Volume 1, Issue 8, October 2012
Abstract— Automatic video annotation is a technique to
provide semantic video retrieval. The proposed method of automatic video annotation consists of two main steps i.e.; feature extraction and algorithm for annotation. The features are extracted from the images in the database and these feature vectors are then provided as a training set to the classifier algorithm. The classifier algorithm is a combination of graph based algorithm and K nearest Neighbor algorithm. In graph based algorithm, the computed feature vectors of each image in the database are taken as nodes of the graph and the neighbourhood information of each node is used for classification. In KNN, the classification is using majority vote among the K objects. When a query video is provided by the user, the key frame is extracted and, pre-processing and feature extraction is performed on this key frame of the video. The extracted feature is then provided to the trained algorithm for annotation. The proposed system has a precision rate of 81.14%. The system also compares the results of different combinations of features and descriptors.
An automatic annotation system can be used for effective search and retrieval of news videos, event detection, video summarization and highlight generation, video content analysis, etc.
Index Terms— Automatic Video Annotation, MPEG-7 features, KNN classifier.
I. INTRODUCTION
The ease of capture and encoding of digital images and videos has caused a massive amount of visual information to be produced and disseminated rapidly. Hence, there is an urgent need of effective and efficient tool to find visual information. The process of image retrieval has started from 1970‟s and a large amount of research has been carried out on image and video retrieval in the last two decades. In general, these research efforts can be divided into three types of approaches. The first approach is the traditional text based annotation.In this approach, images and videos are annotated manually by humans and they are then retrieved in the same way as text documents. However, it is impractical to annotate a huge amount of images manually. Furthermore, human annotations are usually too subjective and ambiguous.
The second type of approach focuses on content based
Manuscript received Oct 18, 2012.
Manjary P. Gangan, Department of Computer Science and Engineering, Vidya Academy of Science and Technology, Thrissur, 680501, India.
Dr. R. Karthi, Department of Computer Science, Amrita Vishwa Vidyapeetham, Amrita University, Coimbatore, 641105, India.
retrieval, where images and videos are automatically indexed and retrieved with low level content features like color, shape and texture. These systems usually have a feature extraction phase and an image retrieval phase. The feature extraction phase identifies the relevant regions in images and the features describing colors, textures and/or shape information of these regions or whole image. In the annotation phase, videos are annotated by selecting properties such as colors, shapes and/or texture of video frame regions or a combination of these. One of the important problems in the CBIR systems is the „semantic gap‟. It refers to the gap between low-level content of information that can be extracted from images/videos and the interpretation of higher level concept of images/videos by humans. Other problem is that it is impractical for general users to provide query images/videos.
The third approach of image retrieval is the automatic image and video annotation. The main idea of automatic image and video annotation techniques is to automatically learn semantic concept models from large number of image/video samples, and use the concept models to label new images/videos. Once images/videos are annotated with semantic labels, they can be retrieved by keywords, which is similar to text document retrieval. The key characteristic of automatic annotation is that it offers keyword searching based on image/video content and it employs the advantages of both the text based annotation and CBIR. By using this method users can specify their query concepts easily by using the relevant keywords.
Classification is one promising approach to enable automatic image/video annotation. The performance of classifiers largely depends on image content representation, automatic feature extraction and effective algorithms for image/video classifier training and feature subset selection. Using more visual features for classifier training has more capacity to characterize different visual properties of images or videos effectively and efficiently. This may further enhance the classifier‟s ability on recognizing different image/video concepts or object classes and result in higher classification accuracy.
Automatic video annotation consists of two main steps i.e.; feature extraction and annotation algorithm, similar to automatic image annotation. In this project video annotation is considered as a classification problem by using a training set of image database.The performance of classifiers largely depends on image content representation, automatic feature extraction and effective algorithms for image/video classifier training and feature subset selection. Using more visual
AUTOMATIC VIDEO ANNOTATION
BY CLASSIFICATION
features for classifier training has more capacity to characterize different visual properties of images or videos effectively and efficiently. This may further enhance the classifier‟s ability on recognizing different image/video concepts or object classes and result in higher classification accuracy.
II. OVERVIEW OF PROPOSED SYSTEM
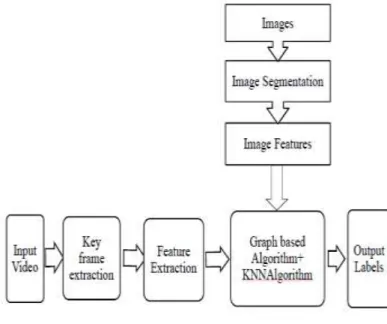
In the proposed method of automatic video annotation, the videos of different animals are annotated using a training set of animal image database. The major steps include preprocessing, feature extraction, algorithm etc. The features are extracted from the images in the dataset. The feature vectors are then provided as a training set to the classifier algorithm. The algorithm used is a combination of graph based and KNN- classifier. The same feature extraction steps are performed for the query video provided by the user and the extracted features are provided to the trained algorithm for classification and annotation. A comparison on different combinations of features for annotation is also performed.
III. LITERATURE SURVEY
In all the related works, the main modules that have been identified are segmentation of image/video objects or regions, feature extraction from the images/video and algorithms used for annotation. The techniques used for these modules by various related works are explained in this chapter.
Image segmentation is usually the first step to extract region based image representation. Because automatic image segmentation is a difficult task, many techniques simplify this task using grid based approach to roughly segment images into blocks [1, 2, and 3]. Visual features are then extracted from these blocks. Clustering algorithms, like k-means, are also used to cluster pixels into different groups with each group identifying a region [11, 12]
Color is one of the most important features of images. Color features are defined subject to a particular color space or model. Various color features have been proposed in the literatures, including color histogram, color moments, color coherence vector , color correlogram , etc. MPEG-7 also standardizes a number of color features including dominant color descriptor , color layout descriptor, color structure descriptor , and scalable color descriptor. Due to its strong discriminative capability, texture feature is widely used in image retrieval and semantic learning techniques. Based on the domain from which the texture feature is extracted, they can be broadly classified into spatial texture feature extraction methods and spectral texture feature extraction methods.Shape is known to be an important cue for human to identify and recognize real world objects. Contour based methods calculate shape features only from the boundary of the shape, while region based methods extract features from the entire region. In [4], Balasubramani et al. discusses in detail about the MPEG 7 features. This paper also gives information on extraction of these features. In [5], Manjunath et al. presents an overview of MPEG-7 color and texture
descriptors and effectiveness of the mpeg 7 descriptors in similarity retrieval, as well as extraction, storage, and representation complexities.
In [13] Vincent et al. propose an innovative method for semantic video annotation through integrated mining of visual features, speech features, and frequent semantic patterns existing in the video. The proposed method mainly consists of two main phases. The first phase consists of construction of four kinds of predictive annotation models, namely speech-association, visual-association, visual-sequential, and statistical models from annotated videos. The second phase is the fusion of these models for annotating un-annotated videos automatically. In the training phase, four kinds of models for video annotations are generated. First model is on the basis of CRM method proposed in [14]. Second model is based on the particular association rules within a scene without considering the temporal continuity. Third model is based on the discovery of implicit temporal continuities of frequent patterns within a scene through the visual analysis. The fourth model exploits special association rules within a scene by performing full speech understanding. For the prediction phase, as the prediction sets are materialized in the training phase, the un-annotated videos can be given couples of appropriate keywords through the constructed prediction models in this phase.
In [15] the system annotates video sequences automatically using knowledge from a pre-annotated dataset. It creates representations from a set of low-level video features and infers the association rules between them and high-level concepts from a pre-defined lexicon. The system consists of two units: learning and annotation units. The learning unit consist of three sequential modules: low-level feature extraction, knowledge representation and rule mining. This unit uses pre-annotated videos to generate rules that link a particular low-level representation of the sequence with a corresponding label from the lexicon. The annotation unit automatically infers concepts and assigns them to videos using the rules and supports generated by the learning unit. Each time new content is added to the database new concepts can emerge from the constant evaluation of the confidence and support measures leading to continuously changing metadata and inference rules. The first module of the learning unit parses video into shots and extracts a representative set of key-frames. Exploiting descriptors extracted from the temporal structure and key-frames, a subsequent filtering stage classifies videos into contextual sub-classes in order to limit the signification space and reduce rule mining complexity.
Volume 1, Issue 8, October 2012
Each time new content is added to the database new concepts can emerge from the constant evaluation of the confidence and support measures leading to continuously changing metadata and inference rules. The first module of the learning unit parses video into shots and extracts a representative set of key-frames. Exploiting descriptors extracted from the temporal structure and key-frames, a subsequent filtering stage classifies videos into contextual sub-classes in order to limit the signification space and reduce rule mining complexity.
The paper [7] offers an overview of the general strategies in visual content-based video indexing and retrieval, video analysis, shot boundary detection, key frame extraction and scene segmentation. Extraction of features including static key frame features, object features and motion features, video data mining, video annotation, video retrieval including query interfaces, similarity measure and relevance feedback, and video browsing.. In [10] video clips are segmented into shots and shot key frames are extracted. Then it constructs a visual vocabulary to describe Bag of features through the clustering of key point features. Finally, the key frame is described as a feature vector according to the presence or count of each visual word. The feature vector forms the classifier under Support Vector Machines (SVM) for semantic annotation.
The semantic concepts appear correlatively and interact naturally with each other rather than exist in isolation. For example, the presence of “road” often occurs together with the presence of “car” while “airplane” and “animal” commonly do not co-occur. Qi et al. [9] have shown that this property is important for semantic video annotation and propose a correlative multi-label (CML) framework. In paper [8], Jinhui et al. adapt this semantic correlation into graph-based semi-supervised learning and propose a novel method named correlative linear neighbourhood propagation to improve annotation performance.
IV. PROPOSEDMETHOD
The proposed system has the four modules namely, Pre-processing, Feature Extraction and Algorithm module. In the pre-processing stage, key frame is extracted from the input video and segmentation is performed on the key frame to obtain the region of interest. The region of interest is then cropped out from the video key frame and rest of the annotation steps are performed on this cropped out region. The watershed segmentation is found to give better segmentation results for the set of animal images in the dataset. In watershed segmentation the image is visualized in three dimensions x, y, grey level (Grey level as altitudes). Any grey image can be considered as a topographic surface. The segmentation is then followed by a hole filling operation. In the next step, the coordinates of the region of interest is found and then it is cropped out from the original image, leaving the background.The features selected for annotation include features like 225-D block-wise color moments, color layout descriptor, dominant color descriptor, glcm, tamura features, homogenous texture descriptor, edge orientation histogram, invariant moments, DWT, DCT, etc.
Fig 1: System Design
Color layout descriptor, dominant color descriptor, edge orientation histogram, homogenous texture descriptor etc. belong to mpeg7 feature descriptors. The mpeg7 descriptors are effective in similarity retrieval, storage, and representation complexities because they are semantic rich features. Moreover, these descriptions do not depend on the way the content is coded or stored.
225-D block-wise color moments
225-D block-wise color moment is a grid-based feature. The mean, variance and skewness are found in LAB color space to represent the color distributions of images. Color moments offer a very compact representation of image content as compared to other color features. For the use of three color moments as described above, only nine components (three color moments, each with three color components) will be used. Thus, we extract the block-wise color moments over 5×5 fixed grid partitions.
Color Layout Descriptor
It is a very compact descriptor and a resolution-invariant representation of color. It efficiently represents the spatial distribution of colors and has no dependency on image format. CLD uses frequency domain features, which introduces perceptual sensitivity of human vision system for similarity calculation.
Dominant Color Descriptor
DCD provides a compact description of the representative colors in an image or image region. The DCD is defined as
F =
Ci
,
Pi
, i =1 to NIt is accurate and compact than the conventional histogram, sufficient to represent the color information of a region.
HTD provides a precise quantitative description of a texture. It is composed of 62 fields, coming from the Gabor filter response.
HTD =
m
,
s
,
f
a1,...
.,
f
a30,
f
b1,...
...,
f
b30
,where
m = mean of the image,
s = standard deviation of the image
ai
f
= type-a feature computed on Gabor filter responses, for 1<=i<=30bi
f
= type-b feature computed on Gabor filter responses, for 1<=i<=30Edge Orientation Histogram
EOH describes spatial distribution of four edges and one non-directional edge in the image. This feature is scale invariant. It defines a small square image-block, by dividing an image space into non-overlapping square blocks. Edge feature is extracted from the image-block. The image-block is further divided into four sub-blocks. The mean values of the four sub-blocks are obtained, and they are convolved with filter coefficients to obtain edge magnitudes. Among the calculated five directional edge strengths for five edge types, if the maximum of them is greater than a thresholding value, then we accept that the block has the corresponding edge type.
Gray Level Co-occurrence Matrix (GLCM)
GLCM is created by calculating how often a pixel with gray-level (grayscale intensity) value „i’ occurs adjacent to a pixel with the value „j’. A co-occurrence matrix is a two-dimensional array, in which both the rows and the columns represent a set of possible image values. A GLCM is defined by first specifying a displacement vector and counting all pairs of pixels separated by this displacement for each gray level value of image. Gray level co-occurrence matrices capture properties of a texture of an image. Other numeric features can also be computed from the co-occurrence matrix that can be used to represent the texture more compactly.
Tamura features
Tamura features are statistical texture feature. These types of texture features characterize texture as a measure of low level statistics of grey level images. Tamura features include a set of six visual features, namely, coarseness, contrast, directionality, likeness, regularity, roughness. Coarseness relates to distances of notable spatial variations of grey levels, that is, implicitly, to the size of the primitive elements (texel) forming the texture. Contrast measures how the grey levels vary in the image and to what extent their distribution is biased to black or white. The degree of directionality is measured using the frequency distribution of oriented local edges against their directional angles. Three other features are highly correlated with the former three features and do not add much to the effectiveness of the texture description.
Invariant moments
Individual moment‟s values do not have the descriptive power to uniquely represent arbitrary shapes. Relative moments are then calculated using the equation for central moments. Invariant moments are the first 7 normalized geometric moments which are invariant under translation, rotation and scaling.
Discrete Cosine Transform (DCT)
Discrete Cosine Transform allows to pack the input data into as few coefficients as possible, since it separates the image into parts (or spectral sub-bands) of differing importance (with respect to the image's visual quality). DCT thus attempts to de-correlate (removal of redundancy between neighbouring pixels) the image data. After de-correlation each transformed coefficient can be encoded independently without losing compression efficiency. This allows the quantizer to discard coefficients with relatively small amplitudes without introducing visual distortion in the reconstructed image. The first transform coefficient is the average value of the sample sequence. This value is referred to as the DC Coefficient. All other transform coefficients are called the AC Coefficients.
Discrete Wavelet Transform (DWT)
Basis functions of the wavelet transform (WT) are small waves located in different times. They are obtained using scaling and translation of a scaling function and wavelet function. Therefore, the WT is localized in both time and frequency. In addition, the WT provides a multi-resolution system. Multi-resolution is useful in several applications. For instance, image communications and image database are such applications.
After the features are extracted for each image in the database, it is given to a classifier algorithm for training. When user provides a query video for annotation, the series of steps done for images in the database are continued (i.e.; pre-processing and feature extraction). The extracted feature is given to the trained algorithm to classify the query video to given set of animal classes. The feature sets calculated for each image in the dataset is taken as a whole feature vector. Construct the graph G =< V; E >, where V = F is the vertex set, E is the edge set associated with each edge
e
ijrepresenting the relationship between the vertices
f
iandf
j.Volume 1, Issue 8, October 2012
V. EXPERIMENTALRESULTS
Table 1: Key frame exraction, cropped region of interest and annotation
Fig.2: Effect of different features on classification
Algorithm Existing (LNP algorithm)
Proposed (LNP+ KNN)
Precision % 81.14 76.56
Recall % 65.71 68. 5
Accuracy % 91.42 92.14
Table 2: Comparison of existing and proposed algorithms
VI. SCOPE OF FUTURE WORK
• Improve the segmentation, by using some advanced or hybrid segmentation techniques
• Decrease the time complexity of the system • Modify the system , to give better performance
• Include more number of MPEG 7 descriptors like scalable color descriptor, Region Based Shape Descriptor, etc. as features
• Include shape features that give better classification
VII. CONCLUSION
The current system is just a prototype for implementation of automatic video annotation, using animal image database. The method provides satisfactory results for various videos. A comparison of annotation results is made by taking different number of features and descriptors.
REFERENCES
[1] Y. Mori, H. Takahashi, R. Oka, “Image-to-word transformation based on dividing and vector quantizing images with words”, Proceedings of the Seventh ACM International Conference on Multimedia, ACM Press, 1999.
[2] A. Vailaya, M.A.T. Figueiredo, A.K. Jain, H.J. Zhang, “Image classification for content-based indexing”, IEEE Transactions on Image Processing 10 (1), 117–130, 2001.
[3] G.J. Qi, X.S. Hua, Y. Rui, J. Tang, T. Mei, and H.J. Zhang, “Correlative multi-label video annotation,” Proc. ACM Multimedia, pp. 17–26, 2007.
[4] Balasubramani R, V. Kannan, “Efficient use of MPEG-7 Color Layout and Edge Histogram Descriptors in CBIR Systems”, Global Journal of Computer Science and Technology , Vol. 9, 2009. [5] B. S. Manjunath, Jens-Rainer Ohm, Vinod V. Vasudevan, and Akio
Yamada, “Color and Texture Descriptors”, IEEE Transactions On Circuits And Systems for Video Technology, Vol. 11, No. 6, June 2001. [6] Andres Dorado, Janko Calic, and Ebroul Izquierdo, “A Rule-Based Video Annotation System”, IEEE Transactions on Circuits and Systems for Video Technology, 2004
[7] Weiming Hu, Nianhua Xie, Li Li, Xianglin Zeng, and Stephen Maybank, “A Survey on Visual Content-Based Video Indexing and Retrieval”, IEEE Transactions on Systems, Man and Cybernetics—Part C: Applications and Reviews, 2011
[8] Jinhui Tang, Xian-Sheng Hua,Meng Wang, Zhiwei Gu, Guo-Jun Qi, Xiuqing Wu “Correlative Linear Neighbourhood Propagation for Video Annotation”, IEEE Transactions on Systems, Man, and Cybernetics, April 2009
[9] G.J. Qi, X.S. Hua, Y. Rui, J. Tang, T. Mei, and H.J. Zhang, “Correlative multi-label video annotation,” Proc. ACM Multimedia,
pp. 17–26, 2007.
[10] Youdong Ding, Jianfei Zhang, Jun Li, Xiaocheng Wei, “A Bag-of-Feature Model for Video Semantic Annotation”, Sixth International Conference on Image and Graphics, 2011.
[11] J.Z. Wang, J. Li, G. Wiederhold, “Simplicity: semantics-sensitive integrated matching for picture libraries”, IEEE PAMI 23 (9), 947–963, 2001.
[12] C.P. Town, D. Sinclair, “Content-Based image retrieval using semantic visual categories”, Society for Manufacturing Engineers, 2001. [13] Vincent S. Tseng, Ja-Hwung Su, Jhih-Hong Huang, and Chih-Jen
Chen, “Integrated Mining of Visual Features, Speech Features, and Frequent Patterns for Semantic Video Annotation”, IEEE Transactions On Multimedia, Vol. 10, No. 2, February 2008.
[14] V. Lavrenko, S. L. Feng and R. Manmatha, “Statistical models for automatic video annotation and retrieval”, The International Conference on Acoustics, Speech and Signal Processing, May 2004. [15] Andres Dorado, Janko Calic, and Ebroul Izquierdo, “A Rule-Based
AUTHORS
First Author – MANJARY P. GANGAN, Department of Computer Science and Engineering, Vidya Academy of Science and Technology, Thrissur, 680501, India.