A Hierarchical Framework for Cross-Domain MapReduce
Execution
Yuan Luo
1,2, Zhenhua Guo
1,2, Yiming Sun
1,2, Beth Plale
1,2, Judy Qiu
1,2, Wilfred Li
3,41
School of Informatics and Computing, Indiana University, Bloomington, IN, 47405
2
Pervasive Technology Institute, Indiana University, Bloomington, IN, 47408
3
San Diego Supercomputer Center, University of California, San Diego, La Jolla, CA, 92093
4
National Biomedical Computation Resource, University of California, San Diego, La Jolla, CA, 92093
{yuanluo, zhguo, yimsun, plale, xqiu}@indiana.edu, [email protected]
ABSTRACT
The MapReduce programming model provides an easy way to execute pleasantly parallel applications. Many data-intensive life science applications fit this programming model and benefit from the scalability that can be delivered using this model. One such application is AutoDock, which consists of a suite of automated tools for predicting the bound conformations of flexible ligands to macromolecular targets. However, researchers also need sufficient computation and storage resources to fully enjoy the benefit of MapReduce. For example, a typical AutoDock based virtual screening experiment usually consists of a very large number of docking processes from multiple ligands and is often time consuming to run on a single MapReduce cluster. Although commercial clouds can provide virtually unlimited computation and storage resources on-demand, due to financial, security and possibly other concerns, many researchers still run experiments on a number of small clusters with limited number of nodes that cannot unleash the full power of MapReduce. In this paper, we present a hierarchical MapReduce framework that gathers computation resources from different clusters and run MapReduce jobs across them. The global controller in our framework splits the data set and dispatches them to multiple “local” MapReduce clusters, and balances the workload by assigning tasks in accordance to the capabilities of each cluster and of each node. The local results are then returned back to the global controller for global reduction. Our experimental evaluation using AutoDock over MapReduce shows that our load-balancing algorithm makes promising workload distribution across multiple clusters, and thus minimizes overall execution time span of the entire MapReduce execution.
Categories and Subject Descriptors
C.2.4 [Distributed Systems]: MapReduce Architecture -
Hierarchical MapReduce for Life Science Applications.
General Terms
Performance, Experimentation
Keywords
AutoDock, Cloud, MapReduce, Multi-Cluster, FutureGrid
1.
INTRODUCTION
Life science applications are often both compute intensive and data intensive. They consume large amount of CPU cycles while processing massive data sets that are either in large group of small files or naturally splittable. These kinds of applications ideally fit in the MapReduce programming model. MapReduce uses a different model from the traditional HPC model. It does not distinguish computation nodes and storage nodes. Each node is responsible for both computation and storage. Obvious advantages include better fault tolerance, scalability and data locality scheduling. The MapReduce model has been applied to life science applications by many researchers. Qiu et al. [14] describe their work to implement various clustering algorithm using MapReduce.
AutoDock [12] is a suite of automated docking tools for predicting the bound conformations of flexible ligands to macromolecular targets. It is designed to predict how small molecules of substrates or drug candidates bind to a receptor of known 3D structure. Running AutoDock requires several pre-docking steps, e.g., ligand and receptor preparation, and grid map calculations, before the actual docking process can take place. There are desktop GUI tools for processing the individual AutoDock steps, such as AutoDockTools (ADT) [12] and BDT [18], but they do not have the capability to efficiently process thousands to millions of docking processes. Ultimately, the goal of a docking experiment is to illustrate the docked result in the context of macromolecule, explaining the docking in terms of the overall energy landscape. Each AutoDock calculation results in a docking log file containing information about the best docked ligand conformation found from each of the docking runs specified in the docking parameter file (dpf). The results can then be summarized interactively using the desktop tools such as AutoDockTools or with a python script. A typical AutoDock run consists of a large number of docking processes from multiple targeted ligands and would take a large amount of time to finish. However, the docking processes are data independent, so if several CPU cores are available, these processes can be carried out in parallel to shorten the overall length of AutoDock run duration.
data sit in shared storage space with users worldwide, while others may have large amounts of data and computation that would be financially too expensive to move into the cloud. It is more typical for a researcher to have access to several research clusters hosted at his/her lab or institute. These clusters usually consist of only a few nodes, and the nodes in one cluster may be very different from those in another cluster in terms of various specifications including CPU frequency, number of cores, cache size, memory size, and storage capacity. Commonly a MapReduce framework is deployed in a single cluster to run jobs, but any such individual cluster does not provide enough resources to deliver significant performance gain. For example, at Indiana University we have access to IU Quarry, FutureGrid [4], and Teragrid [16] clusters but each cluster imposes limit on the maximum number of nodes a user can uses at any time. If these isolated clusters can work together, they collectively become more powerful.
Unfortunately, users cannot directly throw a MapReduce framework such as Hadoop on top of these clusters to form a single larger MapReduce cluster. Typically the internal nodes of a cluster are not directly reachable from outside. However, MapReduce requires the master node to directly communicate with any slave node, which is also one of the reasons why MapReduce frameworks are usually deployed within a single cluster. Therefore, one challenge is to make multiple clusters act collaboratively as one so it can more efficiently run MapReduce. There are two possible approaches to address this challenge. One is to unify the underlying physical clusters as a single virtual cluster by adding a special infrastructure layer, and run MapReduce on top of this virtual cluster. The other is to make the MapReduce framework directly working with multiple clusters without needing additional special infrastructure layers.
We propose a hierarchical MapReduce framework which takes the second approach to gather isolated cluster resources into a more capable one for running MapReduce jobs. Kavulya et al. characterize MapReduce jobs into four categories based on their execution patterns: map-only, map-mostly, shuffle-mostly, and reduce-mostly, and also find that 91% of the MapReduce jobs they have surveyed fall into the map-only and map-mostly categories [9]. Our framework partitions and distributes MapReduce jobs from these two categories (only and map-mostly) into multiple clusters to perform map-intensive computation, and collects and combines the outputs in the global node. Our framework also achieves load-balancing by assigning different task loads to different clusters based on the cluster size, current load, and specifications of the nodes. We have implemented the prototype framework using Apache Hadoop. The rest of the paper is organized as follows. Section 2 presents some related works. Section 3 gives an overview of our hierarchical MapReduce framework. Section 4 presents more details on the application of AutoDock using MapReduce. Section 5 gives experiment setup and result analysis. The conclusion and future work are given in Section 6.
2.
RELATED WORKS
Researchers have put significant efforts to the easy submission and optimal scheduling of massive parallel jobs in clusters, grids, and clouds. Conventional job schedulers, such as Condor [11], SGE [5], PBS [7], LSF [22], etc., aim to provide highly optimized resource allocation, job scheduling, and load balancing, within a single cluster environment. On the other hand, grid brokers and metaschedulers, e.g., Condor-G [3], CSF [2], Nimrod/G[1], GridWay [8], provide an entry point to multi-cluster grid
environments. They enable transparent job submission to various distributed resource management systems, without worrying about the locality of execution and available resources there. With respect to the application of AutoDock, our earlier efforts presented at National Biomedical Computation Resource (NBCR) [13] Summer Institute 2009, addressed the performance issue of massive docking processes by distributing the jobs to the grid environment. We used the CSF4 [2] meta-scheduler to split docking jobs to heterogeneous clusters where these jobs were handled by local job schedulers including LSF, SGE and PBS. Clouds give users virtually unlimited, on-demand resources for computation and storage. Attributed to its ease of executing pleasantly parallel applications, MapReduce has become a dominant programming model for running applications in a cloud. Researchers are discovering new ways to make MapReduce easier to deploy and manage, more efficient and scalable, and also more able to accomplish complex data processing tasks. Hadoop On Demand (HOD) [6] uses the TORQUE resource manager [15] to provision and manage independent MapReduce and HDFS instances on shared physical nodes. The authors of [20] have identified some fundamental performance limitation issues in Hadoop and in the MapReduce model in general which make job response time unacceptably long when multiple jobs are submitted; by substituting their own scheduler implementation, they are able to overcome these limitations and improve the job throughput. CloudBATCH [21] is a prototype job queuing mechanism for managing and dispatching MapReduce jobs and commandline serial jobs in a uniform way. Traditionally a cluster must separate MapReduce-enabled nodes because they are dedicated to MapReduce jobs and cannot run serial jobs. But CloudBATCH uses HBase to keep various metadata on each job and also uses Hadoop to wrap commandline serial jobs as MapReduce jobs, so that both types of jobs can be executed using the same set of cluster nodes. The Map-Reduce-Merge is extended from the conventional MapReduce model to accomplish common relational algebra operations over distributed heterogeneous data sets [19]. In this extension, the Merge phase is a new concept that is more complex than the regular Map and Reduce phases, and requires the learning and understanding of several new components, including partition selector, processors, merger, and configurable iterators. This extension also modifies the standard MapReduce phase to expose data sources to support some relational algebra operations in the Merge phase.
Sky Computing [10] provides end user a virtual cluster interconnected with ViNe [17] across different domains. It aims to bring convenience by hiding the underlying details of the physical clusters. However, this transparency may cause unbalanced workload if a job is dispatched over heterogeneous compute nodes among different physical domains.
Our hierarchical MapReduce framework, aims to enable map-only and map-most jobs to be run across a number of isolated clusters (even virtual clusters), so these isolated resources can collectively provide a more powerful resource for the computation. It can easily achieve load-balance because the different clusters are visible to the scheduler in our framework.
3.
HIERARCHICAL MAPREDUCE
capability of each local cluster. If the input data has not been deployed onto the cluster already, the global controller also partitions input data proportionally to the sub-jobs, and sends them to these clusters. After the jobs are all finished on all clusters, the global controller collects the outputs to perform a final reduction using the global reducer which is also supplied by the user. The bottom layer consists of multiple local clusters that each receives sub-jobs and input data partitions from the global controller, performs local MapReduce computation and sends results back to the global controller.
Although on the surface our framework may appear structurally similar to the Map-Reduce-Merge model presented in [19], our framework is very different in nature. As discussed in the related work section, the Merge phase introduced in the Map-Reduce-Merge model is a new concept which is different and more complex than the conventional Map and Reduce, and programmers implementing jobs under this model must not only learn this new concept along with the components required by it, but also need to modify the Mappers and Reducers to expose data source. Our framework, on the other hand, strictly uses the conventional Map and Reduce, and a programmer just needs to supply two Reducers – one local Reducer, and one global Reducer – instead of just one for the regular MapReduce. The only requirement is that the programmer must make sure that the formats of the local Reducer output keys/value pairs match those of the global Reducer input key/value pairs. However, if the job is map-only, the programmer does not need to supply any reducers, and the global controller simply collects the map results from all clusters and places them under a common directory.
3.1
Architecture
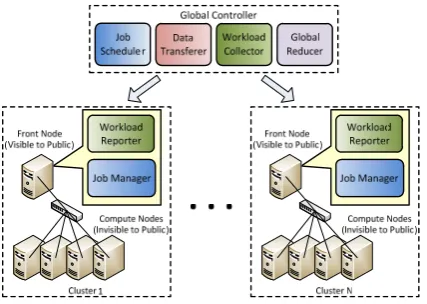
[image:3.595.62.276.500.652.2]Figure 1 is a high-level architecture diagram of our hierarchical MapReduce framework. The top layer in our framework is the global controller, which consists of a job scheduler, a data transferer, a workload collector, and a use-supplied global reducer. The bottom layer consists of multiple clusters for running the distributed local MapReduce jobs, where each cluster has a MapReduce master node with a workload reporter and a job manager. The compute nodes inside each of the cluster are not accessible from the outside.
Figure 1. Hierarchical MapReduce Architecture
When a user submits a MapReduce job to the global controller, the job scheduler splits the job into a number of sub-jobs and assigns them to each local cluster based on several factors, including the current workload reported by the workload reporter from each local cluster, as well as the capability of individual nodes making up each cluster. This is done to achieve
load-balance by ensuring that all clusters will finish their portion of the job in roughly the same time. The global controller also partitions the input data in proportion to the sub-job sizes if the input data have not been deployed before-hand. The data transferer would transfer the user supplied MapReduce jar and job configuration files with the input data partitions to the clusters. As soon as the data transfer finishes for a particular cluster, the job scheduler at the global controller notifies the job manager of that cluster to start the local MapReduce job. Since data transfer is very expensive, we recommend that users only use the global controller to transfer data when the size of input data is small and the time spent for transferring the data is insignificant compared to the computation time. For large data sets, it would be more efficient and effective deploy them before-hand, so that the jobs get the full benefit of parallelization and the overall time does not get dominated by data transfer. After the local sub-jobs are finished on a local cluster, if the application requires, the clusters will transfer the output back to the global controller. Upon receiving all the output data from all local clusters, the global reducer will be invoked to perform the final reduction task, unless the original job is map-only.
3.2
Programming Model
The programming model of our hierarchical MapReduce framework is the “Map-Reduce-Global Reduce” model where computations are expressed as three functions: Map, Reduce, and Global Reduce. We use the term “Global Reduce” to distinguish it from the “local” Reducer, but conceptually as well as syntactically, a Global Reducer is just another conventional Reducer. Users of our framework implement the three functions as a Mapper, a Reducer, and a Global Reducer, and submit the jar to the global controller. The Mapper, just as a conventional Mapper does, takes an input pair and produces an intermediate key/value pair; likewise, the Reducer, just as a conventional Reducer does, takes an intermediate input key and a set of corresponding values produced by the Map task, and outputs a different set of key/value pairs. Both the Mapper and the Reducer are executed on local clusters. The Global Reducer is also a conventional Reducer, except that it is executed on the global controller using the output from the local clusters. For map-only jobs, the programmer does not need to supply any reducers, and the global controller simply collects the map results from all clusters and places them under a common directory. Table 1 lists these 3 functions and also the input and output data types. The formats of the local Reducers output keys/value pairs must match those of the Global Reducer input key/value pairs.
Table 1. Input and output types of Map, Reduce, and Global Reduce functions
Function Name Input Output
Map , ,
Reduce , , … , , Global Reduce , , … , ,
( a c i p t k s a R c R S T j h c d c m i e c c
3
T a h T s p c o w I s r c a d a t W a s w M s r1, and then the (global controll also Map tasks consumes an intermediate ke pairs are passed the local cluste key with a set o set of key/value are send back Reduce task. T corresponding v Reducers, perfo Step 5. Theoretically, t just two hierarc have more dept controllers simi divide its assig clusters. But fo more than two increase the co each additional clusters availab create a broader
3.3
Job Sc
The main chall among each lo how the dataset The input datas submitted by th pre-deployed on catalog to the u on the global c when partitionin In this paper, w submitted by th run separate s consuming and automatically c dataset using u and divides the to each cluster. We make the application are same amount o we will see in MapReduce d scheduling algo run concurrentl
input key/value ler) to the child are launched a input key/valu ey/value pairs.
d to the Reduc ers. Each Redu of correspondin e pairs as outpu to the global he Global Redu values that were orms the compu
the model we pr chical layers, i.e th by turning th ilar to the globa gned jobs and ru for all practical
layers for the f omplexity as we layer. If a rese ble, it is most l
[image:4.595.50.277.351.446.2]r bottom layer t
Figure 2. Pro
cheduling a
enge of our wo ocal MapReduc ts are partitioned set for a particu he user to the gl
n the local clus user who runs controller takes ng the datasets we focus on th he user. If the
ub-jobs on dif d error-prone. count the total user-implemente e dataset and as
assumption tha computation in of time to run – n the next sect displays exactl orithm we use f be the maxim ly on
e pairs are passe nodes (local clu at the local clust ue pair and In Step 3, the e tasks, which uce task consum ng values, and p ut. In Step 4, th
controller to uce task takes i e originally pro utation, and pro
resent can be ex e. the tree struc e non-leaf clust al controller and
un them on its purposes, we d foreseeable futu ell as the overh earcher has a la ikely more effi than to increase
ogramming Mo
nd Data Pa
ork is how to ba ce cluster, whic
d.
ular MapReduc lobal controller sters and is exp the MapReduce into considerat and scheduling he situation wh user manually fferent clusters Our global co l number of r ed InputFormat signs the correc
at all map task ntensive and tak – this is a reaso tion that runni ly this kind for our framewo mum number of
;
ed from the root usters) in Step 2 ters where each produces a s e set of interme
are also launch mes an interme produces yet an e local reduce o perform the G in a key and a oduced from the oduces the outp
xtended to more cture in Figure ters into interme d each would fu own set of ch do not see a nee
ure, because it head introduced arge number of icient to use the
the depth.
odel
artitioning
alance the work ch is closely ti
ce job may be before executio posed via a met
e job. The sche tion the data lo
the job. here input data
split the datase s, it would be
ontroller is ab records in the t and RecordRe ct number of re
ks of a MapR ke approximate onable assumpti ng AutoDock of behavior. ork is as follow Mappers that c be the numb
t node 2, and h Map et of ediate hed at ediate nother output Global set of e local put in e than 2 can ediate further ildren ed for could d with small em to kloads ied to either on, or tadata eduler ocality aset is et and time ble to input eader, ecords educe ly the ion as using The ws. Let can be ber of Ma the on als cor No com Fo Th fac spe dep com Le job inp tas Af usi mo loc
4.
We usi fea too key the for con T Fo Re 1) exe appers currentl e number of ava; , where so use to de
re, that is,
ormally we set mputation inten
r simplicity, let
he weight of eac ctor is the eed, memory si pending on the mputation inten
t b b x, which can put to the Map sks to be schedu
fter partitioning ing equation (5 ove the data ite cal clusters, or f
AUTODO
e apply the Ma ing the hierar asibility of our a ol in the Auto y/value pairs of e location of lig r AutoDock M
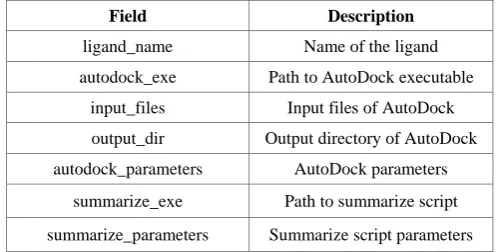
ntains 7 fields s
Table 2. AutoDo
Field ligand_n autodock input_f output_ autodock_pa summariz summarize_p r our AutoDoc educe functions
Map: The Map ecutable against
ly running on ailable Mappers
be t e i is the cluster efine how many
1 in th nsive jobs, so we
t
ch sub-job can computing pow ize, storage cap characteristics nsive or I/O inte
∑
be the total num be calculated tasks, and uled to
g the MapRedu ), we number t ms accordingly from local cluste
OCK MAPR
apReduce parad rchical MapRe approach. We t oDock suite) a f the input of the
and files. We d MapReduce jo shown in Table
ock MapReduc d name k_exe files _dir arameters ze_exe arameters ck MapReduce are implemente p task takes a lig
t a shared recep
; s that can be ad the total number r number, and i y map tasks a us
he local MapRe e get
be calculated fr wer of each clus pacity, etc. The of the jobs, i.e. ensive
mber of Map tas from the numb
be th for job x, so
uce job to Sub the data items o y, either from g er to local clust
REDUCE
digm to the Auto educe framewo
take the outputs as input to the e Map tasks are esigned a simpl bs. Each inpu 2, corresponds
ce input fields a
Des
Name o Path to Auto Input files Output direct AutoDoc Path to su Summarize e, the Map, Re ed as follows:
gand to run the ptor, and then ru
dded for execut r of CPU Cores i ∈ 1, . . . , n. W ser assigns to ea
( educe clusters
( from (4) where
ster, e.g., the C actual var ., whether they
( sks for a particu ber of keys in he number of M
that
( b-MapReduce jo of the datasets a global controller
ter.
oDock applicat ork to prove s of AutoGrid (o
e AutoDock. T e ligand names a le input file form ut record, wh
to a map task.
and description
scription
of the ligand oDock executab
s of AutoDock tory of AutoDo ck parameters ummarize script
script paramete educe, and Glo
e AutoDock bin uns a Python scr
[image:4.595.301.550.548.674.2]s c 2 t f l 3 o i
5
W h a s r i t c i m l I c c f r c f m b p E M m n O d T b m i H H t W H r d j E s summarize_resu constant interm 2) Reduce: The the constant int from low to hig local reducer in 3) Global Reduof the local red into a single file
5.
EVALU
We evaluate hierarchical Ma and Shell scrip stage-in and sta reporter is a information acc to make it a se code. Unfortu information we modify Hadoop load data by usi In our evaluatio cluster and two cluster which h from outside. A related tasks, in cancellation. Th from outside. S mounted to eac by the jobs. Fu parts, and each Eucalyptus, Nim MapReduce us model. It does nodes. Each no Obvious advant data locality sch To deploy Had built-in job sc maintainability in shared direct Hadoop progra Hadoop daemo times. We use three c Hotel and Futur run Linux 2.6 dedicated mas jobtracker) and Each node in specifications o T Cluster Hotel In Alamo In Quarry In
ult4.py to outpu mediate key.
e Reduce task ta termediate key gh, and outputs ntermediate key.
uce: The Global ducer intermed e by the energy
UATIONS
our model b apReduce syste pts. We use ssh age-out. On the component th cessed by globa eparate program unately, Hadoo e need to exte p code to add ing Hadoop Jav on, we use seve clusters in Futu has several login After a user lo ncluding job su he computation Several distribut h computation n utureGrid partiti
h of which pro mbus, and HPC ses a different s not distinguis
de is responsibl tages include b heduling. doop to traditio
cheduler (PBS and performan tory while store am (Java jar fi ons whereas th
clusters for eva reGrid Alamo. E .18 SMP. W ster node (HD d other nodes n these cluste of these cluster n
able 3. Cluster
CPU
ntel Xeon 2.93G ntel Xeon 2.67G ntel Xeon 2.33G
ut the lowest e
akes all the valu and sorts the v s the sorted res .
l Reduce finally diate key, sorts from low to hig
by prototyping em. The system h and scp scrip
e local clusters hat exposes H al scheduler. Ou m without touc op does not ernal applicatio
an additional d va APIs. eral clusters incl
ureGrid. IU Qu n nodes that are ogins, he/she c ubmission, job
nodes however ted file systems node for storing ions the physica ovides a differ C.
model from t sh computation le for both comp better fault toler
onal HPC cluste ) to allocate nce, we install t e data in local d files, etc.) is lo e HDFS data i
aluations – IU Each cluster ha Within each clu DFS namenod are data nodes ers has an 8 nodes are listed
r Node Specific
Cach
GHz 8192 GHz 8192 GHz 6144
energy result us
ues correspondi values by the e ults to a file us
y takes all the v and combines gh.
g a Hadoop m is written in pts to finish the
’ side, the wor Hadoop cluster ur original desig
hing Hadoop s expose the ons, and we h daemon that co
luding the IU Q arry is a classic e publicly acce can do various status query an r, cannot be acc s (Lustre, GPFS g input data acc al cluster into se rent testbed su
the traditional n nodes and st
putation and sto rance, scalabilit
ers, we first us nodes. To ba the Hadoop pro directory, becau
oaded only onc is accessed mu
Quarry, Futur as 21 nodes. Th ster, one node de and MapR s and task trac 8-core CPU. d in Table 3.
cations.
he size Mem
2KB 24G 2KB 12G 4KB 16G sing a ing to energy sing a values them based n Java e data rkload load n was source load had to ollects Quarry c HPC essible s job-nd job cessed S) are cessed everal uch as HPC torage orage. ty and se the alance ogram se the ce by ultiple reGrid hey all e is a
educe ckers. The mory GB GB GB Co tas Th ver exe com In the num pro exp 5,0 Fig dur tra mo num beg To qui ind Ma by M P Tes Ou Co onsidering Auto
1 per sect sks on each nod he version of Au rsion. The glo ecution details mplexity.
our experiment e most importa
mber of evalua obability that b
periences, the g
[image:5.595.316.539.240.403.2]000,000. We con
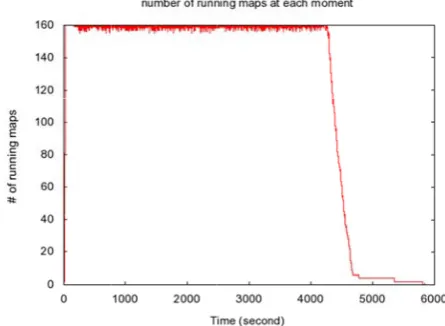
Figure 3: Num
gure 3 plots the ring the job ex ackers, so the m
[image:5.595.311.545.563.702.2]oment is 20 * mber of runni ginning and st owards the end ickly (roughly dicating that no apReduce tasks those new task
Table 4. MapR unde Number of Map Tasks Per Cluster 100 500 1000 1500 2000
st Case 1:
ur first test case ontroller to find
oDock being a C tion 3.3 so tha de is equal to th
utoDock we us obal controller
s because our
ts, we use 6,00 ant configuratio ations. The lar better results m
ga_num_evals i nfigure it to 2,5
mber of runnin MapReduc
number of runn ecution. The cl maximum numb
8 = 160. From ing map tasks tays approxima d of job execu 0 - 5). Notic ode usage ratio
come in, the av ks.
Reduce executi er different nu
Execution Hotel (seconds) 1004 1763 2986 4304 5942
e is a base test c d out how eac
CPU-intensive a at the maximum he number of c e is 4.2 which does not care local job m
00 ligands and 1 on parameters i
rger its value i may be obtained is typically set 500,000 in our e
g map tasks fo ce instance
ning map tasks luster has 20 da ber of running m the plot, we quickly grow ately constant ution, it drops ce there is a t is low. At thi vailable mapper
ion time on dif mber of map t
n Time on Thr Alamo (seconds) 821 1771 2962 4251 5849
case without inv ch of our local
application, we m number of m cores on the no
is the latest sta e about low-le anagers hide
1 receptor. One is ga_num_eval
is, the higher d. Based on pr from 2,500,000 experiments.
or an Autodock
within one clus ata nodes and t
map tasks at a e can see that ws to 160 in for a long tim to a small va tail near the e s moment, if n rs will be occup
fferent clusters tasks. ree Clusters Quarry (seconds) 1179 2529 4370 6344 8778
volving the Glo l Hadoop clust
set map ode. able evel the e of
p A 2 4 A n l T i T C
O M c e c s r d p s c t b s c T l g s a j e c e t d i f c c
performs unde AutoDock in th 2000 ligand/rec 4 for results. As is reflected number of map linear, regardle The total execu is approximatel The main reaso CPUs compared
Figure 4. Loc
Test Case 2:
Our second te MapReduce job clusters, which equation (4) fr constant, and i shows 1 running before distribution on partition the d stage the dat configuration fi the local MapR back to the glo shows the data contexts. The input data ligands. The re gridmap files t stored in 60 approximately job configuratio each cluster, containing 1 r executable jar, transfers it to decompressed. in.” Similarly, w files together w compressed int controller. We c
er different n he Hadoop to ceptor pairs in e
d in Figure 4, p tasks in test ss of the startup ution time of the ly 50% slower on is that nodes d with that of A
cal cluster Map different num
est case show bs with -weigh h is based on th rom section 3.
∈ 1, 2, 3 fo
2 3
ehand. Theref each cluster is ataset (apart fr ta together w file to local clus Reduce executi bal controller f a movement c
aset of AutoDo eceptor is descr totaling 35MB 000 separate 5-6 KB large. on file together the global co receptor file s and job config o the destinati
We call this glo when the local with control file
to a tarball an call this local-to
numbers of m process 100, 5 each of the thre
the total exe case 1 on each p overhead of t e jobs running o
than running o s of the Quarry Alamo and Hote
pReduce execut mber of map ta
ws the perform hted partitioned
he following pa 3, we set or our three clus
160, given no fore, the weig
1
rom shared dat with the jar e sters for execut
on, the output for the final glo cost in the sta
ock contains 1 ribed as a set o
in size, and th directories, e In addition, th r has a total of ontroller create set, 2000 ligan guration files, ion cluster, w obal-to-local pr MapReduce jo s (typically 300 nd transferred o-global proced
map tasks. We 500, 1000, 1500 ee clusters. See
ecution time vs h cluster is clo the MapReduce on the Quarry c on Alamo and H y cluster have s
l.
tion time based asks.
mance of exec datasets on dif arameters setup
, where C sters. Our calcu MapReduce job ght of map
1/3. We then eq taset) into 3 p executable and ion in parallel. files will be s obal reduce. Fig age-in and stag
receptor and of approximate he 6000 ligand each of whic he executable ja 300KB in size es a 14MB t nds directories all compressed where the tarba rocedure “data s obs finish, the o 0-500KB in siz
back to the g dure “data stage
e ran 0 and
Table
s. the ose to e jobs. cluster Hotel. slower
d on
cuting fferent p. For C is a ulation
bs are tasks qually pieces, d job
After staged gure 5 ge-out
6000 ely 20 ds are ch is ar and
. For tarball s, the d, and
all is stage-output
e) are global -out.”
As 13 tak litt com exe
Th Ma clu dat in tim app Ho all onl on
F
Tes
In Ma dif tes ass the of slo Qu Int
s we can see fr .88 to 17.3 seco kes 2.28 to 2.52 tle longer to tra
[image:6.595.315.539.160.294.2]mpare to the ecutions.
Figure 5. Tw partitioned d
he time it takes apReduce cluste usters. The loc
[image:6.595.57.281.214.380.2] [image:6.595.313.535.456.579.2]ta movement co Figure 6. The H me to finish proximately 3,0 otel and Alamo the local result ly 16 seconds t Quarry become
Figure 6. Local datas
st Case 3:
our third test c apReduce jobs fferent clusters, st cases 1 and 2 signed the same e same amount time to finish ower than Alam uarry, Alamo a tel(R) Xeon(R)
rom Figure 5, t onds to finish, w
2 seconds to fi ansfer the data b
relatively long
wo-way data mo datasets: local M
outp
s to run 2000 ers varies due to
al MapReduce osts (both data Hotel and Alam their jobs, b 000 more second . The Global R ts are ready in to finish. Thus, es the bottlenec
l MapReduce t sets, including
case, we evalua s with -we , which is base , we have obser e number of com
of data, they ta h. Among the mo and Hotel. T
and Hotel are X5550 2.67GH
the data stage-i while the data st inish. The Alam but the differen g duration of
ovement cost o MapReduce in puts
map tasks on o the different s execution ma stage-in and st mo clusters take but the Quar ds to finish, abo Reduce task is o the global contr , the relatively ck on the curren
turnaround tim data movemen
ate the perform eighted partitio ed on the follo
rved that althou mpute nodes an ake significantly
three clusters, The specification
Intel(R) Xeon( Hz, and Intel(R
in procedure ta tage-out proced mo cluster take nce is insignific local MapRedu
of -weighted nput and their
each of the lo specification of akespan, includ tage-out) is sho similar amount rry cluster ta out 50% more th only invoked af roller, and it ta
poor performan nt job distributio
me of -weighte nt cost
mance of execut oned datasets
wing setup. Fr ugh all clusters nd cores to proc
y different amo , Quarry is mu ns of the cores (R) E5410 2GH R) Xeon(R) X55
akes dure es a cant uce
ocal the ding own t of akes han fter kes nce on.
ed
2 t d f n c s H c a 0 H p d F s l c 2 t r p W m s a t b r s t 2.93GHz, respe that of processi difference in pr frequencies, th number of co capabilities of scheduling poli Here we set
3 2 for Q calculated 1 are running be
[image:7.595.313.537.90.216.2]0.3860, Hotel, Alamo, partitioned acco dataset is partiti
Table 5. Num
Cluster
[image:7.595.65.275.270.340.2] [image:7.595.60.281.448.583.2]Hotel Alamo Quarry Figure 7 shows scenario. The v ligands sets are can see from th 17.64 seconds t 2.2 to 2.6 seco transfer the dat relatively long previous test ca
Figure 7. T partitioned
With weighted makespan, inclu stage-out) are s amount of time that our refined balancing work reduction comb sorts the result tasks (ligand/re
ectively. The in ing time match r rocessing time erefore, it is n ores for load f each core ar
icy to add CPU
1 2.93 for H Quarry. As is
2 3
eforehand. Thu
2 0.350
and Quarry ording to the n ioned.
mber of Map T Time on
Number of M
2316 2103 1581 s the data move variations in the e quite small, w he graph, the da
to finish, while onds to finish. ta but the differ duration of loc ase.
Two-way data m d datasets: loca
o
d partition, t uding data mov shown in Figur e to finish the l d scheduler conf kload among clu bines partial re ts. The average
ceptor docking)
nverse ratio of roughly. So we is mainly due not enough to m
balancing, an re also importa U frequency as
Hotel, 2 2 for test case
160, given us, the weight
05, and respectively. T ew weight. Tab
Tasks and MapR Each Cluster
Map Tasks Ex
6 3 1
ement cost in th e size of tarball which is smaller ata stage-in proc e the data stage
Alamo takes a rence is also in cal MapReduce
movement cost al MapReduce
utputs
the local Ma vement costs (bo
re 8. All three local MapRedu figuration impro usters. In the fi sults from low e time taken to ) is 16 seconds.
CPU frequency e hypothesize th
to the different merely factor i nd the compu ant. We refine
a factor to set
2.67 for Alamo 2, we again no MapReduce s are
3 0.263
The dataset is ble 5 shows ho
Reduce Execut xecution Time (Seconds) 5915 5888 6395 he weighted par l different numb r than 2MB. A cedure takes 12 e-out procedure a little bit long nsignificant give executions as i
t of -weighte input and thei
apReduce exec oth data stage-i
clusters take si uce jobs. We ca oves performan inal stage, the g
er-level cluster o process 6000
y and hat the t core in the utation e our . o, and have e jobs 1 5 for s also w the tion rtition ber of As we .34 to takes ger to en the in the ed ir cution in and imilar an see nce by global rs and 0 map Fi
6.
In fra clu imp Re fun con mu fun con cap We per wo mi Ou dat com inv vol7.
Ou acc wo8.
[1] [2] [3] [4]igure 8. Local datas
CONCLU
this paper, w amework that c usters and run M mplemented in t
educe” model nctions: Map,
ntroller in our fr ultiple “local” nctions, and th ntroller to run pacity-aware alg e use AutoDoc rformance of orkloads are we
nimum. ur future work
tasets, especia mputing. Instea vestigate movin lume and/or pri
ACKNOW
ur special thank cess to FutureG ork. We also tha
REFERE
] Buyya, R., A architecture f system in a g HPC ASIA'2 ] Ding, Z., We W. Customiz Life Sciences Volume 25, N 10.1007/s003 http://dx.doi. ] Frey, J., Tann
2002. Condo Multi-Institu 2002), 237-2 http://dx.doi. ] FutureGrid, h
MapReduce tu sets, including
USION AND
we have presen an gather comp MapReduce job this framework where compu Reduce, and framework split MapReduce cl e local results the Global Re gorithm to balan ck application our framewor ell balanced an
will address th ally for data ad of moving d ng computation ivacy sensitive.
WLEDGME
ks to Dr. Geof Grid resources ank Chathura H
ENCES
Abramson, D., G for a resource m global computat 2000, China, IEE
ei, X., Luo, Y., M zed Plug-in Mod
s Applications, Number 4, 373-354-007-0024-6 org/10.1007/s0 nenbaum, T., L or-G: A Comput utional Grids. Cl 246. DOI=10.10 org/10.1023/A: http://www.futu urnaround tim data movemen
D FUTURE
nted a hierarch putation resourc bs across them k adopt the “M utations are ex d Global Red s the data set an lusters to run are returned b educe function. ance the workloa as a test case rk. The result nd the total ma
he data locality a-intensive an data to the com to data, which
ENTS
ffrey Fox for p and valuable erath for discus
Giddy, J. Nimrod management and
tional grid, in: P EE CS Press, U Ma, D., Arzberg dules in Metasc
New Generatio -394, 2007, DO 6
0354-007-0024 ivny, M., Foste tation Managem luster Computin 023/A:10156170 :101561701942 uregrid.org
me of -weight
nt cost
E WORK
hical MapRedu ces from differ . The applicatio Map-Reduce-Glo
xpressed as th duce. The glo nd maps them o Map and Redu back to the glo
We use resou ad among cluste e to evaluate t shows that akespan is kept
issue of the in nd data-sensit mputation, we w
might be in la
providing us ea feedback on ssions.
d-G: an d scheduling Proceedings of t USA, 2000.
ger, P. W., Li, W cheduler CSF4 f on Computing OI:
4-6
r, I., Tuecke, S. ment Agent for
[5] Gentzsch, W. (Sun Microsystems). 2001. Sun Grid Engine: Towards Creating a Compute Power Grid. In Proceedings of the 1st International Symposium on Cluster Computing and the Grid (CCGRID '01). IEEE Computer Society,
Washington, DC, USA, 35-39 [6] Hadoop On Demand,
http://hadoop.apache.org/common/docs/r0.17.2/hod.html [7] Henderson, R. L.. 1995. Job Scheduling Under the Portable
Batch System. In Proceedings of the Workshop on Job Scheduling Strategies for Parallel Processing (IPPS '95), Dror G. Feitelson and Larry Rudolph (Eds.). Springer-Verlag, London, UK, 279-294.
[8] Huedo, E., Montero, R. S., and Llorente, I. M. 2004. A framework for adaptive execution in grids. Softw. Pract. Exper. 34, 7 (June 2004), 631-651. DOI=10.1002/spe.584 http://dx.doi.org/10.1002/spe.584
[9] Kavulya, S., Tan, J., Gandhi, R., and Narasimhan, P. 2010. An Analysis of Traces from a Production MapReduce Cluster. In Proceedings of the 2010 10th IEEE/ACM International Conference on Cluster, Cloud and Grid Computing (CCGRID '10). IEEE Computer Society, Washington, DC, USA, 94-103.
DOI=10.1109/CCGRID.2010.112
http://dx.doi.org/10.1109/CCGRID.2010.112
[10]Keahey, K., Tsugawa, M., Matsunaga, A., and Fortes, J. 2009. Sky Computing. IEEE Internet Computing 13, 5 (September 2009), 43-51. DOI=10.1109/MIC.2009.94 http://dx.doi.org/10.1109/MIC.2009.94
[11]Litzkow, M. J., Livny, M., Mutka, M. W. Condor - A Hunter of Idle Workstations. ICDCS 1988:104-111
[12]Morris, G. M., Huey, R., Lindstrom, W., Sanner, M. F., Belew, R. K., Goodsell, D. S. and Olson, A. J. (2009), AutoDock4 and AutoDockTools4: Automated docking with selective receptor flexibility. Journal of Computational Chemistry, 30: 2785–2791. doi: 10.1002/jcc.21256 [13]National Biomedical Computation Resource, http://nbcr.net [14]Qiu, J., Ekanayake, J., Gunarathne, T., Choi, J. Y., Bae, S.
H., Ruan, Y., Ekanayake, S., Wu, S., Beason, S., Fox, G., Rho, M., Tang, H., “Data Intensive Computing for Bioinformatics”, In Data Intensive Distributed Computing, IGI Publishers, 2010
[15]Staples, G. 2006. TORQUE resource manager. In Proceedings of the 2006 ACM/IEEE Conference on Supercomputing (SC '06). ACM, New York, NY, USA, Article 8. DOI=10.1145/1188455.1188464
http://doi.acm.org/10.1145/1188455.1188464 [16]Teragrid, http://www.teragrid.org
[17]Tsugawa, M., and Fortes, J. A. B. 2006. A virtual network (ViNe) architecture for grid computing. In Proceedings of the 20th International Conference on Parallel and Distributed Processing (IPDPS'06). IEEE Computer Society, Washington, DC, USA, 148-148.
[18]Vaqué, M., Arola, A., Aliagas, C., and Pujadas, G. 2006. BDT: an easy-to-use front-end application for automation of massive docking tasks and complex docking strategies with AutoDock. Bioinformatics 22, 14 (July 2006), 1803-1804. DOI=10.1093/bioinformatics/btl197
http://dx.doi.org/10.1093/bioinformatics/btl197 [19]Yang, H., Dasdan, A., Hsiao, R., and Parker, D. S. 2007.
Map-Reduce-Merge: Simplified Relational Data Processing on Large Clusters. In Proceedings of the 2007 ACM SIGMOD International Conference on Management of Data (SIGMOD '07). ACM, New York, NY, USA, 1029-1040. DOI=10.1145/1247480.1247602
http://doi.acm.org/10.1145/1247480.1247602
[20]Zaharia, M., Borthakur, D, Sarma, J. S., Elmeleegy, K., Shenker, S., and Stoica, I. Job Scheduling for Multi-User MapReduce Clusters, Technical Report UCB/EECS-2009-55, University of California at Berkeley, April 2009. [21]Zhang, C., De Sterck, H., "CloudBATCH: A Batch Job
Queuing System on Clouds with Hadoop and HBase," Cloud Computing Technology and Science, IEEE International Conference on, pp. 368-375, 2010 IEEE Second
International Conference on Cloud Computing Technology and Science, 2010