International Journal of Innovative Technology and Exploring Engineering (IJITEE) ISSN: 2278-3075, Volume-8 Issue-11, September 2019
Feature-Based Opinion Mining for Amazon
Product’s using MLT
Siva Kumar Pathuri, ViswaGanesh.A, Ravi Teja.P, V.Rishi Chowdary
Abstract:analysis of sentiment’s or opinion mining is one of the major challenge of NLP (natural language processing) .Business Analytics plays a major role in the present scenario with a view to improve their business. These human beings especially relies upon on reviews about their product to resist in the marketplace and information analytics which can give us an excellent insight on what to expect in the future. Opinions can be referred to, with which futures opinions can be expected. Few words or terms can determine outcomes or results. As maximum of these business people try to improve their business to get maximum profit by selling quality products .So, in this regard sentiment analysis has gain a whole lot attention in current years.SA is an area of study within NLP which is used in identifying the view or opinion of a particular feature inside a content i.e., text. This paper is based on the different techniques used to classify a specified text according to the views expressed in it, i.e. whether a person's overall mentality is negative or positive or neutral. We also examine the two-advance methods (feature classification followed by polarity classification) followed along with the experimental results. Finally in this paper we compared 3 ML classification techniques 1) SVM, 2) Naïve Bayes (NB) 3) Logistic Regression with Hybrid Algorithm in which hybrid algorithm gives more accuracy when compared with the other 3 ML algorithms.
Keywords: Sentiment analysis, Sentiment polarity categorization, Natural language Processing, Opinion mining, Feature based sentiment analysis.
I. INTRODUCTION:
Social websites such as Twitter, Facebook and Blogs, LinkedIn, etc. have become an significant forum for people to communicate their valuable opinions on some subjects. Various opportunities and challenging circumstances have been lifted with such platforms to effectively employ multiple approaches to draw and acknowledge the opinions of others. The internet social web documents
feedback assessment has a variety of uses like customer reviews for film, brand, facilities and alertness. The tweet SA is the favorable or bad or neutral classification of tweets. Sentiment analysis relying on Lexicon related to the appearance in reports of favorable words. Lexicon has distinguishing characteristics including voice tagging, emotion values, sentence subjectivity and many others. The Tweet Sentiment analysis notes the use of these characteristics given by these lexicons. The use of this is enabled by averaging the emotions of phrases to achieve maximum polarity of tweet the machine learning method of sentiment analysis n3eeds the classification to be developed with marked instances through practice.
Revised Manuscript Received on Jul 17, 2019.
Siva Kumar Pathuri, Associate prof in the Dept of CSE at KLEF Vaddeswaram, Guntur.
ViswaGanesh.Alapati, Scholar UG,Dept Of
CompterScience&Engineering,K L University,Vaddeswaram,Guntur Ponnekanti. Ravi Teja, Scholar UG, Dept Of
CompterScience&Engineering,K L University,Vaddeswaram,Guntur
This requires first collecting a data set with positive, negative and neutral capacities and extracting the sentences from this data set, then teaching the rule selection based on instances that is one of the most prevalent on social networking sites [4]. Sometimes individuals publish a tweeting activity online on social websites. Tweets are dynamic and precious as a result of the number of internet social websites [7]. As a result, social pages are one of the most valuable places for opinions on all topics. This enables computer scientists to assess their emotions and expand the routes to mining facts. These data may be used in marketing, sales or polling assessments. Comments can be collected in a timely fashion by comparing human email social sites on the Internet [1, 2, and 3]. In order to build unsourced public opinion polls on important social subjects, scientists can use the information sets [1]. Twitter and Facebook and other social websites have become a powerful instrument for the public to engage in politics, the media and businesses.
However, it could be classified as neutral or not by a classifier using a fully lexicon-based technique. Although these sentences can be described, but it is hard to categorize [2] due to a steady exchange of their use. The mechanism to interpret the technique used for assessing feelings [4, 8].This procedure enables the classifier to decide positives and negative and neutral emotions in the phrases and documents classified by training [4, 8]. In addition, every other categorization has been supplied [6] with the categories of statistical, knowledge-primarily based and hybrid methods. There may be an area for putting out hard research in comprehensive areas through computational analysis of views and feelings [7]. Therefore, a slow practice has risen to obtain the data accessible on social networks for predicting an election, applying for academic tasks, or for company, discussion, and advertising areas. The precision of sentiment analysis and predictions can be obtained through behavioral analysis based on social networks [8]. Opinion Lexicon [10] has become used to discover a complete amount of huge, neutral and bad tweets. This dataset is analyzed to understand algorithms with both monitored and unsupervised system-getting. Using the Rainbow tool [1], it applied Prind, K nearest neighbors (KNN) [1], and Naïve Bayes. Current surveys have screened that internet social sites are capable of obtaining the perception of humans from their profiles as compared to traditional methods of acquiring opinion statistics. In addition, writers of [2] suggested an algorithm to exploit emotions from tweets while thinking about a big scale of documents for evaluating emotions.
Given a collection of reviews with feature terms identified, we might prefer to accurately estimate the sentiment of every incidence of a feature term in a sentence. With one aspect per sentence, an assumption are often created that polarity among the sentence is associated with the polarity of the feature. Once multiple feature terms are present in one sentence, words related to one feature term might incorrectly be associated with another feature term, inflicting the polarities of every feature term among the sentence to aspect of another. An issue with using aspect terms one by one is that often, multiple aspect terms can confer with the identical of comparable aspects. For instance, "Best" and
"Excellent" refer to the
identical aspect, nonetheless are thought-aboutseparate aspect terms.
This implies that how to categorize aspect terms is challenging one planning a system to accurately rate important aspects of a review's subject. As such, we are going to concentrate on accurately distinguishing the sentiment of instances of aspect terms, instead of
aggregating these
terms to supply a lot of accurate view of a more general “aspect category".
Research methodology:
This paper predicts the star rating given to a feedback from a product consumer. We will also use features like effectiveness to enhance our prediction. In this document we consider that messages about a particular feature and judge whether it is positive, negative or neutral. To do this, the evaluation of text and phrase levels involves systems: (1)
Hybrid Algorithm; (2) Support Vector Machinery (SVM). (3) Naive Bayes (NB) (4) Logistic regression, etc... This includes classifying algorithms [7]. In this paper we use a combination of the two methods, also called as hybrid method. Typically, combinations are used for the assessment of subjectivity and then for the learning algorithm [8]. Similar strategy used in [9], which classifies the phrase in only two positive & negative categories, no neutral category generates an issue. 10] But they use distinct techniques of analyzing feelings. But these are different from our approach, we first preprocess the data to remove unwanted data from it. Then we use Lexicon dictionary for polarity identification and then use the Learning algorithm to implement this outcome. In order to determine whether a phrase is positive, negative or neutral, we follow different methods. For sentence level SA, VADER Sentiment Analysis is a favorable, for overall rating of the sentence whether it is positive negative or neutral.
II. VADER SENTIMENT ANALYSIS
VADER (Valence Aware Dictionary and Sentiment Reasoner) is a lexicon-based sentiment analysis method geared specifically to the feelings conveyed in social media. VADER utilizes a blend of feeling lexicon as a list of lexical features (e.g., sentences) usually labeled as either positive or negative according to their conceptual meaning.VADER has been discovered to be quite effective in coping with social media textbooks, NY Times editorials, film reviews, and item reviews, because VADER not only informs us about the Positivity and Negativity rating, but also informs us how positive or negative a feeling is.
International Journal of Innovative Technology and Exploring Engineering (IJITEE) ISSN: 2278-3075, Volume-8 Issue-11, September 2019
Hybrid Approach:
The hybrid model incorporates rules-based, lexicon-based, and machine learning approaches into a unified scheme that uses the powerful fields of individual classifiers while concurrently attempting to prevent their weaknesses. Classifiers relying on rules and Lexicon have elevated accuracy but poor recall. They therefore function as the original two phases of the hybrid system.The prosed algorithm is a rule-based model for performing sentiment analysis on a per-sentence basis. The system was
trained on on- line media text, a number
of including product reviews utilizes a sentiment lexicon created with the aim of being generalizable to multiple aspect-based Sentiment Analysis domains. This makes the hybrid algorithm significantly appropriate for analyzing on-line review information. In addition, by
classifying on a per-sentence basis
and performing unsupervised, this algorithm can simply be applied and tested on newly-seen information and data across domains. Their sentiment lexicon was based on many existing sentiment lexicons, as well as common emoticons and acronyms. It includes valence scores (between (1 and 5) that contain data concerning sentiment intensity (how powerfully a word expresses a sentiment) additionally to sentiment polarity using VADER algorithm for generating polarity. Given a sentence, VADER algorithm calculates a polarity score to measure the sentiment intensity and polarity. 6 major heuristics are used to confirm the valence score of a given sentence.
Most popular words in summary feature III. EXPERIMENTAL RESULTS
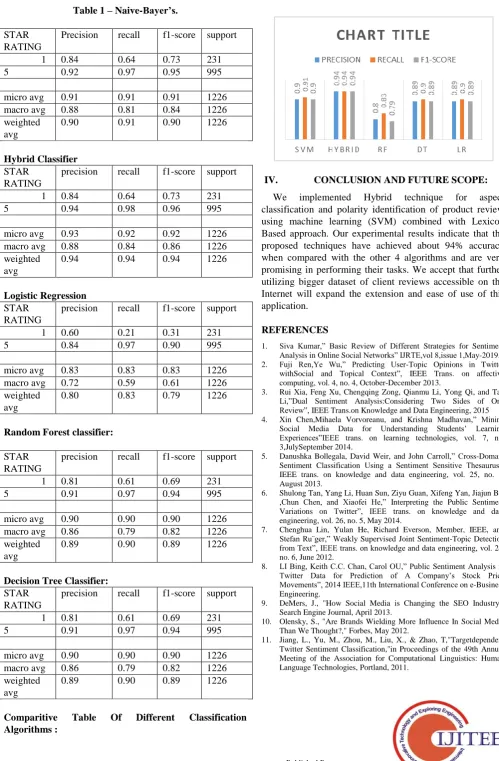
For Evaluations we perform the sentiment analysis using Hybrid approach. And compare the results obtained by other algorithms like Naïve Bayes, SVM etc.
Evaluation Process:
We use measure Accuracy to evaluate the sentiment classification performance. This measure can be check against classification features such as Unigram, Bigram and Trigram with different training size.
Table 1 – Naive-Bayer’s.
STAR RATING
Precision recall f1-score support
1 0.84 0.64 0.73 231
5 0.92 0.97 0.95 995
micro avg 0.91 0.91 0.91 1226
macro avg 0.88 0.81 0.84 1226
weighted avg
0.90 0.91 0.90 1226
Hybrid Classifier STAR
RATING
precision recall f1-score support
1 0.84 0.64 0.73 231
5 0.94 0.98 0.96 995
micro avg 0.93 0.92 0.92 1226
macro avg 0.88 0.84 0.86 1226
weighted avg
0.94 0.94 0.94 1226
Logistic Regression STAR
RATING
precision recall f1-score support
1 0.60 0.21 0.31 231
5 0.84 0.97 0.90 995
micro avg 0.83 0.83 0.83 1226
macro avg 0.72 0.59 0.61 1226
weighted avg
0.80 0.83 0.79 1226
Random Forest classifier: STAR
RATING
precision recall f1-score support
1 0.81 0.61 0.69 231
5 0.91 0.97 0.94 995
micro avg 0.90 0.90 0.90 1226
macro avg 0.86 0.79 0.82 1226
weighted avg
0.89 0.90 0.89 1226
Decision Tree Classifier: STAR
RATING
precision recall f1-score support
1 0.81 0.61 0.69 231
5 0.91 0.97 0.94 995
micro avg 0.90 0.90 0.90 1226
macro avg 0.86 0.79 0.82 1226
weighted avg
0.89 0.90 0.89 1226
Comparitive Table Of Different Classification Algorithms :
IV. CONCLUSION AND FUTURE SCOPE:
We implemented Hybrid technique for aspect classification and polarity identification of product review using machine learning (SVM) combined with Lexicon Based approach. Our experimental results indicate that the proposed techniques have achieved about 94% accuracy when compared with the other 4 algorithms and are very promising in performing their tasks. We accept that further utilizing bigger dataset of client reviews accessible on the Internet will expand the extension and ease of use of this application.
REFERENCES
1. Siva Kumar,” Basic Review of Different Strategies for Sentiment Analysis in Online Social Networks” IJRTE,vol 8,issue 1,May-2019. 2. Fuji Ren,Ye Wu,” Predicting User-Topic Opinions in Twitter
withSocial and Topical Context”, IEEE Trans. on affective computing, vol. 4, no. 4, October-December 2013.
3. Rui Xia, Feng Xu, Chengqing Zong, Qianmu Li, Yong Qi, and Tao Li,”Dual Sentiment Analysis:Considering Two Sides of One Review”, IEEE Trans.on Knowledge and Data Engineering, 2015 4. Xin Chen,Mihaela Vorvoreanu, and Krishna Madhavan,” Mining
Social Media Data for Understanding Students’ Learning Experiences”IEEE trans. on learning technologies, vol. 7, no. 3,JulySeptember 2014.
5. Danushka Bollegala, David Weir, and John Carroll,” Cross-Domain Sentiment Classification Using a Sentiment Sensitive Thesaurus”, IEEE trans. on knowledge and data engineering, vol. 25, no. 8, August 2013.
6. Shulong Tan, Yang Li, Huan Sun, Ziyu Guan, Xifeng Yan, Jiajun Bu, ,Chun Chen, and Xiaofei He,” Interpreting the Public Sentiment Variations on Twitter”, IEEE trans. on knowledge and data engineering, vol. 26, no. 5, May 2014.
7. Chenghua Lin, Yulan He, Richard Everson, Member, IEEE, and Stefan Ru¨ger,” Weakly Supervised Joint Sentiment-Topic Detection from Text”, IEEE trans. on knowledge and data engineering, vol. 24, no. 6, June 2012.
8. LI Bing, Keith C.C. Chan, Carol OU,” Public Sentiment Analysis in Twitter Data for Prediction of A Company’s Stock Price Movements”, 2014 IEEE,11th International Conference on e-Business Engineering.
9. DeMers, J., "How Social Media is Changing the SEO Industry," Search Engine Journal, April 2013.
10. Olensky, S., "Are Brands Wielding More Influence In Social Media Than We Thought?," Forbes, May 2012.
International Journal of Innovative Technology and Exploring Engineering (IJITEE) ISSN: 2278-3075, Volume-8 Issue-11, September 2019
Author-1 Photo
Author-1 Photo
uthor-1 Photo
Author-1 Photo
12. Bhuta, S., Doshi, A., Doshi, U., & Narvekar, M,"A Review of Techniques for Sentiment Analysis of
13. Twitter Data," in Issues and Challenges in Intelligent Computing Techniques (ICICT), 2014.
14. Yu, H., & Kim, S., "SVM
15. Tutorial—Classification, Regression and Ranking.,"Springer Berlin Heidelberg in Handbook of Natural Computing, 2012.
16. Saif, H., He, Y., & Alani, H, "Alleviating Data Sparsity for Twitter Sentiment Analysis," in CEUR Workshop Proceedings (CEUR-WS. org), Lyon,France., 2012.
17. Sagar Bhuta, Avit Doshi, Uehit Doshi, Meera Narvekar : “A Review of Techniques for Sentiment Analysis “ , International Conference on Issues and Challenges in Intelligent Computing Techniques (ICICT) , 978-1-4799- 2900-9/14 2014 IEEE.
18. Alvaro Ortigosa , José M. Martín, Rosa M. Carro: “Sentiment analysis in Facebook and its application to e- learning”, Elsevier Journal of Computers in Human Behavior 31 (2014), Published by Elsevier Ltd.
19. Zohreh Madhoushi, Zohreh Madhoushi, Suhaila Zainudin: “Sentiment Analysis Techniques in Recent Works” Science and Information Conference 2015 July 28-30, 2015 - London, UK.
20. Valentina Mazzonello, Salvatore Gaglio, Agnese Augello, Giovanni Pilato: “A Study on Classification Methods Applied to Sentiment Analysis “, 2013 IEEE Seventh International Conference on Semantic Computing,978-0-7695-5119-7/19 DOI 10.1109/ICSC.2013.82 21. Shreya Banker, Rupal Patel: “A brief review of sentiment analysis
methods”, International Journal of Information Sciences and
Techniques (IJIST) Vol.6,No.1/2, March 2016. DOI :
10.5121/ijist.2016.621089
22. Ms Kranti Ghag and Dr. Ketan Shah: “Comparative Analysis of the Techniques for Sentiment Analysis”, ICATE 2013 Paper Identification Number-124.
23. Neha R. Kasture, Poonam B. Bhilare: “An Approach forsentiment analysis on social networking sites”, IEEE International Conference on
24. Volkova, S., Wilson, T., & Yarowsky, D. Exploring Demographic Language Variations to Improve Multilingual Sentiment Analysis in Social Media. In EMNLP, pp. 1815–1827 (2013).
25. Thelwall, M., Buckley, K., & Paltoglou, G. Sentiment strength detection for the social web Journal of the American Society for Information Science and Technology 63(1), pp. 163–173 (2012). 26. Thomas, K., Fern´andez, M., Brown, S., Alani, H.: OUSocial2 - A
Platform for Gathering Students’ Feedback from Social Media. Demo at the 13th International Semantic Web Conference (ISWC’14) (2014). 27. Simon, T., Goldberg, A., Aharonson-Daniel, L.,Leykin, D., Adini, B.: Twitter in the Cross Fire – The Use of Social Media in the Westgate Mall Terror Attack in Kenya. PloS one 9(8): e104136 (2014). 28. Saif, H., Fern´andez, M., He, Y., Alani, H.: SentiCircles for
Contextual and Conceptual Semantic Sentiment Analysis of Twitter. In: Proceedings of the 11th Extended Semantic Web Conference (ESWC’14), pp. 83–98 (2014)
29. Saif, H., Fern´andez, M., He, Y., Alani, H.: On Stopwords, Filtering and Data Sparsity for Sentiment Analysis of Twitter. In: Proceedings of the 9th International Conference on Language Resources and Evaluation (LREC’14), pp. 810–817 (2014).
30. Saif, H., He, Y., Fern´andez, M., Alani, H.: Semantic Patterns for Sentiment Analysis of Twitter.In: Proceedings of the 13th International Semantic Web Conference (ISWC’14) - part 2, pp. 324– 340 (2014).
31. Aston, N., Liddle, J. and Hu, W. (2014) Twitter Sentiment in Date Streams with Perceptron. Journal of Computer and Communications, 2, 11-16.
32. Bifet, Albert, and Eibe Frank. (2010) Sentimen Knowledge Discovery in Twitter Streaming Data. Proceedings of 13th International Conference on Discovery Science, Canberra, 6-8 October 2010, 1-15. 33. Perez-Tellez, F., Pinto, D., Cardiff, J., & Rosso,P, "On The Difficulty
of Clustering Company tweets," in Proceedings of the 2nd international workshop on Search and mining user-generated contents, New York, 2010.
34. David Bamman and Noah A. Smith., “Contextualized Sarcasm Detection on Twitter”, School of Computer Science, Carnegie Mellon University (2016).
35. Bollen, J., Pepe, A., & Mao, H, "Modeling Public Mood and Emotion: Twitter Sentiment and Socio-Economic Phenomena," in International AAAI Conference on Weblogs and Social Media, Barcelona, 2009. 36. The article has been written with the joint financial support of
RUSA-Phase 2.0 grant sanctioned vide letter No.F 24-51/2014-U, Policy (TN Multi-Gen), Dept. of Edn. Govt. of India, Dt. 09.10.2018, UGC-SAP (DRS-I) vide lette No.F.510/8/DRS-I/2016(SAP-I) Dt. 23.08.2016,
37. DST-PURSE 2 nd Phase programme vide letter No. SR/PURSE Phase 2/38 (G) Dt. 21.02.2017 and DST (FST - level I) 657876570 vide letter No.SR/FIST/MS-I/2018/17 Dt. 20.12.2018.
AUTHORS PROFILE
First Author: Siva Kumar Pathuri working as associate prof in the Dept of CSE at KLEF Vaddeswaram, Guntur Dst, completed Masters in Technology at Andhra Universtiy Visakhapatnam with more than 13 years of teaching ecperience and published more than 18papers both in Scopus and Non Scopus Journals. At present pursuing Ph.D from Alagappa University under the guidance of Dr. N. ANBAZHAGAN.
Second Author: ViswaGanesh.Alapati, Scholar UG,Dept Of CompterScience&Engineering,K L University,Vaddeswaram,Guntur
Dist.Email:[email protected]
Third Author: Ponnekanti. Ravi Teja, Scholar UG, Dept Of CompterScience&Engineering,K L University,Vaddeswaram,Guntur
Dist.Email:[email protected]