2017 2nd International Conference on Computer Science and Technology (CST 2017) ISBN: 978-1-60595-461-5
A New Malware Classification Approach
based on Statistical Feature
Ying FANG
a*, Yu-feng HUANG and Bo YU
National University of Defense Technology, Changsha 410073, China
*Corresponding author
Keywords: Statistical Feature, Ensemble learning, Malware Classification.
Abstract. Malware variants which use obfuscation and metamorphism techniques are seen as a critical security threat. Machine learning based malware classification techniques are able to discriminate different malware families and improve existing anti-malware tools. However, high dimensional feature space brings a higher time overhead and one-sided feature can decreases the accuracy. To solve this issue, we propose a statistical feature based malware classification approach and a new feature selection method which can select strong discriminative features. The results demonstrate that the proposed approach can classify modern malware variants effectively.
Introduction
In recent years, malware variants and unknown malware have presented significant challenges to cyber-security. As the study in [1] revealed, the number of new malware has achieved 32.9 million in 2017.
Some common anti-malware tools have troubles in detecting malware variants accurately [2] and efficiently. As the unknown malware variants are mostly from known malware families, existing malware analysis tools can be improved by classification studies. Therefore, to conduct a research on malware classification is urgent.
Machine learning based techniques are common in classifying malware automatically. It can be generally performed with three steps. In the first step, malware variants are collected as datasets and multi-dimensional features can be extracted from these variants. Next, the features are converted into feature vectors and classification models can be constructed via machine learning algorithms. Finally, the classification model is trained and evaluated.
The rest of the paper is organized as follows. Section 2 presents our proposed framework and feature processing method. Section 3 presents the evaluation of our approach. Section 4 concludes our work.
Methodology
In this section, we firstly describe the Cuckoo Sandbox and explain why it is used to analyze malware, then we present the framework overview, finally the feature extraction and selection method are introduced.
Cuckoo Sandbox
Cuckoo Sandbox [4] is a dynamic malware analysis system. Malware execution traces can be gained from Cuckoo; additionally, it can perform memory analysis with integrated support of Volatility [5].
The static malware analysis techniques classify malware families by analyzing program instructions and structures, retrieving malware strings [6] and extracting the PE header information [7]. The static malware classification results can be limited by obfuscation and morphism techniques [8]. In order to reduce the limitation of static analysis, researchers’ analysis malware in dynamic manner. However, dynamic analysis has a considerable time overhead when compared to the static analysis time [9]. Therefore, Cuckoo is used to generating memory mirroring of malware to confront the obfuscation and morphism techniques. In this way, malware variants can be analyzed in a static manner.
[image:2.612.212.399.501.662.2]Framework Overview
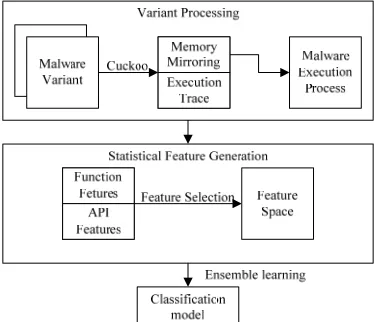
Fig. 1 gives an overview of our malware classification approach. Firstly, the malware variant is executed in Cuckoo to gain the memory mirroring and execution traces of each malware variant. After that, the malware execution process can be dumped from memory mirroring as binary files. The binary files are analyzed by IDA Pro [10] to gain the malware function information. Then function feature and API feature are extracted and their number of occurrences is saved as statistical feature. The feature selection method is based on IG. Since the feature space has gained, the malware classification model can be built via ensemble learning algorithms.
Feature Extraction
[image:3.612.197.413.207.418.2]Function feature and API feature are extracted from two different malware analysis files. The malware execution process files are analyzed via IDA Pro to gain the malware function. Fig. 2 shows an example of malware function. The occurrence number includes argument and instruction is calculated and stored as features. On the other hand, API calls can be extracted from execution traces, the occurrence number of each API call is also stored as features. An example of execution traces is shown in Fig. 3.
Figure 2. An example of malware function.
Figure 3. An example of execution trace.
Feature Selection
Feature selection algorithm is based on IG and improved due to the limitation of IG algorithm itself. Table 1 exemplifies the malware samples and statistical features to illustrate the feature selection method. Aij means the number of malware variants
which are belonged to malware family Cj and have feature ti; Bij means the number of
malware variants which are not belonged to malware family Cj and have feature ti; Cij
means the number of malware variants which are belonged to malware family Cj and
do not have feature ti; Dij means the number of malware variants which are not
belonged to malware family Cj and do not have feature ti. N means the total number of
[image:3.612.145.470.636.707.2]malware variants. Let ti=(feature,number)(1≤i≤m) denotes the features in a malware variant a, the number of malware family is n;
Table 1. Occurrences information
Family
Feature Cj Cj Total number
i
t Aij Bij Aij+Bij
i
t Cij Dij Cij+Dij
It is possible that the occurrences of each feature is the same, soS is used to weightingAij,Bij,Cij,Dij, and
| |Aij Bij
e S= − .
As for featureti, the IG is computed the following:
]} log [ { ]} log [ { )
(
=1
=1+ + + + + + × + × = n j ij ij ij ij ij ij ij ij n j ij ij ij ij ij ij ij ij i D C C D C C N D C B A A B A A N B A S t
G . (1)
The feature is selected fromG(t), putting the G(t) in order from height to low and return the top k features.
Experiments and Discussion
In this section, our proposed approach is evaluated and the implementation details of this experiment are presented. Additionally, our approach is compared to other existing malware classification approach.
The experiments are performed on Intel Core i7 2.00 GHz with 8.00 GB RAM, running on Ubuntu 15.10 operating system. The malware analysis files are generated from Cuckoo Sandbox.
Dataset
[image:4.612.115.496.361.436.2]In this research, 200 malware variants from 10 different malware families are collected. The malware families and their types in our dataset are given in Table 2.
Table 2. Malware families in dataset
Type Malware family (# of Variants)
Worm Abuse (20) Bybz (20)
Clisbot (20) Downloader (20)
Trojan BHO (20) Boht (20)
Buzus (20) Phires (20) Pirminay (20) Ragterneb (20) Performance Metric
In our experiments, we employ two ensemble learning algorithms to build the classification model, Random Forest (RF) [11] and Gradient Boosted Regression Trees (GBRT) [12]. Ensemble learning can combine the strengths of a lot of simpler-base models [13] to improve its performance and reduce the limitation of traditional machine learning algorithms.
We evaluate the performance of our model with popular evaluation metrics, accuracy, precision, recall, f1-score and ROC curve in this section. Accuracy is the fraction of samples that are correctly detected; Precision is the fraction of detected malware samples that are correctly detected out of the total detected dataset; Recall is the fraction of the detected malware samples out of the total malware dataset; F1-score is a weighted harmonic average between Precision and Recall [13]; ROC curve is a graphical plot which is used to illustrate the performance of classifier.
Model Evaluation
follow-up experiments, top 800 function features are selected for constructing feature space.
Table 3. The Accuracy and overhead of u.
u 200 400 600 800 1000
Function 0.763 0.880 0.950 0.978 0.983 Overhead(s) 0.21 0.32 0.89 1.10 1.89
In our evaluation, Table 4 summarizes accuracy, precision, recall and f1-score for two different features in two machine learning algorithms (RF and GBRT) and the ROC curves for each classifier is shown in Fig. 4. It can be easily inferred from the table statistics that our constructed classification model has the ability to classify malware into different categories. For malware classification, precision and recall should be high. However, precision and recall are contradictory in some case. F1-score should be high and it combines precision and recall evaluating a classification model. As can be seen from Table 4, we achieve 0.980 and 0.970 of precision and recall respectively, and the combined feature via GBRT algorithm yields the highest f1-score at 0.970.
Table 4. Classification results.
RF API call function combined accuracy 0.913 0.978 0.960 precision 0.900 0.978 0.950
recall 0.900 0.980 0.950
f1-score 0.900 0.980 0.950 GBRT API call function combined accuracy 0.900 0.970 0.980 precision 0.892 0.970 0.980
recall 0.892 0.970 0.970
f1-score 0.892 0.970 0.970
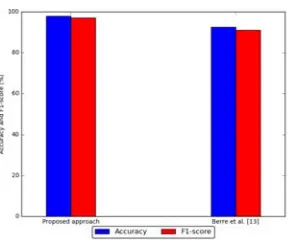
[image:5.612.151.470.484.605.2]To assess the quality of our proposed approach, we perform a comparative experiment with previous work [14]. Accuracy and F1-score of two approach are given in Fig. 5, which shows that our results are higher in Accuracy and F1-score.
Figure 5. Comparison with existing malware classification approach.
Conclusion
In this paper, we propose an ensemble learning based malware classification approach using a new feature selection method. Firstly, we dump the malware execution process from memory mirroring and capture the execution traces from Cuckoo. Then, we combine both dynamic and static features and represent them as statistical features. These features are processed by a new feature selection method which is based on IG idea. The feature space is built and used to construct classification model via ensemble learning algorithms. Our experimental results show that our approach can classify malware variants in an accurate and efficient manner. Additionally, our classification approach is compared to existing anti-malware solutions, the results demonstrate that our approach performs better. Our future work aims at using our method to complete malware clustering.
Acknowledgement
This research was financially supported by the National Natural Science Foundation of China (No.61472437 and No.61379148).
References
[1] Information on https://www.symantec.com/zh/cn/security-center
[2] Rieck, K., Holz, T., Willems, C., & Patrick, D. (2008). Learning and Classification of Malware Behavior. In International Conference on Detection of Intrusions & Malware (pp. 108–125). Springer-Verlag
[3] H. Witten, L., Frank, E., A. Hall, M., & J. Pal, C. (2011). Data Mining: Practical machine learning tools and techniques.
[4] Information on https://cuckoosandbox.org/
[5] Information on https://github.com/volatilityfoundation/volatility
[6] Mithal, T., Shah, K., & Singh, D. K. (2016). Case Studies on Intelligent Approaches for Static Malware Analysis. In Emerging Research in Computing, Information, Communication and Applications (pp. 555–567).
Security, Privacy and Anonymity in Computation, Communication and Storage (pp. 48–58).
[8] Naval, S., Laxmi, V., Rajarajan, M., & Member, S. (2015). Employing Program Semantics for Malware Detection. IEEE Transactions on Information Forensics & Security, 10(12), 2591–2604.
[9] Shehata, H., Yousef, G., Mahdy, B., & Ali, M. (2016). Behavior-based features model for malware detection. Journal of Computer Virology and Hacking Techniques, 12(2), 59–67.
[10] Information on https://www.hex-rays.com/products/ida/index.shtml [11] Breiman, L. (2001). Random Forests. Machine Learning, 45(1), 5–32.
[12] Expansions, B., Polynomials, P., Splines, N. C., African, S., Disease, H., Recognition, P., Considerations, C. (2009). The Elements of Statistical Learning. In the Elements of Statistical Learning (pp. 192–247).
[13] Information on https://en.wikipedia.org/wiki/Precision_and_recall