Second algorithm is to filter out the all the un-interested attributes of web log file.
Only “URL” attributes was declared interested. Date,
Time, IP Address,and User Agentare some other useful
attributes were also dropped. By dropping out such important attributes, the reliability of later phases of Web usage mining cannot be secured. We come to the conclusion that proposed algorithms for data cleaning and data filtering techniques are very weak and needs to be modified.
According to Suneetha and Krishnamoorthi (2004) discussed various sources of web log files such as web server log, proxy log and client log. And, authors discussed the structure of web log file in detail. Authors performed two preprocessing techniques data cleaning and user identification. For their experiment, they took the server web log file as example. In data cleaning step, image pages were removed and in user identification step, authors used three attributes from log file. These attributes are IP Address, Operating System, and User Agent. Data Integration technique was also mentioned but not incorporated. By performing just one or two steps cannot guarantee the reliable results for other two phase of WUM. Sessions identification is another very important technique at preprocessing level, which authors did apply in this paper.
According to Huiying and Wei, 2004 First the data cleaning process on web log file is carries out.
1. Removing records with graphics and videos format such gif, JPEG.
2. Removing records by checking the status code. 3. Removing records applying robot cleaning process. Now came to the conclusion that, if we done the above three steps in web log files then the unwanted data’s are removed and size of web log file will also become less. When compared to other approaches, novel technique reduces the cleaning time even the steps in more.
According to Varunakshi Bhojane, Preprocessing converts the captured log data in to the valuable information which can be given for further pattern discovery. Preprocessing steps includes
1. Extraction the attributes from the web log which is located in web server
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459,ISO 9001:2008 Certified Journal, Volume 4, Issue 8, August 2014)
232
3. Manage the data and put it in relational database or data warehouse.
Now came to a conclusion that, the information after Data Preprocessing can be given to pattern discovery process which includes three different steps in data mining techniques that is clustering, classification and association rules, since irreverent information is removed, so that it speeds up the execution time and provides with valuable information to the users.
From the analysis of web log file and Meta data of page contents user profile were derived In this paper server log file was taken with some mandatory fields such as User-ID, Requested pages and Content-related meta-data. After initial preprocessing, graph of log file is obtained and file is converted into adjacency matrix. Adjacency matrix gives information about user interest viewed pages. By using formula given in Equ 1. Significant pages for user profile can be taken.
s = 1 +2* log (n) --- (Equ. 1)
Here author applied three preprocessing techniques they are, data cleaning, user identification and session identification. Now conclude that it can be said that to extract user profiles, session classification can be more helpful at preprocessing level, which authors completely missed.
According to Yuan, et al., (2003) describes preprocessing on log file as basic activity of Web usage mining. To remove irrelevant entries from log file Author applied two approaches, First authors applied the data cleaning technique, second is path completion technique at preprocessing level User identification technique was also performed based on IP Address, operating system and browsing software. Session identification step was performed based on log file attributes such as IP addresses, referrer null pages, and certain timeout limit of 30 minutes. All the steps of preprocessing were well supported by the proposed algorithms. If authors’ research were able to give some more leverage to WUM users at this level, such as grouping the similar sessions, that could be much better approach.
According to Khasawneh & Chan (2006) log files are designed for not for data mining techniques. It is also designed for debugging purposes; User identification and session identification are also very important and essential step. In this research user’s sessions were identified by applying website ontology based on the structure of web site and features extracted from the pages. Users are identified based on IP Address and user stay for long time in inactive mode. A user was represented as triplet of IP Address, date, and time of visit and set of records visited by user in that period of time as showed in Equ 2.
U ∈ <cip, lastdate, time,{rs.re}>--(Equ. 2)
The authors used maximal forward reference algorithm MF, to convert the user access transactions into database. MF algorithm has its own draw back such as we can miss the number of important log transactions as well. Sessions were not grouped further to help in reducing the complexities of other WUM steps.
According to Castellano, et al., (2007), author develops a tool LODAP for the preprocessing of web log file. The developed Tool provides report summary at each step. It has there preprocessing steps.
Step 1: In Data cleaning was performed based on access method, status code, multimedia objects, and request generated through robots.
Step 2: In Data structuration, user sessions were identified based on IP Address, maximum timeout and set of resources within corresponding access time as given in Equ 3.
S (i) = u (i), t (i), r (i) --- (Equ.3)
Step 3: In Data filtering, least requested pages were removed after defining threshold value.
For each resource r, total numbers of sessions NSi
were calculated. Moreover, user defined threshold value
ε, removes the each request NSi < ε. LODAP tool supports the preprocessing steps along with reports facility at each level of preprocessing in the form of data summarization. We come to the conclusion that it is a good effort by authors to support their work by proper MS Access based tool. In summing up it can be said that if authors were able to perform some sort of classification through LODAP, it would be an effective tool for preprocessing of Web usage mining.
IV. CRITICAL EVALUATION OF PREPEOCESSING
In the above session we have discussed the literature survey on web log pre-processing of web usage mining. we found that data cleaning, data filtering, path completion, user identification, session identification, page view identification, visit identification, episode identification, data summarization are commonly used techniques in pre-processing level of web usage mining. We also observe that in each and every log they used different attributes in different preprocessing techniques. Most commonly used attributes are ip address, date, time, URL, and User agent.
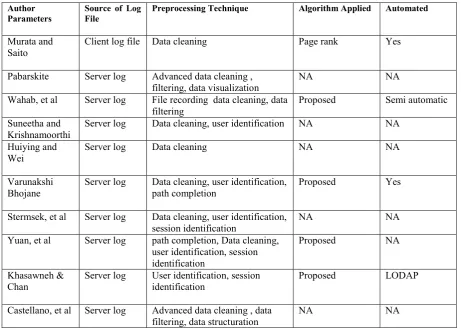
Table 2 summarizes the Preprocessing techniques based on attributes such as source of log file, log file format, preprocessing technique, algorithm applied and tool support to the preprocessing phase.
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459,ISO 9001:2008 Certified Journal, Volume 4, Issue 8, August 2014)
233
Only the Author: Murata and Saito (2006) performed their experiment on client log. In data cleaning technique, irrelevant entries from web log are removed. This is widely used preprocessing technique and it has been performed as mandatory preprocessing technique.
In filtering technique Author: Pabarskaite, (2002) and Wahab, et al.,(2008) use the structure of web site and source code and considered data filtering as sub step of data cleaning and further cleaning was performed.And In filtering technique author: Castellano, et al, (2007) filtered out the least visited pages.
To identify the individual users Suneetha, et al., (2009), Khasawneh, (2006) and Yuan, et al., (2003) used IP Address, browsing software and operating system attributes from web log. And Stermsek, et al., (2007) [7] consist of only used IP Address to identify the users.
V. CONCLUSION AND FUTURE WORK
Preprocessing of web log file is first necessary and important process for web usage mining.
[image:5.595.68.530.401.731.2]Cleaned data after preprocessing is solid base for pattern mining and pattern analysis. Quality of pattern mining and pattern analysis is fully dependent on preprocessing process. In this survey, we summarized the existing web log preprocessing techniques and concluded some results. Most authentic source for web usage mining considers Server log file. So it must be standardized and needs to be updated to capture user access data. Some of preprocessing techniques are applied but we can use less or even ignored preprocessing techniques to improve the quality of preprocessed data. For future work we should explore preprocessing techniques and use them with the combination of existing techniques to make the whole process more robust. New techniques can provide the user to analyze the log file at different level of abstraction such as user sessions. To gain better understanding of log file we need hierarchical clustering by using proposed clustering technique.
Table 2
Summary Of Preprocessing Technique.
Author Parameters
Source of Log File
Preprocessing Technique Algorithm Applied Automated
Murata and
Saito Client log file Data cleaning Page rank Yes
Pabarskite Server log Advanced data cleaning ,
filtering, data visualization
NA NA
Wahab, et al Server log File recording data cleaning, data
filtering Proposed Semi automatic
Suneetha and
Krishnamoorthi Server log Data cleaning, user identification NA NA
Huiying and
Wei Server log Data cleaning NA NA
Varunakshi
Bhojane Server log Data cleaning, user identification, path completion Proposed Yes
Stermsek, et al Server log Data cleaning, user identification,
session identification NA NA
Yuan, et al Server log path completion, Data cleaning,
user identification, session identification
Proposed NA
Khasawneh &
Chan Server log User identification, session identification Proposed LODAP
Castellano, et al Server log Advanced data cleaning , data
filtering, data structuration
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459,ISO 9001:2008 Certified Journal, Volume 4, Issue 8, August 2014)
234
REFERENCES
[1] Murata, T. and K. Saito (2006). Extracting Users' Interests from Web Log Data. Proceedings of the 2006 IEEE/WIC/ACM Conference on Web Intelligence (WI 2006 Main Conference Proceedings) (WI'06) 0-7695-2747-7/06.
[2] Pabarskaite, Z. (2002) implementing Advanced Cleaning and End - User Interpretability Technologies in Web Log Mining. 24th Int. Conf. information Technology Interfaces/ TI 2002, June
24-27, 2002, Cavtat, Croatia.
[3] Yun, L., W. Xun, et al. (2008). “A Hybrid Information Filtering Algorithm Based on Distributed Web log Mining”. Third edu 2008 International Conference on Convergence and Hybrid Information Technology 978-0-7695-3407-7/08 © 2008 IEEE DOI 10.1109/ICCIT.2008.39.
[4] Suneetha, K. R. and D. R. Krishnamoorthi (2009). "Identifying User Behaviour by Analyzing Web Server Access Log File." Published in IJCSNS International Journal of Computer Science and Network Security, VOL.9 No.4, April 2009.
[5] Wahab, M. H. A., M. N. H. Mohd, et al. (2008). “Data Preprocessing on Web Server Logs for Generalized Association Rules Mining Algorithm”. World Academy of Science, Engineering and Technology 48 2008.
[6] Yuan, F., L.-J. Wang, et al. (2003). Study on “Data Preprocessing Algorithm in Web Log Mining”. Proceedings of the Second International Conference on Machine Learning and Cybernetics, Wan, 2-5 November 2003.
[7] Khasawneh,n. and chan (2006). “Active User-Based and Ontology-Based Web Log Data Preprocessing for Web Usage Mining”. Proceedings of the 2006 IEEE/WIC/ACM International Conference on Web Intelligence (WI 2006 Main Conference Proceedings) (WI'06) 0-7695-2747- 7/06© 2006.
[8] Stermsek, G., M. Strembeck, et al. (2007). “A User Profile Derivation Approach based on Log-File Analysis”. IKE 2007: 258-264.
[9] Castellano, G., A. M. Fanelli, et al. (2007). LODAP: “A Log Data Preprocessor for mining Web browsing patterns”. Proceedings of the 6th WSEAS Int. Conf. on Artificial Intelligence, Knowledge Engineering and Data Bases, Corfu Island, Greece, February 16-19 , 2007.
[10] Jalali, M., N. Mustapha, N.B. Sulaiman and A. Mamat,2008. “A web usage mining approach based on LCS algorithm in online predicting recommendation systems”. Proceedings of 12th International Conference Information Visualisation, (IV’08), IEEE Computer Society Washington, DC, USA., pp: 302-307.DOI: 10.1109/IV.2008.40.
[11] TheintT heintAye,”Web log Cleaning for Mining of Web Usage Patterns”, IEEE 978-1- 61284-840-2/11.
[12] Tasawar Hussian, Dr. Sohail Asghar, Dr, Hayyer Masood, Web Usage Mining : “A Survey on Preprocessing of Web log File”, International Conference 978-1-4244080306/10.
[13] Xinjin Li, Sujing Zhang, “Application of Web usage mining in e-learning platform”, 2010 International Conference on E-Business and E-Government.