International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459,ISO 9001:2008 Certified Journal, Volume 4, Issue 1, January 2014)
417
Study of Feature Selection Techniques using Microarray Data.
Sonawane Shraddha
1, Nawathe Anuradha
2, Sonawane Swapnil
3 1ME Student, A.V.C.O.E. Sangamner. INDIA.2Assistant Professor A.V.C.O.E. Sangamner, INDIA.
3
B.Tech Student, V.I.T. Pune, INDIA.
Abstract
—
Feature selection techniques became a noticeable need in several bioinformatics applications. In addition to the several techniques that have already been developed among the machine learning and processing fields, specific applications in bioinformatics have more importance to a wealth of freshly projected techniques.Using unique feature selection technique for achieving most accurate classifier, for all domains, is next to impossible. Suitable domain specific features can yield better performance for that particular domain. So, we are going to implement Occam’s Razor, Sample Compression, and PAC-Bayes learning algorithms using Decision Stump. We are going to apply these feature selection techniques on microarray data and on the basis of specific efficiency measures we can choose a best suitable technique particularly for microarray data.
This paper presents the comparison in between proposed techniques along with traditional feature selection techniques. We apply the projected approaches for gene identification from deoxyribonucleic acid microarray data and compare our results to those of the well-known triple-crown approaches projected for the task. We tend to show that our algorithmic rule not solely finds hypotheses with a far smaller variety of genes whereas giving competitive classification accuracy, in contrast to different approaches. The projected approaches are general and protrusile in terms of each coming up with novel algorithms and application to different domains.
Keywords—Feature selection, microarray data, decision stump, gene identification.
I. INTRODUCTION
Feature selection has been a lively analysis space in pattern recognition, statistics, and data processing communities. Feature selection is to select a subset input variables by eliminating options with very little or no prognostic data. Feature selection will considerably improve the understandability of the ensuing classifier models and sometimes build a model that generalizes higher to unseen points. Further, it is often the case that finding the right set of prognostic options is a crucial problem in its claim. For instance, doctor could build a choice supported the selected options whether or not a dangerous surgery is important for treatment or not.
Feature selection techniques became a clear want in many bioinformatics applications. In addition to the big pool of techniques that have already been developed within the machine learning and data processing fields, large number of applications in bioinformatics have been proposed to a wealth of fresh planned techniques.
During the last decade, the motivation for applying feature selection techniques in bioinformatics has shifted from being associate illustrative example to changing into a true necessity for model building. Above all, the high dimensional nature of many modelling tasks in bioinformatics, going from sequence analysis over microarray analysis to spectral analyses and literature mining has given rise to a wealth of feature selection techniques being conferred within the field.
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459,ISO 9001:2008 Certified Journal, Volume 4, Issue 1, January 2014)
418
II. RELATED WORK
The filter model depends on the ultimate characteristics of data and evaluates choices whereas not involving any learning algorithmic program. While, the wrapper model wants a predetermined learning algorithmic program and uses its performance as analysis criterion to pick out choices. This suggests that that each feature is thought-about severally, thereby ignoring feature dependencies, which might cause worse classification performance in comparison to alternative kinds of feature choice techniques. so as to beat the disadvantage of ignoring feature dependencies, kind of variable filter techniques were introduced, aiming at the incorporation of feature dependencies to some extent. However, because the area of feature subsets grows exponentially with the number of options, heuristic search strategies are used to guide the rummage around for associate optimum set.
Algorithms with embedded model, e.g., C4.5 [3] and LARS [15], incorporate variable choice as a district of the work technique, and have connectedness is obtained analytically from the target of the coaching model. Feature choice algorithms with filter and embedded models may return either a set of elect choices or the weights of all choices. In line with the sort of the output, they'll be divided into feature constant and set selection algorithms.
Table provides a details concerning the filters of feature choice strategies, Filter techniques assess the relevancy of options by trying solely at the intrinsic properties of the data. In most cases a feature relevancy score is calculated, and low-scoring choices are removed. Afterwards, this set of options is conferred as input to the classification algorithmic rule. blessings of filter techniques square measure that they merely scale to really high-dimensional datasets, they square measure computationally straightforward and fast, which they square measure freelance of the classification rule. As a result, feature choice must be performed just one occasion, then fully completely different classifiers are going to be evaluated. a standard disadvantage of filter ways that} is that they ignore the interaction with the classifier which most planned techniques are univariate. Recently, there are quite a few surveys unconcealed to serve this purpose. As AN example, a pair of comprehensive surveys for feature choice printed in machine learning or information domain could also be found in [16, 20]. In [27], the authors provided a decent review for applying feature selection techniques in bioinformatics. In [17], According to the sort of the output, they'll be divided into feature constant and set selection algorithms.
Algorithms with wrapper model usually return feature set. In keeping with our info, presently most feature choice algorithms are designed to handle learning tasks with single data provide, although the potential of practice auxiliary data sources in multi-source feature selection may greatly enhance the educational performance [22,30]. Below, we've got a bent to go to the key plan of connectedness & redundancy for feature choice, equally as a result of the required elements throughout a feature selection technique. The authors surveyed the filter and conjointly the wrapper model for feature selection. In [24], the authors explore the representative feature choice approaches supported distributed regularization, that might be a branch of embedded model. Representative feature choice algorithms are through empirical observation compared and evaluated in [18, 19, 21, 23, 25, 28, 29] with totally completely different disadvantage settings from different views.
So, we are working with unconventional approach of feature selection i.e. Occam Razor’s, Pac Bayes, Sample compression along with decision stump using microarray data.
III. PROGRAMMER’S DESIGN
In this paper we mainly concern with feature selection of microarray data. This system has generally four step process.
• Input
• Particular approach • output
• Comparison Result
A. Input
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459,ISO 9001:2008 Certified Journal, Volume 4, Issue 1, January 2014)
419
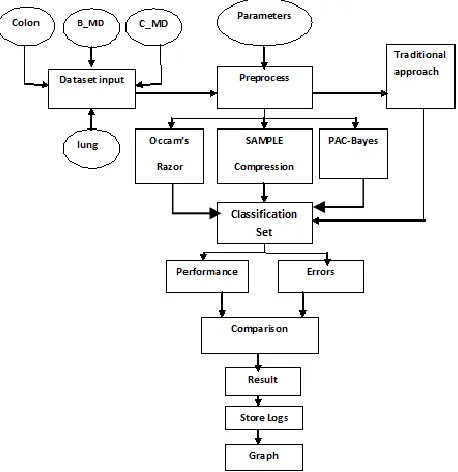
[image:3.612.53.282.215.451.2]This original version was primarily designed as a tool for analyzing knowledge from agricultural domains, however the newer totally Java-based version (Weka 3), that development started in 1997, is currently utilized in many alternative application areas, above all for academic functions and analysis.
Figure 1: System architecture
B. Occam’s Razor [1,2]:
It is a principle of parsimony, economy, or succinctness used in logic and problem-solving. It states that among competing hypotheses, the hypothesis with the fewest assumptions should be selected. The application of the principle often shifts the burden of proof in a discussion. The razor states that one should proceed to simpler theories until simplicity can be traded for greater explanatory power. The simplest available theory need not be most accurate. Philosophers also point out that the exact meaning of simplest may be nuanced. We are applying this phenomenon on feature selection techniques.
C. Pac Bayes [1,2]:
PAC-Bayes certains unit a generalization of the Occam’s razor sure for algorithms that output a distribution over classifiers rather than merely one classifier. This includes the probability of a distribution over one classifier, thus it is a generalization. Most classifiers do not output a distribution over base classifiers. Instead, they output either a classifier, or a median over base classifiers.
D. Sample Compression[1,2]:
The basic idea behind sample compression approach is to obtain classifiers which can be reconstructed again.
E.
Mathematical Model with help of Theory ofProject Our proposed system takes a ARFF dataset file as the input and after processing provides a classified dataset (without scratch) as output.Mathematical model for proposed system:- Terms used in this are as follows:-
w:Weka ARFF dataset files, s:Instances, cS:Correctly classified instances, iS:Incorrectly classified instances, R:Rule(Single level decision tree), C:Comparison on the basis of efficiency measures, O:Output, S:Function which holds i.e sample space.
Let, S: { w, s, R, cS, iS, C }
Let, w: { w1, w2, w3..,...,.wn } where w consists of number of ARFF dataset files.
Let, s: { s1, s2, s3, ..,...,.sn } where s is total number of instances.
Let, cS: { cS1, cS2 , cS3,..,...,.cSn } where cS is total number of correctly classified instances from the input dataset.
Functionality Functions:-
F1- Function F1 will preprocess the data from input dataset and returns the number of instances.
F2- Function F2 will execute decision stump and it will return description of classifier i.e. rule
F3- Function F3 will generate a classifier using HNB i.e. Hidden Navie Bayes Classifier.
F4- Function F4 will perform Sample Compression approach which returns unpruned decision tree.
F5-Function F5 will perform Pac Bayes feature selection and it will return classified dataset.
F6-Function F6 will perform Occam’s Razor approach which uses decision stump and returns classified dataset.. F7-Function F7 will do the comparison of all three algorithms on the basis of specified efficiency measures.
The system design includes seven main functions which are given below:
F1- Function F1 will preprocess the data from input dataset and returns the number of instances.
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459,ISO 9001:2008 Certified Journal, Volume 4, Issue 1, January 2014)
420
F2- Function F2 will execute decision stump and it will return description of classifier i.e. rule
F2(s) → R Description of classifier i.e. Rule ( of input dataset)
e.g. F2(s) → { R1,R2,...,Rn } R
F3- Function F3 will generate a classifier using HNB i.e. Hidden Navie Bayes Classifier.
F3(R) →{cS1, cS2,……., cSn } {iS1, iS2,……., iSn } s.
F4- Function F4 will perform Sample Compression approach which returns unpruned decision tree.
F4(R1) → {cS1, cS2,……., cSn } cSR1 {iS1, iS2,……., iSn } s1.
F5-Function F5 will will perform Pac Bayes feature selection and it will return classified dataset.
F5(R2) →{cS1, cS2,……., cSn } cSR2 {iS1, iS2,……., iSn } s2.
F6-Function F6 will perform Pac Bayes feature selection and it will return classified dataset.
F6(R3) →{cS1, cS2,……., cSn } cSR3 {iS1, iS2,……., iSn } s3.
F7-Function F7 will do the comparison of all three algorithms on the basis of specified efficiency measures. F7(C) →׀ cSR1׀== ׀ cSR2׀ ==׀ cSR3 ׀
e.g. F7(C) →cSR3 iff Pac Bayes gives best result than othetr feature selection techniques.
Functional Dependency matrix of the above functions is shown above:
F. Output:
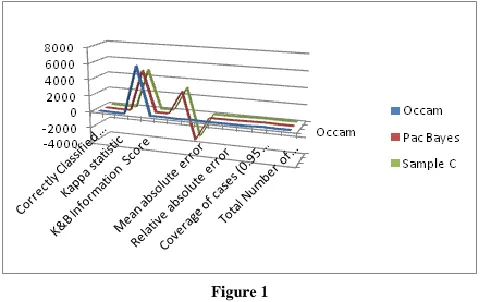
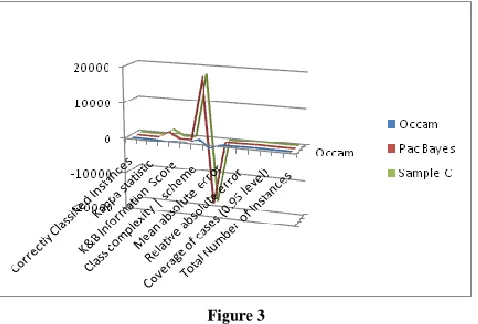
[image:4.612.324.564.310.461.2]The comparison in between proposed techniques along with traditional feature selection techniques is done on the basis of following comparative measures. Correctly classified instances, Incorrectly classified instances, Kappa statistic, K & B Relative Information score, Class complexity | order, Class complexity | scheme, Complexity improvement, Mean absolute error, Root mean squared error, Relative absolute, Root relative squared error, Coverage of cases, Mean rel. region size, Total Number of Instances.
G. Experimental setup
The proposed system is going to work with ARFF file format which is basically microarray data. This project takes a ARFF files as input. For developing this system we required Jdk 1.6 with Netbeans 7.0. This proposed system is going to give the result as in terms of different aspects. Figure 1. shows the block diagram of the proposed system.
IV. RESULTS AND DISCUSSION
The result clearly shows the comparison between proposed techniques of feature selection using microarray data. Figure 1 is the graph obtained for the comparison of proposed techniques for colon dataset. Pac Bayes technique yields competitive classifier.
Figure 1
Figure 2 is the graph obtained for the comparison of proposed techniques for lung cancer dataset. Pac Bayes technique yields competitive classifier.
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459,ISO 9001:2008 Certified Journal, Volume 4, Issue 1, January 2014)
421
[image:5.612.50.289.176.338.2]Figure 3 is the graph obtained for the comparison of proposed techniques for lymphoma dataset. Pac Bayes technique yields competitive classifier.
Figure 3
Finally, we can say that Pac Bayes approach is the best among all proposed techniques. Comparatively Occam Razor gives better results than Sample compression approach.
V. CONCLUSION
As we have discussed earlier, using unique feature selection technique for achieving most accurate classifier, for all domains, is next to impossible. Suitable domain specific features can yield better performance for that particular domain.
In this article, feature selection technique algorithm has been applied to microarray data. We have applied these techniques on different datasets. Comparison of three of them have been discussed in this article on the basis of different criteria mentioned in section E i.e. output. As mentioned previously, we can say that Pac Bayes approach is the best among all proposed techniques. Comparatively Occam Razor gives better results than Sample compression approach for microarray data.
Future study can include exploring the utility of the risk bound for feature selection techniques.
REFERENCES
[1] Mohak Shah, Member, IEEE, Mario Marchand, and Jacques Corbeil “Feature Selection with Conjunctions of Decision Stumps and Learning from Microarray Data,” IEEE transactions on pattern analysis and machine intelligence, vol. 34, no. 1, january 2012 [2] Sonawane Shraddha, Nawathe Anuradha, Sonawane Swapnil,
“Feature Selection Techniques and Microarray Data: A survey” IJETAE_0114_110, International Journal of Emerging Technology and Advanced Engineering (ISSN 2250–2459, ISO 9001:2008 Certified Journal, Volume 4, Issue 1, January 2014)
[3] Yvan Saeys, Inaki Inza and Pedro Larranaga. “A review of feature selection techniques in bioinformatics,” Vol. 23 no. 19, pp 2507– 2517, 2007
[4] Hall,M. (1999) “Correlation-based feature selection for machine learning”. PhD, Thesis., Department of Computer Science, Waikato University, New Zealand.
[5] Koller,D. and Sahami,M. (1996) “Toward optimal feature selection. In Proceedings of the Thirteenth International Conference on MachineLearning”, Bari, Italy, pp. 284–292.
[6] Yu,L. and Liu,H. (2004) “Efficient feature selection via analysis of relevance and redundancy.” J. Mach. Learn. Res., 5, 1205– 1224.Tavel, P. 2007
[7] M. Eisen and P. Brown, “DNA Arrays for Analysis of GeneExpression,” Methods in Enzymology, vol. 303, pp. 179-205, 1999.Sannella, M. J. 1994 Constraint Satisfaction and Debugging for Interactive User Interfaces. Doctoral Thesis. UMI Order Number: UMI Order No. GAX95-09398., University of Washington. [8] M. Marchand and M. Shah, “PAC-Bayes Learning of
Conjunctionsand Classification of Gene-Expression Data,” Proc. Advancesin Neural Information Processing Systems, pp. 881-888, 2005.Forman, G. 2003. An extensive empirical study of feature selection metrics for text classification. J. Mach. Learn. Res. 3 (Mar. 2003), 1289-1305.
[9] A. Blumer, A. Ehrenfeucht, D. Haussler, and M. Warmuth, “Occam’s Razor,” Information Processing Letters, vol. 24, pp. 377-380,1987.
[10] Brown, L. D., Hua, H., and Gao, C. 2003. A widget framework for augmented interaction in SCAPE. D. McAllester, “Some PAC-Bayesian Theorems,” Machine Learning,vol. 37, pp. 355-363, 1999. [11] D. Kuzmin and M.K. Warmuth, “Unlabeled Compression Schemes
for Maximum Classes,” J. Machine Learning Research,vol. 8, pp. 2047-2081, 2007.
[12] D. McAllester, “Some PAC-Bayesian Theorems,” Machine Learning,vol. 37, pp. 355-363, 1999.
[13] D. McAllester, “PAC-Bayesian Stochastic Model Selection,” Machine Learning, vol. 51, pp. 5-21, 2003.
[14] M. Seeger, “PAC-Bayesian Generalization Bounds for Gaussian Processes,” J. Machine Learning Research, vol. 3, pp. 233-269,2002. [15] B. Efron, T. Hastie, I. Johnstone, and R. Tibshirani. Least angle
regression. Annals of Statistics, 32:407{49}, 2004.
[16] I. Guyon and A. Elissee_. “An introduction to variable and feature selection”. Journal of Machine Learning Research, 3:1157{1182}, 2003.
[17] Inaki Inza, Pedro Larranaga, Rosa Blanco, and Antonio J.Cerrolaza. Filter versus wrapper gene selection approaches in dna microarray domains. Arti_cial Intelligence in Medicine, 31:91{103}, 2004. [18] Carmen Lai, Marcel J T Reinders, Laura J van't Veer, and Lodewyk
F A Wessels. A comparison of univariate and multivariate gene selection techniques for classi_cation of cancer datasets. BMC Bioinformatics, 7:235, 2006.
[19] Tao Li, Chengliang Zhang, and Mitsunori Ogihara. A comparative study of feature selection and multiclass classi_cation methods for tissue classi_cation based on gene expression. Bioinformatics, 20(15):2429{2437}, Oct 2004.
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459,ISO 9001:2008 Certified Journal, Volume 4, Issue 1, January 2014)
422
[21] Huiqing Liu, Jinyan Li, and Limsoon Wong. A comparative study on feature selection and classification methods using gene expression profiles and proteomic patterns. Genome Inform, 13:51{60},2002. [22] J. Lu, G. Getz, E. A. Miska, E. Alvarez-Saavedra, J. Lamb, D. Peck,
A. Sweet-Cordero, B. L. Ebert, R. H. Mak, A. Ferrando, J. R. Downing, T. Jacks, H. R. Horvitz, and T. R. Golub. Microrna expression profiles classify human cancers. Nature, 435:834{838}, 2005.
[23] Shuangge Ma. Empirical study of supervised gene screening. BMC Bioinformatics, 7:537, 2006.
[24] Shuangge Ma and Jian Huang. Penalized feature selection and classification in bioinformatics. Brief Bioinformatics, 9(5):392{403, Sep 2008.
[25] Carl Murie, Owen Woody, Anna Lee, and Robert Nadon. Comparison of small n statistical tests of differential expression applied to microarrays. BMC Bioinformatics, 10(1):45, Feb 2009. [26] J. R. Quinlan. C4.5: Programs for Machine Learning. Morgan
Kaufmann, 1993.
[27] Yvan Saeys, Iaki Inza, and Pedro Larraaga. A review of feature selection techniques in bioinformatics. Bioinformatics, 23(19):2507{2517}, Oct 2007.
[28] Y. Sun, C. F. Babbs, and E. J. Delp. “A comparison of feature selection methods for the detection of breast cancers in mammograms: adaptive sequential oating search vs. genetic algorithm”. Conf Proc IEEE Eng Med Biol Soc, 6:6532{6535}, 2005.
[29] Michael D Swartz, Robert K Yu, and Sanjay Shete. “Finding factors influencing risk: Comparing bayesian stochastic search and standard variable selection methods applied to logistic regression models of cases and controls”. Stat Med, 27(29):6158{6174, Dec 2008. [30] Z. Zhao, J. Wang, H. Liu, J. Ye, and Y. Chang. “Identifying
biologically relevant genes via multiple heterogeneous data sources”. In The Fourteenth ACM SIGKDD International Conference On Knowledge Discovery and Data Mining (SIGKDD 2008), 2008. [31] Zheng Zhao, Fred Morstatter, Shashvata Sharma, Salem Alelyani,
Aneeth Anand, Huan Liu, Advancing Feature Selection Research, ASU Feature Selection Repository.Langley, P., 1994.