International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, Volume 2, Issue 5, May 2012)183
Privacy Preserving Data mining with Reduced Communication
overhead
Binu Midhun
1, Prof. Ajay Rana
21,2 Department of Computer Science, Amity University, Noida, India
1[email protected] 2[email protected]
Abstract—In today's world privacy and security are more essential elements when data is shared.A fruitful direction for future data mining research will be the development of techniques that incorporate privacy concerns. Most of the methods use random permutation techniques to mask the data, for preserving the privacy of sensitive data. The approaches for privacy preserving data mining suffer from
high communication and computation overheads. A
distributed scenario is considered in this work, where data is partitioned vertically over multiple databases. The proposed algorithm uses standard k-means clustering algorithm where the attributes of an entity are present in different party`s databases. Finally all the parties will know about the entities assigned to each cluster and the mean corresponding to their own attributes, but not the attributes present with other party. The proposed algorithm is tested with four bench-mark datasets, which are taken from UCI Machine Learning Repository and found that the proposed algorithm gives less communication cost.
Keywords— Privacy Preserving, K-means, Clustering
Algorithm, Low communication overhead, vertically
partitioned data.
I. INTRODUCTION
The problem of privacy-preserving data mining has become more important in recent years because of the increasing ability to store personal data about users, and the increasing sophistication of data mining algorithms to leverage this information. A number of techniques such as randomization and k-anonymity have been suggested in recent years in order to perform privacy-preserving data mining. Furthermore, the problem has been discussed in multiple communities such as the database community, the statistical disclosure control community and the cryptography community. In some cases, the different communities have explored parallel lines of work which are quite similar.
A. The key directions in the field of privacy-preserving data mining are as follows:
Privacy-preserving data publishing
These techniques tend to study different transformation methods associated with privacy.
These techniques include methods such as randomization, k-anonymity, and l-diversity. Another related issue is how the perturbed data can be used in conjunction with classical data mining methods such as association rule mining. Other related problems include that of determining privacy-preserving methods to keep the underlying data useful (utility-based methods), or the problem of studying the different definitions of privacy, and how they compare in terms of effectiveness in different scenarios.
Changing the results of Data Mining Applications to preserve privacy
In many cases, the results of data mining applications such as association rule or classification rule mining can compromise the privacy of the data. This has spawned a field of privacy in which the results of data mining algorithms such as association rule mining are modified in order to preserve the privacy of the data. Classic examples of such techniques are association rule hiding methods, in which some of the association rules are suppressed in order to preserve privacy.
Query Auditing
Such methods are akin to the previous case of modifying the results of data mining algorithms. Here, we are either modifying for restricting the results of queries.
Cryptographic Methods for Distributed Privacy
In many cases, the data may be distributed across multiple sites, and the owners of the data across these different sites may wish to compute a common function. In such cases, a variety of cryptographic protocols may be used in order to communicate among the different sites, so that secure function computation is possible without revealing sensitive information.
Theoretical Challenges in High Dimensionality
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, Volume 2, Issue 5, May 2012)184
B. A look at the key stream mining problems and the challenges associated with each problem:
Statistical Methods for Disclosure Control
The topic of privacy-preserving data mining has often been studied extensively by the data mining community without sufficient attention to the work done by the conventional work done by the statistical disclosure control community. Detailed methods for statistical disclosure control have been will be studied along with some of the relationships to the parallel work done in the database and data mining community. This includes methods such as k-anonymity, swapping, randomization, micro aggregation and synthetic data generation.
Measures of Anonymity
There are a very large number of definitions of anonymity in the privacy-preserving data mining field. This is partially because of the varying goals of different privacy-preserving data mining algorithms. For example, methods such as k-anonymity, l-diversity and t-closeness are all designed to prevent identification, though the final goal is to preserve the underlying sensitive information. Each of these methods is designed to prevent disclosure of sensitive information in a different way.
The k-anonymity Method
An important method for privacy de-identification is the method of anonymity. The motivating factor behind the k-anonymity technique is that many attributes in the data can often be considered pseudo-identifiers which can be used in conjunction with public records in order to uniquely identify the records. For example, if the identifications from the records are removed, attributes such as the birth date and zip-code can be used in order to uniquely identify the identities of the underlying records. The idea in k-anonymity is to reduce the granularity of representation of the data in such a way that a given record cannot be distinguished from at least (k − 1) other records.
The Randomization Method
The randomization technique uses data distortion methods in order to create private representations of the records. In most cases, the individual records cannot be recovered, but only aggregate distributions can be recovered. These aggregate distributions can be used for data mining purposes.
Quantification of Privacy
A key issue in measuring the security of different privacy-preservation methods is the way in which the underlying privacy is quantified. The idea in privacy quantification is to measure the risk of disclosure for a given level of perturbation.
Utility Based Privacy-Preserving Data Mining
Most privacy-preserving data mining methods apply a transformation which reduces the effectiveness of the underlying data when it is applied to data mining methods or algorithms. In fact, there is a natural trade off between privacy and accuracy, though this trade off is affected by the particular algorithm which is used for privacy-preservation.
A key issue is to maintain maximum utility of the data without compromising the underlying privacy constraints.
Mining Association Rules under Privacy Constraints
There are two aspects to the privacy preserving association rule mining problem: When the input to the data is perturbed, it is a challenging problem to accurately determine the association rules on the perturbed data.
A different issue is that of output association rule privacy. In this case, we try to ensure that none of the association rules in the output result is in leakage of sensitive data. This problem is referred to as association rule hiding by the database community, and that of contingency table privacy-preservation by the statistical community.
Cryptographic Methods for Information Sharing and Privacy
In many cases, multiple parties may wish to share aggregate private data, without leaking any sensitive information at their end. For example, different superstores with sensitive sales data may wish to coordinate among themselves in knowing aggregate trends without leaking the trends of their individual stores. This requires secure and cryptographic protocols for sharing the information across the different parties. The data may be distributed in two ways across different sites:
Horizontal Partitioning
In this case, the different sites may have different sets of records containing the same attributes.
Vertical Partitioning
In this case, the different sites may have different attributes of the same sets of records.
Privacy Attacks
It is useful to examine the different ways in which one can make adversarial attacks on privacy-transformed data. This helps in designing more effective privacy-transformation methods. Some examples of methods which can be used in order to attack the privacy of the underlying data include SVD-based methods, spectral filtering methods and background knowledge attacks.
Query Auditing and Inference Control
Many private databases are open to querying. This can compromise the security of the results, when the adversary can use different kinds of queries in order to undermine the security of the data. For example, a combination of range queries can be used in order to narrow down the possibilities for that record. Therefore, the results over multiple queries can be combined in order to uniquely identify a record, or at
least reduce the uncertainty in identifying it. There are two primary methods for preventing this kind of attack:
Query Output Perturbation
In this case, we add noise to the output of the query result in order to preserve privacy.
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, Volume 2, Issue 5, May 2012)185
Query Auditing
In this case, we choose to deny a subset of the queries, so that the particular combination of queries cannot be used in order to violate the privacy.
Privacy and the Dimensionality Curse
In recent years, it has been observed that many privacy-preservation methods such as k-anonymity and randomization are not very effective in the high dimensional case.
Personalized Privacy Preservation
In many applications, different subjects have different requirements for privacy. For example, a brokerage customer with a very large account would likely have a much higher level of privacy-protection than a customer with a lower level of privacy protection. In such case, it is necessary to personalize the privacy-protection algorithm. In personalized privacy-preservation, we construct anonymous of the data such that different records have a different level of privacy.
Privacy-Preservation of Data Streams
A new topic in the area of privacy preserving data mining is that of data streams, in which data grows rapidly at an unlimited rate. In such cases, the problem of privacy-preservation is quite challenging since the data is being released incrementally. In addition, the fast nature of data streams obviates the possibility of using the past history of the data. We note that both the topics of data streams and privacy-preserving data mining are relatively new, and there has not been much work on combining the two topics.
C. Problem Definition
To cluster the distributed data among the parties, to provide privacy among the parties while sharing the permuted distances by using random permutation technique and to reduce communication overhead.
Clustering
Clustering is the process of grouping of similar objects together. Protocols based on statistics and cryptography was proposed for providing privacy and clustering in centralized and distributed scenarios [1]. A distributed scenario is considered in which data is vertically partitioned i.e. the different attributes of an entity are found in different databases. The task is performed using k-means clustering algorithm for gathering data from different sites for a single entity [4]. The k-means clustering is a simple and best partitioned technique to group items into k clusters. The basic idea of k-means is to place each item into its closest cluster, and then the cluster centres are adjusted based on the assigned data. The random permutation technique [5, 7] is mainly used to hide the original data by modifying the original data with randomly generated values, so that the actual values are not learned. Random permutation technique is mostly used in areas like cryptography, simulations, coding theory etc [7]. Most of the privacy preserving algorithms implement random permutation technique, where data is present in different sites.
II. RELATED WORK
Mahir et al. [1] proposed an algorithm for sharing of data among the parties in an organization. In this paper [1] authors worked with k-means clustering algorithm to assign the entity to the closest cluster. Authors considered a scenario in which data is distributed vertically over multiple sites. Authors used Additive secret sharing mechanism to reduce computation cost. Vaidya et al. [2] proposed privacy preserving g k-means clustering algorithm for clustering data from different parties i.e. data is partitioned vertically over multiple sites. Authors worked with Pailliar public key mechanism with 1024 bit key and 1024 bit block size is used. The communication cost of the algorithm is very high. Random permutation technique [1, 5] is used to hide the sensitive data by randomly modifying the data values and often using additive noise with the data so that the actual values in the datasets are not learned. The work of Mahir et al. [1] and Agrawal and Srikanth [3] fall in this category. The work by Kargupta et al. [5] states that random projection based multiplicative data permutation is a very efficient way to perform privacy preserving distributed data mining. The Multi-Party Computation (MPC) technique is a generalized approach of Secure Multi-Party Computation (SMC) technique [1, 10]. In an MPC, a number of participants P1; P2;:::;Pn each has a private data, D1;D2; :::;Dn respectively. The participants want to perform a public function F on n variables on the data 4 point (D1;D2; :::;Dn). The MPC protocol provide security such that no participant can learn more from the description of the public function and the final result. Kargupta et al. [5] considered a set of techniques for privacy-preserving data mining by randomly permuting the data while preserving the basic probabilistic properties. It explores the random-value permutation technique (Agrawal and Srikanth [3]), a well-known technique for masking the data using random value. This approach tries to preserve data privacy by adding random value and also questions the privacy-preserving capability of the random-value permutation technique. Pascal Pailliar et al. [8] proposed Public key crypto system based on composite degree residuosity classes. In this paper [8] authors explained about the rules involved for key generation and stated the advantages of the rules in the security system.
Vaidya et al. [9] proposed privacy preserving association rule mining in vertically partitioned data. In this paper [9] authors described association rules for preserving data when data is partitioned vertically over different databases.
III. DESIGN
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, Volume 2, Issue 5, May 2012)186
After the initial assignment of clusters, the cluster means are recalculated and each entity is reassigned to the closest cluster. This process is repeated until there is no change in entities in the clusters for two consecutive iterations. This algorithm takes time complexity of O(nkt).
A. Privacy preserving k-means clustering Algorithm
The central idea of proposed algorithm is similar to the one proposed by [1, 2]. The algorithm is as follows:
Algorithm 1
Privacy Preserving K-means Clustering Algorithm Require: r parties, k clusters, n points.
1. for each party i= 1,...,r do 2. for each cluster c = 1,...,k do
3. initialize _ci randomly 4. end for
5. end for 6. repeat
7. for each entity j=1,...,n do
8. Cluster[j] = ComputeClosestCluster (j) 9. end for
10. for each party i= 1,...,r do 11. for each cluster c=1,...k do
12. calclaute_ci = mean of party's attributes in cluster c 13. end for
14. end for
15. until the convergence criteria is met.
B. Finding closest cluster
This algorithm is used as a function in k-means clustering algorithm to securely and out the nearest cluster for the given entity i.e. to which cluster should an entity to be assigned. This algorithm is invoked for every single entity in each iteration. Each party has its input data, the distance component corresponding to each of the k clusters i.e. which is equivalent of having a matrix of distances of dimensions r*k. Euclidean distance measure is used to compute the distance between the entity and the cluster centroid. Euclidean distance between two vectors x and y is obtained as:
d (x; y) = √ ∑m
i=1 (xi - yi)2 , where m = number of attributes.
Then compute closest cluster algorithm is described in Algorithm 2 below.
Algorithm 2 Compute closest cluster Require: r parties
1. {Between P1 and all other parties}
2. {P1 publishes initial starting point indexes (cluster Id's) to all other Parties}.
3. for each party Pi, i=1,2,...r do
4. for each entity j=1,2,...n do 5. Vij= random number
6. for each centroid Cl, l=1,2,...,k do
7. Compute the partial distances Xij to the k initial centroids.
8. end for
9. Perform randomized permutation on Xij [i.e. ∏(Vij + Xij)]
10. end for 11. end for 12. for i= 2,...,r do
13. sends computed distances vector to P1 14. end for
15. P1 computes the final local distances and compares the distances.
16. P1 assign the entities to the closest clusters. The main idea of the algorithm is as follows: P1 selects
randomly k number of entities from the dataset as initial starting points and publishes the starting points indexes to all other parties. Every party computes the local distances of their attributes for k clusters. Random permutation is applied on local distances for each of the k cluster. Since there are r parties and each of them sends the computed random permuted local distances to party P1. P1 combines all randomized masked local distances with respect to each entity and compares the masked local distances with k cluster and and assigns the entity to the closest cluster. The final output of privacy preserving k-means clustering algorithm is that all the parties will know to which cluster each entity is assigned.
IV. IMPLEMENTATION
To check the performance of the proposed algorithm, four different datasets are used to see how much communication overhead is caused by the proposed algorithm and algorithms by Mahir et al. [1] and Clifton et al. [2].
V. EXPERIMENTAL RESULTS
For testing the proposed algorithm four different datasets were used; Synthetic control chart time series, Echo cardiogram, Ecoli and Iris datasets taken from UCI Machine Learning Repository [11].
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, Volume 2, Issue 5, May 2012)187
The attributes of the entities are distributed among parties equally or unequally, which does not show any effect on the algorithms.
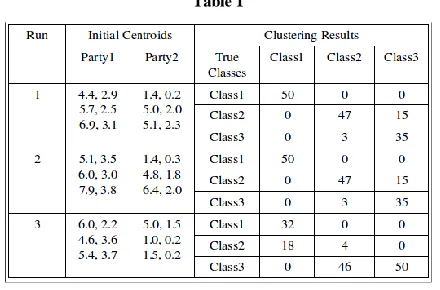
[image:5.612.59.279.229.374.2]The proposed algorithm is applied to Iris dataset consist of 150 entities, 3 classes and 4 attributes for each entity. The clustering results is shown in Table 1.1 with number of parties r = 2. The corresponding outputs are shown as Test Case 1, Test Case 2 and Test Case 3.
Table 1
The clustering results of the proposed algorithm for Iris dataset with number of parties r=2.
The Synthetic control chart time series dataset consist of 600 entities, 6 classes and each entity 60 attributes, so n = 600, k = 6 and r=60 . Parties can be upto 60 because the dataset has 60 attributes. The comparison of communication cost of Synthetic control chart time series dataset is shown in the Table 1.1, and Figure 1.1, the graph shows the comparison result of communication cost with time series dataset.
This section describes how the communication cost of Mahir et al. [1], Clifton et al. [2] and the proposed algorithms are computed with different datasets.
The computation procedure is as follows: Communication cost of Clifton et al. [2] is:
2048(r-1)kn bits Where r=10, n = 600, and k = 6 are applied on the equation above:
2048(r-1)kn we get 66355200 bits
Now convert the number of bits to bytes by dividing by 8: We obtain 66355200 _ 8 = 8294400 bytes.
Then take the answer and convert it to kilobytes by dividing by 1024:
We obtain 8294400 _ 1024 = 8100 KB.
Then take the answer and convert it to megabytes by dividing by 1024 once again:
We obtain 8100 _ 1024 = 7:910 MB.
The remaining computations follows the above procedure with respect to the datasets and algorithms.
Table 2
No of parties (r )
Clifton et al.[2]
Mahir et al.[1]
Proposed * 10
10 7.910 1.235 1.235
20 16.999 5.219 2.609
30 25.488 11.947 3.982
40 34.277 21-423 5.355
50 43.066 33.645 6.729
60 51.855 48.615 8.102
[image:5.612.336.546.425.607.2]Megabytes transmitted with Time series dataset
Figure 1 Megabytes transmitted with the Time series dataset.
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, Volume 2, Issue 5, May 2012)188
Table 3No of Parties Clifton et al.[2]
Mahir et al.[1] * 10
Proposed * 10
2 0.200 0.060 0.037
3 0.400 0.187 0.062
4 0.600 0.374 0.094
5 0.800 0.624 0.124
6 1.000 0.937 0.156
7 1.200 1.312 0.187
[image:6.612.43.294.148.565.2]Megabytes transmitted with Ecoli dataset
Figure 2 Megabytes transmitted with the Ecoli dataset.
The Echocardiogram dataset consist of 107 entities, 2 classes and 8 attributes for each entity, so n = 107, k = 2 and r=8 . Parties can be upto 8 because the dataset has 8 attributes.
The communication cost is compared and is shown in the Table 1.3 and Figure 1.3, the graph shows the comparison result of Echocardiogram dataset are shown below.
Table 4
No of Parties Clifton et al.[2]
Mahir et al.[1] * 10
Proposed * 10
2 0.052 0.016 0.008
3 0.104 0.049 0.016
4 0.157 0.098 0.024
5 0.209 0.163 0.033
6 0.261 0.244 0.041
7 0.313 0.342 0.049
8 0.366 0.457 0.057
Megabytes transmitted with Echocardiogram dataset
Figure 3 Megabytes transmitted with the Echocardiogram dataset.
[image:6.612.318.566.179.536.2]International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, Volume 2, Issue 5, May 2012) [image:7.612.46.286.146.465.2]189
Table 5No of Parties Clifton et al.[2]
Mahir et al.[1] * 10
Proposed * 10
2 0.110 0.034 0.017
3
0.220 0.103 0.034
4
0.330 0.206 0.052
Megabytes transmitted with Iris dataset
Figure4 Megabytes transmitted with the Iris dataset.
VI. COST ANALYSIS
Distributive privacy preserving algorithms are mostly used in real time applications; these algorithms should have less communication and computational overheads. In the proposed algorithm communication cost overhead lies in Compute closest cluster. The communication cost as well as computational cost mainly depends on the datasets and selection of initial cluster. In the proposed algorithm, only one iteration of k-means algorithm is considered with r parties, k clusters and n number of entities.
A. Communication cost analysis
In the proposed algorithm the party P1 publishes the initial starting indexes (cluster Ids) to all other parties. Every party computes the local distances of their own attributes for k clusters. Random permutation is applied on the computed local distances for each of the k cluster. Since there are r parties all the parties sends the computed random permuted local distances of 32 bits to party P1.The communication cost of this process takes 32(r-1 )kn.
The algorithm proposed by Mahir et al. [1] has high communication cost for the first phase of securely finding closest cluster algorithm takes 32r(r-1)kn. In phase one, for each entity, every party sends secret shares of its portion of distances to every other party for each of the k clusters by using additive secret sharing.
The algorithm proposed by Clifton et al. [2], has high communication cost i.e. 2(r-1)1024kn=2048(r-1)kn, every party sends its encrypted local distances to party 1. Party 1 adds the generated random value to the local distance value by using additive homomorphic property of the public key encryption. Considering Pailliar public encryption scheme with 1024 bits of key and block size is used.
The communication cost of Mahir et al. [1], Clifton et al. [2] and the proposed algorithms are shown below in Table 1.6.
Table 6
Algorithm Bits transmitted(Communication cost
Mahir et al.[1] 32r(r-1)kn
Clifton et al.[2] 2048(r-1)kn
Proposed 32(r-1)kn
Communication Cost of algorithms
B. Computation cost analysis
The proposed privacy preserving k-means clustering algorithm has less computational overhead because the algorithm uses random permutation rather than cryptographic operations. The proposed algorithm uses only primitive operations. The work of Clifton et al. [2] uses public key encryption and decryption operations. The algorithm needs modular exponentiation operations, which leads to high computational cost. The work of Mahir et al. [1] uses additive secret sharing mechanism, which also uses random permutation and has less computational cost. As the proposed algorithm uses simple primitive operations it gives less computational overhead.
VII. CONCLUSION
In this paper a new privacy preserving k-means clustering algorithm is proposed without compromising the security of individual. Work of Mahir et al. [1] and Clifton et al. [2] was considered as a basis, which uses homomorphic additive secret sharing and homomorphic public key encryption respectively. The proposed algorithm uses random permutation due to which the communication overhead gets reduced.
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, Volume 2, Issue 5, May 2012)190
REFERENCES
[1 ] M.C. Doganay, T.B. Pederson, Y. Saygin, E. Savas and A. Levi. “Distributed privacy preserving k-means clustering with additive
secret sharing,” Proceedings of the 2008 international workshop on Privacy and anonymity in information society. PAIS '08, pp. 6003-6011, Mar 2008.
[2 ] Jaideep Vaidya and Chris Clifton \Privacy-preserving k - means clustering over vertically partitioned data,"Proceedings of ninth ACM SIGKDD international Conference on Knowledge discovery and data mining. USA '03, pp. 206-215, Dec 2003.
[3 ] A. Rakesh and R. Srikant \Privacy- preserving data mining, "Proceedings Of the 2000 ACM SIGMOD International conference of Management of Data.USA, pp. 439-450, Mar 2000.
[4 ] Margaret H. Dunham, Data Mining - Introductory and Advanced Concepts, Person Education, 2006.
[5 ] H Kargupta, S Datta,Q wang and K Siva Kumar\Random-data perturbation techniques and privacy-preserving data mining "IEEE conference on Knowledge and Information system on data mining. London, pp. 387- 414, sep 2004.
[6 ] S.V. Kaya, T.B. Pedersen, E. Savas and Y Saygan \Efficient Privacy- preserving distributed clustering based on secret sharing, “In PAKDD 2007 International Workshops: Emerging Technologies in Knowledge Discovery and data mining. Springer, pp. 280-291, Mar 2007.
[7 ] Random-permutation: http://en.wikip-edia.org/wiki/Random Permutation.
[8 ] Pascal Pailliar. \Public key Cryptosystem based on composite degree residuosity class, "Advances in Cryptology EUROCRYPT 99 International Conference on Theory and Application of Cryptographic Techniques. pp. 223-238, May 1999.
[9 ] Jaideep Vaidya and Chris Clifton.\Privacy-preserving association rules in vertically partitioned data."In Proceedings of Eighth ACMSIGKD international Conference on Knowledge discovery and data mining. CANADA '02, pp. 639-644, july 2002.
[10 ]Secure-multiparty-computation:
http://en.wikipedia.org/wiki/Secure multiparty computation. [11 ]Merz C J, Murphy P M, "UCI Repository of Machine Learning
Database," Available http://www.ics.uci.edu/ mlearn/.
ACKNOWLEDGMENT

![Table 5 communication cost for the first phase of securely finding closest Mahir et al.[1] The algorithm proposed by Mahir et al](https://thumb-us.123doks.com/thumbv2/123dok_us/8736785.888825/7.612.46.286.146.465/table-communication-securely-finding-closest-mahir-algorithm-proposed.webp)
