From Chunks to Function-Argument Structure: A Similarity-Based
Approach
Sandra K ¨ubler and Erhard W. Hinrichs
Seminar f¨ur Sprachwissenschaft University of T¨ubingen D-72074 T¨ubingen, Germany
kuebler,eh @sfs.nphil.uni-tuebingen.de
Abstract
Chunk parsing has focused on the recognition of partial constituent struc-tures at the level of individual chunks. Little attention has been paid to the question of how such partial analyses can be combined into larger structures for complete utterances. Such larger structures are not only desirable for a deeper syntactic analysis. They also constitute a necessary prerequisite for assigning function-argument structure.
The present paper offers a similarity-based algorithm for assigning func-tional labels such as subject, object,
head, complement, etc. to complete
syntactic structures on the basis of pre-chunked input.
The evaluation of the algorithm has concentrated on measuring the quality of functional labels. It was performed on a German and an English treebank using two different annotation schemes at the level of function-argument struc-ture. The results of 89.73 % cor-rect functional labels for German and 90.40 % for English validate the general approach.
1 Introduction
Current research on natural language parsing tends to gravitate toward one of two extremes: robust, partial parsing with the goal of broad
data coverage versus more traditional parsers that aim at complete analysis for a narrowly defined set of data. Chunk parsing (Abney, 1991; Ab-ney, 1996) offers a particularly promising and by now widely used example of the former kind. The main insight that underlies the chunk pars-ing strategy is to isolate the (finite-state) analysis of non-recursive syntactic structure, i.e. chunks, from larger, recursive structures. This results in a highly-efficient parsing architecture that is realized as a cascade of finite-state transducers and that pursues a leftmost longest-match pattern-matching strategy at each level of analysis.
Despite the popularity of the chunk parsing ap-proach, there seems to be a gap in current re-search:
Chunk parsing research has focused on the recognition of partial constituent structures at the level of individual chunks. By comparison, lit-tle or no attention has been paid to the ques-tion of how such partial analyses can be com-bined into larger structures for complete utter-ances. Such larger structures are not only de-sirable for a deeper syntactic analysis; they also constitute a necessary prerequisite for assigning function-argument structure.
Automatic assignment of function-argument structure has long been recognized as a desider-atum beyond pure syntactic labeling (Marcus et al., 1994)1. The present paper offers a
similarity-1
based algorithm for assigning functional labels such as subject, object, head, complement, etc. to complete syntactic structures on the basis of pre-chunked input. The evaluation of the algo-rithm has concentrated on measuring the quality of these functional labels.
2 The T ¨uSBL Architecture
In order to ensure a robust and efficient archi-tecture, T ¨uSBL, a similarity-based chunk parser, is organized in a three-level architecture, with the output of each level serving as input for the next higher level. The first level is part-of-speech (POS) tagging of the input string with the help of the bigram tagger LIKELY (Feldweg, 1993).2 The parts of speech serve as pre-terminal ele-ments for the next step, i.e. the chunk analysis. Chunk parsing is carried out by an adapted ver-sion of Abney’s (1996) CASS parser, which is realized as a cascade of finite-state transducers. The chunks, which extend if possible to the sim-plex clause level, are then remodeled into com-plete trees in the tree construction level.
The tree construction level is similar to the DOP approach (Bod, 1998; Bod, 2000) in that it uses complete tree structures instead of rules. Contrary to Bod, we only use the complete trees and do not allow tree cuts. Thus the number of possible combinations of partial trees is strictly controlled. The resulting parser is highly efficient (3770 English sentences took 106.5 seconds to parse on an Ultra Sparc 10).
3 Chunking and Tree Construction
The division of labor between the chunking and tree construction modules can best be illustrated by an example.
For sentences such as the input shown in Fig. 1, the chunker produces a structure in which some constituents remain unattached or partially anno-tated in keeping with the chunk-parsing strategy to factor out recursion and to resolve only unam-biguous attachments.
Since chunks are by definition non-recursive structures, a chunk of a given category cannot
fully automatic recognition of functional labels.
2
The inventory of POS tags is based on the STTS (Schiller et al., 1995) for German and on the Penn Treebank tagset (Santorini, 1990) for English.
Input: alright and that should get us there about
nine in the evening
Chunk parser output:
[uh alright] [simpx_ind
[cc and]
[that that]
[vp [md should] [vb get]]
[pp us]
[adv [rb there]] [prep_p [about about]
[np [cd nine]]] [prep_p [in in]
[np [dt the]
[daytime evening]]]]
Figure 1: Chunk parser output.
contain another chunk of the same type. In the case at hand, the two prepositional phrases (’prep p’) about nine and in the evening in the chunk output cannot be combined into a sin-gle chunk, even though semantically these words constitute a single constituent. At the level of tree construction, as shown in Fig. 2, the prohibition against recursive phrases is suspended. There-fore, the proper PP attachment becomes possible. Additionally, the phrase about nine was wrongly categorized as a ’prep p’. Such miscategoriza-tions can arise if a given word can be assigned more than one POS tag. In the case of about the tags ’in’ (for: preposition) or ’rb’ (for:
ad-verb) would be appropriate. However, since the
POS tagger cannot resolve this ambiguity from local context, the underspecified tag ’about’ is as-signed, instead. However, this can in turn lead to misclassification in the chunker.
alright
UH
and
CC
that
DT
should
MD
get
VB
us
PP
there
RB
about
RB
nine
CD
in
IN
the
DT
evening
NN
− − HD HD HD − −
PR−DM HD
DT−ART HD DTP
SPR HD
HD
NP COMP
ADVP ADJ
CNUM HD
PP ADJ HD
NP COMP
ADVP ADJ
NP ADJ
NP
SBJ HD
VP COMP
CNJ −
S −
0 1 2 3 4 5 6 7 8 9 10 11
500 501 502 503 504 505 506
507 508
509 510 511
512 513
[image:3.612.82.511.18.185.2]514 S
Figure 2: Sample tree construction output for the sentence in Fig. 1.
subject of the whole sentence. The label ADJ above the phrase about nine in the evening signi-fies that this phrase is an adjunct of the verb get.
T ¨uSBL currently uses as its instance base two semi-automatically constructed treebanks of Ger-man and English that consist of appr. 67,000 and 35,000 fully annotated sentences, respectively3.
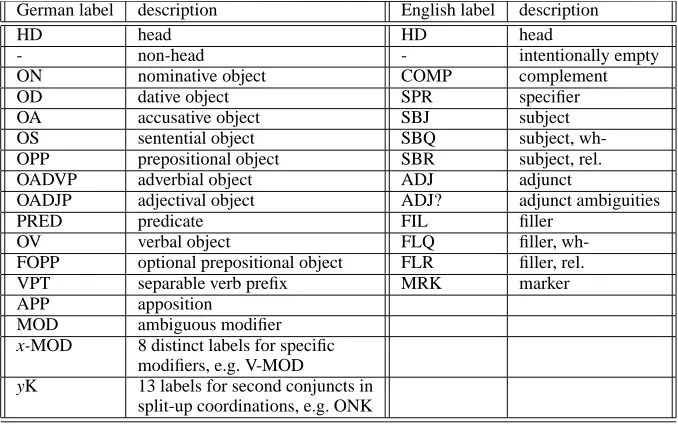
Each treebank uses a different annotation scheme at the level of function-argument structure4. As shown in Table 1, the English treebank uses a to-tal of 13 functional labels, while the German tree-bank has a richer set of 36 function labels.
For German, therefore, the task of tree con-struction is slightly more complex because of the larger set of functional labels. Fig. 3 gives an ex-ample for a German input sentence and its corre-sponding chunk parser output.
In this case, the subconstituents of the extra-posed coordinated noun phrase are not attached to the simplex clause that ends with the non-finite verb that is typically in clause-final position in declarative main clauses of German. Moreover, each conjunct of the coordinated noun phrase forms a completely flat structure. T ¨uSBL’s tree construction module enriches the chunk output as shown in Fig. 4. Here the internally recur-sive NP conjuncts have been coordinated and
in-3
See (Stegmann et al., 2000; Kordoni, 2000) for further details.
4
The annotation for German follows the topological-field-model standardly used in empirical studies of German syntax. The annotation for English is modeled after the theo-retical assumptions of Head-Driven Phrase Structure Gram-mar.
Input:
dann w”urde ich vielleicht noch vorschlagen Donnerstag den elften und Freitag den zw”olften August (then I would suggest maybe Thursday eleventh and Friday twelfth of August)
Chunk parser output:
[simpx [advx [adv dann]] [vxfin [vafin w"urde]] [nx2 [pper ich]]
[advx [adv vielleicht]] [advx [advmd noch]] [vvinf vorschlagen]] [nx3 [day Donnerstag]
[art den] [adja elften]] [kon und]
[nx3 [day Freitag] [art den] [adja zw"olften] [month August]]
Figure 3: Chunk parser output for a German sen-tence.
tegrated correctly into the clause as a whole. In addition, function labels such as MOD (for:
mod-ifier), HD (for head), ON (for: subject), OA (for: direct object), OV (for: verbal object), and APP
(for: apposition) have been added that encode the function-argument structure of the sentence.
4 Similarity-based Tree Construction
[image:3.612.307.495.309.462.2]German label description English label description
HD head HD head
- non-head - intentionally empty
ON nominative object COMP complement
OD dative object SPR specifier
OA accusative object SBJ subject
OS sentential object SBQ subject,
wh-OPP prepositional object SBR subject, rel.
OADVP adverbial object ADJ adjunct
OADJP adjectival object ADJ? adjunct ambiguities
PRED predicate FIL filler
OV verbal object FLQ filler,
wh-FOPP optional prepositional object FLR filler, rel.
VPT separable verb prefix MRK marker
APP apposition
MOD ambiguous modifier
x-MOD 8 distinct labels for specific modifiers, e.g. V-MOD
yK 13 labels for second conjuncts in
[image:4.612.129.468.14.226.2]split-up coordinations, e.g. ONK
Table 1: The functional label set for the German and the English treebanks.
0 1 2 3 4 5 6 7 8 9 10 11 12 13
500 501
502
503
504 505
506
507 508 509
510 511
512 513 514 515
516 517
dann
ADV w"urde
VAFIN ich
PPER
vielleicht
ADV noch
ADV
vorschlagen
VVINF
Donnerstag NN
den
ART elften
NN und KON
Freitag NN
den
ART
zw"olften
ADJA August
NN
HD HD
HD
VXINF OV
HD HD
VXFIN HD
− HD NX HD APP ADVX
MOD
HD NX ADVX ADVX ON MOD MOD
HD ADJX − − HD
NX HD APP NX
NX
− − −
NX OA
VF LK MF VC
NF SIMPX
− − − − −
Figure 4: Tree construction output for the German sentence in Fig. 3.
learning (Stanfill and Waltz, 1986).5 Memory-based learning assumes that the classification of a given input should be based on the similarity to previously seen instances of the same type that have been stored in memory. This paradigm is an instance of lazy learning in the sense that these previously encountered instances are stored “as is” and are crucially not abstracted over, as is typically the case in rule-based systems or other learning approaches. Previous applications of
5
Memory-based learning has recently been applied to a variety of NLP classification tasks, including part-of-speech tagging, noun phrase chunking, grapheme-phoneme conver-sion, word sense disambiguation, and PP attachment (see (Daelemans et al., 1999; Veenstra et al., 2000; Zavrel et al., 1997) for details).
[image:4.612.77.508.265.427.2]the instance base. If these strategies fail for com-plete chunks, T ¨uSBL attempts to match smaller subchunks.
The algorithm used for tree construction is pre-sented in a slightly simplified form in Figs. 5-8. For readability, we assume here that chunks and complete trees share the same data structure so that subroutines like string yield can operate on both of them indiscriminately.
The main routine construct tree in Fig. 5 sepa-rates the list of input chunks and passes each one to the subroutine process chunk in Fig. 6 where the chunk is then turned into one or more (partial) trees. process chunk first checks if a complete match with an instance from the instance base is possible.6 If this is not the case, a partial match on the lexical level is attempted. If a partial tree is found, attach next chunk in Fig. 7 and extend tree in Fig. 8 are used to extend the tree by either at-taching one more chunk or by resorting to a com-parison of the missing parts of the chunk with tree extensions on the POS level. attach next chunk is necessary to ensure that the best possible tree is found even in the rare case that the original seg-mentation into chunks contains mistakes. If no partial tree is found, the tree construction backs off to finding a complete match at the POS level or to starting the subroutine for processing a chunk recursively with all the subchunks of the present chunk.
The application of memory-based techniques is implemented in the two subroutines
com-plete match and partial match. The presentation
of the two cases as two separate subroutines is for expository purposes only. In the actual implemen-tation, the search is carried out only once. The two subroutines exist because of the postprocess-ing of the chosen tree, which is necessary for par-tial matches and which also deviates from stan-dard memory-based applications. Postprocessing mainly consists of shortening the tree from the in-stance base so that it covers only those parts of the chunk that could be matched. However, if the match is done on the lexical level, a correction of tagging errors is possible if there is enough evi-dence in the instance base. T ¨uSBL currently uses an overlap metric, the most basic metric for
in-6
string yield returns the sequence of words included in
the input structure, pos yield the sequence of POS tags.
stances with symbolic features, as its similarity metric. This overlap metric is based on either lexical or POS features. Instead of applying a more sophisticated metric like the weighted over-lap metric, T ¨uSBL uses a backing-off approach that heavily favors similarity of the input with pre-stored instances on the basis of substring identity. Splitting up the classification and adaptation pro-cess into different stages allows T ¨uSBL to prefer analyses with a higher likelihood of being correct. This strategy enables corrections of tagging and segmentation errors that may occur in the chun-ked input.
5 Quantitative Evaluation
Quantitive evaluations of robust parsers typically focus on the three PARSEVAL measures: labeled precision, labeled recall and crossing accuracy. It has frequently been pointed out that these evalu-ation parameters provide little or no informevalu-ation as to whether a parser assigns the correct seman-tic structure to a given input, if the set of category labels comprises only syntactic categories in the narrow sense, i.e. includes only names of lexi-cal and phrasal categories. This justified criticism observes that a measure of semantic accuracy can only be obtained if the gold standard includes an-notations of syntactic-semantic dependencies be-tween bracketed constituents. It is to answer this criticism that the evaluation of the T ¨uSBL system presented here focuses on the correct assignment of functional labels. For an in-depth evaluation that focuses on syntactic categories, we refer the interested reader to (K¨ubler and Hinrichs, 2001).
The quantitative evaluation of T ¨uSBL has been conducted on the treebanks of German and En-glish described in section 3. Each treebank uses a different annotation scheme at the level of function-argument structure. As shown in Table 1, the English treebank uses a total of 13 func-tional labels, while the German treebank has a richer set of 36 function labels.
cat-construct tree(chunk list, treebank):
while (chunk list is not empty) do
[image:6.612.74.458.79.374.2]remove first chunk from chunk list process chunk(chunk, treebank)
Figure 5: Pseudo-code for tree construction, main routine.
process chunk(chunk, treebank): words := string yield(chunk)
tree := complete match(words, treebank)
if (tree is not empty) direct hit,
then output(tree) i.e. complete chunk found in treebank
else
tree := partial match(words, treebank)
if (tree is not empty) then
if (tree = postfix of chunk) then
tree1 := attach next chunk(tree, treebank)
if (tree is not empty) then tree := tree1
if ((chunk - tree) is not empty) if attach next chunk succeeded
then tree := extend tree(chunk - tree, tree, treebank) chunk might consist of both chunks output(tree)
if ((chunk - tree) is not empty) chunk might consist of both chunks (s.a.)
then process chunk(chunk - tree, treebank) i.e. process remaining chunk
else back off to POS sequence
pos := pos yield(chunk)
tree := complete match(pos, treebank)
if (tree is not empty) then output(tree)
else back off to subchunks
while (chunk is not empty) do
remove first subchunk c1 from chunk process chunk(c1, treebank)
Figure 6: Pseudo-code for tree construction, subroutine process chunk.
attach next chunk(tree, treebank): attempts to attach the next chunk to the tree take first chunk chunk2 from chunk list
words2 := string yield(tree, chunk2) tree2 := complete match(words2, treebank)
if (tree2 is not empty) then
remove chunk2 from chunk list return tree2
else return empty
Figure 7: Pseudo-code for tree construction, subroutine attach next chunk.
extend tree(rest chunk, tree, treebank): extends the tree on basis of POS comparison words := string yield(tree)
rest pos := pos yield(rest chunk)
tree2 := partial match(words + rest pos, treebank)
if ((tree2 is not empty) and (subtree(tree, tree2))) then return tree2
else return empty
Figure 8: Pseudo-code for tree construction, subroutine extend tree.
egories alone, and 2. labeled precision for func-tional labels.
The results of the quantitative evaluation are
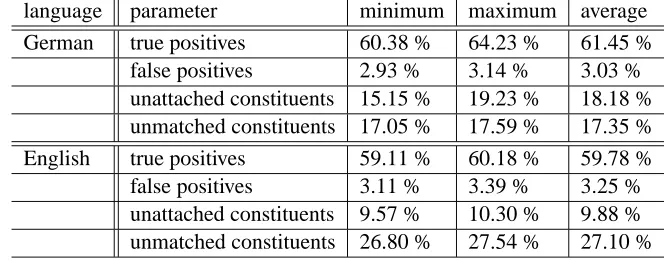
pars-language parameter minimum maximum average German true positives 60.38 % 64.23 % 61.45 %
false positives 2.93 % 3.14 % 3.03 % unattached constituents 15.15 % 19.23 % 18.18 % unmatched constituents 17.05 % 17.59 % 17.35 % English true positives 59.11 % 60.18 % 59.78 % false positives 3.11 % 3.39 % 3.25 % unattached constituents 9.57 % 10.30 % 9.88 % unmatched constituents 26.80 % 27.54 % 27.10 %
Table 2: Quantitative evaluation: recall.
language parameter minimum maximum average
[image:7.612.129.461.15.146.2]German labeled precision for synt. cat. 81.28 % 82.08 % 81.56 % labeled precision for funct. cat. 89.26 % 90.13 % 89.73 % English labeled precision for synt. cat. 66.15 % 67.34 % 66.84 % labeled precision for funct. cat. 90.07 % 90.93 % 90.40 %
Table 3: Quantitative evaluation: precision.
ing approach like ours. We have, therefore di-vided the incorrectly matched nodes into three categories: the genuine false positives where a tree structure is found that matches the gold stan-dard, but is assigned the wrong label; nodes which, relative to the gold standard, remain unattached in the output tree; and nodes contained in the gold standard for which no match could be found in the parser output. Our approach follows a strategy of positing and attaching nodes only if sufficient evidence can be found in the instance base. Therefore the latter two categories can-not really be considered errors in the strict sense. Nevertheless, in future research we will attempt to significantly reduce the proportion of unattached and unmatched nodes by exploring matching al-gorithms that permit a higher level of generaliza-tion when matching the input against the instance base. What is encouraging about the recall results reported in Table 2 is that the parser produces gen-uine false positives for an average of only 3.03 % for German and 3.25 % for English.
For German, labeled precision for syntactic categories yielded 81.56 % correctness. While these results do not reach the performance re-ported for other parsers (cf. (Collins, 1999; Char-niak, 1997)), it is important to note that the two treebanks consist of transliterated spontaneous
speech data. The fragmentary and partially ill-formed nature of such spoken data makes them harder to analyze than written data such as the Penn treebank typically used as gold standard.
It should also be kept in mind that the basic PARSEVAL measures were developed for parsers that have as their main goal a complete analy-sis that spans the entire input. This runs counter to the basic philosophy underlying an amended chunk parser such as T ¨uSBL, which has as its main goal robustness of partially analyzed struc-tures.
Labeled precision of functional labels for the German data resulted in a score of 89.73 % cor-rectness. For English, precision of functional la-bels was 90.40 %. The slightly lower correctness rate for German is a reflection of the larger set of function labels used by the grammar. This raises interesting more general issues about trade-offs in accuracy and granularity of functional annota-tions.
6 Conclusion and Future Research
sophisticated similarity metrics7 and by enrich-ing the lenrich-inguistic information in the instance base. The latter can, for example, be achieved by pre-serving more structural information contained in the chunk parse. Yet another dimension for ex-perimentation concerns the way in which the al-gorithm generalizes over the instance base. In the current version of the algorithm, generaliza-tion heavily relies on lexical and part-of-speech information. However, a richer set of backing-off strategies that rely on larger domains of structure are easy to envisage and are likely to significantly improve recall performance.
While we intend to pursue all three dimensions of refining the basic algorithm reported here, we have to leave an experimentation of which modi-fications yield improved results to future research.
References
Steven Abney. 1991. Parsing by chunks. In Robert Berwick, Steven Abney, and Caroll Tenney, editors,
Principle-Based Parsing. Kluwer Academic
Pub-lishers.
Steven Abney. 1996. Partial parsing via finite-state cascades. In John Carroll, editor, Workshop on
Ro-bust Parsing (ESSLLI ’96).
Rens Bod. 1998. Beyond Grammar: An
Experience-Based Theory of Language. CSLI Publications,
Stanford, California.
Rens Bod. 2000. Parsing with the shortest derivation. In Proceedings of COLING 2000, Saarbr ¨ucken,
Germany.
Thorsten Brants, Wojiech Skut, and Brigitte Krenn. 1997. Tagging grammatical functions. In
Proceed-ings of EMNLP-2 1997, Providence, RI.
Norbert Br¨oker, Udo Hahn, and Susanne Schacht. 1994. Concurrent lexicalized dependency parsing: the ParseTalk model. In Proceedings of COLING
94, Kyoto, Japan.
Eugene Charniak. 1997. Statistical parsing with a context-free grammar and word statistics. In
Pro-ceedings of the Fourteenth National Conference on Artifical Intelligence, Menlo Park.
Michael Collins. 1999. Head-Driven Statistical
Mod-els for Natural Language Parsing. Ph.D. thesis,
University of Pennsylvania.
7
(Daelemans et al., 1999) reports that the gain ratio sim-ilarity metric has yielded excellent results for the NLP appli-cations considered by these investigators.
Walter Daelemans, Jakub Zavrel, and Antal van den Bosch. 1999. Forgetting exceptions is harmful in language learning. Machine Learning: Special
Is-sue on Natural Language Learning, 34.
Helmut Feldweg. 1993. Stochastische Wortartendis-ambiguierung f¨ur das Deutsche: Untersuchungen mit dem robusten System LIKELY. Technical re-port, Universit¨at T¨ubingen. SfS-Report-08-93.
Valia Kordoni. 2000. Stylebook for the English
Treebank in VERBMOBIL. Technical Report 241, Verbmobil.
Sandra K¨ubler and Erhard W. Hinrichs. 2001.
T¨uSBL: A similarity-based chunk parser for robust syntactic processing. In Proceedings of HLT 2001,
San Diego, Cal.
Leonardo Lesmo and Vincenzo Lombardo. 2000.
Au-tomatic assignment of grammatical relations. In
Proceedings of LREC 2000, Athens, Greece.
Mitchell Marcus, Grace Kim, Mary Ann
Marcinkiewicz, Robert MacIntyre, Anne Bies, Mark Ferguson, Karen Katz, and Britta
Schas-berger. 1994. The Penn Treebank: Annotating
predicate argument structure. In Proceedings of
HLT 94, Plainsboro, New Jersey.
Beatrice Santorini. 1990. Part-Of-Speech Tagging
Guidelines for the Penn Treebank Project. Univer-sity of Pennsylvania, 3rd Revision, 2nd Printing.
Anne Schiller, Simone Teufel, and Christine Thielen. 1995. Guidelines f¨ur das Tagging deutscher Text-korpora mit STTS. Technical report, Universit¨aten Stuttgart and T¨ubingen. http://www.sfs.nphil.uni-tuebingen.de/Elwis/stts/stts.html.
Craig Stanfill and David L. Waltz. 1986. Towards memory-based reasoning. Communications of the
ACM, 29(12).
Rosmary Stegmann, Heike Schulz, and Erhard W. Hinrichs. 2000. Stylebook for the German
Tree-bank in VERBMOBIL. Technical Report 239,
Verbmobil.
Pasi Tapanainen and Timo J¨arvinen. 1997. A
non-projective dependency parser. In Proceedings of
ANLP’97, Washington, D.C.
Jorn Veenstra, Antal van den Bosch, Sabine Buch-holz, Walter Daelemans, and Jakub Zavrel. 2000. Memory-based word sense disambiguation.
Com-puters and the Humanities, Special Issue on Sense-val, Word Sense Disambiguations, 34.
Jakub Zavrel, Walter Daelemans, and Jorn Veen-stra. 1997. Resolving PP attachment ambiguities
with memory-based learning. In Proceedings of