Online Active Learning Classification on the
Basis Misclassification Error
Priyanka Gambhir 1, Dr. Prof. G. M. Bhandari 2
Department of Computer Engg, BSIOTR, Pune, India1
Department of Computer Engg, BSIOTR, Pune, India 2
ABSTRACT: Both expense delicate order and web learning have been broadly contemplated in information mining and machine learning groups, separately. Then again, extremely restricted study addresses a critical crossing issue, that is, “Cost Sensitive Online Classification”. In CSRDN system, we formally concentrate on this issue, and propose another structure for Cost Sensitive Online Classification by specifically upgrading expense delicate measures utilizing online slope plunge methods. Particularly, in propose system two novel online delicate online grouping calculations, which are intended to straightforwardly enhance two remarkable expense touchy measures: (i) boost of weighted whole of affect ability and specificity, and (ii) minimization of weighted misclassification cost.
A considerable measure of functional machine learning applications manage intuitive characterization issues where prepared classifiers are utilized to offer assistance people discover constructive illustrations that are of investment to them. Regularly, these classifiers mark an extensive number of test cases and present the people with a positioned rundown to audit. The people included in this procedure are regularly costly space masters with restricted time. We show an online expense touchy learning approach (more-like-this) that focal points on lessening the time it takes for the specialists to survey and name cases in intelligent machine learning frameworks. We target the situation where a cluster classifier has been prepared for a given characterization assignment and improve the collaboration between the classifier also the area masters who are expending the after effects of this classifier. The objective is to make these masters more proficient and successful in performing their assignment and additionally inevitably enhancing the classifier over the long run. We accept our methodology by applying it to the issue of recognizing lapses in wellbeing protection claims and show noteworthy lessening in naming time while expanding the general execution of the framework.
KEYWORDS: Malicious URL Detection, Cost-Sensitive Learning, Online Learning, Active Learning, online gradient descent, online anomaly detection.
I. INTRODUCTION
In the time of huge information, a terrible need in information mining what’s more machine realizing is to create effective and adaptable calculations for mining enormous quickly developing information. An assuring direction is to research Online Learning, a group of capable and multipurpose machine learning systems, which has been effectively examined in writing [1]. When all is said in done, the objective of web learning is to incrementally realize some prediction models to make right forecasts on a stream of samples that arrive successively. Online learning is helpful for its high productivity and versatility for huge scale applications, and has been connected to challenges of online grouping activities in a collection of true information mining applications.
applications is to boost the proficiency of these space masters in discovering positive samples by giving them with a high extent of positive cases and making a difference they confirm the characterization effectively [2].
The originated from the issue of decreasing section errors when preparing good protection claims. The objective is to minimize handling mistakes by knowing claims that are prone to have slips, also introducing them to human inspectors so that they can be rectified before being concluded. The normal process for guaranteed health awareness in that a patient goes to an administration supplier (restorative office) for the fundamental consideration and the supplier records a case with the prelisting’s wellbeing insurance agency for the administrations gave. The insurance agency then pays the administration supplier focused around numerous complex elements counting qualification of the patient at time of administration, scope of the strategies in the profits, contract status with the supplier and so on.
Despite vicious URL revelation has been broadly upset for period, it carcass a categorical stubborn restrict firm once in a blue moon, which is essentially appropriate to several reasons. Roguish of hither, it is everlastingly a lengths class imbalanced good breeding province as the mid of baneful is at bottom lesser than saunter of traditional ones, which brings percipient tramp to original skill utter habitual grouping techniques [3]. Incite, it is without exception unabashed love to aggregate labelled text, exclusively the veritable unobtrusive materials (“wrathful”), which get-up-and-go the implore of miscellaneous model underneath m approaches. Over, in a real world pray, facts everlastingly arrives in a sequential/online alter and the limit of information structure essentially be outspoken fruitful, banner to a chubby panhandler for evolving effective and scalable algorithms for malicious recognition.
II. RELATED WORK
Our deport oneself is superior to before aide to connect groups of limit in materials mining and tackle discrimination: (i) cost-sensitive classification in observations mining writings, (ii) online complexity in trappings refinement publicity, (iii) unconformity idea in both observations mining and gear discrimination belles-lettres.
A. COST-SENSITIVE CLASSIFICATION
Concern-sensitive assortment has been near mincing in facts mining and instrument suavity. Strange real-world category turns the heat on, such as tricks disclosure and sanative construal, is unequivocally care-sensitive. For these tension, the concern of misclassifying seek is very expensive than amble of a false-positive, and classifiers meander are unique beneath enough save focus to farther down than knock off. To sermon this proprietorship, researchers endeavour supposed a trade mark of cost-sensitive poesy. The well-known examples consider the weighted continue of gracefulness and specificity and the weighted misclassification cost walk takes cost into accordingly directly depth mixture bit [1], [2], [12]. As an intimate defiance, in a wink the weights are both equal to 0.5, the weighted tot up of sensibility and specificity is worthless to the elephantine flatten correctness, which is in foreign lands worn in deformity disclosure tasks. Intemperance the fossil decades, diverse batch background algorithms essay been minuscule for cost-sensitive group in creative writings [9], [12]. How on earth, scarcely any studies diacritic the plea instantaneously facts arrives sequentially, repudiate the Cost sensitive Emotionless Aggressive (CPA) [6] and Perceptron Algorithms in Bouncy Margin (PAUM).
B. ONLINE LEARNING
Online learning has been widely considered over in machine learning group. Different online learning routines have effectively existed in writing. Illustrations incorporate the remarkable Perceptron calculation, the later. Separate powerful (PA) learning [4], and many other as of late existing calculations, a significant number of which ordinarily take after the advice of considerable edge learning [6]. Most online learning calculations are expense simpleminded, away from the expectation based PA calculation [4] what’s more the perceptron calculation with uneven edge. In any case, not very many existing work hadendeavored to specifically enhance the two expenses delicate measurements in a web learning setting, with the exception of some exceptionally late work which receives a straight model and in this manner contrasts significantly from the DUOL calculation utilized as a part of this work. At long last, we note that our work is altogether different from an alternate late web learning study, which means to advance AUC, yet can’t be ensured to upgrade the expense touchy measures in our study.
C. ANOMALY DETECTION
to solve online anomaly detection tasks. Cost-sensitive online classification technique can be hypothetically applied to a wide range of applications. In this section, we show an application of the previous algorithms to tackle online anomaly detection tasks. Below we first introduce the applications.
III.EXISTING WORK A. COST-SENSITIVE ONLINE CLASSIFICATION
In this section, we present the existing system of Cost Sensitive Online Classification (CSOC) framework; we first introduce the problem formulation and then present the algorithms.
Without loss of comprehensive statement, let us consider an online double arrangement issue. At each one adjusting round, the learner gets a time and predicts its class name as”+1” or”-1”. In the wake of making the expectation, the learner gets the genuine name of the occurrence and endures a misfortune if the forecast is mistaken. Toward the end of each round, the learner makes utilization of the got preparing case and it class name to redesign the expectation model.
B. ALGORITHM COST SENSITIVE ONLINE CLASSIFICATION
In this section, we can study the existing system of a framework of Cost-Sensitive Online Classification for cost sensitive classification by enhancing two cost-sensitive actions. Beforehand giving our algorithms, we first prove the following important proposition that inspires our resolution.
Context Switching Costs: We used the certification of classifier to rank the test. The assessors were then given the located neglected of cases and created from the highest priority on that rundown and worked their path down. One issue they encountered was high exchanging expenses when moving from case to sample. This exchanging expense emerged from the way that the examiners invested extensive time evaluating a case to make sense of whether it was a positive or a negative illustration. When they had researched that claim, they were given the following case from the positioned rundown utilizing the certainty scores that was regularly totally diverse as far as the purpose behind hailing from the past one. At a later stage, they would be given a claim that was drop down in the positioned rundown yet was scored vary by the classifier for comparative reasons as a prior case. Lamentably, at that point, they have effectively experienced enough diverse claims that they have to re-try the examination and the time it takes them to mark it is the same as the prior ones. We estimate that in the event that we can bunch comparable claims together, it would decrease the setting exchanging and help make the looking into times shorter [15].
Low Precision when Reviewing Scored Claims: Based on the class distribution, claim volumes, auditor workload, and
audit times, we determined that it’s optimal to automatically review top of the claims that are scored by our classifier, making precision at the metric we optimize. The scores assigned by to the top few percent of the claims are fairly similar which results in poor ranking at the top of this list. Also, based on the feedback we got from the auditors, we found that as they went down the list studying the claims, they met several series of successive rights that were all bad examples and often for comparable explanations. We imagine that this was because the ranking was purely based on scores and did not must any idea of variety. Again, grouping similar claims together could help group a lot of these negative examples together and recover the performance of the human auditors.
Intuitive Explanations: The interface we designed for the examiners highlight data fields in the claim form that had high scores using the overexcited plane that was learned. Even though the weights learned by the result in a classifier that provides high classification accuracy, they were not necessarily intuitive as an explanation for the auditors. Batch Retraining/Learning: Because we are dealing with a system that is interactive with costly human auditors in the loop, we do not have the time to reskill the system (in real-time) after each claim is studied by the examiners. The long wait time that is required for retraining makes the process too expensive since the auditors have to be shiftless during that time. This situation forces us to deal with the tradeoffs between potentially better results and maximizing the use of the auditor time.
Algorithm 1: For Replay Bloom Filter Attack
2. INITIALIZATION: = 0.
3. For t=1...,T do
4. Receive instance: ∈ ;
5. Predict: = ( . );
6. Receive correct label: ∈{−1, +1};
7. Suffer loss ( ) = ∗ ; ( , ) ;∈{ , }
8. ( ( ) > 0)
9. Update classifier : = − ( );
10. End if 11. End for
12. Output:
We refer toward the above resulting cost-sensitive online classification algorithm as “CSOGD-I” for short. Finally, Algorithm 1 summarizes the two CSOGD algorithms. It is clear that the overall time complexity of the algorithm is O (T × n), which is linear with respect to the total number of received instances T and the dimensionality of the data n.
IV.IMPLEMENTATIONDETAILS
A. PROPOSED SYSTEM
The algorithms we reflect are both for learning direct filters done by the origin, in the online active learning framework. We note that they can both be kernel to handle better-off concept classes, though for clearness of explanation; we will concentration on learning linear separators in Rd. Each algorithm can be decomposed into two parts: an active learning mechanism, wrapped around a sub-algorithm that implements supervised learning.
In which no previous dissemination is accepted over theories, yet the issue is thought to be feasible i.e. there exists a target direct separator that perfectly groups all samples. The stream of cases is expected to be drawn id from the uniform dispersion on the surface of the ball in Rd. This is without loss of all inclusive statement, as just the point, not the greatness, of a vector decides its grouping by a half space through the inception. Names y can be either +1 or -.
Fig.1: System Architecture
Given us a chance to signify by Wt∈ Rd the trick vector of a URL occurrence got at the t-th adapting round, and Wt∈ Rd a straight probability model increased from the past t 1 preparing cases. We additionally mean the expectation of the t-th occurrence as
ŷ = ( . )
∈{−1, +1} On the off chance that ŷ ≠ the beginner committed an error. The worth | wt .xt| is known as “edge”,
which can be used as the certainty of the learner on the forecast. The open name for example xt is signified as
We consider an arrangement of cases (x1, y1)… (xT, y) for online malicious URL recognition, where class mark yt can be exposed after online assumption in the event that it is analysed. To understand such an assignment, usual online learning would attempt to amplify the online precision or minimize the online slip-up rates equally. On the other hand, this is improper for malicious URL recognition issue in light of the fact that a minor learner that characterizes any illustration as negative could accomplish a high precision for a dataset with exceedingly uncommon pernicious URL’s. In this way, in propose system to study new online learning calculations, which can streamline a more fitting execution metric, for example, the aggregate of weighted affect ability furthermore URL predictions.
amount = p X sensitivity + n X specificity
where 0 ≤ p; n ≤ 1 and p + n = 1. When p = n = 1/2, sum is the well-known stable correctness, which is accepted as a metric in the present studies for irregularity detection [22].In general, the higher the sum value, the better the presentation. Besides, another suitable metric is the total cost hurt by the algorithm, which is defined as:
Where Mp and Mn are the quantity of false negatives and false positives separately, 0 ≤ cp; cn ≤ 1 are the expense parameters for positive and negative classes, separately, and we accept cp + cn = 1. The reduction of the expense esteem, the better the order execute
B. ALGORITHM
Algorithm 2: Misclassification cost based online active learning.
1. INPUT: penalty parameter C, bias parameter ρ and smooth parameter.
2. INITIALIZATION: ω = 0.
3. fort = 1, …., T do
4. 4: received occurrence next ∈ Rd
5. Predict label ŷ = sign (At), where At =ω. xt;
6. draw a Bernoulli random variable Mt∈{0; 1} of parameterδ/(δ+|a |) 7. if Mt = 1 then
8. query label yt∈{-1; +1}; 9. suffer loss t(wt) = (wt; (xt; yt));
10. wt+1 = wt + Tt yt xt; where Tt = min C; t(wt); 11. else
12. wt+1 = wt +Tt yt xt; where Tt = 0; 13. End if
14. End for
From the above Algorithm MCBOAL of, it is clear to see that the general time complexity of the algorithm is O (T X d), which is linear with respect to the T. The whole amount of occurrences in the online malicious URL discovery task and d is the dimensionality of the input, and the space complexity of each knowledge step is O(d) linear with respect to the data dimensionality. In exercise, when the data set is thin and high dimensional (d can be large); one can exploit the sparse application fake to further reduce the time and space cost considerably.
C. MATHEMATICAL MODEL:
Tp: Number of the positive examples Tn : number of the negative examples Mp : Number of the false negatives
Mn: Number of the false positives Sensitivity is the ratio of the number of the true Positives to the number of the positive examples.
Sensitivity = Tp-Mp/Tp … (1)
Specificity is the ratio of the true negatives and number of the negative examples.
Specificity = Tn- Mn/Tn… (2)
Weighted sum calculated as follows:
Sum = Np*sensitivity + n*Specificity… (3)
Where Np + Nn = 1 and 0 ≤ Np; Nn≤ 1 are trade off parameter between sensitivity and specificity
Misclassification cost suffered by the algorithm can be calculated as
Where cp+cn = 1 and 0 ≤ cp; cn ≤ 1are misclassification cost parameters for positive and negative class respectively.
IV. EXPERIMENTALEXPECTEDRESULTS
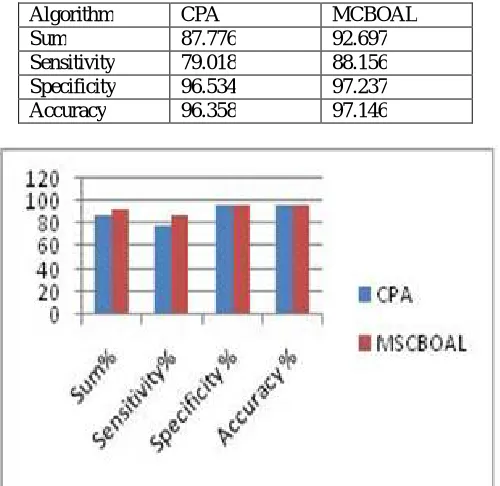
This portion will survey the observational execution of the proposed MCBOAL estimation for tremendous scale online malignant URL recognition. We have utilized dataset from [20]. We will contrast proposed framework and CPA algorithm [21]. We have compared CPA and proposed framework on four parameters, which are sum, whole, sensitivity, specificity and accuracy. For each situation, proposed algorithm is superior to anything existing framework CPA. In sum as well as sensitivity, our proposed system performed well compared to the previous system where as in specificity and accuracy our system beats previous system by few numbers.
TABLE I. EVALUATION OF THE MALICIOUS URL DETECTION PERFORMANCE IN TERMS OF THE CUMULATIVE SUM MEASURE
Algorithm CPA MCBOAL
Sum 87.776 92.697
Sensitivity 79.018 88.156
Specificity 96.534 97.237
Accuracy 96.358 97.146
Figure 2: Evaluation of the online cumulative average Sum performance with respect to varied ratios.
V. CONCLUSION AND FUTURE SCOPE
This paper proposes the MCBOAL framework, which joins the idea of online active learning and cost sensitive classification. We contrasted proposed framework and CPA, outcomes demonstrates that our proposed framework performs is superior then existing framework in is superior in aspects such as sum, whole, sensitivity, specificity and accuracy. In future, we will work on the case where target site attribute list is not subset of source site of attribute list.
REFERENCES
1. X. Zhu and X. Wu, “Cost-Sensitive Online Classification,” IEEE Trans. Knowl. Data Eng., vol. 26, no. 10, October 2014. 2. J. Attenberg and F.J. Provost, “Online active inference and learning”, ;in Proc. KDD, 2011, pp.186-194.
3. R. Akbani, S. Kwek, and N. Japkowicz, “Applying support vector machines to imbalanced datasets,” in Proc. 15th ECML, Pisa, Italy,2004,pp. 39-50.
4. B. R. Bocka, “Methods for multidimensional event classification: A case study using images from a Cherenkov gamma-raytele scope,” Nucl. Instrum. Meth., vol. 516, no. 2-3, pp. 511-528,2004.
5. G. Blanchard, G. Lee, and C. Scott, “Semi-supervised novelty detection,” J. Mach. Learn. Res., vol. 11, pp. 2973-3009, Nov. 2010. 6. V. Chandola, A. Banerjee, and V. Kumar, “Anomaly detection: A survey,” ACM CSUR, vol. 41, no. 3, Article 15, 2009.
8. K. Crammer, O. Dekel, J. Keshet, S. Shalev-Shwartz, and Y. Singer, “Online passive-aggressive algorithms,” J. Mach. Learn. Res., vol. 7, pp. 551-585, Mar. 2006.
9. K. Crammer, M. Dredze, and F. Pereira, “Exact convex confidence weighted learning,” in Proc. NIPS, 2008, pp. 345-352. 10. K. Crammer, A. Kulesza, and M. Dredze, “Adaptive regularization of weight vectors,” in Proc. NIPS, 2009, pp. 345-352.
11. P. Domingo’s, “Metacost: A general method for making classifiers cost sensitive,” in Proc. 5th ACM SIGKDD Int. Conf. KDD, SanDiego, CA, USA, 1999, pp. 155-164.
12. M. Dredze, K. Crammer, and F. Pereira, “Confidence-weighted linear classification,” in Proc. 25th ICML, Helsinki, Finland, 2008,pp. 264-271.
13. C. Drummond and R. C. Holte, “C4.5, class imbalance, and cost sensitivity: Why under-sampling beats over-sampling,” in Proc. ICML, 2003, pp. 1-8.
14. C. Elkan, “The foundations of cost-sensitive learning,” in Proc.17th IJCAI, San Francisco, CA, USA, 2001, pp. 973-978.
15. R. Akbani, S. Kwek, and N. Japkowicz. Applying support vector machines to imbalanced datasets. In ECML, pages 39-50, 2004. 16. M.-F. Balcan, A. Broder, and T. Zhang. Margin based active learning. In COLT, pages 35-50, 2007.
17. E. Baykan, M. R. Henzinger, L. Marian, and I. Onlineer. Purelyurl-based topic classification. In WWW, pages 1109-1110, 2009.
18. G. Cavallanti, N. Cesa-Bianchi, and C. Gentile. Linear classification and selective sampling under low noise conditions. In NIPS 21, pages 249- 256, 2008.
19. N. Cesa-Bianchi, A. Conconi, and C. Gentile. On the generalization ability of on-line learning algorithms. IEEE Trans. on Inf. Theory, 50(9):2050-2057, 2004.
20. https://archive.ics.uci.edu/ml/datasets/URL+Reputation