Copyright © 2014 IJECCE, All right reserved
Achieving the Capability of a Dictionary Based Data
Compression Technique OLZW and its Variants
Utpal Nandi
Department of Computer Science,Bangabasi College, Kolkata-700009, West Bengal, India Email: [email protected]
Jyotsna Kumar Mandal
Department of Computer Science & Engineering University of Kalyani, Nadia-741235, West Bengal, IndiaEmail: [email protected]
Abstract – In this paper, the capability of a lossless dictionary based data compression technique OLZW and its variants MOLZW, MOLZWV1 and MOLZWV2 have been discussed with respect to LZW technique. In OLZW technique, initially the dictionary is empty. If the phrase to be encoded is already in dictionary, it encoded with the code in the dictionary. Length of code is not fixed and is calculated by the highest index in the dictionary. Otherwise, ASCII code is used to encode the same. The technique eliminates some limitations of LZW technique and works very well for small size files particularly. MOLZW is the modified form of OLZW where additionally a checking is performed to determine the dictionary is full or not before insertion of new entry into the dictionary. When the dictionary gets full, the least recently used dictionary phrase is deleted. In MOLZWV1, no phrases of dictionary are deleted. But, phrases added to the dictionary are all the string formed by concatenation of previous match and prefix of current match including current match itself. MOLZWV2 combines both the above MOLZW and MOLZWV1 techniques. The experimental results show that OLZW technique offers better compression rates for small size files particularly than its counter parts and MOLZW techniques work well not only for small size files but also for large size files.
Keywords – Compression Ratio, Data Compression, Dictionary-Based Compression, LZW, MOLZW, MOLZWV1, MOLZWV2, OLZW.
I. I
NTRODUCTIONData compression techniques reduce the size of data to store or transmit that are divided into two types- loss-less and lossy [6]. Loss-less compression techniques [1-12] generate an exact duplicate of any file/stream after compress-expand process. It is used to compress spreadsheets, database, word document etc. But, the lossy data compression allows a certain loss of accuracy of data and used to compress image, video, audio files. A lossless data compression is generally implemented using one of two different types of modeling: statistical or dictionary-based. The compression techniques used statistical model encode single symbol at a time where symbols encoding are done by bit strings that use fewer bits than the original symbols. But, the dictionary-based compression algorithms use a completely different approach. It encodes phrases (variable-length group of symbols) as single tokens. Dictionary-based modeling uses either static or adaptive dictionary. Static dictionary is built up before compression occurs and it does not change while the data is being compressed. The problem with a static dictionary is that the dictionary needs to be transmitted along with the text, increasing the size of compressed file. An
adaptive dictionary scheme can avoid this problem. It does not tune dictionary in advance. In 1977 and 1978, Jacob Ziv and Abraham Lempel introduced two dictionary-based compression algorithms i.e. LZ77 and LZ78 [4]. The dictionary of LZ77 is adaptive and consists of all strings in a limited size window into the previously read input stream. But, LZ78 builds its dictionary out of all the previously seen symbols in the input text. A variant of LZ77 is LZSS [3] eliminating the requirement that each token output a phrase and character. Another effective variant of LZ78 is LZW [7] that does the same improvements on LZ78. The detail discussion of this technique is done in section II. The technique has few limitations. The dictionary is filled with 256 symbols of the alphabet before encoding. It is found that large numbers of symbols in the dictionary are not used during encoding of some files. But, these symbols reserve some indexes that cannot be used for other necessary phrases of dictionary. Again, initially the next available index (257) can be represented by at least 9 bits. To overcome these limitations, OLZW [1] coding technique is introduced. The detail discussion of this technique is done in section III. The technique works very well for particularly small size files most of the time than LZW. But, the compression ratios offered by the OLZW technique are not so well as LZW for large size files. To overcome this limitation, OLZW is modified and termed as Modified compression technique based on optimality of LZW code (MOLZW) [2] as discussed in section IV. Two variant of the same are also discussed to that section. Results are given in section V and conclusions are drawn in section VI.
II. LZW T
ECHNIQUE AND IT’
SL
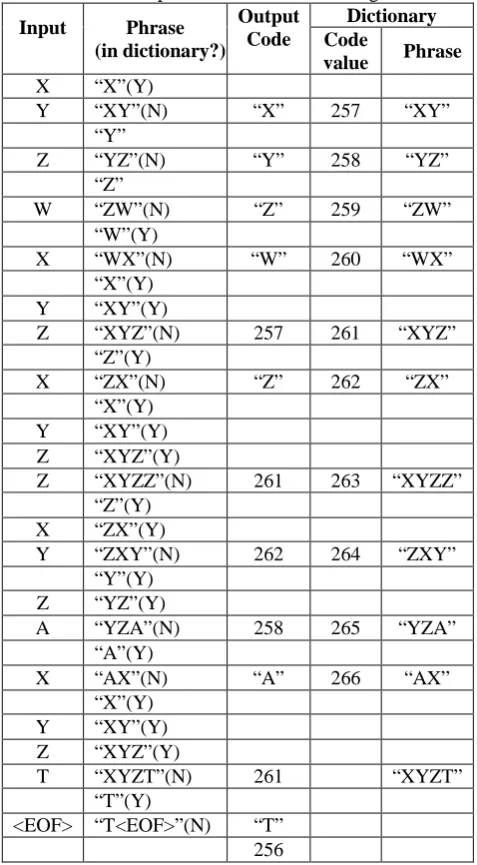
IMITATIONSCopyright © 2014 IJECCE, All right reserved “XYZWXYZXYZZXYZAXYZTX” (say, STRNG) used
to demonstrate the technique as shown in table I. The first character X is in the dictionary. Then, check if the concatenation of first and second character i.e. “XY” is in the dictionary. Since it isn’t, the code for “X” is output, and the string “XY” is inserted to 257th index of the dictionary. Because, 0th to 255th and 256th indexes of dictionary are already occupied by 256 symbols of alphabet and End_Of_File marker respectively. After the next character ‘Z’ read, the next string, “YZ”, is inserted to the dictionary, and the code of ‘Y’ is output. This process is continued until end of string and all codes have been output. The compressed message of STRNG is “XYZW<257>Z<261><262><258>A<261>T<256>”. Size of STRNG is 20x8 bits = 160 bits. Size of compressed message is 13 X 12 bits = 156 bits. The compression ratio is {1-(156/160)}x100% = 2.5%. Here, LZW coding (LZW12) uses a fixed size 12 bit code to encode each phrase of the dictionary. But, 12 bits code size allows for a 4K phrase dictionary which is not enough for large file/stream. LZW is improved by increasing the size of the dictionary. The more powerful improved version of LZW coding (LZW15V) contains several enhancements. First, it expands the maximum code size to 15 bits. Second, it starts encoding with 9 bit codes, working its way up in bits size only as necessary. Finally, it flushes the dictionary when the dictionary is filled up with phrases. Now, size of compressed message is 13 X 9 bits = 117 bits and compression ratio is {1-(117/160)} x100% = 26.87%. But, there are some limitations in the improved version of LZW also. In LZW12 and LZW15V, all 256 symbols in the alphabet are inserted as phrase to the dictionary at the beginning of compression. All inserted phrases in the dictionary are not used during compression of files/streams most of the times. But, these initially inserted unused phrases reserve some indexes that cannot be assigned to other necessary phrases of dictionary. Available indexes can be represented by more bits compare to indexes of these initially inserted unused phrases.
Initialize dictionary with 256 symbols and corresponding code from 0 to 255;
STNG=1stcharacter; nxt_c=257;
While (not end of file/stream) do CHAR=next character;
If (STNG+CHAR is in the dictionary), then STNG=STNG+CHA;
Else
Output code for STNG;
Add (STNG+CHAR) to the dictionary with code value nxt_c;
nxt_c=nxt_c+1; STNG=CHAR; End if;
End of while;
Output code for STNG; End;
Fig.1. LZW technique
Table 1: Compression of STRNG1 Using LZW
Input Phrase
(in dictionary?)
Output Code
Dictionary Code
value Phrase
X “X”(Y)
Y “XY”(N) “X” 257 “XY”
“Y”
Z “YZ”(N) “Y” 258 “YZ”
“Z”
W “ZW”(N) “Z” 259 “ZW”
“W”(Y)
X “WX”(N) “W” 260 “WX”
“X”(Y)
Y “XY”(Y)
Z “XYZ”(N) 257 261 “XYZ”
“Z”(Y)
X “ZX”(N) “Z” 262 “ZX”
“X”(Y)
Y “XY”(Y)
Z “XYZ”(Y)
Z “XYZZ”(N) 261 263 “XYZZ”
“Z”(Y)
X “ZX”(Y)
Y “ZXY”(N) 262 264 “ZXY”
“Y”(Y)
Z “YZ”(Y)
A “YZA”(N) 258 265 “YZA”
“A”(Y)
X “AX”(N) “A” 266 “AX”
“X”(Y)
Y “XY”(Y)
Z “XYZ”(Y)
T “XYZT”(N) 261 “XYZT”
“T”(Y)
<EOF> “T<EOF>”(N) “T” 256
It increases compressed file/stream size. Again, at the beginning of the compression, the next available index (257) can be represented by at least 9 bits. Because, first 256 indexes are occupied by 256 symbols of the alphabet. These large length available indexes of phrases increase compressed file/stream size. To overcome these limitations, a coding technique is introduced and described in section III.
III. OLZW T
ECHNIQUECopyright © 2014 IJECCE, All right reserved like LZW12 nor (9 - 15) bits like LZW15V. Phrase code
lengths are 1, 2, 3, 4 …. for number of dictionary entry up to 1, 4, 8, 16 …. respectively and so on. In this way, a significant reduction of number of bits can be done. Another advantage of this technique is that it does not bring any symbol into the dictionary until it is needed and does not waste any dictionary index. The technique reads symbols one by one. The symbol to be encoded not in dictionary is encoded with 8-bit ASCII code and inserted into the next free index of dictionary as a new phrase. If a symbol to be encoded is already in dictionary, next symbol is read and concatenated. And this is continued until a string (STNG + CHAR) is found such that STNG is in dictionary but (STNG + CHAR) is not. Then, the technique outputs x bits code of STNG where x=┌log(index of last entry)┐and the string (STNG + CHAR) is inserted into the next free index of dictionary. A flag is used to distinguish above two possibilities. The complete OLZW compression algorithm is shown in Fig.1.
Initially, set nxt_c=1,STNG=NULL, F=0; CHAR=1stcharacter from input file/stream; Write value of F with ASCII code for CHAR;
Insert CHAR to dictionary with corresponding code value ( nxt_c);
nxt_c=nxt_c+1;
While (not end of input file/stream) do CHAR=next character from input file/stream; If (STNG+CHAR is in dictionary), then F=1; STNG=STNG+CHAR;
Else
Insert STNG+CHAR to dictionary with nxt_c; nxt_c=nxt_c+1;
If (F=0), then
Write value of F with ASCII code for CHAR; STNG=NULL;
Else
LN=Find_ length (nxt_c);
Write F with x bits code for CHAR from dictionary;
If(CHAR is not in dictionary), then F=0;
Write F with ASCII code for CHAR; Insert CHAR to dictionary with nxt_c; nxt_c=nxt_c+1;
Else
STNG=CHAR; F=1;
End if; End if; End if; End while;
If (F=1), then
LN= find_length (nxt_c);
Write F with x bits code for STNG from dictionary;
End if; End;
Fig.2. OLZW compression algorithm.
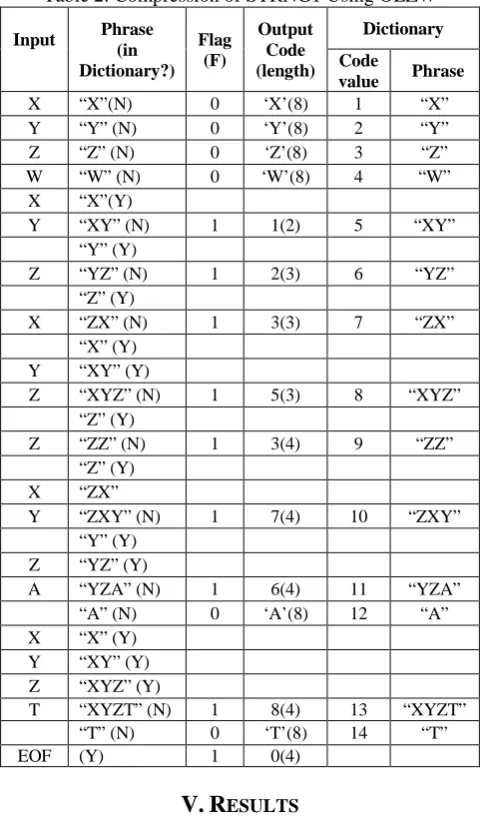
For example, let us consider the same message STRNG to demonstrate the technique as shown in table II. The first read symbol X is not in dictionary. Therefore, the encoder outputs ASCII code of X with single bit flag 0 and X is inserted as new phrase to the dictionary index 1. Similarly, the technique outputs ASCII codes of Y, Z, W with corresponding flags 0 for input Y, Z, W and these are inserted into the dictionary indexes 2, 3, 4 respectively. The next symbol X is read that is already in dictionary. Then, the next symbol Y is read. But, the string “XY” is not found in the dictionary. The encoder outputs ┌log(4)┐=2 bit code of X (i.e.01) from dictionary with single bit flag 1. Because, currently the last used index of dictionary is 4. Then, the next symbol Y is read. But, the string “XY” is not found in dictionary. The encoder outputs ┌log(5)┐=3 bit code of X (i.e.001) from dictionary with single bit flag 1. The string “XY” is inserted in dictionary index 5 as new phrase and initializes string as Y. The Y is already in dictionary. The next symbol Z is read. But, the string “YZ” is not found in the dictionary. Similarly, the encoder outputs 3 bit code of P with single bit flag 1. All other symbols are encoded similarly. Finally, a special code value 0 is output for End_Of_File marker. The compressed message of STRNG1 is 0X0Y0Z0W1<1>1<2>1<3> 1<5>1<3>1<7>1 <6>0A1<8>0T 1<0>. Size of STRNG is 20x8 bits = 160 bits. Size of compressed message is (1x15+2x1+3x3+4x5 +8x6) bits = 94 bits. The compression ratio is {1-(94/160)} x100% = 41.25%.
IV. MOLZW
AND ITSV
ARIANTSThe technique is also started with empty
dictionary. The symbol to be encoded not in
dictionary is encoded with 8 bit ASCII code and
inserted into the next free index of dictionary as a
new phrase. If a symbol STNG is in the dictionary,
the next read symbol is concatenated to STNG. This
process is continued as long as the string STNG is
found in the dictionary. When, concatenating the
next read symbol (say X) to STNG causes the
dictionary search to fail, the STNG is encoded with
the corresponding index of the dictionary. The length
of the code is determined by the last used index the
dictionary similar with OLZW. The concatenation of
STNG and X is inserted into the next available index
of dictionary as a new phrase and STNG is initialized
by the symbol X. This is repeated for remaining all
symbols also. During insertion of new entry into the
dictionary, the technique checks the dictionary is
full(i.e. the number of phrases exceed a specified
number) or not. If the dictionary is full, the least
recently used dictionary
phrase is removed. The detailCopyright © 2014 IJECCE, All right reserved STNG including STNG itself and STNG’ is the previous
match. This is in contrast to OLZW and MOLZW techniques where phrases inserted are the concatenation of the current match STNG and the first symbol of the next match X. For example, STNG’=A and STNG=PQR, then phrases AP, APQ and APQR are inserted to the dictionary. Another variant of the MOLZW is MOLZWV2. This technique combines the features of both the MOLZW and MOLZW1 techniques. That is, the technique removes the least recently used phrases if the dictionary is full and inserts all the string STNG’T where T is a prefix of the current match STNG and STNG’ is the previous match.
Table 2: Compression of STRNG1 Using OLZW Input Phrase
(in Dictionary?)
Flag (F)
Output Code (length)
Dictionary
Code
value Phrase
X “X”(N) 0 ‘X’(8) 1 “X”
Y “Y” (N) 0 ‘Y’(8) 2 “Y”
Z “Z” (N) 0 ‘Z’(8) 3 “Z”
W “W” (N) 0 ‘W’(8) 4 “W”
X “X”(Y)
Y “XY” (N) 1 1(2) 5 “XY”
“Y” (Y)
Z “YZ” (N) 1 2(3) 6 “YZ”
“Z” (Y)
X “ZX” (N) 1 3(3) 7 “ZX”
“X” (Y)
Y “XY” (Y)
Z “XYZ”(N) 1 5(3) 8 “XYZ”
“Z” (Y)
Z “ZZ” (N) 1 3(4) 9 “ZZ”
“Z” (Y)
X “ZX”
Y “ZXY” (N) 1 7(4) 10 “ZXY”
“Y” (Y)
Z “YZ” (Y)
A “YZA” (N) 1 6(4) 11 “YZA”
“A” (N) 0 ‘A’(8) 12 “A”
X “X” (Y)
Y “XY” (Y)
Z “XYZ” (Y)
T “XYZT”(N) 1 8(4) 13 “XYZT”
“T” (N) 0 ‘T’(8) 14 “T”
EOF (Y) 1 0(4)
V. R
ESULTSFor experimental purpose, seven different types of files (i.e. c, doc, hybrid, exe, core, NTSC and tiff ) with five different sizes (i.e. 1KB, 5KB, 100KB, 1MB and 5MB ) have been taken. The graphical representations of comparison of compression ratios of LZW12, LZW15, OLZW, MOLZW, MOLZW1and MOLZW2 techniques are shown in Fig.4 to Fig.10 for doc, hybrid, exe, core, NTSC and tiff files respectively. For all seven types of 1KB, 5KB files, the compression ratios of OLZW, MOLZW and its variants are better than LZW12 and LZW15V. The compression ratios of MOLZW and its
variants for all types of 100KB, 1MB and 5MB files are better than LZW12 and even some time better than the compression ratios of LZW15V. But, the performance of OLZW degrades for large size 100KB, 1MB and 5MB files.
Innitially set nxt_c=1,PHARSE=NULL, F=0; Read 1stelement from input file/stream as CHAR; Write F with ASCII code for CHAR to output file / stream;
Insert CHAR to dictionary with nxt_c; nxt_c is incremented by 1;
While (not end of file/stream) do
Read next element from input file/stream as CHAR; If (PHARSE +CHAR is in dictionary), then F=1; PHARSE = PHARSE + CHAR; Else
If (dictionary is full)
Delete least recently used phrase from dictionary.
End if;
Insert PHRASE to dictionary with nxt_c; nxt_c is incremented by 1;
If (F=0), then
Write F with ASCII code for CHAR to output file / stream;
PHRASE=NULL; Else
LN=Find_length (nxt_c);
Write F with LN bits code for CHAR from dictionary to output file / stream;
If(CHAR is not in dictionary), then F=0;
Write F with ASCII code for CHAR to output file / stream;
If (dictionary is full)
Delete least recently used phrase from dictionary.
End if;
Insert CHAR to dictionary with nxt_c; nxt_c is incremented by 1;
Else
PHRASE=CHAR; F=1;
End if; End if; End while; If (F=1), then
LN= find_length (nxt_c);
Write F with LN bits code for PHRASE from dictionary to output file / stream;
End if; End;
Fig.3. MOLZW compression algorithm
VI. C
ONCLUSIONCopyright © 2014 IJECCE, All right reserved LZW12 and LZW15V) most of the time. And also the
compression rates of this technique are not so poor for large size files. It offers better results for large size files than LZW12 most of the time. But, the compression rates are not as well as offered by LZW15V for large files. The MOLZW and its variants eliminate the problems. The techniques not only offer significant compression rates for small size files, but also for large size files. Similar with OLZW, the techniques works very well for particularly small size files most of the time than LZW. And the results of MOLZW and its variants are quite well for large size files also. These techniques offer better compressions for large size files than LZW12 and OLZW most of the time and some time better than or at least closed to the compression ratios of LZW15V. Among MOLZW, MOLZWV1 and MOLZWV2 techniques, the performances of MOLZW2 are better. The OLZW and MLZW techniques have a great scope of modifications and can also be used for image compression.
Fig.4. The graphical representations of compression ratios of different techniques of C files
Fig.5. The graphical representations of compression ratios of different techniques of doc files
Fig.6. The graphical representations of compression ratios of different techniques of Hybrid files
Fig.7. The graphical representations of compression ratios of different techniques of exe files
Fig.8. The graphical representations of compression ratios of different techniques of core files
Copyright © 2014 IJECCE, All right reserved Fig.10. The graphical representations of compression
ratios of different techniques of Tiff files
A
CKNOWLEDGMENTThe authors extend sincere thanks to the department of Computer Science and Engineering, University of Kalyani and PURSE Scheme of DST, Govt. of India and Bangabasi College, Kolkata, West Bengal, India for using the infrastructure facilities for developing the technique.
R
EFERENCES[1] U. Nandi,J. K. Mandal, “A Compression Technique Based On Optimality Of LZW Code (OLZW),” The Third IEEE International Conference on Computer & Communication Technology (ICCCT-2012), Allahabad, India , Nov, 2012, pp.166-170.
[2] U. Nandi, J. K. Mandal, “Modified Compression Techniques Based On Optimality Of LZW Code (MOLZW),” 1st
International Conference on Computational Intelligence: Modelling, Techniques and Applications (CIMTA- 2013), kalyani, West Bengal, India,2013, pp. 949–956.
[3] J.A. Storer, T.G. Szymanski, “Data compression via textual substitution,”journal of the ACM 29, Vol. 29 Issue 4, Oct. 1982, pp. 928-951.
[4] J. Ziv, and A.Lempel, “Compression of individual sequences via
variable-rate coding,” in IEEE Transactions on Information Theory, Vol. 24, No.5, September 1978, pp. 530- 536.
[5] H. K. Reglebati, “An Overview of Data Compression Techniques,” inIEEE Computer, April 1981,pp. 71-75. [6] M. Nelson, “The Data Compression Book,” ed. Second, India,
BPB Publications, 2008.
[7] Welch, Terry, A Technique for High-Performance Data Compression, in IEEE Computer, Vol. 17, No.6, June 1984, pages 8-19.
[8] M . Nelson, LZW Data Compression, in Dr. Dobb’s Journal, Vol. 14, No. 10, October 1989, pp. 29-37.
[9] U. Nandi,J. K. Mandal, “Comparative Study And Analysis of
Adaptive Region Based Huffman Compression Techniques,”
International Journal of Information Technology Convergence and Services (IJITCS) Vol.2, No.4, August 2012 pp. 17-24. [10] U. Nandi,J. K. Mandal, “Region Based Huffman Compression
with region wise multipleinterchanging of codes,” Advancement
of modelling & simulation techniques in enterprises(AMSE), France, Vol.17, No.2, July 2012, pp. 44-58.
[11] U. Nandi, J. K. Mandal,“WINDOWED Huffman Coding with limited distinct symbols,” 2nd International Conference on
Computer, Communication, Control and Information Technology (C3IT-2012), vol. 4, pp. 589-594, 2012, Hooghly, India.
[12] U. Nandi, J. K. Mandal, “Adaptive Region Based Huffman Compression Technique with selective code interchanging,” The
Second International Workshop on Peer-to-Peer Networks and Trust Management (P2PTM-2012), vol. 176, pp. 739-748, 2012, Chennai, India.
A
UTHOR’
SP
ROFILEUtpal Nandi
M.Sc. (Computer Science, Vidyasagar University), M.Tech. (Computer Science & Engineering) from University of Kalyani, Nadia, West Bengal, India. Assistant Professor, Dept. Of Computer Science, Bangabasi College, West Bengal, India. Total number of publications are14.