MINING ACCESS PATTERNS USING
CLASSIFICATION
Mrs. KIRUTHIKA M Asst. Professor,Computer Dept.
Fr.C.R.I.T, Sector 9A, Vashi. [email protected]
Mrs. DIPA DIXIT Lecturer, Computer Dept., Fr.C.R.I.T, Sector 9A, Vashi
[email protected] Abstract:
In day to day life, we see many advertisements aimed at attracting more customers and also changes in marketing schemes. These are done by a company after immense research in the market about the customer. Since, internet became a household phenomenon; it gave rise to creation of many websites. Extracting the usage patterns of users became very important. Thus, websites were required to maintain user profiles for better marketing purposes over the internet. In this paper, we discuss classification of the usage pattern of the users into one or more predefined classes. This may help the company in decision making and also to some extent customer satisfaction can be achieved.
Keywords: Web usage mining, access patterns, visualization
1. Introduction
1.1 Overview of Data Mining
Data mining is the process of extracting patterns from data. Data mining is becoming an increasingly important tool to transform this data into information. It is commonly used in a wide range of profiling practices, such as marketing, surveillance, fraud detection and scientific discovery. Data mining can be used to uncover patterns in data but is often carried out only on samples of data. The mining process will be ineffective if the samples are not a good representation of the larger body of data. Data mining cannot discover patterns that may be present in the larger body of data if those patterns are not present in the sample being "mined". Inability to find patterns may become a cause for some disputes between customers and service providers. Therefore data mining is not foolproof but may be useful if sufficiently representative data samples are collected. The discovery of a particular pattern in a particular set of data does not necessarily mean that a pattern is found elsewhere in the larger data from which that sample was drawn. An important part of the process is the verification and validation of patterns on other samples of data.
1.2 Problem Definition
Since the conception of the internet, many websites have emerged .A particular user will visit the websites using his/her internet. In such cases, it becomes feasible to create user profiles according to the navigation path of the user. Web usage mining can be used to classify the users and create user profiles. With web usage mining useful knowledge can be discovered from the data obtained from interactions of the user with the web. Creating user profile is a problem as it involves complex processes as modeling and predicting a user access. It has thus attracted lots of research internet. There are many software’s readily available, but they have increased size and complexity. Thus more intelligent mining techniques are necessary.
We would like to propose a system that:
2. Classification Concepts
Classification is a data mining (machine learning) technique used to predict group membership for data instance. For example, you may wish to use classification to predict whether the weather on a particular day will be “sunny”, “rainy” or “cloudy”. Popular classification techniques include decision trees and neural networks.
For our system, we have chosen the data mining technique as Classification. 2.1 Design Steps
The design consist of four important steps. (I) Collection of Data Sets:
The usage data collected at different sources will represent the navigation pattern of different segments of overall web traffic, ranging from single user- single site to multiuser – multisite access patterns. This usage data is in the form of web logs collected at server side. This requires recording of the browsed URL’s onto text files for all requests sent to that particular server over a subsequent period of time.
(II) Conversion of Text To Database:
This step involves conversion of the text log files into a database. This includes mapping of text logs into database tuples.
A log tuple can contain:{u, p, t}
u User
p Pages
t Time stamp.
Thus the database acts as a metadata repository.
(III) Identifying Relevant Attributes:
The web log is mostly not in a format that can be used by mining application. This data needs to be reformatted. After reformatting, dataset is clear and relevant attributes can be easily chosen.
(IV) Applying Data Mining Technique:
Now any classification algorithm can be applied to the data set to train 80% of the samples. Then the remaining 20% of samples should be given as input. On this classification any optimization required can be applied. The database samples will now be classified into different pre-defined categories i.e. if 3 classes are pre-defined A, B and C, when test data ‘x’ is given as input to the classification algorithm, it gets classified into either A, B or C. The output will be the user sessions classified into pre-defined categories.
(V) Visualization:
Once the data is analysed, it needs to be abstracted in a schematic form so that useful information which helps in decision making can be extracted. Main goal of data visualization is to communicate information clearly and effectively through graphical means.
3. Implementation
The above design has been proposed for a general dataset but the implementation of the above design has been done for a particular set of weblogs.
Step 1:
Fig.1. Web log records
Step 2:
Now these weblogs were converted to database tables using the following steps: a. Log into MySQL command line client.
b. Create a MySQL database.
c. Create table into DB with attributes and primary key. d. Import the log files into database.
Steps to import text files to database:
a. Upload log file to local directory accessible by MySQL (‘/logfile.txt’).
b. Load this infile or LOCAL file into MySQL table by appropriately specifying the path and delimiters. Above steps in step 2 are explained in figures 2,3,4,5 and 6 given below.
Fig.3. Select schema for text file
Fig.4. Connect to MySQL DB
Fig.6. Table showing required attributes
Step 3:
a. Identifying relevant attributes: Relevant attributes were identified by analyzing the table.
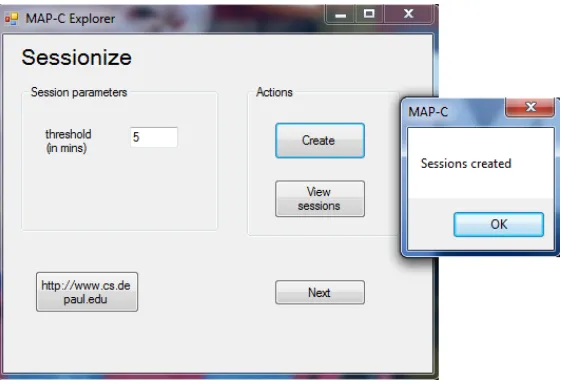
b. Session Identification: User sessions were identified by setting a threshold of 5 minutes for 432 log records. These steps are explained with help of figure no 7, 8 given below.
Fig 8: Identification of user session with threshold of 5 mins
Step 4: Applying of data mining technique
a. The algorithm was trained with the datasets using a query based approach with pre-defined classes. The defined classes are:-
1. Admin
2. Current Student 3. Student 4. Faculty 5. Failed Login 6. External Server 7. Alumni
8. Online Learning Student, for a university website
b. Once the algorithm was trained with training samples it was tested with individual user sessions to classify them into one of the pre-defined classes.
The algorithm used for classification is as follows:-
1. Once the user sessions are identified, class labels or membership criteria (as keywords) for each class is assigned. 2. The entire database of 432 records is used for training based on these keywords.
Finally, each user session is given as input to classify them into one of the pre-defined classes. 5. Results
The following results were obtained after applying classification on cs.depaul datasets using two training modes, i.e; apply classification on class using training set and apply using test set:
Example: - Class ‘prospective_std’.
Fig.9. classification for class ‘prospective_std’ using taining set of 432 records having 11 data elements.
2) Using test set of users session, it could classify 5 user sessions under the class prospective_std which is shown below.
Fig.10. 5 user session where classified under class prospective_std.
Fig.11. Pie Chart showing 3.6% of user sessions under class ‘prospective_std’
6. Conclusion
The above paper discusses the design steps and results of classification of the user sessions into pre-defined classes. This approach showed significant results when applied for a single dataset with classes pre-defined. Also, more datasets with more pre-defined classes can be analysed so that a clear view of user sessions are resulted which helps in decision making.
7. References
[1] Margaret H Dunham, “Data mining introductory and advanced topics” 5th Ed.
[2] Jiawei Han and Micheline Kamber, “Data mining: concepts and techniques”.
[3] “Mining access patterns efficiently from web logs” by Jian Pei,Jiawi, HanBehzad Mortazavi-asl and Hua Zhu Simon Fraser
University,Canada.
[4] “Research on Path Completion Technique in Web Usage Mining” by Yan LIa,b, Boqin FENGa, Qinjiao MAOa School of Electronics and
Information Engineering, Xi' an Jiaotong University, Shaanxi, China School of Computer Science and Engineering, Xi' an University of Technology, Shaanxi, China.
[5] “Applying Web Usage Mining Techniques to Discover Potential Browsing Problems of Users” by I-Hsien Ting, Chris Kimble,Daniel
Kudenko Department of Computer Science, the University of York, Seventh IEEE International Conference on Advanced Learning Technologies,2007.
[6] “Web Mining: Information and Pattern Discovery on the World Wide Web” Cooley, R. Mobasher, B. and Srivastave, J. (1997) In