Research Article
a
May
2019
Computer Science and Software Engineering
ISSN: 2277-128X (Volume-9, Issue-5)
Image Classification Using Convolutional Neural Network
Prof. A. S. Shelar*, Prof. S. K. Patil
CSE Department, TEI, Ichalkaranji, Maharashtra, India
[email protected], [email protected]
Abstract— Scene recognition is a task of computer vision. The project is all about to detect the scene with its attribute and category. Here, it is going to use convolutional neural network (CNN) to detect the scene. Convolutional neural network is effective for image classification. To get accurate results we must learn the deep features of image which is possible with the help of convolutional neural network. Here, we are going to train two specific convolutional neural networks in which one of the convolutional neural network is of object centric and the other is of scene centric. These two networks will work parallel which will reduce the response time of the system and improve the accuracy.
Keywords— Image Classification, Convolutional Neural Network.
I. INTRODUCTION
Scene recognition involves detection of scene in an image. This topic has received great deal of attention in computer vision because of its wide applications such as it’s an important feature for driver-less car. To detect the scene accurately, we are going to use Convolutional neural network (CNN). Neural network is a computational model that works in a similar way to the neurons in the brain. Each neuron takes an input, performs some operations then passes the output to the following neuron. Convolutional neural network is a type of artificial neural network in which the connectivity pattern between its neurons is inspired by the organization of the animal visual cortex. The visual cortex has small regions of cells that are sensitive to specific regions of visual field. Some individual neuronal cells in brain responds onl y in presence of edges of a certain orient action. For example, neurons fires when exposed to vertical edges and some when shown horizontal or diagonal edges.
We are going to teach the computer to recognize the scene in image and classify them into one of the 6 categories such as auditorium, farms, labs etc. For example, we need to recognize the cat in image. To do so, we first need to teach the computer how a cat looks like before it being able to recognize a new object. The more cats the computer sees, the better it gets in recognizing cats. With the help of CNN, the computer will start recognizing the patterns present in cat pictures that are absent from other ones and will start building its own cognition.
Convolutional neural network (CNN) is one of the most popular techniques used in improving the accuracy of image classification. CNN has convolution layer at the beginning which breaks the image into number of tiles, the machine then tries to predict what each tile is. Finally, the computer tries to predict what’s in the picture based on the prediction of all the tiles.
Understanding the world in a single glance is one of the most accomplished feats of the human brain. It takes only a few tens of milliseconds to recognize the category of an object or environment, emphasizing an important role of feed
forward processing in visual recognition.
Project takes image as an input and from that images machine predict the scene categories, Scene types and Scene attributes. These kind of applications are part of the deep learning. We need to train the images with different categories. For training an images we use the convolutional neural network algorithm.
ISSN(E): 2277-128X, ISSN(P): 2277-6451, pp. 20-25
backpropagation. It has trained 30000 images containing 6 categories. For such kind of huge dataset CPU machine is not performed well, so for that we need GPU architecture. GPU performs parallel task, so it helps to reduce training time.
II. LITERATURE REVIEW
Literature survey is the most important step in software development process. Before developing the tool, it is necessary to determine the time factor, economy. Once these things are satisfied, then next steps are to determine which operating system and language can be used to developing the tools. Once the programmer start building the tool the programmer need lots of external support. This support can be obtained from senior friends, teachers, from book or from websites. Before building the system, the above consideration are taken into account for developing the proposed system. It can see the papers as maintained below.
In [1], They measured relative densities and diversities between SUN, IMAGENET and PLACES using AMT (Automated Mechanical Transmission). They introduced PLACES as a new dataset containing 7 million images from 476 places.
In [2], They implemented dataset bias of IMAGENET and PLACES to increases the accuracy up to 70%. In [3], They stated that, Convolutional neural network helps us to simulate human vision which is amazing at scene recognition.
In [4], They improved the PLACES dataset with adding extra 3 million images, containing 900 different categories.
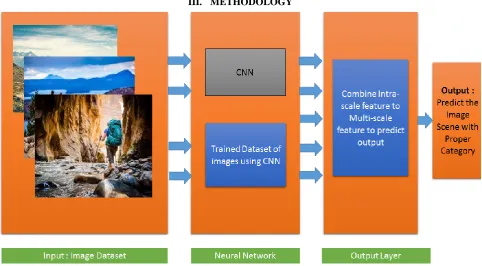
III. METHODOLOGY
Fig. 1 System Architecture for Scene Recognition using CNN
We are going to build three modules. In first module the given input image will be biased into image centric and scene centric. The second module is CNN. We are going to build two specific CNN, one of the CNN will be specifically trained for extracting intra scale features of objects in image, the other CNN will be specifically trained for extracting intra scale features of scene in the image. The last module will combine all the intra scale features and it will predict the accurate scene.
Module 1: Scaled Versions:
The captured images is given as the input and will be biased into image centric and scene centric.
Module 2: Convolutional neural network (CNN).
The biased images are classified with the help of the Convolutional neural network 1. Input layer.
ISSN(E): 2277-128X, ISSN(P): 2277-6451, pp. 20-25
3. Pooling.
4. Fully Connected Layer. 5. Output layer.
Module 3: Output Layer:
The last module i.e. output layer will combine all the intra scale features and it will predict the accurate scene. Intra-scale feature: The output given by the max pooling (CNN) is considered as the intra scale output. Multi-scale features: its combines the all intra-scale feature and predicted the accurate scene.
IV. IMPLEMENTATION DETAILS
In neural networks, Convolutional neural network (ConvNets or CNNs) is one of the main categories to do images recognition, images classifications. Objects detections, recognition faces etc. are some of the areas where CNNs are widely used. CNN image classifications takes an input image, process it and classify it under certain categories. Computers sees an input image as array of pixels and it depends on the image resolution. Based on the image resolution, it will see h x w x d [ h = Height, w = Width, d = Dimension ]. Example An image of 6 x 6 x 3 array of matrix of RGB [3 refers to RGB values] and an image of 4 x 4 x 1 array of matrix of grayscale image.
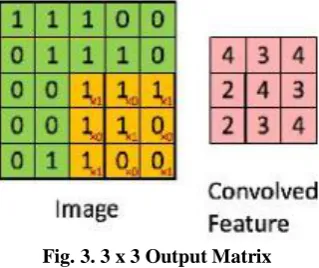
Technically, machine learning CNN models to train and test, each input image will pass it through a series of convolution layers with filters (Kernals), Pooling, fully connected layers (FC) and apply Softmax function to classify an object with probabilistic values between 0 and 1. The below figure is a complete flow of CNN to process an input image and classifies the objects based on values. Convolution Layer means Convolution is the first layer to extract features from an input image. Convolution preserves the relationship between pixels by learning image features using small squares of input data. It is a mathematical operation that takes two inputs such as image matrix and a filter or kernel. Consider a 5 x 5 whose image pixel values are 0, 1 and filter matrix 3 x 3 as shown in below,
Fig. 2 Image matrix multiplies filter matrix.
Then the convolution of 5 x 5 image matrix multiplies with 3 x 3 filter matrix which is called “Feature Map” as output shown in below,
Fig. 3. 3 x 3 Output Matrix
Convolution of an image with different filters can perform operations such as edge detection, blur and sharpen by applying filters. The below example shows various convolution image after applying different types of filters (Kernels).
ISSN(E): 2277-128X, ISSN(P): 2277-6451, pp. 20-25
Fig. 4. Stride of 2 pixels
Padding
Sometimes filter does not fit perfectly fit the input image. We have two options: • Pad the picture with zeros (zero-padding) so that it fits.
• Drop the part of the image where the filter did not fit. This is called valid padding which keeps only valid part of the image.
Non Linearity (ReLU)
ReLU stands for Rectified Linear Unit for a non-linear operation. The output is
ƒ(x) = max(0,x).
Why ReLU is important: ReLU’s purpose is to introduce non-linearity in our ConvNet. Since, the real world data would want our ConvNet to learn would be non-negative linear values.
There are other non linear functions such as tan(h) or sigmoid can also be used instead of ReLU. Most of the data scientists uses ReLU since performance wise ReLU is better than other two.
1. Pooling Layer: Pooling layers section would reduce the number of parameters when the images are too large. Spatial pooling also called subsampling or downsampling which reduces the dimensionality of each map but retains the important information. Spatial pooling can be of different types:
• Max Pooling • Average Pooling • Sum Pooling
Max pooling take the largest element from the rectified feature map. Taking the largest element could also take the average pooling. Sum of all elements in the feature map call as sum pooling.
Fig. 5 Max Pooling
ISSN(E): 2277-128X, ISSN(P): 2277-6451, pp. 20-25
Fig. 6. After Pooling Layer, Flattened as FC layer
In the Fig.6, feature map matrix will be converted as vector (x1, x2, x3,…). With the fully connected layers, we combined these features together to create a model. Finally, we have an activation function such as softmax or sigmoid to classify the outputs.
V. EXPERIMENTAL EVALUATION
The main building block of CNN is the convolutional layer. Convolution is a mathematical operation to merge two sets of information. In our case the convolution is applied on the input data using a convolution filter to produce a feature map. There are a lot of terms being used so let’s visualize them one by one. We perform the convolution operation by sliding this filter over the input. At every location, we do element-wise matrix multiplication and sum the result. This sum goes into the feature map.
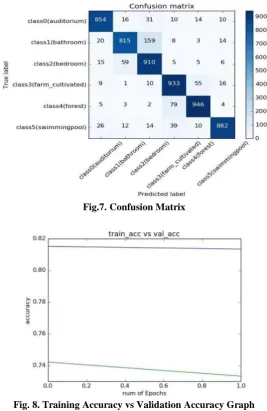
Confusion matrix yielded by the proposed CNN method (without temporal smoothing) on the Opportunity Activity Recognition dataset for Subject 1 (the larger the value the darker the background)
Fig.7. Confusion Matrix
ISSN(E): 2277-128X, ISSN(P): 2277-6451, pp. 20-25
Fig.9. Training Loss Chart
VI. CONCLUSIONS
Convolutional Neural Network is widely used concept in recent era to solve the problems like data classification mainly image classification. Here, the scene recognition is carried out using artificial neural network and scene is classified into different categories. The image dataset is trained using GPUs massively multithreaded environment and result is achieved. In future still optimization of neural network is possible by adding hybrid intelligence into it.
REFERENCES
[1] Bolei Zhou1, Agata Lapedriza1,3, Jianxiong Xiao2, Antonio Torralba1, and Aude Oliva1, “Learning Deep Features for Scene Recognition using Places Database”. Massachusetts Institute of Technology, Priceton University. (2015)
[2] Luis Herranz, Shuqiang Jiang, Xiangyang Li,“Scene recognition with CNNs: objects, scales and dataset bias”. IEEE Conference on Computer Vision and Pattern Recognition. (2016)
[3] Bavin Ondieki,“Convolutional Neural Networks for Scene Recognition” Stanford University.(2016)