International Journal of Innovative Technology and Exploring Engineering (IJITEE) ISSN: 2278-3075, Volume-8 Issue-10, August 2019
Abstract: Paper Anti-malware software producers are persistently tested to recognize and counter new malware as it is discharged into nature. An emotional increment in malware generation as of late has rendered the ordinary technique for physically deciding a mark for each new malware test unsound. This paper introduces a versatile, mechanized methodology for identifying and arranging malware by utilizing design acknowledgment calculations and measurable techniques at different phases of the malware examination life cycle with Meta highlights. By utilizing a regular fragment examination, Mal-ID can dispose of malware parts that start from kindhearted code. What's more, Mal-ID uses another sort of highlight, named Meta-include, to more readily catch the properties of the dissected portions. In this paper, we introduce Ensemble Classifier technique to handle malware uncovering based on meta features. Our system consolidates the static highlights of capacity length and printable string data separated from malware tests into a solitary test which gives order results superior to those accomplished by utilizing either include independently. In our testing, we information includes data from near 1400 unloaded malware tests to various diverse grouping calculations. Utilizing k-overlap cross approval on the malware, which incorporates Trojans and infections, alongside 151 clean records, we accomplish a general characterization exactness of over 98%.
Keywords : Malware detection, classifier, security, Ensemble learning, meta-feature classification and communication infrastructure.
I. INTRODUCTION
Android has turned into the main versatile working framework with a generously higher level of the worldwide piece of the pie. More than a billion Android gadgets sold out and 76 billion applications download are expected to come from Google Play alone. The development of Android's notoriety and the expansion of external application markets have also made it a well-known malware hub. A year ago, McAfee announced that there were more than 12 million malware tests on Android, with about 2.5 million new samples found every 4 months. Android malware can be inserted in an assortment of uses, for example, banking applications, gaming applications, the way of life applications, instructive applications, and so on. These
Revised Manuscript Received on August 05, 2019
Chandra Sekhar Vasamasetty, Department of CSE, SRKR Engineering College, Bhimavaram, India.
Siva Sankar Chandu, Department of CSE, SRKR Engineering College, Bhimavaram, India.
Janakidevi Maddala, Department of CSE, SRKR Engineering College, Bhimavaram, India,
malware-tainted applications would then be able to bargain security and protection by enabling unapproved access to protect delicate data, establishing gadgets, transforming gadgets into remotely controlled robots, and so on. Android zero day malware can bypass the usual trademark-based warranties. Consequently, there is a dire need to grow progressively successful recognition strategies. As of late, Artificial Intelligence (AI)-based techniques are progressively being connected to Android malware location. In any case, classifier combination methodologies have not been widely investigated as they have been in different spaces like system interruption identification. Recognition has known malware is regularly performed by against infection apparatuses. These instruments identify the known malware utilizing mark location techniques. At the point when another malware is discharged, the counter infection sellers need to get an occurrence of the new malware, break down it, make another mark and they update their clients. Between the presence of other obscure malware and the updating of the brand database of clients opposed to infection, many PCs are defenseless against new malware. In this way, in spite of the fact that signature-based recognition techniques, in the long run, yield high location rate, they can't adapt to new, inconspicuous previously, malware. Fast correspondence channels empower malware to proliferate and taint has rapidly thus it is fundamental to distinguish and take out new (obscure) spreading malware at beginning periods of the assault. Ongoing investigations have proposed strategies for identifying malignant executables utilizing Machine Learning (ML) methods. From a prepared set of two pernicious and lovable executable codes, a classifier is willing to recognize and characterize an obscure vindictive executable as malicious. Part of the strategy is propelled by content order procedures, in which words are very similar to double-code groups. Harmful and considerate records are processed by a vector of strong points, separated from the PE header and the matched code of the executable. These records are utilized to prepare a classifier. In the middle of the recognition phase, in light of the classifier's speculation capabilities, an obscure document may be delegated vindictive or in-kind. The result of this perception is that one should utilize various classifiers that will arrange another case foreseeing its genuine class (like a gathering of specialists) and afterward joining every one of the outcomes, utilizing a wise blend strategy, into one last outcome. Ideally, this "super classifier" will defeat each of the individual classifiers and will group new occurrences with increased accuracy by learning the quality
and flaws of each classifier.
Meta-Feature Classification to Explore
Automatic Detection of Malware Using
Segmentation Method
In this paper we present three principle commitments: (1) we demonstrate that multi-inducer gatherings are competent to recognize malware; (2) we present an inventive joining strategy, called Troika which broadens Stacking and show its predominance in the malware discovery errands; and (3) we present observational outcomes from a broad genuine investigation of different malware utilizing various sorts of highlights.
II. REVIEWOFLITERATURE
In this section, we describe different authors opinion regarding detection of malware relates to android and prefer training features. There are some pros and cons of resource management in static and dynamic methods.
Late Android malware identification work that utilizes AI with static highlights incorporate the accompanying. DroidMat [11] propose to apply nearest k-means and k-closest neighbor (k-NN) calculations dependent on steadfast highlights derived from authorizations, plans, and API Calls (Application Program Interface), to group applications as amiable or malicious program. Arp et al. [4] The proposed SVM is dependent on authorizations, API calls, organize get to, and so forth for lightweight on-gadget discovery.
Yerima et al. [12], [14] have proposed an eigenspace investigation an approach, just as arbitrary woodland group learning models. In documents, the Artificial Intelligence (AI) based search API relies on calls, purpose, consent and established instructions. Varsha et al. [15] examined SVM, irregular woodland, and turn timberlands on three datasets; their discovery strategy utilized separate static highlights separated from the show and application performance records. Sharma and Dash [16] used API calls and authorizations to assemble innocent Bayes and k-NN identification frameworks. In [17], API classes were utilized along arbitrary backwoods, J48, and SVM classifiers. Wang et al. [18] assessed the value of hazardous consents for malware recognition utilizing SVM, choice trees, and irregular woodland. DAPASA [19] concentrates on identifying malware related to benevolent applications using complex sub-graphs to create five strong points illustrating invocation designs. The highlights are encouraged into AI calculations, i.e., arbitrary woodland, choice tree, k-NN and PART provide the best recognition with irregular timber.
Cen et al. [20] proposed a discovery technique dependent on API calls of decomposed codes as well as authorities. The proposed strategy applies a probabilistic discriminative model dependent on the Regularized calculated relapse (RLR). RLR contrasts through SVM, the tree of choice, k-NN and the innocent Bayes with earlier data as well as a varied mix of innocent Bayes. A few scientists inspected the materialness of outfit techniques in recognizing the malevolent code. Zhang et. al., (2007) orders a new vindictive code dependent on the n-gram highlights extricated from the double code of the record. To start with, strengths based on n-grams are excerpted and the best n-grams are exclusive by utilizing the technique of choice Information-Gain includes. At that point, the PNN (Probabilistic Neural Network) is utilized to build a few classifiers for recognition. At long last, the PNN classifier is
consolidated using the Dempster-Shafer hypothesis to establish the rules for incorporating lone options. The strategy has been assessed on many pernicious executions
downloaded from VX Heavens site
(http://www.vx.netlux.org) and on own projects accumulated of a Windows 2000 server machine: all 423 benevolent programs and 450 malicious files (150 viruses, 150 Trojan horses and 150 worms) all in Windows PE position. The results demonstrate a superior ROC curve for PNN collection versus the best individual PNN for each of the three classes of malware. In this examination, we examine some techniques for consolidating different classifiers to determine which of these strategies (assuming they are) best improves the accuracy of the discovery.
III. GENERALFRAMEWORKFORDROID
FUSIONDETECTION
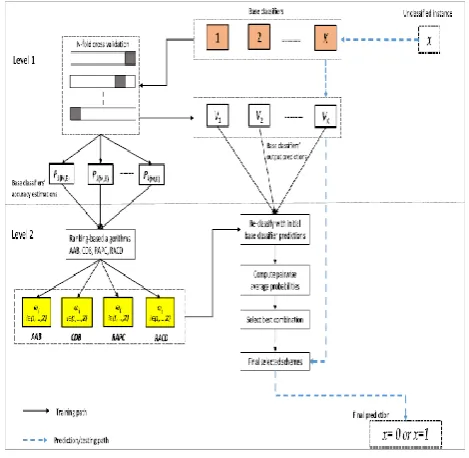
[image:2.595.322.557.430.659.2]The Droid-Fusion system includes a staggered design for the classifier combination. It is planned like a general reason classifier combination framework; with the goal that it tends to be connected to both conventional solitary classifiers and outfit classifiers (which themselves utilize a base classifier more often than not to deliver diverse haphazardly prompted models that are in this manner joined). At the bottom level, the basic classifiers (Droid-Fusion) are prepared on a pre-set using an N-overlapping stratified cross-approval strategy to evaluate their approximate relative accuracy. The results are used by four distinctive positioning-based calculations (in the upper layer) that characterize some of the selection criteria and the resulting meld of a subdivision (or all) of the appropriate basic classifiers.
Figure 1 Droid-fusion layered architectural implementation.
The results of the positioning, calculations are consolidated two by two to locate the most grounded pair, which is consequently used to construct the last Droid-Fusion model (following tests performed on an unweighted parallel mix of basic classifiers).
International Journal of Innovative Technology and Exploring Engineering (IJITEE) ISSN: 2278-3075, Volume-8 Issue-10, August 2019
The structure of the model, i.e., the preparation procedure is particular from the forecast or test phase, as the previous one uses a set of preparation approvals to build an amazing holding classifier that is then assessed on a test data set different from the last step. Fig. 1 outlines the two-level design of Droid-Fusion. It demonstrates the preparation ways (strong bolts) and the testing/expectation way (dashed bolts). To start with, at the bottom level, each basic classifier experiences an N-crease cross-approval based gauge of class execution exactnesses. Give the N-a chance to crease cross-approved prescient exactnesses for K basic classifiers are communicated by if you don't mind a K-tuple of the class correctness of K basic classifiers.
1 1 2 2
{[
,
],[
,
],...,[
,
]}
base m b m b km kb
P
P
P
P
P
P
P
Elements of Phase describe rank based algorithm descriptions to increase the accuracy in detection of malware droid-fusion in android related applications.
IV. DETECTIONOFMALWAREUSING
COMBINEDENSEMBLEAPPROACH
A not labeled example is classified with the highest vote (most incessant votes) by class. This strategy is otherwise called the PV (Plurality vote) or the BEM (basic ensemble method). This methodology has often been used as a consolidation strategy to contrast with recently proposed strategies. Scientifically it very well may be composed as:
( )
( )
arg max
(
( ), )
ik i
c dom y k
class x
g y x c
Where
y x
k( )
is kith classification factor g(y,c) function indicated and defined as1,
( , )
0,
y
c
g y c
y
c
Crisp classification based on probabilistic classification usually defined as
( )
( )
arg max
|
i
k Mk i
c dom y
y x
P
y
c x
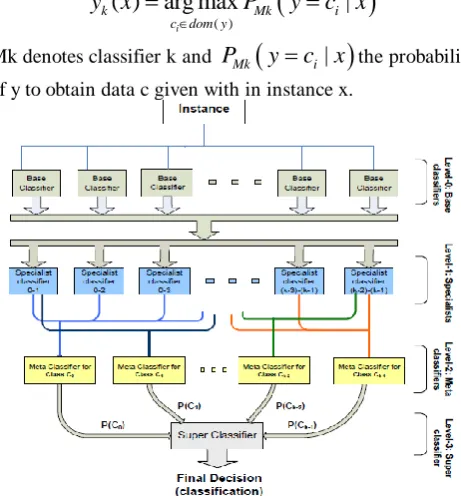
[image:3.595.52.283.510.758.2]Mk denotes classifier k and
P
Mk
y
c x
i|
the probability of y to obtain data c given with in instance x.Figure 2. Meta classifier description with different levels of data representation.
Performance weigh classification proportional to the performance of validation set
1
(1
)
(1
)
ii t
i j
E
E
Where EI is a standardization aspect that depends on the presentation assessment of classifier I on an approval set. Distribution Summation consolidation technique can sum the contingent likelihood vector acquired of each classifier; the chosen class was chosen by the most surprising incentive of the all-around vector. Scientifically, it tends to be composed as:
( )
( )
arg max
(
| )
i
k Mk i
c dom y k
y x
P
y
c x
At the Bayesian Combination method, the predecessor of the classifier given to the set to learn weight associated with each classifier
( )
( )
arg max
(
| ).
(
| )
iM i
c dom y k
Class x
P Mk S P
y
c x
This classifier (meta-classifier) groups the distinct expectations in the last presented in Figure 2. It is suggested to divide the first set of data into two sub-sets. The first sub-set is saved to shape the meta-dataset and the second sub-set is utilized to assemble the base-level classifiers. Subsequently, the meta-classifier's forecasts reflect the true execution of the learning calculations at the base-level. Stacking execution can be improved using a base-class classifier using yield possibilities for each class's name. It antiquated appearing with stacking the troupe performs, similar to choosing the best classifier of the troupe by cross approval.
V. EXPERIMENTALEVALUTION
Consequently, choosing 100 and 9 for arbitrary tree-100 as well as irregular tree-9, individually, leads to two distinctive base classifier models. Irregular tree, REPTree, J48, and cast a ballot perception were chosen as model base classifiers (on 12 base classifiers) as a result of their joined precision and preparing time execution as decided from starter examination; an alternate arrangement of learning calculations can be utilized with Droid-Fusion since it
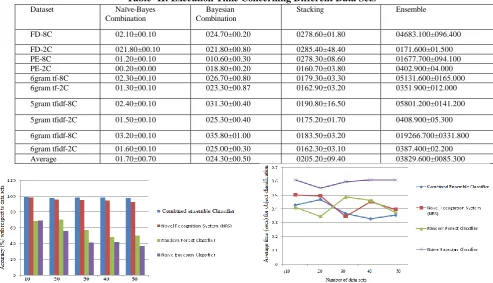
[image:4.595.60.547.170.341.2]intended to be universally useful, and not explicit to a specific sort of Artificial Intelligence (AI) calculation. Comparing approaches with different features concerning accuracy in real time data sets shown in table I. Comparison of the execution time of the combined classifier approach with different data sets in the detection of malware shown in table II.
Table- I: Accuracy Of Combined Ensemble Classifier In Real-Time Data Sets
Dataset Naïve-Bayes Combination
Bayesian Combination
Stacking Troika Ensemble B.C Name FD-8C 012.4±1.4 081.7±0.7 081.2±1.1 082.2±0.8 079.8±0.8 C4.5
FD-2C 078.6±1.2 084.5±0.9 085.8±1.0 083.7±0.9 084.6±1.0 C4.5 PE-8C 079.3±1.6 090.5±1.5 090.8±1.5 091.5±1.3 091.8±1.4 KNN PE-2C 094.8±0.7 094.8±0.6 095.9±0.7 096.3±0.6 096.1±0.5 KNN 6gram tf-8C 042.1±1.4 083.1±0.8 083.0±1.0 083.4±1.0 083.4±1.0 KNN 6gram tf-2C 067.1±1.5 091.3±0.8 093.2±0.8 093.3±0.7 093.2±0.7 KNN 5gram tfidf-8C 036.0±1.5 083.8±0.8 083.4±0.9 084.1±0.9 084.1±0.9 KNN
5gram tfidf-2C 064.2±1.3 093.9±0.8 094.0±0.8 094.1±0.7 094.0±0.8 KNN
[image:4.595.51.545.361.644.2]6gram tfidf-8C 059.8±1.3 083.1±0.9 082.2±1.0 083.0±0.9 083.0±0.9 KNN 6gram tfidf-2C 053.4±1.9 094.6±0.6 094.5±0.6 094.5±0.6 094.5±0.6 KNN Average 053.4±1.2 088.1±0.8 089.2±0.9 089.3±0.8 088.4±0.9
Table- II: Execution Time Concerning Different Data Sets
Dataset Naïve-Bayes Combination
Bayesian Combination
Stacking Ensemble
FD-8C 02.10±00.10 024.70±00.20 0278.60±01.80 04683.100±096.400 FD-2C 021.80±00.10 021.80±00.80 0285.40±48.40 0171.600±01.500 PE-8C 01.20±00.10 010.60±00.30 0278.30±08.60 01677.700±094.100 PE-2C 00.20±00.00 018.80±00.20 0160.70±03.80 0402.900±04.000 6gram tf-8C 02.30±00.10 026.70±00.80 0179.30±03.30 05131.600±0165.000 6gram tf-2C 01.30±00.10 023.30±00.87 0162.90±03.20 0351.900±012.000
5gram tfidf-8C 02.40±00.10 031.30±00.40 0190.80±16.50 05801.200±0141.200
5gram tfidf-2C 01.50±00.10 025.30±00.40 0175.20±01.70 0408.900±05.300
6gram tfidf-8C 03.20±00.10 035.80±01.00 0183.50±03.20 019266.700±0331.800 6gram tfidf-2C 01.60±00.10 025.00±00.30 0162.30±03.10 0387.400±02.200 Average 01.70±00.70 024.30±00.50 0205.20±09.40 03829.600±0085.300
Figure 3 Accuracy with respect to different attributes in real time data sets
Figure 4 Performance evaluation of average execution time with respect to different data sets
International Journal of Innovative Technology and Exploring Engineering (IJITEE) ISSN: 2278-3075, Volume-8 Issue-10, August 2019
VI. CONCLUSION
In this paper, we present and examined the ensemble Meta classifier in selecting security domain aspects. The main aspect of the proposed Meta classifier is to identify malware identification in android related micro-soft applications based on real-time applications. This classifier exploits efficient accuracy in detection of malware using Troika and naïve bay’s classification with different data sets. We can likewise observe that the Naïve-Bayes troupe technique simple remarkable for its quick execution time which is equivalent to all the weighting techniques. This is the exactness and AUC are genuinely awful contrasting with every single other group. One clarification to its poor execution is the way that its suspicions are most likely not occurring; for the model, the supposition of autonomous base-classifier does not exist in practice .Further improvement of the proposed approach to define different features with different training data sets.
REFERENCES
1. Suleiman Y. Yerima, “DroidFusion: A Novel Multilevel Classifier Fusion Approach for Android Malware Detection”, IEEE TRANSACTIONS ON CYBERNETICS,2168-2267 c 2018 IEEE. Personal use is permitted, but republication/redistribution requires IEEE
permission. See
http://www.ieee.org/publications_standards/publications/rights/index.ht ml for more information.
2. McAfee Labs Threat Predictions Report, McAfee Labs, Santa Clara, CA, USA, Mar. 2016.
3. Y. Zhou and X. Jiang, “Dissecting Android malware: Characterization and evolution,” in Proc. IEEE Symp. Security Privacy (SP), San Francisco, CA, USA, May 2012, pp. 95–109.
4. D. Arp, M. Spreitzenbarth, M. Hubner, H. Gascon, and K. Rieck, “Drebin: Efficient and explainable detection of Android malware in your pocket,” in Proc. 20th Annu. Netw. Distrib. Syst. Security Symp. (NDSS), San Diego, CA, USA, Feb. 2014, pp. 1–15.
5. A. Apvrille and R. Nigam. (Jul. 2014). Obfuscation in Android Malware and How to Fight Back Virus Bulletin. Accessed: Sep. 2017. [Online]. Available:
https://www.virusbulletin.com/virusbulletin/2014/07/obfuscation-androi d-malware-and-how-fight-back
6. Y. Jing, Z. Zhao, G.-J. Ahn, and H. Hu, “Morpheus: Automatically generating heuristics to detect Android emulators,” in Proc. 30th Annu. Comput. Security Appl. Conf. (ACSAC), New Orleans, LA, USA, Dec. 2014, pp. 216–225.
7. T. Vidas and N. Christin, “Evading Android runtime analysis via sandbox detection,” in Proc. 9th ACM Symp. Inf. Comput. Commun. Security, Kyoto, Japan, Jun. 2014, pp. 447–458.
8. T. Petsas, G. Voyatzis, E. Athanasopoulos, M. Polychronakis, and S. Ioannidis, “Rage against the virtual machine: Hindering dynamic analysis of Android malware,” in Proc. 7th Eur. Workshop Syst. Security (EuroSec), Amsterdam, The Netherlands, Apr. 2014, p. 5.
9. F. Matenaar and P. Schulz. (Aug. 2012). Detecting Android Sandboxes. Accessed: Nov. 2017. [Online]. Available: ttp://www.dexlabs.org/blog/btdetect
10.S. R. Choudhary, A. Gorla, and A. Orso, “Automated test input generation for Android: Are we there yet?” in Proc. 30th IEEE/ACM Int. Conf. Autom. Softw. Eng. (ASE), Nov. 2015, pp. 429–440.
11.D.-J. Wu, C.-H. Mao, T.-E. Wei, H.-M. Lee, and K.-P. Wu, “DroidMat: Android malware detection through manifest and API calls tracing,” in Proc. 7th Asia Joint Conf. Inf. Security (Asia JCIS), 2012, pp. 62–69. 12.S. Y. Yerima, S. Sezer, and I. Muttik, “Android malware detection: An
eigenspace analysis approach,” in Proc. Sci. Inf. Conf. (SAI), London, U.K., Jul. 2015, pp. 1236–1242.
13.S. Y. Yerima, S. Sezer, and I. Muttik, “Android malware detection using parallel machine learning classifiers,” in Proc. 8th Int. Conf. Next Gener. Mobile Apps Services Technol. (NGMAST), Oxford, U.K., Sep. 2014, pp. 37–42
14.S. Y. Yerima, S. Sezer, and I. Muttik, “High accuracy Android malware detection using ensemble learning,” IET Inf. Security, vol. 9, no. 6, pp. 313–320, Nov. 2015.
15.Kelly, C., Spears, D., Karlsson, C., and Polyakov, P., 2006. An Ensemble of Anomaly Classifiers for Identifying Cyber Attacks. Proc. of the International SIAM Workshop on Feature Selection for Data Mining. 16.Kibler, D. A., 1991. Instance-based learning algorithms. Machine
Learning, pp. 37-66.
17.Kienzle, D.M., and Elder, M.C., 2003. Internet WORMS: past, present, and future: Recent worms: a survey and trends. ACM workshop on Rapid malcode (WORM03).
18.Kittler, J., Hatef, M., Duin, R., and Matas, J., 1998. On Combining Classifiers. IEEE Transactions on Pattern Analysis and Machine Intelligence, 20(3) 226-239.
19.Kolter, J., Maloof, M., 2006. Learning to Detect and Classify Malicious Executables in the Wild. Journal of Machine Learning Research, vol. 7, pp. 2721-2744.
20.Kuncheva L.I., 2005. Diversity in Multiple Classifier Systems (Editorial), Information Fusion, 6 (1) 3-4.
21.Mahoney, M.V., 2003 A machine learning approach to detecting attacks by identifying anomalies in network traffic. Ph.D. dissertation, Florida Tech.
22.Menahem, E., 2008. Troika - An Improved Stacking Schema for Classification Tasks. MSc. Thesis in Information System Engineering dep., Ben-Gurion University of the Negev,Israel.
23.Mitchell, T., 1997. Machine Learning. McGraw-Hill.
24.Moskovitch, R., Elovici,Y., and Rokach, L., 2008. Detection of Unknown Computer Worms based on Behavioral Classification of the Host. Computational Statistics and Data Analysis, 52(9) 4544-4566. 25.Mukkamalaa, S., Sunga A.H., and Abrahamb, A., 2005. Intrusion
Detection Using an Ensemble of Intelligent Paradigms. Journal of Network and Computer Applications, vol. 28, pp. 167-182.
26.Opitz D. and Shavlik, J., 1996. Generating Accurate and Diverse Members of a Neural Network Ensemble. Advances in Neural Information Processing Systems, vol. 8, pp. 535-541.
27.Quinlan, R., 1993. C4.5: Programs for Machine Learning. Morgan Kaufmann Publishers.
28.Schultz, M., Eskin, E., Zadok, E., and Stolfo, S., 2001. Data Mining Methods for Detection of New Malicious Executables. Proc. of the IEEE Symposium on Security and Privacy, pp. 178-184.
AUTHORSPROFILE
Dr.Chandra Sekhar VasamsettyAssociate Professor in Computer Science and Engineering, SRKR Engineering
College, Bhimavaram. He awarded Ph.D.,in Computer
Science and Systems Engineerring from Andhra
University, Visakhapatnam, AP, India in 2014
Siva Sankar Chandu completed B.Tech in Computer Science and Engineering in VKR, VNB and AGK Engineering College, India. He is currently pursuing M.Tech in Computer Science and Engineering from Jawaharlal Nehru Technological University Kakinada, India.
.
Janakidevi Maddala Assistant Professor in Computer Science and Engineering, SRKR Engineering College,
Bhimavaram. She completed M.Tech in Shri Vishnu