2018 2nd International Conference on Applied Mathematics, Modeling and Simulation (AMMS 2018) ISBN: 978-1-60595-580-3
Research on the Technology of Data Cleaning in Big Data
Fu-jun FENG
*, Jun-ping YAO
and Xiao-jun LI
Research Inst. of High-Tech, China
*Corresponding author
Keywords: Big data, Data quality, Data cleaning.
Abstract. Some dirty data exists inevitably under big data environment, and it seriously affects the data quality, while the technology of data cleaning is one of the most important methods to improve data quality, and the researches on the data cleaning framework are helpful for big data decision. A general framework of data cleaning in big data is proposed, the core data cleaning module includes three submodules, which are incomplete records cleaning, inconsistent data repairing and approximate duplicate records cleaning, and the processes of data cleaning are discussed specifically. The character of big data is volume, variety, value, velocity and complexity, and there are some incomplete, incorrect and duplicate dirty data in original information, which cause the big data uncontrollable and unavailable[1-2]. It is hoped that valuable information can be extracted from the mass data to provide reference for decision makers. Because of error in data merging or migration of dada sources, it is unavoidable to exist some redundant, incomplete, indeterminable and inconsistent data, which is called dirty data and affects seriously the efficiency of data utilization and the quality of decision making. The technology of data cleaning is particularly important to make the data more accurate and consistent, and it can filter or modify the unnecessary data and output the required data. At present, there are some researches on the data cleaning for big data[3-6]. The technology of big data is developed from the traditional technology, and inherits the traditional concepts and analysis methods[7-8], such as data cleaning and data warehouse. The traditional data cleaning can provide high quality data and enhance efficiency and correctness of data analysis. In big data environment, data cleaning is the basis and original process of big data analysis, which decides the data quality of results. The technology of data cleaning in big data is discussed in this paper, and a general framework of data cleaning is proposed.
Principle of Data Cleaning
There are many reasons for data quality problems, such that the abuse of abbreviation causes data confusion, the approximate duplicate records increase the database loads, human error or system failure may bring about the incomplete or abnormal data, these result in the generation of dirty data. Data cleaning can simplify the database through remove the duplicate records, and convert the residual data to the standard data. In data cleaning, the data sources are processed to make data with the properties of accuracy, completeness, consistency and validity. So any data processing, which can improve data quality, can be considered as data cleaning.
The principle of data cleaning is shown in Fig.1. The information collected is processed by data analysis to get the dirty data, then according to the cleaning rules and algorithms designed before, the dirty data willed be cleaned by manual or automatic mode until the results meets the requirements of data cleaning.
The manual cleaning has the characters of low speed and high accuracy, which is suitable for data cleaning in small scale. But for the large scale of data processing, the speed and accuracy of manual cleaning are decreased significantly, so the automatic cleaning is more suitable.
disadvantage is that it is difficult for implementation and later maintenance. Due to the huge amount of information in big data, data cleaning is completed by the automatic cleaning.
Figure 1. Principle of data cleaning.
A General Framework of Data Cleaning
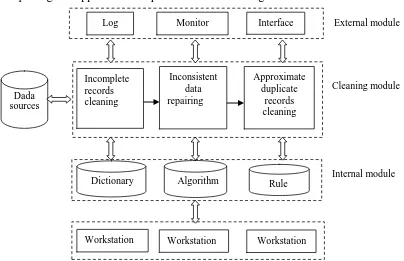
A general framework of data cleaning in big data is proposed in this paper, as shown in Fig.2. It is composed of external module, cleaning module and internal module. The external module includes system logs, monitoring system and access interface. The internal module includes some databases invoked by the cleaning module, such as dictionary, algorithm and rule base. The cleaning module is the core of the data cleaning framework, it searches and invokes the databases according to the designed algorithms and rules, and also accepts the access and monitor of the external module. The cleaning module is composed of three submodules, that is incomplete records cleaning,inconsistent data repairing and approximate duplicate records cleaning.
Figure 2. A framework of data cleaning. Manual cleaning
Rule s Algorithm
s
Dirty data
Automatic cleaning
Required data
Cleaning module Approximate
duplicate records cleaning Incomplete
records cleaning
Inconsistent data repairing Dada
sources
Workstation
External module
Monitor Interface
Log
Internal module Dictionary Algorithm
Rule
[image:2.595.70.474.455.716.2]The Realization of Data Cleaning Module
The Incomplete Records Cleaning
In complex network environment, a large number of missing data will be produced when data reporting or interfaces invoking, so the incomplete data is inevitable, which can affect the decision making in big data. The process of incomplete records cleaning is shown in Fig.3. Firstly, the attribute values are checked for the data sources to prepare for the subsequent data processing; then the missing value will be filled according to the data filling algorithms; lastly outputs the complete data.
Figure 3. Process of incomplete records cleaning.
For attribute value checking, it accomplishes the text content extraction by using the relation extraction technology. In big data environment, we want to search a subject such as “the events related with someone”. In information extraction system, the information of relation and events are expressed by pattern, and different patterns express the different context information. The pattern is a sequence combination of n tuples, and it includes three classes: named entity, entity relation and context assistant.
Named entity class mainly contains entities, such as person, station, organization, email and etc. The entity relation class denotes the relation type of two entities, such as kinship between person and person, affiliation between organization and person and duty of someone. The context assistant class is composed of preposition, conjunction and some words with special meaning.
The instance pattern is generated from one sentence which contains both entity and entity relation. For example, the sentence of “Alice and Bob is good brother” can be expressed by a instance pattern, that is “person and person is kinship”. If an instance pattern often appears without ambiguity, it is called generalization pattern.
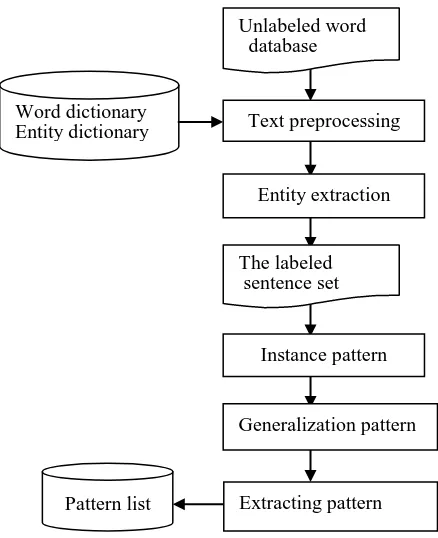
The process of pattern extraction is shown in Fig.4, if the instance pattern obtained in Fig.4 meets the pattern definition in the pattern lists, and then outputs the relation.
Attribute value checking
Data filling
Figure 4. Process of pattern extraction.
The Inconsistent Data Repair
The integrity constraints of dada sources are violated for a variety of reasons, so there are a large number of inconsistent data in big data. The function of the inconsistent data repair is to repair the inconsistent data and make data conform to the integrity and consistency constraints. The process of inconsistent data repair is shown in Fig.5.
Figure 5. Process of inconsistent data repair. The specific process of inconsistent data repair is:
(1) the data sources are detected and preprocessed according to the specified format to prepare for the subsequent data processing;
(2) the results above are processed by the inconsistency detection, if they are different from the integrity constraints of original data, the data will be repaired. The data after repair usually brings some new problems of data inconsistency, so the results will be detected and repaired again until they meet the requirements.
(3) the final repair results are transformed to the original format to be convenient to use by other systems.
Approximate Duplicate Records Cleaning
The approximate duplicate records accounts for a large proportion of dirty data and the reasons include misspellings, different abbreviations or storage types, and so on. It usually appears as many
Text preprocessing Unlabeled word
database
Word dictionary Entity dictionary
The labeled sentence set
Pattern list
Instance pattern
Generalization pattern
Extracting pattern Entity extraction
Inconsistency detection Data
preprocessing
[image:4.595.91.505.485.530.2]cleaning. The cleaning of approximate duplicate records can improve database utilizations and data qualities, and also reduce system consumptions.
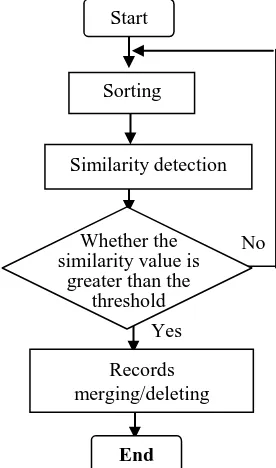
[image:5.595.205.343.151.385.2]There are many methods for duplicate data detection[9], such as the sorted neighborhood method, priority queue and so on. The submodule of approximate duplicate records cleaning in this paper uses sorting and merging algorithm as shown in Fig.6.
Figure 6. Process of approximate duplicate records cleaning. The process of approximate duplicate records cleaning is:
(1) analyzes the attribute segments and finds the key values in the source database, then sorts records according to the key values in top-down or bottom-up order;
(2) scans each record in order and compare it to the adjacent one, then computes the similarity value;
(3) if the similarity value is greater than the set threshold, the record or several successive records are the approximate duplicate records, then they will be merged or deleted; otherwise, scans the next record and repeats the above operations in (2) and (3);
(4) outputs the final results when all records in database are finished.
Summary
The dirty data in big data environment seriously affects the efficiency of data utilization and the quality of decision making, so the technology of data cleaning is particularly important to make the data more accurate and consistent. It can improve data quality, filter or modify the unnecessary data and output the required data. Data cleaning is widely used in various fields, such as bank, traffic, water conservancy, etc. The definition and principle of data cleaning are researched in this paper, and a general framework of data cleaning in big data is proposed. It includes three submodules, that is incomplete records cleaning, inconsistent data repairing and approximate duplicate records cleaning, and the cleaning process of each submodule is particularly analyzed. The focus of our researches in the next step is on the algorithm optimization of approximate duplicate records cleaning.
Start
Yes
No Sorting
Similarity detection
Records merging/deleting
End Whether the similarity value is
References
[1] M. Xiaoting, Design of big data cleaning system for library based on big data decision analysis need, J. Moden Info. 36 (2016) 107-111.
[2] M. Kaihang, G. Yongming, W. Zhihuan, Data management technology of big daba era, Computer Engineering and Software, 36(2015):46-49.
[3] C. Yonghong, L. Xin, Z. Xin, Data cleaning technology oriented health big data, Modern Computer, 1(2017): 21-25.
[4] Y. Donghua, L. Ningning, W. Hongzhi, The optimization of the big data cleaning on task merging, J. Computers, 39(2016): 97-108.
[5] T. Hui, L. Zhensong, Z. Xiaocui. Researches on the data cleaning, Infor. & Com., 1(2017): 238-239.
[6] H. Shenbin, W. Haijie, Z. Zhenhua. Design and implementation of cloud clean system on big data[J]. Intelligent Computer and Applications, 2015, 5(3): 88-90.
[7] W. Shumeng,W. Xiaosong. Network public opinion hotspot based on MapReduce under the environment of big data, Computer Engineering and Software, 36(2015):108-113.
[8] S. Madden, From databases to big data, IEEE Internet Computing, 2012: 4-6.