INTRUSION DETECTION USING
ENSEMBLE CLASSIFIER WITH
SELECTIVE SMOTE AND FEATURE
REDUCTION
Rajul Richhariya
Dept. Of CSE/IT M.I.T.S. Gwalior Gwalior , India [email protected]
Amit Kumar Manjhwar
Dept. Of CSE/IT M.I.T.S. Gwalior Gwalior, India [email protected]
Abstract:
Nowadays network security is growing security concern. Intrusion detection system (IDS) is exploit to prevent network attacks. To recognize the kind of attacks various methodologies exist like data mining methods, and etc. This paper ,focuses on the class im-balancing problem present in NSL-KDD because of class imbalance problem existing IDS generate high false positive and false negatives. Therefore It’s paramount important to research and adopt approaches to better the performance of IDS. In the Proposed work SMOTE has been applied to balance the dataset. Here dataset characteristics are clustered utilize k-means clustering and only minority classes are oversampled using SMOTE. Info gain rely upon feature selection is useful on balanced dataset to elect relevant features. The Random Forest Ensemble Classifier is utilizing for classifying network traffic. It’s observed that proposed method generate 99.9894% accuracy.
A Comparative analysis is carried out amid normal taxonomy and taxonomy along with SMOTE and feature selection. It’s observed that proposed method give better results than normal classification.
Keywords— IDS, Feature selection, random forest, SMOTE, NSL-KDD, FPR
1. INTRODUCTION
A system intrusion is any effort to attack a system and compromise its security aspects for instance confidentiality, availability or integrity. IDS are carried out to establish an intrusion when it occurs and on to find, they should trigger right recovery measures. IDS monitor every traffic as it permits thru n/w, analyze the traffic, reconstruct sessions and discover predefined patterns of attack or abnormal behaviors that would be caused by way of approach attacks. The IDS sample describes any IDS features. A sample describes the straightforward primary, implementation-independent features, and threats. Actual patterns add functionalities and threats and take into account the features of their exact atmosphere. In this case, the abstract services are realized via define IDS which rely on well-known attack signatures or carryout on irregular behavior in the n/w[1].
2. IDS
security threat and will be let know to the higher administration by email or as SNMP traps. These policies are essential to be updated frequently to keep up with the threats and necessities of the safety incidents that happen on an/w, the huge majority arrive from the n/w. Such attacks may comprise of otherwise allowed customers who are disgruntled employees. The residue come from the exterior, in the form of DoS attacks or attempts to penetrate thru an infrastructure. IDS stay on the only proactive means of caught and responding to threats that branch from both insider and outsider a commercial network. There is subsequent form of IDS [2]:
• Host Based IDs • Hybrid IDs
• Network Based IDs
3. FEATURE SELECTION
The feature selection (FS) is to define a subset of relevant feature. It’s the essential preprocessing step prior to applying data mining (DM) tasks. It selects the subset of unique characteristic, without any loss of useful information. It deletes dismissed and irrelevant features for lessening data dimensionality. As a outcome it improves the mining accuracy, lessens the computation time and enhances outcome comprehensibility. On applying mining tasks to the reduced feature subset produces, the similar outcome as with original high- dimensional dataset. FS offers benefits e.g. storage necessities, facilitating data visualization, speeding up the execution of mining algorithms [4].
The optimal FS insert a further complexity layer in the modeling as instead of just finding optimal parameters for full set of features; initial highest feature subset is to be pattern parameters are to be optimized. Attribute election way may be widely divided into wrapper and filler approaches.
In the filter method the attribute election method is self-governing of the DM algorithm to be useful to the elected attributes and assess the features relevance thru looking only at the intrinsic assets of the info. In greatest cases a feature relevance score is compute, and lowest scoring features are deleting. The left features subset later feature elimination is describe as input to the taxonomy algorithm.
Reimbursements of filter approaches are which they conveniently scale to highest dimensional datasets are computationally rapid and simple, and as the filter method is self-governing of the mining algorithm, so FS necessities to be performed only once and then dissimilar classifiers can be evaluated.
Drawback of filter approach are that we ignore the interplay with the classifier and that ordinarily define approach are univariate meaning that each one feature is considered individually, thereby disregarding dependencies of feature, that may lead to worse taxonomy performance when equated to other kind of FS approach.
Wrapper technique embed the replica speculation hit onto in the characteristic subset discover. In the wrapper method the attribute election approach exploit the outcome of the DM algorithm to define how better a provide attribute subset is. In this setup, a detect process in the probable feature subsets space is describe, and several subsets of features are calculated and generated. The core feature of the wrapper way is which the attribute subset quality of is straight measured thru the DM algorithm performance applied to which attribute subset. The wrapper way has a tendency to be plenty slower than the filter out method, as the DM algorithm is carried out to all characteristic subset taken into consideration thru the detect. In addition, if several DM algorithms are to be applied to the info, the wrapper technique becomes even greater computationally expensive[5].
4. RANDOM FORESTS
Random Forests approach (RF) is a novel strategy known as ensemble studying and sturdy which is concerning with the noise and the no. of accredits [6]. RF approach is an ensemble learning process for taxonomy that works thru making several of decision trees at the time of training and time of giving output; here the class with the class mode is the o/p with the aid of every individual tree. The technique group of two thoughts that is of Breiman’s "bagging" views and the random election of features, which is presented independently thru Ho and Amit and Gemanfor the construction of gathering of decision trees consist of controlled variation.
5. SYNTHETIC MINORITY OVERSAMPLING TECHNIQUE (SMOTE)
• For the nominal features majority vote taken by 0 amid the feature vector and k which is the neighbors. In the case of a tie, elect at random.
• Assign that value to the latest synthetic minority class example [8].
6. LITERATURE SURVEY
Yuhu Cheng et al. [2017] they describe a fresh 0-shot picture classifier called random forest area rely on the
relative attribute.. First, depend on the series and non-series couples of images from the seen classes, the idea of ranking SVM is exploited to learn ranking functions for attributes. Then, according to the relative relationship amid seen and unseen classes, the RA ranking-score model per attribute for each unseen image is built, where the appropriate seen classes are automatically elected to participate in the modeling process. In the third step, the random forest classifier is trained rely on the RA ranking scores of attributes for all seen and unseen images. Finally, the class labels of testing images can be predicted via the trained RF. Experiments on Outdoor Scene Recognition, Pub Fig, and Shoes data sets illustrate which our define approach is superior to several state-of-the-art methods in terms of capability of categorization for zero-shot learning worries [9].
Sireesha Rodda et al. [2016] in this paper their main focus is on the existence of problem in class imbalance in
intrusion datasets. There are many threats which is effectively recognize by IDSinstead of little fraction also recognize the intrusion data. They give the overview of NSL_KDD datasets and it was evaluated on four approach e.g. DoS, R2L, U2R and Probe attacks. Weka was exploited to perform taxonomy on dissimilar datasets by applying various classification techniques. This method showed that highly imbalanced class might be not classified correctly. Outcomes illustrate that RF improved than other techniques [10].
Changsheng Zhou et al. [2016] this paper gives a theoretical analysis on the underlying causes leading to the
drawback of imbalanced finding out from the Bayesian perspective. A noval SMOTE is define, specifically misclassification fee Minimization Oriented SMOTE (CMOSMOTE).Experiments on several imbalanced data sets from actual world illustrate that our process achieves satisfactory efficiency on five analysis metrics [11].
Hossein Gharaee et al. [2016] this paper has proposed an anomaly depend IDS utilizing SVM and GA with a
novel FS method. The novel model has exploited a FS process depend on Genetic with an innovation in fitness function lessen the dimension of the data, increase true positive detection and simultaneously decrease positive false detection. Addition to, the computation time for training will also have a remarkable reduction. Results illustrate that describe approach can reach highest accuracy and little false positive rate (FPR) simultaneously, though it had earlier been achieved in earlier studies separately. These analyses define a method which can realize more stable features in comparison with other techniques. The define model experiment and test on KDD CUP 99 and UNSW-NB15 datasets. Numeric Results and comparison to other models have been presented [12].
Rajveer Kaur et al. [2015] In this paper, they performed study on dissimilar FS techniques. They compared
various FS approach thru exploiting pre-processed data set. Evaluation performed on the NSL - KDD dataset and a range of FS approach are applied for the reduction of test and training test data sets. For taxonomy they used Naïve Bayes. They performed comparison by experimenting results by applying it on various parameters like TP rate, FP rate, Precision, ROC area, Kappa Statistic and Taxonomy Accuracy [13].
Mohammad Farid Naufal et al. [2015] it needs a approach to solve this problematic exploiting oversampling
method. In is utilized, as oversampling approach. It is having advantages of FARM in learning on gathering of info that is having quantitative attribute and collective with the election process of software complexity metrics using CFS and oversampling using SMOTE, this approach is expected has a better than the earlier approach[14].
Jiong Zhang et al. [2008] in this paper they proposed new framework that is systematic and then applied on a
RF algorithm of info and utilized misuse, anomaly and hybrid-network-based IDSs. In misuse detection, they performed detection of patterns which was randomly generated over certain trained datasets. After that they performed matching on intrusions thru taking generated patterns. Exploited detection utilized to locate original intrusions method of the RF algorithm in anomaly detection. Then build new patterns by RF and outliers associated to the described patterns. They used advantages of the anomaly detection and misuse which improved the detection performance to create them hybrid approach. KDD’99 dataset utilized in their approach and demonstrated that their method was quite better than other methods [15].
7. PROPOSEDMETHODOLOGY
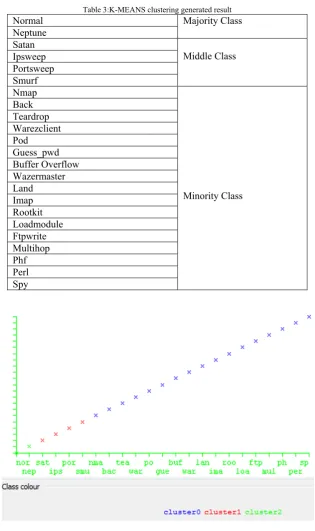
multihop, ftpwrite, loadmodule, rootkit, imap, land, wazermaster, bufferoverflow, guess_pwd, pod, warezclient, teardrop, and back in comparison to Normal, Neptune, satan and others. The dataset group into three classes majority class, the minority class and middle class by applying k-means clustering with k=3. The third cluster having 17 attacks that is a minority class .k-means clustering generated result shown in graph 1 and table 3. SMOTE is exploiting to oversample the minority class data. The class imbalance difficult is minimized to a required level by SMOTE in preprocessing phase by sampling the minority class of the data. SMOTE isn’t applied on majority class because in which records are already high compare to minority class. If SMOTE is applied on whole dataset the classes with high records also oversample and grows simultaneously with minority class and dataset will not balance. The newest synthetic minority examples are made as For the nominal features majority vote taken by 0 amid the vector of feature and k that is the nearest neighbors. In the case of a tie, elect at random. And assign that value to the latest class sample of synthetic minority. The SMOTE generated training data distribution with oversampling of 800% presented in table 4.
The data generated by SMOTE, that is assumed to be imbalance free, will be utilize for extracting features. After that for ranking features in a order (usually from highest to lowest) IG values are used. Then functions might be ranked depend on their records advantage values. IG rely on FS way is utilize because this is the appropriate manner is IDS as illustrate in literature survey.
The FS element of the framework forwards the novel feature lessen info to the RF classifier that identify normal traffic and attack patterns. RF is the best classifier that generate higher accuracy.
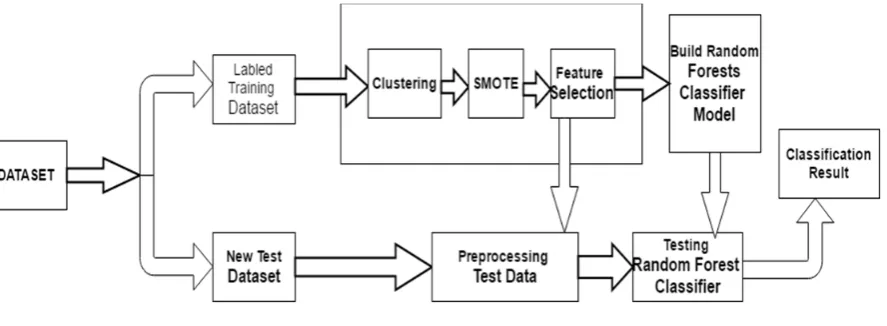
Fig 1. Proposed methodology
• Clustering: Clustering is the procedure of establishing data into collection and these groups are called
clusters. The objective of the similar cluster is more like to different cluster. K-means clustering algorithm is the simplest unsupervised finding out methods, where collections of identical objects in a data set are automatically, recognize missing any humanoid intervention.
k - Means is a partitioning procedure in clustering system of DM. K-Means clustering framework is exploited to parcel the training data into k clusters with the support of Euclidean distance similarity [4] It is an algorithm to organize or to classify the objects situated on attributes/services into k no. of clusters. Euclidean Distance condition to discover separate amid two articles is: D(a,b)= D(b,a)= |a-b|= Basic strides for clustering the data by k-means are:
• Choice a no. (k) of cluster middles centroids (random) • Assign each dissent its nearest cluster focus
• Transferevery cluster focus to the mean of its allotted objects
• Repeat stages 2, 3 until blending (trade cluster assignments lower than a most remote point).
• SMOTE: The class imbalance problematic is minimized to a required level by SMOTE in
preprocessing phase by sampling the minority class of the training data.
• Feature Selection: FS plays an vital role in Intrusion Detection, where a big no. of features extracted
In feature ranking, feature choice approach ranks the functions in a sure order of measure of relevance. It determines the significance of individual feature and ignores viable interactions of features.
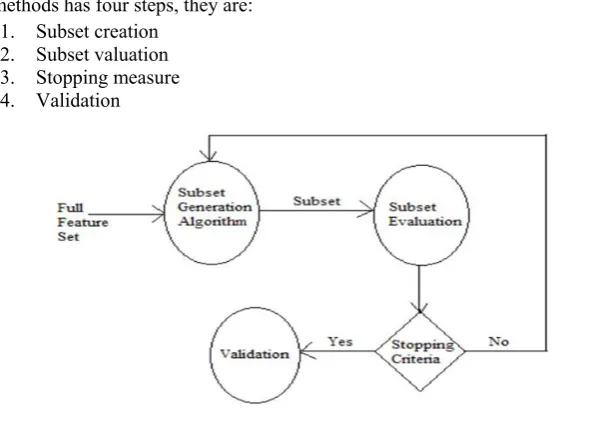
FS methods has four steps, they are: 1. Subset creation
2. Subset valuation 3. Stopping measure 4. Validation
Fig 2. Steps in feature selection.
In this paper Info Gain (IG) standards is exploited for characteristic election. To exploit IG for FS an entropy value of every specific data has to be compute. The entropy price is utilized for ranking functions that affect facts taxonomy. A feature that doesn’t longer have a good deal impact on the statistics class has very lesser data advantage and it could be left out lacking affecting the detection classifier accuracy.
• Random forest (RF): RFas described by way of their originator, Breiman, is collective of timber such
that every tree is built on bootstrapped pattern of the unique data of training. To categorize a brand newest object from an enter vector, the i/p vector will be put down every of the timber inside the forest. Every tree offers a vote to specify the tree’s choice approximately the item class. The forest region elect the class having the typically chooses over the full tress insider the forest region. All forest tree is rise as follows:
1. Let the extensive variety of instances within the unique training statistics is N. Design a bootstrap sample size N from the authentic schooling facts. This pattern can be a make latest training dataset for developing the tree. Data that might be in the unique training info however not inside the bootstrap pattern are known as out-of-bag records.
2. Let the full extensive change of i/p capabilities in the unique training information be M. On this bootstrap pattern info, handiest m attributes are chosen at random for every tree
3. where in m < M. The attributes from this collection makes the great likely break up at all the tree node. The value of m must be constant during the rising of the forest.
8. DATASETDESCRIPTION
In this paper we utilize NSL-KDD dataset [20], a better pattern of KDDCup’99 benchmark IDs dataset. According to the developers of NSL-KDD [20], the key restriction within the KDDCup’99 dataset is the massive extensive kind of needless records. That is 78% schooling records and 75% trying out records are duplicated which motive the studying set of rules to be biased in the direction of the mostly frequent facts, therefore avoid it from knowing minority lessons.
As said in [14] although the NSL-KDD dataset won't be an excellent illustrative for actual n/w facts, it could be applied as powerful benchmark dataset to come across community intrusions. In NSL-KDD dataset, the simulated attack can fall in anyone of the next 4 classes.
• DoS Attack: DoS attack effects thru preventing valid demands to an/w aid thru using consuming the
through overloading computational assets.
• Probing Attack: Probing is a class of attack wherein an attacker scans a community to gather statistics
of goal device earlier to beginning an attack.
• User to Root (U2R) Attack: An attacker begins out with get right of entry to a typical consumer
• Root to Local (R2L) Attack: An attacker who doesn’t have an account on system transmit packet to
that computing device over a community and exploits susceptibilities to acquire regional get right to utilize as a character of that gadget.
The NSL-KDD data set carries a complete of 22 training attack sorts. The distinct attack kinds and their individual lessons in the NSL-KDD education dataset is presented in Table 1. Table II suggests the distribution of the whole NSL-KDD training datasets. The NSL-KDD IDs dataset has 41 functions.
Table 1:Types of attack in NSL-KDD dataset and their categories.
Attack Class Attack Name
DoS Land,Neptune, Teardrop, Pod, Back R2L Guess-password, Ftp-write, Warezclient
U2R Load- module, Per, Buffer-overflow, Probing IP-sweep, Satan, Port-sweep,
9. EXPERIMENTAL SETUP AND RESULTS
In sequence to detect the helpfulness of the proposed framework a proof of content prototype has been implemented utilizing WEKA machine learning tool exploiting NSL-KDD training dataset.
Table 2: NSL-KDD Training Data Distribution
Attack Type No. of records
Normal 67343
Neptune 41214
Satan 3633
Ipsweep 3599
Portsweep 2931
Smurf 2646
Nmap 1493
Back 956
Teardrop 892
Warezclient 890
Pod 201
Guess_pwd 53
Buffer Overflow 30
Wazermaster 20
Land 18
Imap 11
Rootkit 10
Loadmodule 9
Ftpwrite 8
Multihop 7
Phf 4
Perl 3
Spy 2
Table 3:K-MEANS clustering generated result
Normal Majority Class
Neptune Satan
Middle Class Ipsweep
Portsweep Smurf Nmap
Minority Class Back
Teardrop Warezclient Pod Guess_pwd Buffer Overflow Wazermaster Land Imap Rootkit Loadmodule Ftpwrite Multihop Phf Perl Spy
Graph 1: K-means Clusters
On SMOTE generated NSL-KDD training dataset applying the IGdependFS method from The 41 functions the subsequent 19 features are elected in keeping with their IG value:, 3, 4, 6, 12, 23, 24, 25, 26, 29, 30, 33, 34, 35,36, 37, 38 and 39.40.
After that IG depend FS method applied on a two class of SMOTE produced NSL KDD training dataset (minority class, and common classes (usual, Neptune) as one class) this dataset is known as minority classes attack mode dataset.
For this minority classes attack mode dataset, we have found some extra features. Hence the latest function set comprises the subsequent 22 efficient functions: 3, 4, 5, 6, 10, 12, 23, 24, 25,26, 29, 30, 32, 33, 34, 35,36, 37, 38, 39,40, and 41
99.9894% accuracy and FPR reduce to 0.00 and other performance measures Precision, Recall, F-measure and ROC Area also have been improved.
Table 4:SMOTE generated NSL-KDD training data distribution Majority Classes Normal 67343
Neptune 41214
Middle Classes
Satan 3633
Ipsweep 3599
Portsweep 2931
Smurf 2646
Nmap 1493
Minority Classes
Back 8604
Teardrop 8028
Warezclient 8010
Pod 1809
Guess_pwd 477
Buffer Overflow 270
Wazermaster 180
Land 163
Imap 99
Rootkit 90
Loadmodule 81
Ftpwrite 72
Multihop 63
Phf 36
Perl 27
Spy 18
Total 150886
TABLE 5: Result Performance Comparison
Proposed Framework
Random Forest Clustering
+ Smote +
Random Forest
Clustering +
Smote +
Feature Selection +
Random Forest
Clustering +
Smote +
Feature Selection +
Random Forest
No. Of Features 41 41 19 22
taxonomy accuracy
99.8682% 99.8986% 99.8623% 99.9894%
FPR 0.001 0.001 0.001 0.000
Precision 0.999 0.999 0.999 1.000
Recall 0.999 0.999 0.999 1.000
F-measure 0.999 0.999 0.999 1.000
10. CONCLUSION
In this paper, classifier of Random Forest is utilizing for progress the effective IDS. For enhancing the detection rate in imbalanced dataset SMOTE is utilize. Feature selection approach can be utilized for extracting features from intrusion detection database on which further processing is performed. It also gives lessen feature list for the test data preprocessor. The attacks need to be proper classified. For classification, we utilize random forest taxonomy which helps in lessening the false alarm rate and enhancing the detection rate of IDS. Experimental outcomes indicate that our technique extension the grouping accuracy and decrease the false positives rate. And different overall performance measures Recall, F-measure, Precision, ROC Area is the increase in considerable amount.
References
[1] Kumar A., Fernandez E.( 2012): Security Patterns for Intrusion Detection Systems.
[2] Bhadouria A., Patidar E. P., Rawat. M.K. (2014): Survey Paper on Knowledge Based Improved Intrusion Detection System by Means of Information Gain, International Journal of Research in Engineering Technology and Management ISSN 2347 – 7539.
[3] Patel J., Panchal M. K.(2015): Effective Intrusion Detection System using Data Mining Technique, Volume 2, Issue 6 JETIR (ISSN-2349-5162).
[4] Sutha K., Tamilselvi J. J.(2015): A Review of Feature Selection Algorithms for Data Mining Techniques , ISSN : 0975- 3397 Vol. 7 No.6.
[5] Beniwal S., Arora J.(2012): Classification and Feature Selection Techniques in Data Mining, ISSN: 2278-0181, Vol. 1 Issue 6. [6] Pundir S. N., Amrit (2013): Feature Selection using Random Forest in Intrusion Detection System, International Journal of Advances
in Engineering & Technology ©IJAET.
[7] Sandeep D., Chaudhari M.S.(2014): Review on Data Mining Techniques for Intrusion Detection System, International Journal of Innovative Research in Computer and Communication Engineering (An ISO 3297: 2007 Certified Organization) Vol. 2, Issue 1, IJIRCCE.
[8] Chawla N.V., Lazarevic A., Hall L.O., Bowyer K.W.(2003): SMOTE Boost: Improving Prediction of the Minority Class in Boosting ,PKDD 2003, LNAI 2838, pp. 107–119
[9] Cheng Y.,Qiao X.,Wang X.,Yu Q.(2017): Random Forest Classifier for Zero-Shot Learning Based on Relative Attribute, 2162-237X © IEEE.
[10] Rodda S., Erothi U. S. R.(2016): Class Imbalance Problem in the Network IntrusionDetection Systems, International Conference on Electrical, Electronics, and Optimization Techniques (ICEEOT).
[11] Zhou C., Liu B.,Wang S.(2106): CMO-SMOTE: Misclassification Cost Minimization Oriented Synthetic Minority Oversampling Technique for Imbalanced Learning 8th International Conference on Intelligent Human-Machine Systems and Cybernetics, 978-1-5090-0768-4/16 © IEEE.
[12] Gharaee H.,Hosseinvand H.(2106): A New Feature Selection IDS based on Genetic Algorithm and SVM, 8th International Symposium on Telecommunications.
[13] Kaur R.,Kumar G.,Kumar K.,(2105): A Comparative Study of Feature Selection Techniques for Intrusion Detection , 978-9-3805-4416-8/15 IEEE.
[14] Naufal M. F.,Rochimah S.(2015): Software Complexity Metric-based Defect Classification Using FARM with Preprocessing Step CFS and SMOTE International Conference on Information Technology Systems and Innovation (ICITSI) Bandung – Bali, November 16 – 19, 2015 ISBN: 978-1-4673-6664-
[15] Zhang J.,Zulkernine M.,Haque A.(2008): Random-Forests-Based Network IntrusionDetection Systems, IEEE Transactions On Systems, Man, And Cybernetics—Part C: Applications And Reviews, Vol. 38, No. 5.
[16] Azhagusundari B.,Thanamani A.S.(2013): Feature Selection based on Information Gain , International Journal of Innovative Technology and Exploring Engineering (IJITEE), pp 18- 21.
[17] Chaudhary S. Bhowal A.(2015): Comparative analysis of machine learning algorithms alog with classifiers for network intrusion detection system 978-1-4799-9855-5/15/ © IEEE.
[18] Kenaza T.,Zaidi A.(2010): Clustering approach for false alerts reducing in behavioral based intrusion detection systems 978-1-4244-8611-3/10/ ©IEEE
[19] https://github.com/defcom17/NSL_KDD