CastFlow
: Clean-Slate Multicast Approach using
In-Advance Path Processing in Programmable
Networks
Cesar A. C. Marcondes, Tiago P. C. Santos, Arthur P. Godoy, Caio C. Viel and Cesar A. C. Teixeira
Computer Science Dept., Federal University of S˜ao Carlos, (UFSCar)S˜ao Carlos - SP, Brazil 13565-905
Email:{marcondes, tiagopomponet, arthur.godoy, caio viel, cesar}@dc.ufscar.br
Abstract—Multipoint communication is an important require-ment for many types of applications such as videoconferencing, IPTV and online radio. However, the division of Internet in au-tonomous systems hinders the widespread adoption of traditional multicast protocols, which, for using distributed algorithms, delay the group control events processing. This paper proposes a multicast clean-slate approach logically centralized based on programmable networks and anticipated processing for all routes from each possible source, aiming to reduce event delays. A prototype was implemented based on OpenFlow technology. In addition, extensive evaluation was performed and results show promising delays comparable to the requirements of multipoint applications.
Keywords : Multicast, Software-Defined Networks, OpenFlow, Network OS, Network Services.
I. INTRODUCTION
Some types of applications, as chat or video conferencing, require communication between multiple host. While others, like Internet Protocol TV (IPTV), take the services of a content provider, which sends identical data for many subscribers. These last applications could use IP Multicast to perform multipoint communication, avoiding the waste of bandwidth by sending redundant data across multiple unicast connections. Due to the distributed feature of the current Internet, with each router performing part of the routing algorithm, multicast routing protocols, such as Distance Vector Multicast Routing Protocol (DVMRP) or Multicast Open Shortest Path First (MOSPF), are not efficient to make changes in the multicast tree. This is because it is necessary to wait routers exchange information among themselves and update their routing tables, which can be a slow process. In addition, the Internet Group Management Protocol (IGMP), responsible for controlling the host join and leave from the group, may need to send messages to multiple routers to notify the occurrence of group events [1]. Using a logically centralized approach to perform multicast routing may offer several advantages over the distributed approach. For instance the possibility of creating an optimal distribution tree for each occasion, because a centralized algorithm has a complete view of the topology. It would also be possible to process control group events quickly without creating flood of messages, as happens in the distributed approach.
Many applications require changes on-the-fly in the mul-ticast group. For example, each channel on an IPTV service could have a related group. A user when zapping would be entering and leaving multicast groups. Using the distributed approach of the IP Multicast would not be an efficient solution for zapping., as IGMP introduces significant delays in join and leave from groups [2]. In the logically centralized approach, the element responsible for routing knows which branches should be added or removed from the multicast tree to respond to joining and leaving hosts. Considering that the process of reconfiguration of the routers is fast, the changes in the multicast group would have a low-latency.
With a unified view of all multicast groups, it would also be possible to aggregate in a forest all multicast trees. The forest would use the same multicast trunk for data dissemination. As a consequence, the number of entries in the routing tables could be reduced, promoting greater scalability and even better routing performance.
In this paper it is proposed a multicast clean-slate approach on which the calculation of all possible routes from sources to group members is done in advance, in order to speed up the processing of events in multicast groups (join, leave and the source change). A prototype using OpenFlow [3] was implemented to help understanding the initial cost with routes calculation and characterizing the time spent processing the events. Experiments were performed in the emulated topologies generated in a single laptop using Mininet [4]. The topologies analyzed were generated by the tool BRITE [5]. The results obtained with our experiments, as well as with the complexity analysis of the algorithms, indicate that the amount of time to calculate routes and group events processing may be smaller, when compared with values obtained using logically distributed techniques. This way the logical centralized ap-proach is interesting by improving the response time of group events processing, allowing smooth changes in the multicast group and better group management.
In section II it is detailed the approach used in distributed multicast in the IP multicast. Section III discusses how to use the OpenFlow technology to implement the clean-slate multicast. Section IV details the developed prototype. In section V it is presented the experiments and results. Section
VI discusses the impact of the results in one application. The related works are analyzed in Section VII. Section VIII presents the conclusions and future work.
II. IP MULTICAST
Multicast is the technique of sending packets to a specific group of hosts on the network, allowing communication in model 1-N or N-N. The main benefit of using multicast is the reduction of the traffic, due to the replication of messages supported by the routres. This is the most appropriate method to disseminate information for many categories of applications from multipoint, streaming, distributed systems and fault-tolerant systems.
The IETF RFC 1301 specifies two types of protocols that manage the multicast on Internet: the multicast routing proto-cols and the group control protoproto-cols. The multicast routing protocols are responsible for determining how packets are distributed (e.g., using a tree), having the goal of avoiding redundancy of information and preventing loops. Examples of these are DVMRP, MOSPF and Protocol Independent Multicasting (PIM). Complementing the functionality of rout-ing, the protocols for group management are responsible for controlling of join and leave events in the groups. IGMP and the Multicast Listener Discovery (MLD) are the protocols adopted by IPv4 and Ipv6 respectivelly.
The DVMRP protocol is a modification of the Routing Information Protocol (RIP). It uses unicast routing tables to keep information of the distance from each router to the destination (IETF RFC 1705). It is the protocol widely used in the network MBone [6]. . Nevertheless, scalability problems are faced as it is necessary to update the information in the routing tables every time a host joins or leaves a group [7], which can take several seconds. As MOSPF protocol is based on the Open Shortest Path First (OSPF), which uses link states to build the shortest path trees to the destinations, routers changes require costly operation for the dissemination of link states. Unlike others, the PIM (IETF RFC 2362) is not based on an adaptation of unicast protocols. Instead, it has different operating modes to suit both dense and sparse topologies. This adds complexity, making difficult its setup.
The group control protocols, such as IGMP or MLD, function similarly. A router IGMP querier is elected and becomes responsible for managing the events of the groups. The querier sends out periodics ”IGMP Query” to identify which hosts participate in a particular group. Hosts already on the group and entrants to enter the querier must respond with the message ”IGMP Report.” From the IGMPv2, each host leaving a group must notify the querier messages with ”IGMP Leave Group”. When the router detects that a host is out of a group, it checks if there are still entries in the table for active hosts. If there is no other active host left, the querier removes the table entry IGMP groups and promotes the pruning of the multicast tree branch. Note that the IGMP management messages are sent together with the user data generating network overload.
III. RESTRUCTURING THEMULTICAST WITHOPENFLOW
The OpenFlow protocol is based on programmable switches that combines flexibility in developing new software defined network applications while easing the burden for manufac-turers to adapt legacy switches. OpenFlow switches (OF) are capable of forwarding packets using rules defined in the so-called flow tables. In addition, there is a controller element connected to the switches OF. On the controller, network applications process network events, such as flow arrivals and using the OF protocol, it remotely control the OF switches, managing network flows at any granularity [3].
With the programming flexibility promoted by the controller on OF networks, it is possible to completely rethink multicast routing protocols without the use of complex and error-prone distributed algorithms. This is the novel approach used in this work.
In this new multicast approach, it was taken into account the following design decisions: (1) separate data plane from con-trol plane, (2) centralize the calculations about the multicast tree, (3) manage events related to multicast groups, (4) allow rapid changes in the multicast tree; and (5) prevent bottlenecks and increase reliability/availability. These decisions enable an optimized multicast from the network point of view, with a high processing rate of joining and leaving participant hosts consistent with stringent requirements of applications, such as IPTV and others. The following describes how these design decisions were incorporated in the solution.
A. Separate data plane from control plane
In the distributed multicast, the multicast-enabled routers are responsible for both, the forwarding of packets and the exchange of multicast routing messages. This creates an ex-tra overhead, in terms of bandwidth consumption, whenever control messages (such as joins, tree updates, etc) along with traffic data are sent through the same links. This issue was identified early as a limitation in [8]. In that work, there was a proposal for the use of one or more central elements responsible only for the routing algorithm, using a control network separated from the data path. However, it was never deployed due to the ossified nature of the Internet.
With the increasing deployment rate and popularity of Openflow, and since, the separation of control and data planes is already in place in OpenFlow. Our multicast solution can rely on a separation of the data and control planes.
B. Centralize the calculation about the multicast tree It can be observed that the behavior of multicast trees is unpredictable due to the large number of joins and leaves events from participating hosts over time [8]. Therefore, it is useful to adopt a mechanism that has full knowledge of the network topology and pre-compute optimal multicast trees, opportunistically depending on every occasion. This method would be better than the distributed multicast routing. In the latter, a high rate of hosts joins and leaves can destabilize the optimal tree turning the stabilization process really slow or even impossible.
The application running on OpenFlow controller would be responsible for calculating opportunistically the multicast tree. Thus, using the information about the topology, the active multicast group, joins and leaves, this application, in every event, step-in and re-calculates the minimum multicast flow tree.
C. Management of Multicast Groups
The hosts that participate in a particular multicast group need to be managed, as in the IGMP protocol. Thus, a management mechanism that allows hosts to enter and leave a multicast group is needed. In addition, the admission of the host, and further validation through a list of allowed hosts (for example, subscribers of a specific IPTV service) are basic features required. Furthermore, the application must be also responsible for handling multicast source request changes.
As in the previous design decision, the group management should be running on the controller, but, it could be using a separate and specialized service of multicast group manage-ment. Therefore, it decouples the multicast routing algorithm from the group admission algorithm itself. This removes con-straints by allowing multiple co-existing policies for admission without the need to modify the routing algorithm. Another beneficial side effect is that, since the controller is directly connected to OpenFlow switches by out-of-band network and protocol (control plane), there is a desirable higher level of security between the host and controller in terms of multicast group management.
D. Rapid Changes in the Multicast Tree
For certain types of applications, such as IPTV zapping, there may be intense changes in the multicast group size and dynamics. In such cases, hosts could be joining and leaving the group all the time, as well as changes in the source of the group (as pointed out). Thus, in order to be efficient, it is necessary to have a mechanism capable to modify the multicast tree on-the-fly quickly.
The decision made was that the application should calculate in advance all the possible path routes for a given multicast group and kept a fast and efficient list of installed and active links/routes in the controller application. Whenever an event happens, the group controller would notify the OpenFlow controller, which would then remove or add entries in the specific flow tables of the OF switches.
E. Bottlenecks, Reliability and Availability
A central element can eventually limit the scalability of the system, because it may be unable to meet the demand of the system as it grows, creating a bottleneck. In addition, the reliability and availability may be low, since the central element is a critical point of failure. Although we acknowledge this as a problem, this has been also a criticism point of OpenFlow itself.However, several studies have been proposed to circumvent or reduce these problems. For example, [9] implemented a distributed OF controller that reduces the problem of scalability and is also suitable for fault tolerance.
This way, the proposed multicast solution can also leverage from these general OF scalability solutions.
IV. CASTFLOW
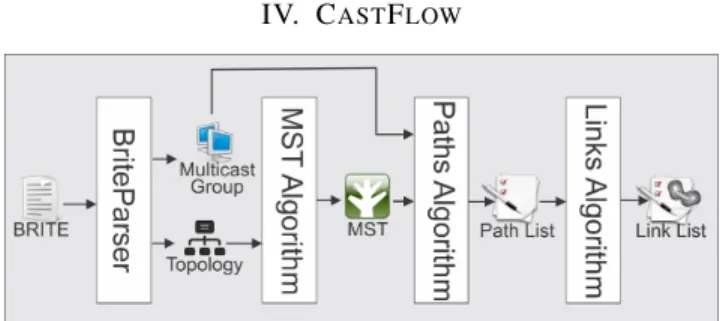
Fig. 1: Multicast Tree Creation Workflow
CastFlow is a public and open source proposal for a multi-cast clean-slate approach in programmable networks .The idea is to handle large amounts of hosts that can dynamically enter and leave the multicast group. Hence, the event processing efficiency of the control group becomes critical. In order to enhance the processing of such events, we make calculations in advance of all possible routes during the setup of the multicast group, avoiding the need for route calculation afterwards, when the events are been processed. In addition, there is a careful scheme based on path differences that performs the fewest possible changes in the flow tables)of the OF switches, in response to group events. The following describes the architecture and workflow of CastFlow, and the main mechanisms for route calculation and the processing of group events.
A. Route Calculation
We will first introduce the process of route calculation used by CastFlow to create multicast trees (Fig. 1). In order to achieve realism and to ease topologies generation for tests, we use in our prototype the BRITE tool. Using it, it was possible to generate software artifacts that represent a network topology. Afterwards, we parameterize the topology creation process by using an uniform distribution to select a host’s subset, from all nodes of the generated topology, to act as active members of the multicast group. Finally, one of the hosts is chosen to be the multicast source.
From the graph that represents the topology, a minimum spanning tree (MST) centralized on the multicast source is calculated using the PRIM algorithm. The PRIM algorithm generates the minimum spanning tree as a function of the weights associated to the edges of the graph and has com-plexity O(E log V) [10].
For the purposes of this study, the weight of each edge was defined as the path cost distance between the edge and the source of the multicast, and this yields optimal MSTs. Proving by contradiction, suppose there is a shorter path (PL) for a given node (Ni) than that found by PRIM (PP). From one point of the graph, the edges of PL have lower weights than those of PP. However, the PRIM is a greedy algorithm
(a) Shortest Path List (b) Links List (c) Sources Path List
Fig. 2: CastFlow Main Data Structures
and always uses the smallest edge weight, finding the path PL instead of PP (QED).
With the MST and the information for which hosts are part of the multicast group, the paths are calculated between the source and the hosts of the group, generating a list of shortest paths (Fig. 2a). This list of paths is further processed to remove redundancies, generating a list of links inside the MST (Fig. 2b). Through the list of links, the controller can easily add entries in the flow tables of OF switches to create the routes of the multicast tree.
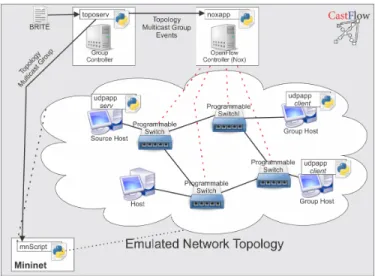
B. Prototype Architecture
The prototype was developed as a proof of concept for this proposal can be illustrated in Fig. 3. It consists of 4 main components: (1) toposerv, (2) udpapp, (2) mnScript and (3) noxapp.
1) toposerv - Topology Server: This component is respon-sible for providing information to other components about the network topology and the multicast group configuration. He also receives and validates control group events (such as joins and leaves) and performs analysis from BRITE files in order to define the underlying topologies. In a real situation, the last functionality would not exist, because the topology would be real, instead of an emulated one, as it was performed in our evaluation. Despite, in any case, the information about the topology and events would still be sent from this component. In some aspects, toposerv can be considered as similar to the IGMP protocol, because it is mainly responsible for the multicast group management and control.
2) udpapp - UDP Multicast Application: The udpapp is an application developed specifically for the testing phase of the prototype. It assumes the role of a real multicast application, as for example, a video conferencing application. It has two operational’s mode: client and server. In client mode, it only receives packets sent by another instance in server mode and display confirmation messages in the standard output. In server mode it keeps sending continuously data packets at intervals of 33 milliseconds, in order to emulate data traffic from an application performing video streaming at a rate of 30 frames per second. The server is bound to the allocated multicast IP address. The communication performed by udpapp is datagram oriented.
In order to proceed with the prototype multicast tests, it was initialized an application in server mode at a random
participating host as the multicast source. Then, this instance sends packets to the multicast group IP address, specifically allocated for this group. In the tests, the other hosts of the multicast group run instances in client mode, receiving the packets sent by the multicast source.
3) mnScript - Mininet Script Manager: The tests were instantiated from a network emulation using the component mnScript that uses the Mininet API to build the network topology directly, with nodes and switches, from a BRITE file. It also adds an entry in the ARP table for the multicast group address and initializes instances of udpapp in client mode on each host of the multicast group. Based on requests from the toposerv, it gets the information about the topology that must be created and the description from the multicast group. In a real situation, the mnScript would not exist, because there would be a real network topology and the client applications would be initiated on demand by users.
4) noxapp component: The noxapp is the application that runs in the openflow controller. We decided to use the NOX controller [Gude et al. 2008] in our prototype. During the setup of each experiment, noxapp obtains topologies informations and multicast group by toposerv and perform the calculation in advance of all possible routes, considering a different multicast tree for each possible source of the multicast group. Then it creates entries in the switches flows tables to map the initial multicast tree. Noxapp also register itself in toposerv for receive all multicast group events. When a events occur, toposerv notifies noxapp that will remove or add the entries in switches flows tables to perform the event.
C. Multicast Group Processing Events
One of the main features of the proposed multicast approach is the fast processing of the multicast group events (joining and leaving participant hosts or changing the main multicast source). For this, it is calculated in advance, during the setup of a multicast group, all possible routes between all possible multicast sources and each hosts of the multicast group. Those routes are stored at noxapp in a data structure called route map. The route map is composed of two linked hash tables (in python), the first table maps the possible multicast sources with a second hash table. Each second hash table maps the hosts of the multicast group with the path between it and the multicast source. Figure 2c contains a graphical representation of the route map.
Fig. 3: CastFlow Prototype Architecture
In addition to the route map, we also maintained a list of installed links at noxapp. This was, whenever an input event is received, the paths between the current source and joining nodes are obtained in constant time through the route map. Afterwards, the list of installed links is traversed in order to verify if any of the link (from the source to the joining node) must be installed or overwritten to add the new paths to the multicast tree. The result of this process is a difference list of links that must be installed in other words, the new branch to be inserted onto the tree.
For leaving events the process is similar. We get the paths to the nodes that are leaving from route map and traverse up the list of installed links, to check what links need to be removed or overwritten. The result is the branch of the tree should be pruned. Finally, events of changing a multicast source are the most complex to handle. First, we get the new paths between the source and all active nodes in the multicast group directly, in constant time, from the route map and traverse up the list of installed links to see which links were due to be removed, added or overwritten.
V. PROTOTYPEEVALUATION
A. Test Environment
The experiments were performed in virtual network gies emulated by Mininet. We generated five different topolo-gies using BRITE tool with a number of routers ranging from 10 up to 50. In each of the routers we connected a host. The toposerv performed the analysis of the files generated by Brite, mnScript and sent to the topology that should be emulated for a given experiment. Also we used a simplification of the MBone topology in the experiments. A simplification of the real topology, considering each site as an MBone router, totaling 84 routers.
The multicast group, multicast source and the initial active hosts were chosen at random, following a uniform distribution. The mnScript start instances of udpapp applications in client mode in each client hosts, this way the udpapps can collect data during the experiments.
The toposerv was programed to generate input events, output events or source changing events in a given time interval. These events were randomly generated also following a uniform distribution, and sent to noxapp, which installed or removed routes as needed to process the event group.
Udpapp instances (running on each host) and noxapp (run-ning on the controller) stored text files contai(run-ning the collected data. The experiments were repeatedly performed to assure that the data obtained were statistically consistent.
B. Experiment 1: Setup Time of a Multicast Group
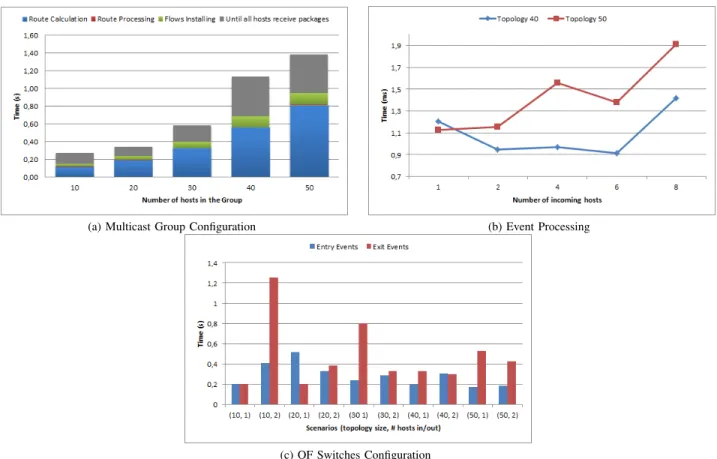
The objective of this experiment is to characterize a setup time of the multicast group. For this was used the simplified topology representation from Mbone and varied the size of the multicast group (number of hosts) of 10 up to 50 hosts. Figure 4a presents the results obtained in experiment 1.
We observed that the calculation in advance of the routes was the slowest process during the setup. This was expected, since this is precisely the proposed tradeoff: to make calcu-lation of all possible routes during the setup of the multicast group to minimize the delay in the processing of group events. The time used for the calculation in-advance presents nearly a linear growth, due the time spent processing a MST depends on graph edge number. As the topology was fixed the time is constant. A different tree is computed for each possible source (in this experiment, all the hosts of multicast group are potential sources), the spent time by calculation in-advance is directly proportional to the group size.
The processing time of routes, which is small compared to others setup steps, corresponds to the time it takes to noxapp to define which routes will be added to the switches. The flows installation time grows in proportion to the number of installed entries in the flow tables of the routers.
C. Experiment 2: Joining and leaving hosts
The objective of experiment 2 is to characterize the effect of join and leave events of hosts in the multicast group. For this we used five different BRITE topologies with increasing size. In each topology we fixed multicast group size and the
(a) Multicast Group Configuration (b) Event Processing
(c) OF Switches Configuration
Fig. 4: Setup Times
number of active hosts and varied the amount of hosts that joined and leaved.
Figure 4b shows the average time required to process the events in the topologies of 40 and 50 switches. Figure 4c shows the reconfiguration time of the switches for some of the scenarios analyzed. Figure 5a presents data relating the number of switches affected by the join events.
The processing time of the events is rather small, in the order of milliseconds, and it grows as the size of the topology and the number of hosts involved in the event increases. This shows that the calculation in advance of routes reduces the pro-cessing time of the events. The measured time configuration of the switches seems to be proportional to the number of hosts participating in the event that directly influence the number of affected switches. We also can notice that the configuration time of the join events is generally greater than leave events. The time spent to configure the switches, in addition to being large, presents a great variability. For the same scenario, settling an equal number of routes, there were a few times smaller than 0.01 s and others close to 1s. Such variability may be partly explained by the network emulation environment of Mininet. The same machine is running the controller, hosts udpapp applications, besides all the network infrastructure emulated by mininet. All the various processes are competing for machine resources such as CPU, causing interference.
These interferences were not detected significantly in exper-iment 1 because the routes had not yet been installed. Thus the
client applications udpapp were blocked waiting for packets sent by the source, the switches were not performing packet forwarding. In a related work, [12] proposes a framework for assessing the performance of OpenFlow switches. In that work the authors evaluate different OpenFlow switches, achieving less than 1 ms for the installation or modification of entries in the flows table. In work [13] built a OpenFlow switch in hardware using the technology NetFPGA that was able to add new entries in its flows table in 11 ms.
Despite the high times observed in experiment 2, which suf-fered greatly influenced by the test environment, we believed that in real scenarios, such as those used in the work of [12] and [13], the total time spent on configuration of the switches is much smaller and grow linearly with the number of switches affected by the event. For example, considering switch setup time of 1 ms, for the scenario of the topology of 50 nodes, with 8 hosts joining in an event we would be spending around 13 ms for the configuration, totaling just over 15 ms between the time that the controller is informed of the event and the route reconfiguration was completed.
The time for the switches configuration could be further reduced if a parallel programming adopted. The configuration messages would be sent simultaneously to all or groups of switches, rather than serially, as is the standard controller Nox. Other implementations of controllers can significantly increase the flow of creation or modification of entries in the flows table using multi-threaded approach [14].
(a) Join Events (b) Leave Events
Fig. 5: Number of Switches/Nodes affected by input/leave events
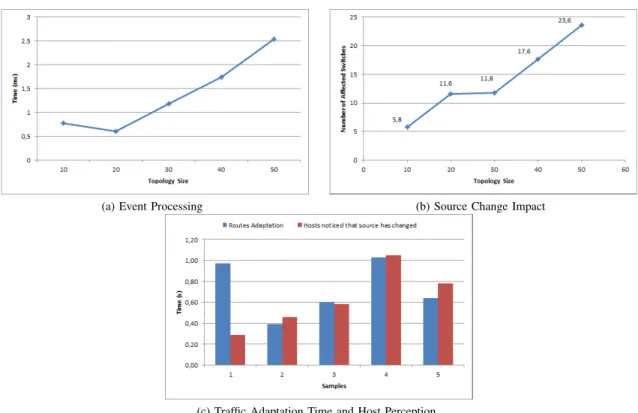
D. Experiment 3: Multicast Source Change
The objective of experiment 3 is to characterize the effect of source changing events. For this, we used five different BRITE topologies with increasing complexity. In each topology was fixed the multicast group size and the number of active hosts. Figure 6a shows the average time to process the events. The graph in Figure 6b shows the average number of switches affected by the events. Both the processing time of the events and the number of routers affected by the event presents an upward trend as the number of nodes in the topology increases. The processing time of events is small, similar to that seen in the join and leave of the experiment 2. Note also that, on average, half switches of the topology are affected by the source change.
Figure 6c compares the time until complete and proper adequacy of flows in various testing samples, with the average time for the hosts from request join the group until begin receiving data from the new source. It is noticed that in some situations hosts starting to receive data even before the adjustment is completed. Although the complete adequacy of flows likely to be a slow process, many hosts can start receiving the new data source before the process is fully completed.
VI. CASE OFSTUDY: IP TV
To justify the use of CastFlow we considered the case study of IPTV. A typical IPTV service can have a large subscriber base and provide a lot of channels. Each channel can be associated with a different multicast group, in which the multicast source would be the very TV station content servers, and the rest of the multicast group would be composed of subscribers who are watching the channel. In the imagined scenario, the initial multicast group setup would be calculated whenever there was change in the subscriber base. According to the results of experiment 1, the time of this calculation is not prohibitive and grows almost linearly. Furthermore the sources are restricted to the TV stations content servers which makes the calculation of multiple trees, based on multicast source, treatable by CastFlow.
In a TV scenario, with a great variety of channels, it is natural for users to zap through channels constantly. Because each channel is represented by a different multicast group, the joining and leaving of hosts in a group tend to be intense. The work of [2] studies the factors that contribute to the increase in latency of channel change in IPTV scenarios using IP multicast. It reaches the conclusion that the IGMP protocol
contributes significantly to delays in the order of seconds. In CastFlow approach, as discussed in experiment 2, the join and leave events would be processed in milliseconds and would require minimal changes in switches flow tables, generating optimal multicast trees.
VII. RELATEDWORK
Some works in the literature may be classified as increments of the Internet. Among them [8] presents a centralized multi-cast proposal that is similar to the logic used in this study, how-ever, does not have the flexibility of programmable networks. In the same context [15] proposed the use of unicast paths to distribute multicast packets forming an overlay network, how-ever this solution does not receive network support acting only at the application level. Considering proposals that require significant change in the network, as well as the proposal of this work, [16] use the Multiprotocol Label Switching (MPLS) Virtual Private Network on to manage multicast traffic, which suffers from scalability problems and also lacks the flexibility of programmable networks. On the other hand, [17] proposes high-level primitives based on OpenFlow to provide a more user friendly network. One of its primitives is a simplified implementation of multicast communication on OpenFlow, but that does not consider changes in the group, tree management and others imports issues. The CastFlow differs from these proposals promoting a more complete approach to multicast, including support for scalable network, calculating in advance multicast tree, and a focus on reducing the processing time of group events in the regular group management.
VIII. CONCLUSIONS ANDFUTUREWORK
This paper proposes a multicast clean-slate approach logi-cally centralized based on programmable networks with Open-Flow. During the setup of the multicast group, the calculation is carried out in advance of all possible routes in order to reduce the delay in processing multicast group events such as joining and leaving hosts or multicast source change.
We have implemented a proof of concept of this approach called CastFlow. Experiments were performed to characterize setup time and events processing. The results showed overall satisfactory performance in the order of milliseconds, faster than results published in the literature for IP multicast. The in-advance tree calculation time growth was linear, due to the complexity of the algorithms used in the implementa-tion. Considering real situations (installing flows on real OF switches), the time to process group events proved to be greatly
(a) Event Processing (b) Source Change Impact
(c) Traffic Adaptation Time and Host Perception
Fig. 6: Total Processing Time between source changes or affected switches
reduced. It is concluded that the proposal could be beneficial for applications that require multipoint communication and which hosts entry, hosts exit or source change in multcast group are intense, as may occur in IPTV.
In future work we intend to exploit mechanisms that allow aggregation OpenFlow flows from several different multicast trees, using wildcards similar to that proposed in [18].
REFERENCES
[1] P. Paul and S. V. Raghavan, “Survey of multicast routing algorithms and protocols,” inProceedings of the 15th international conference on Computer communication, ser. ICCC ’02. Washington, DC, USA: International Council for Computer Communication, 2002, pp. 902–926. [2] E. Kim, J. Liu, B. Rhee, S. Cho, H. Kim, and S. Han, “Design and implementation for reducing zapping time of iptv over overlay network,” inProceedings of the 6th International Conference on Mobile Technology, Application & Systems, ser. Mobility ’09. New York, NY, USA: ACM, 2009, pp. 41:1–41:7.
[3] N. McKeown, T. Anderson, H. Balakrishnan, G. Parulkar, L. Peterson, J. Rexford, S. Shenker, and J. Turner, “Openflow: enabling innovation in campus networks,”SIGCOMM Comput. Commun. Rev., vol. 38, pp. 69–74, March 2008.
[4] B. Lantz, B. Heller, and N. McKeown, “A network in a laptop: rapid prototyping for software-defined networks,” inProceedings of the Ninth ACM SIGCOMM Workshop on Hot Topics in Networks, ser. Hotnets ’10. New York, NY, USA: ACM, 2010, pp. 19:1–19:6.
[5] A. Medina, A. Lakhina, I. Matta, and J. Byers, “Brite: An approach to universal topology generation,” inProceedings of the Ninth International Symposium in Modeling, Analysis and Simulation of Computer and Telecommunication Systems, ser. MASCOTS ’01. Washington, DC, USA: IEEE Computer Society, 2001, pp. 346–.
[6] K. Savetz, N. Randall, and Y. Lepage, MBONE: Multicasting Tomor-row’s Internet, 1st ed. Foster City, CA, USA: IDG Books Worldwide, Inc., 1995.
[7] A. S. Thyagarajan and S. E. Deering, “Hierarchical distance-vector multicast routing for the mbone,”SIGCOMM Comput. Commun. Rev., vol. 25, pp. 60–66, October 1995.
[8] S. Keshav and S. Paul, “Centralized multicast,” inProceedings of the Seventh Annual International Conference on Network Protocols, ser. ICNP ’99. Washington, DC, USA: IEEE Computer Society, 1999, pp. 59–.
[9] A. Tootoonchian and Y. Ganjali, “Hyperflow: a distributed control plane for openflow,” inProceedings of the 2010 internet network management conference on Research on enterprise networking, ser. INM/WREN’10. Berkeley, CA, USA: USENIX Association, 2010, pp. 3–3.
[10] T. H. Cormen, C. Stein, R. L. Rivest, and C. E. Leiserson,Introduction to Algorithms, 2nd ed. McGraw-Hill Higher Education, 2001. [11] N. Gude, T. Koponen, J. Pettit, B. Pfaff, M. Casado, N. McKeown,
and S. Shenker, “Nox: towards an operating system for networks,”
SIGCOMM Comput. Commun. Rev., vol. 38, pp. 105–110, July 2008. [12] C. Rotsos, N. Sarrar, S. Uhlig, R. Sherwood, and A. W. Moore, “Oflops:
An open framework for openflow switch evaluation,”13th Passive and Active Measurement Conference, 2012, (to appear).
[13] J. Naous, D. Erickson, G. A. Covington, G. Appenzeller, and N. McK-eown, “Implementing an openflow switch on the netfpga platform,” in Proceedings of the 4th ACM/IEEE Symposium on Architectures for Networking and Communications Systems, ser. ANCS ’08. New York, NY, USA: ACM, 2008, pp. 1–9.
[14] “Controller performance comparison,” November 2011. [On-line]. Available: http://www.openflow.org/wk/index.php/ Con-troller Performance Comparisons
[15] S. Ratnasamy, A. Ermolinskiy, and S. Shenker, “Revisiting ip multicast,”
SIGCOMM Comput. Commun. Rev., vol. 36, pp. 15–26, Aug. 2006. [16] I. Martinez-Yelmo, D. Larrabeiti, I. Soto, and P. Pacyna, “Multicast
traffic aggregation in mpls-based vpn networks,”Communications Mag-azine, IEEE, vol. 45, no. 10, pp. 78 –85, october 2007.
[17] K.-K. Yap, T.-Y. Huang, B. Dodson, M. S. Lam, and N. McKeown, “Towards software-friendly networks,” inProceedings of the first ACM asia-pacific workshop on Workshop on systems, ser. APSys ’10. New York, NY, USA: ACM, 2010, pp. 49–54.
[18] R. Wang, D. Butnariu, and J. Rexford, “Openflow-based server load balancing gone wild,” in Proceedings of the 11th USENIX conference on Hot topics in management of internet, cloud, and enterprise net-works and services, ser. Hot-ICE’11. Berkeley, CA, USA: USENIX Association, 2011, pp. 12–12.