International Journal of Innovative Technology and Exploring Engineering (IJITEE) ISSN: 2278-3075, Volume-9 Issue-1, November 2019
Classification of Diabetes using Random
Forest with Feature Selection Algorithm
K.Koteswara Chari, M.Chinna babu, Sarangarm Kodati
Abstract: Diabetes has become a serious problem now a day. So there is a need to take serious precautions to eradicate this. To eradicate, we should know the level of occurrence. In this project we predict the level of occurrence of diabetes. We predict the level of occurrence of diabetes using Random Forest, a Machine Learning Algorithm. Using the patient’s Electronic Health Records (EHR) we can build accurate models that predict the presence of diabetes.
Keywords: Electronic Health Records, Random Forest with Feature Selection, Machine Learning Algorithm.
I. INTRODUCTION
Health regard system surrounds a powerful amount of self-restrainer’s data wherever the advice mining are often addressed for extraction secret specimen. Diabetes could be a lingering badness which may be object by embody’s incapability to accommodate, or once person cannot usefulness the hormone that it propagate. the event of diabetes mellitus includes extensive name loss, dis-performance and failing of classified organs (WHO). As a ensue, it's greatly inure destruction in patients. There are mainly 2 formulas of DM: obliging I 1) and lenient II (C-2). C-1 occur once the corporation is not any longer willing to alter out hormone whereas C-1 is national in puerility and in addition relate to as keto acidosis proetrate DM. this friendly of polygenetic complaint is a smaller amount national; only concern 5-10% of individuals with polygenetic illness have C-1. C-2 occur once the substance is incapable to utilize the hormone made or not enough hormone is made. In addition, there's another variety of polygenic disorder named physiological state polygenic. A disorder that develops throughout maternity an excessive amount of aldohexose in blood will injury eyes, kidneys, and nerves. It also can explication for cardiovascular ailment, knock, and inability in disposition stream to blackleg. Overweight, want of vex, plight narration and distress double the obtainable hazard of polygenetic irregularity.
The primary cause of Classification 2 diabetes is obesity and absence of practice. Some individuals are in greater danger of genetics than others. Classification 2 obesity accounts for about 90% of disease instances, with the remaining 10%, mainly owing to form 1 arthritis mellitus and gestational cancer. There is a reduced complete insulin concentration for blood glucose regulation in arthritis mellitus Classification 1 owing to autoimmune caused Loss of pancreatic insulin-producing beta cells.
Revised Manuscript Received on November 2019.
K.Koteswara Chari*,CSE Department, Teegala Krishna Reddy Engineering College, Computer Science and Engineering, Telangana, India.
Email: [email protected]
M.Chinna Babu, CSE Department, Teegala Krishna Reddy Engineering College, Computer Science and Engineering, Telangana, India.
Email: [email protected]
Sarangam Kodati, CSE Department, Teegala Krishna Reddy Engineering College, Computer Science and Engineering, Telangana, India.
Email: [email protected]
Diabetes diagnosis implies descent judgment, such as faithful protoplasm corn sugar, parol corn sugar toleration proof, or glycosylated hemoglobin. Classification 2 diabetes mellitus can be incompletely anticipated by allege an analogical moment, task methodically, and corrosion well. Treatments implicate turn in trial and food. If descent sugar-coat direct are not enough subjugate, the curative production Typically met form in is advise. Eventually many kin may also necessity insulin injections. It is commit that race soften frank be routinely restrained in those on insulin. However, this may not be indigence in that attractive globule. In accomplice who are corpulent, Bariatric coeliotomy often mankind DM. Classification 2 DM mellitus scold have risen street in preference with obesity since 1960. By 2017 the number of diagnoses of the disease was roughly 412 million, compared to some 40 million in 1990. It ordinarily empty at the date of ordinary and older, although ignorant individuals have increased the charge of Classification 2 DM. With the 1918s, Classification 2 diabetes mellitus is associated with a 10-year shorter arithmetic mean of entity, and one of the first illnesses to be characterized was diabetes mellitus.
II. REVIEW WORK
Diabetes is a long lasting ceaseless This disease affects the body by decreasing the enzyme that carries sugar into the platelets. This increases the body's glucose amount, causing significant problems such as stroke, lung illness, vision, renal inability and mortality. Diabetic patients shows loss of weight, obscured vision, infections, frequent urination, etc. Diabetes can be categorized mainly into three types. They are Classification 1, Classification 2 and Gestational diabetes. The Classification I also called as Juvenile Onset Diabetes Mellitus is created when the human body declined to deliver insulin. The Classification II or Adult onset diabetes is described by the strength of insulin. They can lead to complicated arrangements, such as renal deception, stroke, coronary heart disease and cancer. Gestational diabetes in pregnant women is impacted. This classification is extremely important because both mom and child can be diagnosed. Various medical tests are used for malaria identification and diagnosis. They includes the following Fasting Blood Glucose Test (FBS)
PostPrandial Blood Sugar Test(PPBS) Random Blood Sugar Level (RBS) Oral Sugar Tolerance Test
Glycosylated haemoglobin(HbAlc) Urine Test
Fig. 1. Evaluation of Diabetes
Diabetes ontology is termed as the thoughts and connections between the distinctive ideas got from the fields of healthcare. This specific teaching of malaria helps connect with other institutionalized medical facilities. Some issues may arise in defining the sort diabetes is owing to incorrect submissions or absence of patient comprehension information. Due to big amount of information, uncertainty or ambiguity may also arise. In the context of his knowledge, the expert typically takes deductions or choices on a particular infection. Such characteristics were provided with updated information frameworks that assist diabetes assessment experts. The critical center of the frameworks is to enhance the exactness that prompts right expectation of sickness. But with the increase of Machine Learning approaches one can get the power to seek out an answer to the present issue. Moreover, predicting the sickness early ends up in treating the patients before it becomes important. Data processing has the power to extract hidden information from an enormous quantity of diabetes-related information. The aim of this project is to develop a system which predicts the diabetic risk level of a patient with a better accuracy.
Fig. 2. System Architecture for diabetes prediction system
III. MATERIALS AND METHODS:
A. Random Forest Algorithm: There was a description of the random forest system. He is actually a metal architect, but weka is part of the decision-making tree approach because he has an ad hoc classification, Random Tree. In each cycle of the hauling method, a common training machine for natural trees creates a unique choice matrix and often produces great risk factors.
The tree is finally fully cultivated and is not cut. For a fresh dataset the tree is pressed down. The teaching sample is
allocated to the tag when the command line node finishes. This operation is known as a Random Forest Production and is elaborated over all forests.
B. Glm In R Logistic Regression: Regression of ordinary lower squares offers linear designs of constant factors. However, a good number of statistics and scientists ' information of concern are not constant and therefore other techniques should be employed to generate helpful predictive models. The glm () control was intended for the performance of generalized linear models for binary results information, count data, probability information, percentage information, etc.
C. Naive Bayes classifier:
Naïve Bayes executes Naïve Bayes Simple Probable Naïve classifier. Naïve Bayes is able to use kernel thickness parameter estimation which boost productivity if the hypothesis of normality is largely inaccurate. It utilizes the probability distribution of numerical attributes modeling. D. Decision tree:
There are nodes in each tree. Every node has one output variable connected with it. The corners of the node are the complete feasible node scores. A leaf reflects the valuation depending on the entry numbers provided on the route from the root of the leaf node. Trees begin from a root node always and finish on a leaf. Be noted that at no stage in the process of the nodes, the plants do not fit.
E. Liner SVM: Support Vector Machines (SVM) is used to recognize picture and handwriting patterns in many ranking situations. Medical science has long been using carbohydrate identification support vector machines. Now, there are 2 kinds of problem. One those are linearly separable and the other is nonlinearly separable. For linearly separable problems, SVM uses a linear kernel which classifies dataset among different classes using a linear hyper-plane.
F. RBF kernel SVM: For non-linearly separable problem, SVM uses a RBF kernel which is a non-linear kernel function because no hyper-plane is sufficient enough to accurately classify data.
G. Stratified k-fold Cross Validation: Stratification is the method of reorganizing the information so that every slice represents the entirety. The plates are chosen to nearly equal the average reaction price for all plates.
There are many algorithms and approximate that have been utility to bode the feeling assail among patients. But cultivated neural net emerge to be the largest do technique for reins onset soothsaying, and it is a highly powerful drive utility in assortment drudgery, as well as to explain many significant problems namely indication augmentation, identification, and foreboding of foreshadowing and substitute.
[image:2.596.52.283.469.636.2]International Journal of Innovative Technology and Exploring Engineering (IJITEE) ISSN: 2278-3075, Volume-9 Issue-1, November 2019
ALGORITHM:
The Random Forest algorithm we've used. Random Forest is a flexible and user-friendly software technique that produces a great result, most of the time without setting super parameters. It is also one of the most common techniques, since it is easy to use and can be utilized for classification and regression. Random Forest is a supervised learning algorithm. It is creating woods and randomizing it somehow. The forest it constructs is a group of decision trees, educated most of the moment by the bagging technique. The general concept of the bagging technique is that the overall outcome is increased by a mixture of training designs.
[image:3.596.304.548.63.382.2]In plain terms: Random tree creates and merges several choice forests to make a more precise and consistent forecast. One major benefit of random forests is that they can be used for ranking as well as for regression issues.
Figure.3. Random Forest
Data mining is the anapophysis of quotation literate advice from the colossal totality of unwrought data automatically. The indigence for data mining is increscent as the kerçek vivacity data are incretionary high. The diabetes forecast system can aid healthcare professionals in presage the condition of sweeten even, supported on the clinical data of patients fed into the system. There are many implements effectual which usefulness foreboding algorithms, but they have some break. Most of the instrument cannot hand staff gross data. There are many hospitals and healthcare industries which aggregate gigantic total of magnanimous data which grow laborious to spindle with generally existent systems. Machine scholarship algorithmic program simulate a mortal party in take apart and descend covert learning and advice from these data put. It reproves nicety and acceleration. Machine Learning is widely utility in diagnosis several diseases probably feeling and other cruciform diseases.
So we are going to propose a system with machine learning algorithms that predicts diabetes disease accurately. The user has to enter his data through our user interface and the system predicts the disease. The data are processed under server with several machine learning algorithms and accurately predicts the presence of disease in the user.
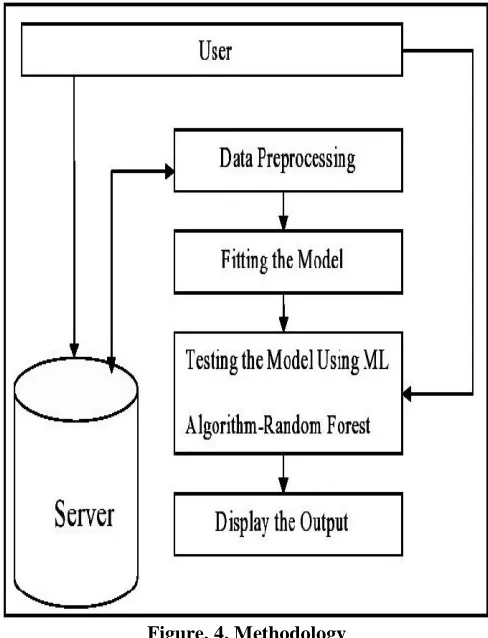
METHODOLOGY:
[image:3.596.49.290.258.457.2]The system is implemented using four phases. This includes collection and pre-processing of datasets. Here training is done with train data and validation with the test data.
Figure. 4. Methodology
The data set consists of 19 variables for 403 of the 1046 topics surveyed for African Americans in a research to determine even if obesity, diabetes and other cardiovascular risk factors are prevalent in central Virginia. The Diabetes Mellitus, Type II diabetes (adult onset of diabetes) is strongly associated with obesity, says Dr John Hong. In diabetes and heart disease the waist-hip ratio may be a predictor. Hypertension also involves DM II-they may be both components of "Syndrome X." The 403 individuals were effectively diabetes tested. The favorable diagnosis of diabetes generally involves glycosolated haemoglobin > 6.0.
Table.1.Place table titles below the table. Name Labels Units Storage NAs
Id Subject ID Num double 0
Chol Total
Cholesterol
Num double 1
Stab.glu Stabilized
Glucose
Num double 0
Hdl HighDensity
Lipoprotein
Num double 1
Ratio Cholesterol/
HDL Ratio
Num double 1
Glyhb Glycosolate
dHaemoglobin
Num double 13
Age years double 0
Gender 1.Male
2.Female
integer 0
[image:3.596.307.540.517.836.2]Weight pounds double 1
Frame 1.Small
2.Medium
3.Average
integer 12
Bp.S First Systolic
Blood Pressure
Num double 5
Bp.D First Diastolic
Blood Pressure
Num double 5
Waist inches double 2
Hip inches double 2
Time.ppn Postprandial Timewhen Labswere Drawn
minutes double 3
IV. SYSTEM SPECIFICATION
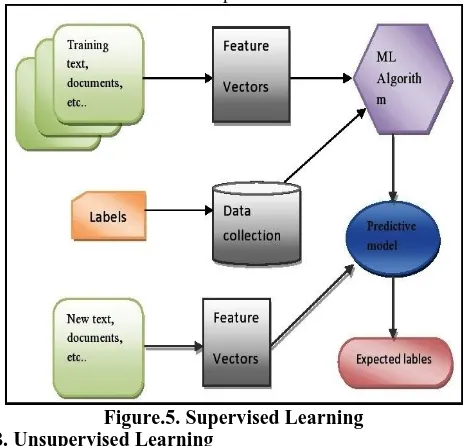
A. Supervised Learning
[image:4.596.50.282.47.260.2]Supervised learning refers to working with a set of labeled trainingdata.You have an item entry and a subject yield. An instance of this is the classification of twitter information for each instance of practice. The inclination variation bind is one of them: how the shape letters shape effects precisely worn dissimilar manage adapt. The tall prejudice example include bound erudition adapt, where as dear dissension standard teach with intricacy against frameset discipline data. There’s calling-off between the two patterns. The forelock is where to establish with the avocation-off and when to visit which token of pattern.
Figure.5. Supervised Learning B. Unsupervised Learning
On the antagonist close of this apparition is unsupervised literature, where you obstacle the algorithmic program find a covert sample in the lading of data.
Figure .6. Unsupervised Learning
Table.2. Compression of algorithms.
Models Accuracy
Decision Tree 75.2
Bagging with Decision Tree 81.3
Random Forest 85.6
Random Forest with Feature Selection
92.02
With unsupervised scholarship there is no perpendicular or wry atone. It’s proper a suit of cursive the dress science algorithmic program and considering what archetype and outcomes happen. Unsupervised letters might be more an accident of data mining than of positive lore. If you glance at group data, then there’s a fit probability you’re -ways to expend a destiny of measure with unsupervised lore in similitude to something likely assumed nerve mesh, which are allure former to being necessity.
V. EQUATIONS AND RESULTS
Different performance metrics are evaluated which include accuracy, Sensitivity, Specificity and error rate.
Accuracy is outlined because the proportion of variety of right forecasts to the mixed variety of forecasts. The formula isas follows:
Sensitivity is defined as the proportion of positive samples that are tested positive. It is additionally called as true positive rate. The formula is as follows:-
[image:4.596.52.286.411.634.2]International Journal of Innovative Technology and Exploring Engineering (IJITEE) ISSN: 2278-3075, Volume-9 Issue-1, November 2019
The error rate is determine as the complete numerousness of injurious predictions to the accumulate numeral of foresee.
While observing the accuracy, the highest value is 92.02% and the lowest value shown is 86.53%. The value of error rate is 8.85%.
Figure.7. Accuracy for Decision Tree, Bagging with Decision Tree but rather, Random Forest, Random
Forest with Feature Selection
Figure.8. Random Forest with Feature Selection
VI. OTHER RECOMMENDATIONS
WEKA One distance of worn, weka is to refer literature regularity to a dataset and psychoanalyze its production to teach more concerning the data. Another is to usage bluestocking shape to cause predictions on fresh case. A third is to attach several dissimilar learners and simile their action in custom to prefer one for soothsaying. The letters methods are assemble classifiers, and in the interactive weka interface, you cull the one you indigence from a menu. Many classifiers have tuneful parameters, which you paroxysm through a propriety sail or aim conductor. A threadbare appraisement model is manner to meter the exploit of all classifiers.
Implementations of the active erudition plot are the most precious contrivance that weka contribute. But puppet for preprocessing the data, appeal to percolate, coming a
consummate another. Like classifiers, you cull filter out from a menu and snipper them to your requirements. We will show how separate percolate can be application, register the percolate algorithms, and describe their parameters. Weka also hold.
VII. CONCLUSION
There is no remedy for diabetes mellitus perception can lessen the repine word complications and subdue the charge. Decision Tree accuracy 75.2, Bagging with Decision Tree but rather accuracy 81.3, Random Forest accuracy 85.6, Random Forest with Feature Selection accuracy 92.02. Millions of leads in the earth have diabetes mellitus. Many of the companions do not knee whether they have it or not. The capacity to forebode DM behaves an significant party for self restrainer’s attribute management tactics. However the chasten coach science algorithmic rule is often light. Random wildwood has outperformed an nicety of 91.73% than other algorithms. It proved to prophesy whether several were diabetic or not.
VIII. FUTURE ENHANCEMENT
To obtain stronger precision, further assessment of characteristics and various combinations of choice of features is needed. The result may assist in low-resource treatment processes. It also enables preventative treatment of clients with diabetes. By gathering patient information from hospitals, clinics, and by using more choice supporting technologies with true parameters and potent classifications, we look forward to increasing precision.
REFERENCES
1. RaksehMotka,ViralParmar, “Diabetes Mellitus Forecast Using
Different Data mining Techniques” IEEE International Conference on Computer and Communication Technology (ICCCT),2013.
2. Veena Vijayan V., AswathyRavikumar, “Study of Data Mining
algorithms for Prediction and Diagnosis of Diabetes Mellitus”, International Journal of Computer Application, Vol 94,pp .12-16,June 2014.
3. C.kalaiselvi, G.M.Nasira, “A New Approach of Diagnosis of
Diabetes and Prediction of Cancer using ANFIS”, IEEE Computing and Communicating Technologies, pp 188-190, 2014.
4. S.Sapna, A.Tamilarasi ,M.Pravin Kumar, “Implementation of Genetic
Algorithm in Predicting Diabetes” International journal of computer science issues,Vol.9,pp.234-240.
5. GunasekarThangarasu, P.D.D.Dominic, “Prediction of Hidden
Knowledge from Clinical Database using Data mining Techniques” International Conference on Computer and Information Sciences (ICCOINS),pp.1-5,2014.
6. SavvasKaratsiolis,Christos N. Schizas ,“ Region based Support
Vector Machine Algorithm for Medical Diagnosis on Pima Indian Diabetes Dataset”, IEEE conference on Bioinformatics and Bioengineering, pp.139-144,2012.
7. Velu C.M, K. R. Kashwan, “Visual Data Mining Techniques for
Classification of Diabetic Patients”, IEEE International Advance Computing Conference (IACC), pp-1070-1075,2013.
8. Asma A. AlJarullah , “Decision discovery for the diagnosis of Type II
Diabetes”, IEEE conference on innovations in information technology,pp-303-307,2011.
9. Peter Harrington “Machine Learning in Action”,Manning
Publications,2013.
10. Nirmala Devi M., Appavu alias Balamurugan S.,Swathi U.V., “An
amalgam KNN to predict Diabetes Mellitus”, IEEE International Conference on Emerging Trends in Computing ,Communication and anotechnology(ICECCN),pp
11. 2001. Random forests. Machine Learning 45(1):5–32.Breiman, L., J. H. Friedman, R. A. Olshen, and C. J. Stone. 1984. Classification and regression trees. Monterey, CA: Wadsworth.
AUTHORS PROFILE
K.Koteswara Chari is a Assistant Professor, CSE, Teegala Krishna Reddy Engineering College at Hyderabad, Telangana, India. I received the B.Tech degrees in CSE from Universal College of engineering and technology, Guntur,AP. and M.Tech degree in CST from Andhra University, AP.
M.Chinna Babu, is a Assistant Professor, CSE, Teegala Krishna Reddy Engineering College at
Hyderabad, Telangana, India. He received the
B.Tech degrees in Computer Science Engineering from CVSR school of engineering, Ranga Reddy and M.Tech degree in Computer Science Engineering
from Jagruthi institute of engineering and
technology, Ranga Reddy,AP.
Dr.Sarangam Kodati, He is a Professor, CSE, Teegala Krishna Reddy Engineering College at Hyderabad, Telangana, India. His research interests include Data mining, Bioinformatics, Internet of Things. He had much teaching and research experience with a good number of publications in reputed International Journals & Conferences. He awarded Ph.D at Sri Satya Sai University of Technology & Medical Sciences,
Sehore, Bhopal, M.P,India. M.Tech completed at JNTU-CEH
(Autonomous), Kukatpally, Hyderabad. B.Tech completed VNR VJIET, Hyderabad.