http://dx.doi.org/10.4236/jcc.2014.29013
Semantic Recognition of a Data Structure in
Big-Data
Aïcha Ben Salem
1,2, Faouzi Boufares
1, Sebastiao Correia
21Laboratory LIPN-UMR 7030-CNRS, University Paris 13, Sorbonne Paris Cité, Villetaneuse, France 2Company Talend, Suresnes, France
Email: [email protected], [email protected], [email protected], [email protected]
Received April 2014
Abstract
Data governance is a subject that is becoming increasingly important in business and government. In fact, good governance data allows improved interactions between employees of one or more organizations. Data quality represents a great challenge because the cost of non-quality can be very high. Therefore the use of data quality becomes an absolute necessity within an organization. To improve the data quality in a Big-Data source, our purpose, in this paper, is to add semantics to data and help user to recognize the Big-Data schema. The originality of this approach lies in the semantic aspect it offers. It detects issues in data and proposes a data schema by applying a se- mantic data profiling.
Keywords
Data Quality, Big-Data, Semantic Data Profiling, Data Dictionary, Regular Expressions, Ontology
1. Introduction
The general management and business managers must have a unified vision and usable information to make the right decisions at the right time. The data quality governance has become an important topic in companies. Its purpose is to provide accurate, comprehensive, timely and consistent data by implementing understandable in- dicators, easy to communicate, inexpensive and simple to calculate. In the big-data era, the quality of the infor- mation contained in a variety of data sources, is becoming a real challenge.
Data quality and semantics aspects are rarely joined in the literature [1]-[3]. Our challenge is to use semantics to improve the data quality. Indeed, misunderstanding of the data schema is an obstacle to define a good strategy to correct any anomalies in the data. Very often metadata are not enough for understanding the meaning of data.
of the string “16˚C” which is a city temperature in degree Celsius.
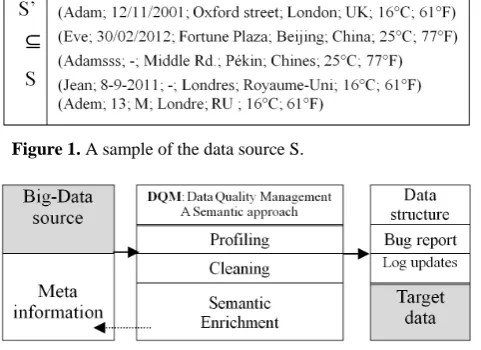
Let S be an unstructured data source, result of integration of multiple heterogeneous data sources. S can be seen as a set of strings, separated by semicolons (;). S can then be described by the set C of all its columns. One note S(C) the data schema. Notice that the source S has no defined structure, which can cause a problem for se- mantic data manipulation. S may contain inconsistences (Figure 1). Several questions arise such as: 1) what are the semantics of strings? 2) What are the languages used? 3) What is invalid and what is not?
Let us remark that this source has several columns. S is defined by (Coli, i = 1;7).
In the data source S, the column Col4 should contain only cities given in English. London and Beijing are syntactically and semantically valid. While, “Pékin” and “Londres” are syntactically correct and semantically invalid. “Londre” is syntactically invalid. The Col2 column contains mostly dates. Therefore, the “13” value will be considered semantically invalid. This demonstrates the need of more semantics to understand and correct the data.
This paper is organized as follows. The second section presents the meta-information required for the seman-tic data structure. The semanseman-tic data profiling process is given in the third section. Our contribution and future works are given in conclusion.
2. Meta-Information
We discussed in the previous works [9] [10] various problems of data quality in particular the deduplication one. We started the development of a new kind of Big-Data ETL based on semantic aspects. It allows data profiling, data cleaning and data enrichment.
To assist the user in his quality approach, the originality of our work lies in: semantic recognition of descrip- tive data schema and hence fortification data themselves. We will focus, in this paper, to the data profiling step.
Data profiling presents the first step in the data quality process (DQM tool Figure 2). It is a quantitative ana- lysis of the data source to identify data quality problems. It includes descriptive information such as schema, ta-ble, domain and data sources definitions. As a result, data profiling collects summaries of the data source (Number of records, attributes) [11] [12].
However, existing data profiling tools [13]-[16] provide a statistical data profiling and do not address the se- mantic aspects. For that, the purpose of this paper is to introduce some semantic indicators to enrich the data profiling process and propose a semantic one.
For the semantic data profiling, we propose for each input data source S, a bug report, log for updates and a new semantic structure using some meta-information.
The bug report contains the various existing anomalies in the data source: more than one category and lan- guage used for the same column, different data formats, duplicates, null values.
[image:2.595.195.436.535.710.2]Log for updates is the set of update actions to be applied to a data source such as translation in the same lan- guage, homogenization in the same format. These updates cover one column at a time. In order to make corrections
Figure 1. A sample of the data source S.
between columns, the concept of functional dependencies has to be applied.
This meta-information can be enriched over the time (more details will be presented in the Section 3.3). In the following, we will be interested in the semantic data profiling process details (presented in Figure 3) and in particular to the meta-information.
The meta-information consists of three components: the Meta-Schema-Ontology (MSO), the Meta-Repository (MR) composed by the DD and RE and the list I of indicators.
Several tables (Tk, k = 1,7) are used to store the different artefacts corresponding to the results of the seman-
tic data profiling process.
Let us start by defining the first component, the Meta-Schema-Ontology (MSO).
2.1. Meta-Schema-Ontology
A database, as a set of information, can be described in many different ways. The difference is mainly in the name of concepts and attributes.
The idea with the MSO is to store all these equivalent descriptions in a meta-structure. The Meta is presented with the UML [17] (Unified Modeling Language) class diagram (Figure 4).
MSO is a set of knowledge that can be managed as ontologies [18]-[22]. Ontology is a formal language. It is a grammar that defines how terms may be used together. Ontologies allow sharing a common understanding of the information structure among people.
Many instances (knowledge) can be created from the MSO. For instance, Person, Organization and Invoice
are three Concepts. Each of them may have several synonyms.
[image:3.595.227.402.379.520.2]For instance, the concept Person can have many synonyms such as Client, Student and Customer. The con- cept Person is defined by some Attributes like FirstName, Address, City, Country and BirthDate. This implies that each synonym of the concept Person can be defined in a similar manner. The ontology is viewed with the
Figure 3. The semantic data profiling process.
[image:3.595.193.436.547.700.2]open source Protégé tool [23] (Figure 5).
This knowledge can evolve over the time according to different descriptions of the databases and it can be represented as a meta-repository.
2.2. Meta-Repository
The meta-repository is a set of knowledge describing the data dictionary (set of categories in different languag- es), regular expressions and a list of indicators (statistical, syntactic and semantic).
2.2.1. Data Dictionary
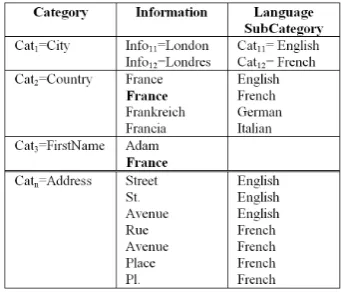
Valid strings (syntactically and semantically) can be grouped into categories. Categories describe concepts. These descriptions (strings) can be in several languages. They may also contain sub-categories. The set of cate- gories Catext can be seen as a data dictionary. For example, the monument category will contain all valid strings describing the airports, universities, hospitals, museums and castles names. The names of cities, countries and continents where are these monuments, are also part of data dictionary (DD).
Let Catext be the set of categories defined by extension: Catext = {Cati, i = 1;n} with Cati belongs to {FirstName,
Country, City, Civility, Gender, Email, Web Site, Phone Number}. For each Cati, a set of sub-categories SubCat
= {Catij, j = 1;m} can be defined. In this study, language is used as a sub-category. The set of languages used is
Lang = {English, French, German, Italian, Portuguese, Spanish}.
We define the DD as a set of triplets of (Category, Information, Language). A category Cati is then defined by
extension where Information is a valid string, Category ∈ Catext and Language ∈ Lang.
[image:4.595.132.500.369.528.2]Note that, as mentioned in the Figure 6, the information “France” can refer to two categories in the same time: Country and FirstName. Other exceptions may exist.
Figure 5. An instance of the Meta-Schema-Ontology under Protégé.
[image:4.595.227.398.558.704.2]2.2.2. Regular Expressions
A category Kati can also be defined by intention using regular expressions (RE). These are used to validate the
syntactic and semantic of strings. Let Katint be the set of these categories.
RE can be defined as a set of pairs Catregex (Category, Regular-Expressions).
[image:5.595.200.427.437.538.2]RE = {Catregexi/Catregexi (Kati, Regexij); i = 1...p, j = 1...q}. Some instances of categories are presented in
Figure 7.
2.2.3. Indicators
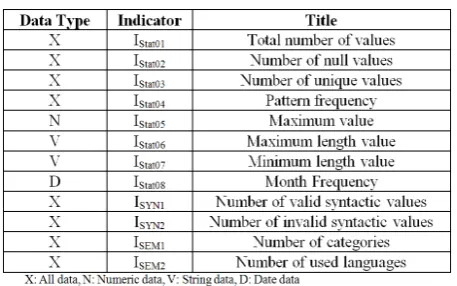
The semantic data profiling is based on a set I of p indicators applied to the data source. Most of the existing tools are interested only in quantitative summaries of the source data. Few tools focus on semantic analysis. For that, we propose semantic indicators. I is composed of three types of indicators (Figure 8): statistic indicators {Istati, i = 1;p}, two syntactic indicators (ISYN1,2) and two semantic ones (ISEM1,2).
After presenting in this paragraph, the input data for semantic data profiling, we will outline below, the process itself.
3. Semantic Data Profiling Process
Let us give some notations and definitions used in the algorithm of the semantic data profiling process.
Each column Ci, belonging to the data source S, has a set of values vi (i = 1...n). Each vi has a data type such
as {String, Number, Date, Boolean, list or range of values}.
Definition 1: Syntactic validity of a value v
A value v is syntactically valid if and only if (iff) v ∈ RE or v ≈ w ∈ DD. (≈means similar using similar- ity distances [5] [6]).
Definition 2: Syntactic invalidity of a value v
A value v is syntactically invalid iff v ∉ RE and v ∉ DD.
Definition 3: Dominant Category
Let Cati(v) be the number of syntactically correct values for a given attribute.
A Cati is a dominant category iff Cati(v) > Catj(v) with i ≠ j.
[image:5.595.200.429.559.702.2]The “Number of categories” indicator defines the number of categories detected.
Figure 7. A set of regular expressions.
Definition 4: Semantic validity of a value v
A value v is semantically valid iff v ∈ Cati, and Cati is the dominant category.
Definition 5: Semantic invalidity of a value v
A value v is semantically invalid iff v ∉Cati, and Cati is the dominant category.
3.1. Profiling Algorithm
The principle of semantic data profiling algorithm (Figure 9) is to check if a value v belongs to the meta-repo- sitory. The aim is to verify the syntactic and semantic validity of v.
Given the data source S and the meta-information as inputs, the algorithm returns several tables (Tk, k = 1,7).
These contain indicators results, invalid syntactic data, valid syntactic data, invalid semantic category-data, invalid semantic language-data and the new semantic structure.
The statistic Indicators function consists on applying different statistical indicators for a general summary (total number of values, number of duplicate values, pattern frequency) or according to the data type such as year Frequency, Maximum Length, Minimum Length.
The role of the semantic Recognition Structure function is trying to find a category and language for each data (v) using RE or DD. The three steps below will describe the principle of this function. Note that if v is a string, several possibilities are considered. Two types of research are used according to the presence or absence of keywords.
The first step is to check if v satisfies the definition 1. v is then considered syntactically valid. Then, we check the semantic validity (definition 4) using the dominant category concept (definition 3). This step allows obtain- ing the category and language for each column.
The second step deals, in one hand, with semantically invalid values (definition 5), remind that they are syn- tactically correct. In the other hand, this step processes with syntactically invalid ones (definition 2).
In the third step, the syntactically correct and semantically incorrect values are handled in several ways. Ac- cording to their membership to the dominant category and the selected language, updates are automatically pro- posed such as homogenization, translation and standardization.
Whenever, the syntactically invalid values are well spelled (satisfy some regular expressions), they can be used to enrich the DD.
As there may be several languages for each column, not only one has to choose the dominant language col- umn but also the dominant language of the source studied. The principle is presented in the semantic Language function.
The details of these functions (statistic Indicators, semantic Recognition Structure, semantic Language) are presented in Appendix (Figure A1).
The following paragraph will present the intermediate results.
3.2. Profiling Results
[image:6.595.237.387.564.703.2]Several tables are used to store the different artefacts corresponding to the results of the semantic data profiling process.
The first one contains indicators results. For each column, we have some statistical summaries (e.g. percen- tage of null values), the number of invalid syntax values, the number of valid syntax values, the number of de- tected categories and number of detected languages.
The misspelled values are automatically added to the invalid syntax table (second table).
The third table contains the values, syntactically correct, which do not belong to Meta-Repository. They will be designated unknown categories.
For each column of the data source, we can have more than one category. So, to validate the dominant cate- gory, we choose the one with the greater percentage. The percentage is calculated based on the number of values that belong to this category. If we have two categories with the same percentage, we choose another sample from the data source and apply the semantic data profiling.
The values that do not belong to the dominant category are stored in the table T4 as semantic invalid catego- ry-value. In the same way, values that do not belong to the dominant language are stored in the table T5 as se- mantic invalid language-value.
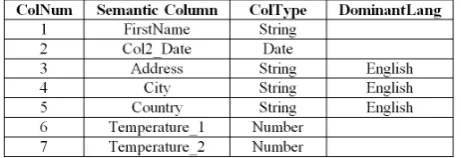
Note that each column Ci of the source S is seen initially as a string. The goal is to recognize its semantic
meaning (Figure 10). The dominant category and language are used to define the semantic structure for a data source.
Data source may contain similar columns, noted Coli≤ Colj. For instance, Temperature_1 and Temperature_2
columns are similar categories (Col6≤ Col7). When two columns Coli and Colj belong to the same semantic
cat-egory and have the same content (Coli = Colj), one of the two columns should be deleted.
3.3. Semantic Enrichment
As mentioned before, the meta-information must be enriched with new information. Both the data dictionary and the Meta-Schema-Ontology can be enriched.
The content of the DD may evolve using the values in T3, which must exist in some lexical databases suchas WordNet [24] and WOLF [25]. Similarly, when new categories are discovered after the semantic data profiling, the Meta-Schema-Ontology is expanded using new Attributes and their synonyms synAttributes.
Users can also enrich the meta-information with new regular expressions.
4. Conclusions and Contribution
Big data often have even less metadata than usual databases and that's a problem when the data scientist wants to perform analyses on these data. The use of our DQM tool would help the data scientist in recognizing data types (integer, dates, strings) and data semantics (Email, FirstName, Phone). The semantics would then be useful to automatically suggest views on data with a semantic meaning or to find matches between heterogeneous struc- tures in big data.
DQM tool that we are currently developing is a contribution to new generation of Big-Data ETL based on semantics. Our goal is to guide the user in his quality approach.
In the case of the absence of the data structure, we help the user:
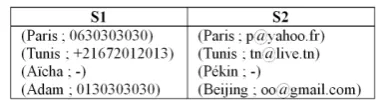
[image:7.595.199.430.626.705.2]1) To understand more the definition of manipulated data. Indeed, during the integration process for the union or the join operations, it is essential to differentiate synonyms and homonyms to succeed semantic data integra- tion. Existing tools [14]-[16] [26] do not take into account semantic aspects. Only the syntactic ones are consi- dered. For instance, in the case of the data integration process, user can choose to join two columns syntactically equivalent but semantically not S1.Col1 and S2.Col1 can be synonyms or homonyms (Figure 11). The union of S1 and S2 is semantically meaningless, while existing tools allow this operation. DQM tool alerts users to
Figure 11. Integration of the data sources S1 and S2.
Figure 12. Target data with cleaning actions.
incompatible semantic integration operations.
2) Throughout the laborious cleaning step. Transformation and homogenization that we propose will allow better elimination of duplicate or similar tuples. In fact, recalling that no method of calculating similarity dis- tance permits the approximation between Pékin and Beijing, for example, because information on the language used is not taken into account. Our approach allows this reconciliation.
The originality of our approach is to infer the semantics of the data source structure using on one hand, the data itself and on the other hand, instances of the Meta-Schema-Ontology. Furthermore, our approach allows us to automatically propose cleaning actions on unstructured data. This constitutes part of our current and future work using MapReduce concepts [13] [27].
The results of the data profiling process are: 1) a data structure for better understanding of the semantic con-tent of Big Data, 2) a set of updates for the correction of invalid data.
The semantic structure of the Big-Data source is: S (Col1_FirstName: String, Col2_Date: Date, Col3_Address: String, Col4_City: String,
Col5_Country: String, Col6_Temperature_1: Number, Col7_Temperature_2: Number).
The target data after the cleaning actions should be for instance (Figure 12).
References
[1] Becker, J., Matzner, M., Müller, O. and Winkelmann, A. (2008) Towards a Semantic Data Quality Management— Using Ontologies to Assess Master Data Quality in Retailing. Proceedings of the Fourteenth Americas Conference on Information Systems (AMCIS’08), Toronto.
[2] Madnick, S. and Zhu, H. (2005) Improving Data Quality through Effective Use of Data Semantics. Working Paper CISL#2005-08, 1-19.
[3] Wang, X., Hamilton, J-H. and Bither, Y. (2005) An Ontology-Based Approach to Data Cleaning. Technical Report CS-2005-05, 1-10.
[4] Köpcke, H. and Rahm, E. (2009) Frameworks for Entity Matching: A Comparison. Data Knowledge Engineering (DKE’09), Leipzig, 197-210.
[5] Bilenko, M. and Mooney, R.J. (2003) Adaptive Duplicate Detection Using Learnable String Similarity Measures. Pro- ceedings of the Ninth ACM SIGKDD International Conference on Knowledge Discovery, and Data Mining, Washing- ton DC, 39-48. http://dx.doi.org/10.1145/956750.956759
[6] Koudas, N., Sarawagi, S. and Srivastava, D. (2006) Record Linkage: Similarity Measures and Algorithms. In: ACM SIGMOD’06, International Conference on Management of Data, Chicago, 802-803.
[7] Cohen, W.W. and Richman, J. (2004) Iterative Record Linkage for Cleaning and Integration. Proceedings of the 9th ACM SIGMOD Workshop on Research Issues in Data Mining and Knowledge Discovery (DMKD’04), Paris, 11-18.
[9] Boufarès, F., Ben Salem, A., Rehab, M. and Correia, S. (2013) Similar Elimination Data: MFB Algorithm. IEEE 2013 International Conference on Control, Decision and Information Technologies (CODIT’13), Hammamet, 6-8 May 2013, 289-293.
[10] Boufarés, F., Ben-Salem, A. and Correia, S. (2012) Qualité de données dans les entrepôts de données: Elimination des similaires. 8èmes Journées francophones sur les Entrepôts de Données et l’Analyse en ligne (EDA’12), Bordeaux, 32-41.
[11] Berti-Équille, L. (2007) Quality Awereness for Managing and Mining Data. HDR, Rennes.
[12] Tamraparni, D., Theodore, J., Muthukrishnan, S. and Vladislav, S. (2002) Mining Database Structure; or, How to Build a Data Quality Browser. Proceedings of the ACM SIGMOD International Conference on Management of Data, (SIGMOD’02), Madison, 2002, 240-251.
[13] Dean, J. and Ghemawat, S. (2004) MapReduce: Simplified Data Processing on Large Clusters. 6th Symposium on Op- erating System Design and Implementation (OSDI’04), San Francisco, 6-8 December 2004, 137-150.
[14] Data Cleaner, Reference Documentation, 2008-2013, datacleaner.org.
[15] (2011) Oracle Warehouse Builder Data Modeling, ETL, and Data Quality Guide, Performing Data Profiling.
http://docs.oracle.com/cd/E11882_01/owb.112/e10935/data_profiling.htm#WBETL18000
[16] Datiris Profiler. http://www.datiris.com/
[17] UML. http://www.uml.org/
[18] Noy, N.F. and McGuinness, D.L. (2001) Ontology Development 101: A Guide to Creating Your First Ontology. Stan- ford Knowledge Systems Laboratory Technical Report KSL-01-05 and Stanford Medical Informatics Technical Report SMI-2001-0880, 1-25.
[19] Bechhofer, S. (2012) Ontologies and Vocabularies. Presentation at the 9th Summer School on Ontology Engineering and the Semantic Web (SSSW’12), Cercedilla.
[20] Hauswirth, M. (2012) Linking the Real World. Presentation at the 9th Summer School on Ontology Engineering and the Semantic Web (SSSW’12), Cercedilla.
[21] Herman, I. (2012) Semantic Web Activities@W3C. Presentation at the 9th Summer School on Ontology Engineering and the Semantic Web (SSSW’12), Cercedilla.
[22] Kamel, M. and Aussenac-Gilles, N. (2009) Construction automatique d’ontologies à partir de spécification de bases de données. Actes des 20èmes Journées Francophones d'Ingénierie des Connaissances (IC), Hammamet, 85-96.
[23] Protégé Tool. http://protege.stanford.edu/
[24] Wordnet Database. http://wordnet.princeton.edu/
[25] WOLF Database. http://alpage.inria.fr/~sagot/wolf-en.html
[26] Talend Data Profiling. http://fr.talend.com/resource/data-profiling.html
Appendix
Function statisticIndicators (Column C)
//return statistical indicators results
Begin
For each Id from I do //d=1..18
Add(Id (C), T1c)
//statistic indicators: total number of values, number of null values…
end for
EndstatisticIndicators
Function semanticLanguage (Data Source S’)
//return the dominant language
Begin
For eachLanguagei from T7 (i=1..n) //T7 is the semantic structure
ni:= Count the number of occurrences (Languagei)
End for
DominantLanguage := Language where Max(ni)
End semanticCategories
Function semanticCategories (Column C)
//return syntactic and semantic indicators results and semantic structure
Begin
For each vjfrom C do //j=1..m (m number of tuples)
Ifvj∈ RE
thenadd(vj, Catj, Langj) // vj∈Catjandvj∈Langj
elseifvjcheckSpelling=true
//verifies some regular expressions for strings
then if vj≈ w∈ DD //w a value from DD
thenadd(vj, Catj’, Langj’)//vj∈Catj’
andvj∈Langj’; j’≠j
else add(vj, CatUNKNOWN)
//vj∈Unknown Category
add(vj, T3c) //vj is a candidate to enrich DD
end if
else add(vj, T2c)
end if end If End for
add(Isem1(C), T1c) //number of used categories
add(Isem2(C), T1c) //number of used languages
add(Isyn1(C), T1c) //number of valid syntax value
add(Isyn2(C), T1c) //number of invalid semantic value
add((Catdom, Langdom), T7c) where %Catdom =Max(%Catp) //p=1..x
and %Langdom =Max(%Langq) //q=1..y
add(Catp’, T4c)where p’ ≠ p
add(Langq’, T5c)where q’ ≠ q
[image:10.595.170.420.98.534.2]EndsemanticCategories