Container-based Cluster Management Platform
for Distributed Computing
Ju-Won Park and Jaegyoon Hahm
Div. of Supercomputing, KISTI,
245 Daehak-ro, Yuseong-gu, Daejeon 305-806, Korea
Abstract—Several fields of science have traditionally de-manded large-scale workflows support, which requires thou-sands of CPU cores or more. Since users’ demands for software packages and configuration is the difference, an approach to making available in real time a service en-vironment desired by users without significant challenges for administrators is necessary. In this paper, we present a container based cluster management platform and introduce an implementation case to minimize performance decline and to provide a dynamic distributed computing environment desired by users. This paper makes the following contri-butions. First, a container based virtualization technology is assimilated with resource and job management system to expand its applicability to support large-scale scientific workflows. Second, an implementation case in which docker and HTCondor are interlocked with each other is introduced. Lastly, docker and native performance comparison using two widely known benchmark tools and Monte-Carlo simulation results implemented using various programming languages are presented.
Keywords: Container-based virtualization, Docker, HTCondor, Distributed computing
1. Introduction
Traditionally, high energy physics, oceanography, mete-orology, astronomy, and space science require large-scale workflows demanding CPUs consisting of more than several thousand cores [1], [2]. These scientific workflows come in a variety of forms, ranging from high throughput computing (HTC) combining millions of loosely-coupled tasks to high performance computing (HPC) referring to a tightly-coupled from such as message passing interface (MPI) tasks being processed simultaneously by several thousand cores. In order to handle such scale scientific workflows, large-capacity cluster systems such as supercomputers are widely used. Such a large-capacity cluster system usually supports RJM (Resource and job Management) functions, enabling multitude of uses to share resources fairly. However, as the resources are shared by multiple users and organizations, there still exist many challenges, the biggest of which is the difference in users’ demands for software packages and configurations. Because of these challenges, in practice an operating system (OS) and software stacks are often once
installed and kept unchanged for a very long time [3]. These rigid utilization practices pose many constraints to new technology development initiatives, dampening expectation of performance increase following software version upgrade. To overcome such issues of rigid utilization practices and deliver more dynamic service environments to users, many studies - aimed at configuring and providing users with clusters using virtualization resources built on Xen or KVM-based virtualization technologies - have been conducted [4], [5], [6]. In fact, many scientists are working on researches, using the VM available from Amazon EC2. Although sig-nificant performance improvement has been achieved thanks to the improvement of hypervisor technology and develop-ment of various techniques such as passthrough approach, overhead incurred by hypervisor inevitably compromises performance [7]. Because of such constraints, container-based virtualization technologies such as Linux-VServer, OpenVZ, and LXC are frequently utilized recently [7], [8], [9].
This paper presents a container-based cluster management platform and introduces an implementation case to minimize performance decline and to provide a dynamic distributed computing environment desired by users. As container-based virtualization technology compromises performance less than hypervisor-based one, the former can reach near-native performance. This paper is designed to contribute in three regards. First, container-based virtualization technol-ogy is assimilated with RJM to expand its applicability to cluster environment in a bid to support large-scale scientific workflows with near-native performance. As conventional container resource utilization approaches were focused on providing user-customized service environment in a single computer, they were not suitable for supporting scientific workflows utilizing resources on a large scale. Second, an implementation case in which docker [10], which is a container-based virtualization technology using LXC, and HTCondor [11] frequently used in HTC applications are interlocked with each other is introduced to present a method of implementing with ease the approach presented herein. Third, docker and native performance comparison using widely known benchmarking tools is presented and Monte-Carlo simulation results implemented using various programming languages in an environment where HTCondor and docker are interlocked with each other are presented.
This paper is organized as follows. The motivation and related work are described in Section 2. Then, detailed descriptions of the proposed approach and implementation are proposed in Section 3. Next, Section 4 shows the performance of cluster system implemented on HTCondor and docker. Finally, we conclude this paper in Section 5.
2. Background
2.1 Motivation
Most large-capacity cluster systems are shared by a mul-titude of individual and organizational users. As these users require way different service environments (OS, software package, configuration, etc.) in this setting, it is significantly challenging to meet their varying requirements in entirety. In particular, in-house codes developed by scientists on their own require specific OS and library versions.
To overcome these constraints, PLSI1 provides users with
compilers supported by different clusters, mathematical li-braries, and installation paths on its website. Then, users need to find and access clusters where they can compile their own codes for execution [12].
This environment poses challenges to both administrators and users:
• Challenges for administrators: First of all, a lot of packages required by users should be installed on all computing nodes upon request. Given that most clusters have 500 or more computing nodes and numerous libraries and versions, this administration approach in-volves very daunting challenge. In addition, if a user-requested kernel version is different from OS already installed, it is difficult to fulfill such request. Because of this issue, service approach is commonly available without significant modification except for some bug fix and security enhancement in most clusters. This rigid service approach cannot support new technology de-velopment and compromises performance improvement following compiler version upgrade.
• Challenges for users: A user always has to confirm in advance if essential packages are available and, if not available, sends a request to administrator. In particular, if each cluster has different administrator in an environment where multiple clusters are interlocked with each other like in PLSI, a user has to request multiple administrators to install necessary software packages. Therefore, it is difficult for users to be provided with execution environments in real time as they desire. Because of these issues, scientists run their application programs using public cloud services despite performance degradation.
1To ensure that supercomputing resources are provided to researchers as efficiently as possible, a project named Partnership & Leadership for the Nationwide Supercomputing Infrastructure (PLSI) is carried out in Korea, aiming to establish a unified system of resources utilization by integrating supercomputing resources across the nation.
An approach to making available in real time a service environment desired by users without significant challenges for administrators is necessary.
2.2 Related Work
There has been good research activities in addressing the performance of virtualized resource in cloud computing environments [13], [14], [15], [16]. Walker [13] conducted the study on HPC in cloud by benchmarking Amazon EC2. Then, He et al. [14] extend to evaluating the technical capability of current public cloud computing platforms, and their suitability for running scientific applications, especially High Performance Computing (HPC) applications. Jackson et al. [15] represents the evaluation comparing conventional HPC platforms to Amazon EC2, using real applications representative of the workload at a typical supercomputing center. To evaluate the performance of real scientific work-loads, it uses the NERSC benchmarking framework [17]. Iosup et al. [16] analyze the performance of cloud computing services for scientific computing workloads. Specifically, it focused on the real scientific computing workloads of Many-Task Computing (MTC) users. Despite these many activities, the use of virtualization has been traditionally laid off in most HPC facilities due to inherent performance overhead [3].
Recently, container-based virtualization systems (e.g., Linux VServer, OpenVZ, and Linux Containers) are in-vestigated since it offer a lightweight virtualization layer, which promises a near-native performance [7], [8], [9]. In [7], the performance of three well known open source hypervisors, KVM, OpenVZ, and Xen was evaluated in the context of HPC. Their results showed that OpenVZ had the best performance for I/O throughput among them. Soltesz et al. [8] described a virtualization approach which is a synthesis of resource containers and security containers applied to general-purpose, time-shared operating systems. They conducted a network bandwidth benchmark using iperf and macro benchmarks for CPU and disk I/O intensive. From their results, I/O related benchmarks perform worse on Xen when compared to Linux VServer. Xavier et al. [9] conducted a number of experiments of container-based vir-tualized for HPC. Their results showed that the container-based virtualization system had better performance than traditional hypervisor-based virtualization. Furthermore, they described that LXC demonstrated to be the most suitable of the container-based system for HPC since the performance degradation can be offset by the easy of management.
Docker is a lightweight and powerful open source con-tainer virtualization technology combined with a work flow for building and containerizing applications [10]. It provides a toolset and unified API for managing kernel-level tech-nologies, such as containers, cgroups, namespace and union file systems. Therefore, docker lets us quickly assemble applications from components and eliminates the friction
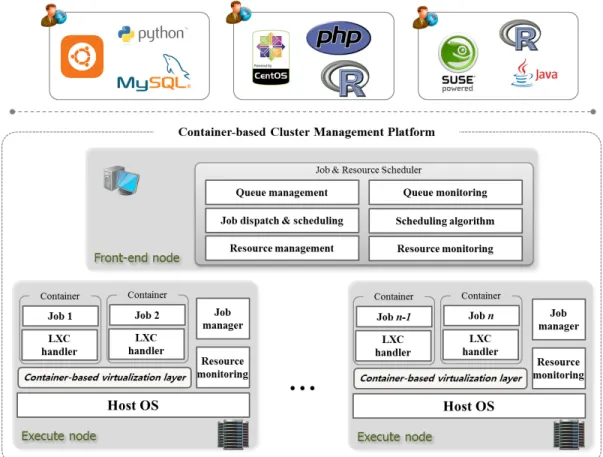
Fig. 1: Container-based cluster management platform architecture.
between development and production environments.
3. Container-based cluster management
platform
3.1 Approach
Fig. 1 shows the proposed approach. In general, cluster systems supporting scientific workflows consist of a front-end node allocating computing resources in response to user requests and multiple execute nodes running actual tasks. In our approach, a user can submit tasks to the front-end node and multiple execute nodes regularly measure node resource status and report measured data to the front-end node. If resources are available, the front-end node dispatches tasks from a queue in accordance with FIFO, round-robin, priority-based preemptive or other scheduling algorithm and match-makes them with available resources for resource allocation. Upon completion of resource allocation, files needed for actual task execution are transferred to execute nodes. Execute nodes receive tasks to be executed from the front-end node and run application programs based on container-based virtualization layer. Execution results are transferred back to the front-node that submitted the tasks initially and forwarded to a user.
3.2 Implementation
In our implementation case, HTCondor was used as a job and resource scheduler and docker for container-based virtualization.
3.2.1 HTCondor daemons
In HTConodr pool, each machine can serve a variety of roles. Then, different daemons are running on the machine based on the role [11]. For the sake of simplicity, we focus on the six essential daemons in this paper.
• SCHEDD: This daemon takes responsibility for re-source requests to the HTCondor pool. For this, it advertises the status of job queue and claims available resources to serve those requests.
• STARTD: This daemon takes responsibility for resource management of execute node. It advertises certain at-tributes about the execute node and is responsible for enforcing the policy that the resource owner configures. • COLLECTOR: It collects all the information about the status of an HTCondor pool. All other demons periodically send ClassAd2 updates to COLLECTOR.
2ClassAd is a scheme-free resource allocation language to represent arbitrary services and constraints on their allocation [18]
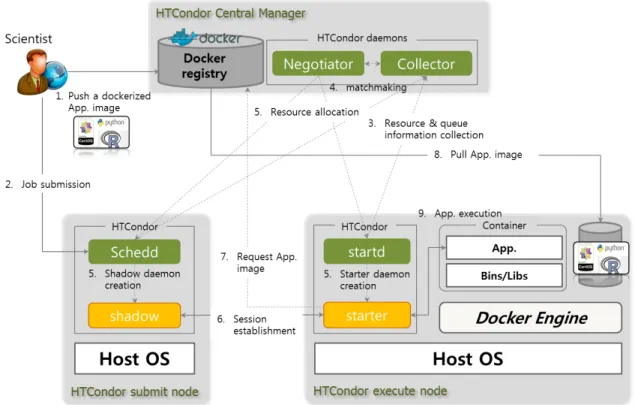
Fig. 2: Container-based cluster management platform implementation.
These ClassAds contain the state of the daemons, the resources, and the queue in the HTCondor pool. • NEGOTIATOR: It is responsible for the match making
in the HTCondor pool. Specifically, it contacts each SCHEDD that has waiting resource request and allocate available resources to those requests.
• SHADOW: It acts as the resource manager for the request. For example, Jobs that are linked for standard universe perform remote system call using this daemon. It runs on the machine where a job was submitted. • STARTER: It sets up the execution environment and
monitors the running job.
3.2.2 Implementation using HTCondor and Docker
Table 1: Hardware and software specifications.
Hardware spec.
CPU Intel(R) Xeon(R) CPU
[email protected] * 2ea
Memory 32GB
HDD Western Digital WD 500GB 7200 RPM Software spec.
OS CentOS release 6.5 Final
Job & resource
scheduler HTCondor 8.0.7
Container-based
virtualization Docker 1.1.2
Image management Docker-registry server (dev) 0.8.0
Table 1 shows the hardware and software specifications of the system used herein. First of all, as shown in Fig. 2, a scientist creates a dockerized application image in advance for running his scientific workflow, pushes it to the docker registry, and creates a shell script file (launch_docker.sh) to launch dockerized application in execute nodes. Caution needs to be taken when a file to be used as argument must be forwarded into the container. To this end, the working directory of the host where execution file reside has to be mounted into the container, using–voption of the docker as follow:
Table 2: launch_docker.sh. #!/bin/bash
sudo docker run -v $(pwd):/data docker_image /data/execute_file
To submit the shell script prepared in this manner to the HTCondor scheduler, a HTCondor job description file (Table. 3 is an example of job script) is created and submitted to the HTCondor SCHEDD. In the case of HTCondor, STARTD daemon reports the resource status of executable machines and SCHEDD daemon reports the job queue status to COLLECTOR daemon in ClassAd format at regular interval [11]. NEGOTIATOR match-makes job ClassAd and resource ClassAd based on data collected by COLLECTOR
to determine execute machine where tasks are to be executed. Once execute host to run tasks is determined via the match-making by NEGOTIATOR, SCHEDD and STARTD launch SHADOW and STARTER respectively, then a session is established between the two launched daemons. Through this session,launch_docker.shfile and argument files required for execution are transferred to the execute host and STARTER executes script file. At this time, STARTER daemon checks if dockerized application image is available in the local host where STARTER daemon is run and, if not available, pulls the dockerized image by the user in advance from the docker registry to execute dockerized application. Upon task completion, result files are transferred to submit node via SHADOW daemon and the user can confirm the results at submit node to which task was submitted.
Table 3: An example of HTCondor job script. universe = vanilla
executable = launch_docker.sh output =output file
transfer_input_files =execute_file queue 100
Utilizing HTCondor and docker in this fashion brings about two advantages as follows. First, it is possible to implement with ease a container-based cluster management platform proposed. Secondly, such approach is applicable to a multi-cluster system like PLSI since HTCondor ensures that multiple cluster resources are utilized for a single scientific workflow.
4. Evaluation
This section analyzes the performance of docker, a container-based virtualization approach, and evaluates the performance of cluster system implemented on HTCondor and docker.
4.1 Micro-Benchmarks
Two widely known benchmark tools, unixbench and sys-bench, were used to measure the performance of docker with the following measurement results:
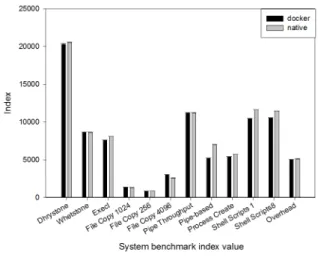
• unixbench: The unixbench is a benchmark tool designed to measure overall system performance and provide a variety of benchmark results such as Whetstone, Drystone, file copy, pipe throughput, etc. Fig. 3 shows the index values of each item measured by unixbench tool. The index values of docker for all items except for the pipe-based context switching are found to be 90% or more when compared to the native performance. Pipe-based context switching test measures system perfor-mance by increasing integer through a pipe. The pipe-based context switching test is more like a real-world
Fig. 3: unixbench benchmark results.
Fig. 4: The system benchmark index score.
application [19]. In this value, docker shows 75% of the native performance. Fig. 4 shows the system benchmark index scores measured at 5699.5 and 5492.7 for native performance and docker shows its performance at 96% when compared to the native performance.
• sysbench: The sysbench is a tool using a variety of scenarios to measure CPU, memory, and File I/O per-formance results. Table 4 shows the benchmark results. First item shows CPU time taken to process 10,000 events of arithmetic operations using decimal fractions. It is confirmed that docker and native performances are identical. Second item shows sequential or random memory I/O performance in an assigned memory buffer and docker is measured to be better than native per-formance by 3% ∼ 5%3. Last item shows sequential
or random file I/O performance results using 128 GB test files created in local disk. Form Table. 4, it can be
3This benchmark results conflict with our intuitive understanding. The analysis of this problem should be explored in the near future.
confirmed that docker is found to show performance almost identical to native performance.
When the unixbench and sysbench measurements are compared in this section, docker is found to show no significant performance decline in comparison with native performance. Many studies conducted recently also show that container-based virtualization technology has a near-native performance [9].
Table 4: Sysbench benchmark results.
Test item Option Docker Native CPU Total time 24.5 sec 24.5 sec
Memory
Sequence write 2.21 GB/sec 2.14 GB/sec Random write 3.41 GB/sec 3.25 GB/sec Sequence read 3.82 GB/sec 3.63 GB/sec Random read 3.67 GB/sec 3.50 GB/sec File I/O
Sequence write 104.8 MB/sec 105.2 MB/sec Sequence read 91.7 MB/sec 91.7 MB/sec Combined R/W 1.5 MB/sec 1.5 MB/sec
4.2 Macro-Benchmarks
Fig. 5: The container-based cluster management system using docker and HTCondor.
This section presents the performance measurements of a cluster system implemented on docker and HTCondor for supporting scientific workflows. First of all, as illustrated in Fig. 5, HTCondor pool consisting of 1 central manager node and 3 execute nodes in accordance with the hard ware specification in Table 1 was configured. In addition, a docker registry was installed in the central manager node and docker clients in the execute nodes.
To measure the performance of the system implemented in this manner, a program to calculatePiwith a Monte-Carlo technique was implemented using C, JAVA, Python, and R. It picks points at random inside the square 10,000,000 times and checks to see if the point is inside the circle. Then, a simulation workflow to run the implemented program
100 times to reduce errors was created and submitted to HTCondor scheduler to compare execution time.
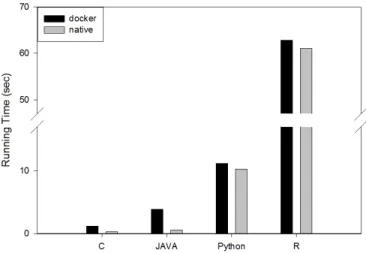
Fig. 6: Monte-Carlo simulation results (100 times). Fig. 6 shows the Monte-Carlo simulation results with and without docker. As the figure confirms, difference in docker and native execution times is shown, depending on implemented languages. Namely, when executed with docker, execution time significantly increased 3.2 and 3.6 folds when compared to native performance in the cases of C and JAVA respectively while it increased only by 18% and 9% respectively in the cases of Python and R. The biggest factor underlying such difference is that in a simulation using docker, image loading time is different among implementation languages.
Fig. 7: Monte-Carlo simulation results (1 time). Fig. 7 shows one simulation execution time of docker and native status. To exclude the possibility of image transfer
time, the dockerized image had been pulled in advance on each execute host. As the figure shows, execution time increased by 8% and 2% respectively in the cases of python and R while it rose very significantly 3.9 and 6.9 folds respectively in the cases of C and JAVA.
5. Conclusion
In this paper, we presented a container-based cluster man-agement platform to provide a service environment desired by users. To provide a dynamic service environment, the virtualization technology is widely used. However, due to the inevitable overhead of hypervisor-based virtualization, container-based virtualization technologies such as Linux VServer, OpenVZ, and LXC are utilized recently. In this pa-per, we introduced an implementation case in which docker and HTCondor are interlocked. In addition, we conducted micro-benchmarks using unixbench and sysbench for CPU, memory, and file I/O performance and macro-benchmarks using Monte-Carlo simulation workflow for the performance of cluster system. Our results showed that docker had a near-native performance and image loading time is different among implementation languages.
References
[1] E. Deelman, D. Gannon, M. Shields, and I. Taylor, “Workflows and e-science: An overview of workflow system features and capabilities,”
Future Generation Computer Systems, vol. 25, no. 5, pp. 528–540, 2009.
[2] Y. Gil, E. Deelman, M. Ellisman, T. Fahringer, G. Fox, D. Gannon, C. Goble, M. Livny, L. Moreau, and J. Myers, “Examining the challenges of scientific workflows,”IEEE Computer, vol. 40, no. 12, pp. 24–32, Dec 2007.
[3] K. Chen, J. Xin, and W. Zheng, “Virtualcluster: Customizing the cluster environment through virtual machines,” inProc. of IEEE/IFIP International Conference on Embedded and Ubiquitous Computing, 2008, vol. 2, Dec 2008, pp. 411–416.
[4] P. Ruth, P. McGachey, and D. Xu, “Viocluster: Virtualization for dynamic computational domains,” in Proc. of IEEE International Cluster Computing, 2005, Sept 2005, pp. 1–10.
[5] M. A. Murphy, B. Kagey, M. Fenn, and S. Goasguen, “Dynamic provisioning of virtual organization clusters,” in Proc. of the 9th IEEE/ACM International Symposium on Cluster Computing and the Grid, Washington, DC, USA, 2009, pp. 364–371.
[6] P. Marshall, K. Keahey, and T. Freeman, “Elastic site: Using clouds to elastically extend site resources,” inProc. of the 10th IEEE/ACM International Conference on Cluster, Cloud and Grid Computing, Washington, DC, USA, 2010, pp. 43–52.
[7] N. Regola and J.-C. Ducom, “Recommendations for virtualization technologies in high performance computing,” in Proc. of IEEE Second International Conference on Cloud Computing Technology and Science (CloudCom), Nov 2010, pp. 409–416.
[8] S. Soltesz, H. Pötzl, M. E. Fiuczynski, A. Bavier, and L. Peterson, “Container-based operating system virtualization: A scalable, high-performance alternative to hypervisors,” SIGOPS Oper. Syst. Rev., vol. 41, no. 3, pp. 275–287, Mar. 2007.
[9] M. Xavier, M. Neves, F. Rossi, T. Ferreto, T. Lange, and C. De Rose, “Performance evaluation of container-based virtualization for high performance computing environments,” in Proc. of 21st Euromicro International Conference on Parallel, Distributed and Network-Based Processing (PDP), 2013, Feb 2013, pp. 233–240.
[10] “Docker.” [Online]. Available: www.docker.com
[11] D. Thain, T. Tannenbaum, and M. Livny, “Distributed computing in practice: the condor experience.” Concurrency - Practice and Experience, vol. 17, no. 2-4, pp. 323–356, 2005.
[12] “PLSI: Partnership & leadership for the nationwide supercomputing infrastructure.” [Online]. Available: http://www.plsi.or.kr
[13] E. Walker, “Benchmarking amazon EC2 for high-performance scien-tific computing,”LOGIN, vol. 33, pp. 18–23, 2008.
[14] Q. He, S. Zhou, B. Kobler, D. Duffy, and T. McGlynn, “Case study for running HPC applications in public clouds,” in Proc. of the 19th ACM International Symposium on High Performance Distributed Computing. New York, NY, USA: ACM, 2010, pp. 395–401. [15] K. Jackson, L. Ramakrishnan, K. Muriki, S. Canon, S. Cholia, J. Shalf,
H. J. Wasserman, and N. Wright, “Performance analysis of high performance computing applications on the amazon web services cloud,” inProc. of IEEE Second International Conference on Cloud Computing Technology and Science (CloudCom), Nov 2010, pp. 159– 168.
[16] A. Iosup, S. Ostermann, M. N. Yigitbasi, R. Prodan, T. Fahringer, and D. H. Epema, “Performance analysis of cloud computing services for many-tasks scientific computing,”IEEE Transactions on Parallel and Distributed Systems, vol. 22, no. 6, pp. 931–945, 2011.
[17] “NERSC: National energy research scientific computing center.” [Online]. Available: https://www.nersc.gov
[18] R. Raman, M. Livny, and M. Solomon, “Matchmaking: distributed resource management for high throughput computing,” inProc. of The Seventh International Symposium on High Performance Distributed Computing, 1998., Jul 1998, pp. 140–146.
[19] “Unixbench.” [Online]. Available: https://code.google.com/p/byte-unixbench/