Rochester Institute of Technology
RIT Scholar Works
Theses
Thesis/Dissertation Collections
5-1-1999
Server selection for mobile agent migration
Wayne Caro
Follow this and additional works at:
http://scholarworks.rit.edu/theses
This Thesis is brought to you for free and open access by the Thesis/Dissertation Collections at RIT Scholar Works. It has been accepted for inclusion
in Theses by an authorized administrator of RIT Scholar Works. For more information, please contact
Recommended Citation
Server Selection for Mobile Agent Migration
by
Wayne Caro
A Thesis Submitted
In
Partial Fulfillment of the
Requirements for the Degree of
MASTER OF SCIENCE
III
Computer Engineering
Approved by:
Principle Advisor
Dr. Hans-Peter Bischof, Assistant Professor, Computer Science Department
Committee Member
Dr. Roy Czemikowski, Professor, Computer Engineering Department
Committee Member
Dr. David Suits, Associate Professor, College of Liberal Arts
Department of Computer Engineering
College of Engineering
Rochester Institute of Technology
Rochester, New York
RELEASE PERMISSION FORM
Rochester Institute of Technology
Server Selection for Mobile Agent Migration
I,
Wayne Caro, hereby grant permission to any individual or organization to reproduce
this thesis in whole or in part for non-commercial and non-profit purposes only.
Abstract
The
purpose
of
this thesis
is
to
develop,
test,
and
simulatean
algorithmthat
mobile
software
agents
can
use
to
select
a
server
to
whichthe
agents
can migrate.Software
agents are autonomous software entities
that
performtasks
on
behalf
of
otheragents or
humans,
and
that
have
some
degree
of
intelligence.
In
particular,
a
mobilesoftware
agent
is
capable
of
migrating from
one
computer
system
(agent
server)
to
another
during
the
course
ofperforming its
tasks.
Most
current
implementations
of
mobile
software
agents
(simply
referred
to
as
agents)
have
simpleforms
of
serverselection.
The
algorithm
discussed in
this thesis
proposes
newideas for
dealing
withthe
server selection process.
The
algorithm proposed
in
this
thesis
is intended
to
provide a goodbasis from
which
further
work canbe
continued
in
the
area ofagent server
selection.This
algorithmwas
demonstrated
to
workas
expected undera
set
of
boundary
conditions
ofpurely
abstract
computerresources.
Then
the
algorithm
was usedin
a
simulation ofa print
job
scheduler
for
a cluster
of printers.Some
ofthe
concepts
that this
algorithm
usesare
resourceimportance
factors,
"needed" and
"wanted"
resources,
riskfactors,
serverTable
of
Contents
List
of
Figures
iii
List
ofTables
iv
Glossary
v1
INTRODUCTION
1
1.1 Agent
Description
1
1.2 Mobile
vs.
Non-Mobile Agents
4
1.3 Trust
and
Security
in Multiple Agent Systems
7
1.4 Resource Allocation
and
Usage in Multiple Agent Systems
9
1.5 Conclusion
of
Introduction
10
2
DESCRIPTION
OF THE PROBLEM
11
2.1 The Focus
ofthe
Thesis
11
2.2 Assumptions
12
3
OVERVIEW
OF THE
SOLUTION
15
3.1 Needs
and
Wants
13
3.2 Evaluations
14
3.3 Risk
15
4
DESCRIPTION
OF THE ALGORITHM
19
4.1 Algorithm Overview
19
4.2 Server Responsibilities
20
4.3 Agent Responsibilities
21
4.4
Preliminary
Algorithm
Setup
22
4.4.1 TheRMatrix
22
4.4.2 The P Matrix
23
4.4.3 The A Matrix
23
4.4.4 The E Matrix
24
4.4.5 The
sVector.
24
4.5 The Calculations
25
5 IN-DEPTH DISCUSSION OF THE ALGORITHM
26
5.1 Explain Decisions Made
26
5.1.1 Resources
26
5.1.2 Trust
28
5.1.3 Significance
of
the
Values
31
5.2 Various Uses
ofthe
Algorithm
34
5.3 Strengths
and
Weaknesses
ofthe
Algorithm
36
5.3.1 Strengths
36
5.3.2 Weaknesses
39
6 EXPERIMENTATION
43
6.1
Boundary
Cases
45
6.1.1 Test#l:
Only
One Server Has All
the
Necessary
Resources
45
6.1.2 Test #2: One Server Has Much Better Resources
Availability
47
6.1.5
Test #5: Best
Resources,
but
Lowest Evaluations
53
6.1.6
Test
#6:
Perfect
Evaluations,
Much Fewer Resources
55
6.1.7
Review ofResults
58
6.2 Print Job
Scheduling
Simulations
59
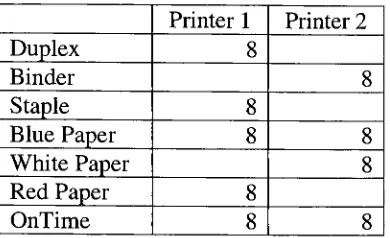
6.2.1 Simulation
#1:
Only
One Printer Has All
the
Necessary
Features
61
6.2.2 Simulation #2: Same Job
to
Similar Printers
63
6.2.3
Simulation #3: Same Job
to
Printers
withChanging
Evaluations
64
6.2.4 Simulation #4: Different Printers
withChanging
Job Specifications
....676.2.5
Review ofResults
70
7
FUTURE WORK
71
7.1
Specifying
a
Server Preference
71
7.2 Different Weights for Different Evaluations
71
7.3 Different Types
ofEvaluations
72
7.4
Evaluation Algorithms
73
7.5
Handling
Dynamic Resource
Availability
73
7.6 Non-Linear Resource
Ranking
74
7.7 Universal
Naming
Scheme
75
7.8 Resource List from Task Description
76
7.9
Deciding
on
Risk Factor
and
Resource Importance
77
7.10 Server Rules
andAdvertising
78
7.11 Server
andAgent Police
79
7.12
Testing
the
Algorithm in Specific Environments
80
8 CONCLUSION
81
APPENDIX A: SOURCE
CODE
82
Appendix
A.l: Algorithm Tests
82
Appendix A.2: Printer
Simulations
97
Appendix
A.3: Support Files
125
List
of
Figures
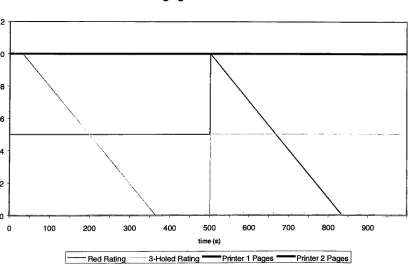
Figure #1: Simulation
of one
usable printer62
Figure #2: Simulation
of
submitting
the
same
job
to
similar printers
64
Figure #3: Simulation
of
changing
printerevaluations
with30%
risk
66
Figure #4: Simulation
of
changing
printer evaluations
with80%
risk
66
Figure #5: Simulation
of
changing job feature importance factors
at
10%
risk
68
Figure #6: Simulation
of
changing job feature importance factors
at
20%
risk
69
List
of
Tables
Table #1: Review
of all
test
results
58
Table #2: Algorithm
testing
data file
locations
134
Glossary
Agent:
page
3
a
self-contained
software
entity
capable of
carrying
out
aset of
tasks,
requested
by
a
human
oranother software
entity,
either
locally
(on
the
computer
whereit
wasinstantiated)
or
remotely
(on
a computer other
than
where
it
was
instantiated).
ACL:
page
2
Agent
Communication Language.
AES:
page
4
Agent Environment Server. A
server
that
is
capable of
providing
the
necessary
resources
to
allow an agent
to
execute
ona computer system.
To
agents,
an
AES is
analogous
to
a
fish
tank
for fish.
Agent Author:
page
7
The
person
orgroup
who
takes
responsibility for
the
creationof a
particulartype
of
agent.
ATM:
page
26
Asynchronous Transfer Mode. A high-speed
computer
networktechnology.
ATP:
page
5
Agent Transfer Protocol.
CPU:
page
10
Central
Processing
Unit. More commonly
used
to
referto
the
microprocessor
in
a
personal
workstation computer.FTP:
page
5
File Transfer Protocol. An
applicationlayer
networkprotocol
for moving files
around a
network.
Foreign
Server:
page12
Any
AES
otherthan
an agent's
home
server.Home
Server:
page
12
The AES in
whichan
agentis instantiated.
HTTP:
page
5
Hypertext Transfer Protocol. An
applicationlayer
networkprotocol
for
accessing
information
on
the
WWW.
JVM:
page6
KQML:
page
2
Knowledge
Query
Management Language. An
agent
communicationlanguage
(ACL).
MA:
page
6
Multiple Agent. Often
usedin
a sentence as
"MA
system".
RAM:
page
15
Random Access Memory. Volatile memory inside
a computer.SMTP:
page
5
Simple Mail Transfer
Protocol.
An
applicationlayer
network protocolfor sending
andreceiving
electronic mail.TCP:
page
5
Transmission Control
Protocol.
A
networkcommunicationslayer
protocol.User:
page1
The human
withthe
mostdirect
causalrelationship
to
anagent's
instantiation.
WWW:
page
26
1
Introduction
1.
1
Agent Description
In
the
modern
world,
computers
arerapidly
being
improved
withthe
discovery
of
new
technologies,
the
rediscovery
of
"old"technologies,
and
the
merging
of
severaldifferent
technologies.
Software
agents
are a primeexample
of
the
collaboration ofresearch efforts
involving
new and old
technologies
being
combinedand
transformed
into
new
technologies
with great
potentialfor
leading
technological
advances
into
the
newmillennium.
[1]
describes
agents as
"the
next great wave ofinnovation
and
development
across
the
Infosphere" and which will"have
an effect as profound as
the
World Wide
Web"on
humans
all overthe
world.
Currently
there
is
noglobally
accepted
definition
of software agents(referred
to
as
"agents"
from here
on),
but
there
are
many
agreed upon characteristicsthat
are
common
among many different
groups of agent researchers.The
core
concept of agentsis
that
they
are computer code
that
has
a state associated
withthem
in
muchthe
same
way
that
"objects"do in Object Oriented
Programming
(OOP).
Beyond
this
basic
core,
there
are othercharacteristics
that
aredependent
on each
researcherworking in
the
field
ofagents.
Here is
a
list
of some of
the
common agent characteristics.Autonomous:
According
to
[1,2,3,4,5,6]
agents
should
be
able
to
actindependently
of
the
rest
ofthe
computersystem.
In operating
systemlingo,
an agent wouldbe
similarto
a"process". An
agent
can performtasks
withoutdirect
controlfrom
some externalsource
andis
a software
entity
that
has very definite
boundaries.
Emissary:
[2,3,5,6,7,8]
mentionthat
an agentperforms
tasks
onbehalf
of
human
users or
other agents.When
anagent
performsa
task
on a
computersystem,
it is
doing
so
in
place ofa
particularhuman
or another agent.
Anything
that
an agent
does
couldhave been done
by
a
human
andis,
in
fact,
done
for
that
human. If
an
Reactive (Robust in changing
environments):
[3,4,5,6,7,8]
agree
that
computersystems are
generally
dynamic
systems,
so an agent must
be
ableto
cope withsuch an environment.
When
the
environment changes
in
such a
way
that
it
affects
an
agent, the
agent should
be
able
to
respond
to
the
change.
If
an agent
is printing
documents
for
a
user,
and a new printer
is
added
to the
system,
the
agent
shouldbe
able
to
decide
to
usethe
new
printerif it is
appropriate.
Agents
should also
be
able
to
handle
similar scenarios
that
are negative
in
naturefor
the
agents.
Intelligent:
[1,5,6,7,8]
claim
that
agents should
have
a
minimalability
to
reasonabout
their
situations
andapply previously
accumulated
knowledge
to
make
decisions
in
their
dynamic
environments.
The
greatest
difference
between
intelligence
andbeing
reactiveis
that
apurely
reactiveagent
willalways respond
to the
same environment
in exactly
the
same way.
With
intelligence,
an agent
may
respond
differently
at
different
times
to the
same environmental situation
because
it may have
acquired
knowledge
since
the
previous
time(s)
that
it
was
in
the
same
situation.
Communicative
(with
otheragents
and/or
human
users):The
idea
ofcommunication
for
agents
is
mentionedby
[2,3,4,5,7,8,9]
as
they
discuss how
agents
can
accomplish certaintasks.
[7]
specifically focuses
on
the
idea
of
creating Agent Communication Languages
(ACL)
that
would"let heterogeneous
agents
communicate"
with each other.
One
such
ACL
is
the
Knowledge
Query
Management Language
(KQML);
KQML
allows agents
to
"tell
facts,
ask
queries,
subscribe
to
services,
orfind
otheragents."
Communicating
withhumans
can
be
as
simpleas
opening
a window onthe
user's
workstation
and
displaying
a
text
messagein it
as
is demonstrated in
[2].
However,
messages
among
agents
require a specific protocoland some sort
of messagepassing infrastructure
withinthe
agent system.Collaborative (with
otheragents
and/orhuman
users):[3,4,5,7,8]
referto
agent
systems
in
whichan
agent will work with other agentsor a
human
userin
order
to
accomplish
the task that the
agent
is
trying
to
perform.[7]
specifically deals
with
"personal
assistant
who
is
collaborating
with
the
user
in
the
same
workenvironment".
Agents
can also
be
used
to
"help
different
users
collaborate".Drudge: One
of
the
most
basic
uses
of agents
has been
to
establish agents
as
software
that
can
take
some of
the
boredom
out
ofpeople's
lives
by
allowing
computers
to
perform more of
the
tedious
and repetitive
tasks
that
peopledislike
doing.
[2,5,6,8]
have
addressed
these
issues in
various
forms.
According
to
[8],
an"agent
can
assist
in
...information
filtering,
information
retrieval,
management,
meeting
scheduling,
selection
ofbooks,
movies,
music,
and
so
forth.""The biggest
advantage
that
agents
bring
is simply
their
ability
to
automate
previously
manual operations.
"[6]
Having
an
agentperform
these
sorts
oftasks
willincrease
aperson's
productivity
and givethe
person
moretime to
work
on
tasks that
are still
too
difficult for
a computer
to
perform.[6]
refersto
customers who
"will employ
software agents
to
help
them
identify,
locate,
and
procurethe
products and services
that
they
require".
Pro-active (has
goals):
Many
agentresearchers,
suchas
[3,4,6,7],
describe
agents
as
having
"goals" or"desires". In
particular,
[7]
refers
to
agents
as
having
"intentions"and
"social
commitments".Such
goals,
intentions,
and so on allow
an agent
to
performtasks
withouta
userspecifying how
anagent should act
in
all circumstances.So,
instead
of a
userhaving
to tell
an agentto
how
to
swap
two
values
by
telling
it every
step,
a user mightbe
able
to
describe
to the
agent
whatthe
result willbe,
and
the
agent willfigure
outthe
steps.This is closely
tied to
intelligence,
but
it differs because it is
morethan
just
reasoning;
being
pro-active meansthat
anagent
will reason with an"abstract"
(as
abstract
as
currently
feasible using
moderntechnology)
purpose.For
the
purposes of
this
thesis,
software
agents willbe described
asautonomous
software
entitiesthat
performtasks
onbehalf
of other agentsor
humans,
and
that
have
some
degree
of
intelligence.
The
other
characteristicsthat
weredescribed
above seem
to
be
characteristicsof
particularimplementations
andnot
characteristicsof generalized
1.2 Mobile
vs.
Non-Mobile
Agents
There
are
two
major
types
of software agents:
Mobile: "Mobile
agents roam
the
network
visiting
various servers
in carrying
outtheir
tasks."[2]
Non-Mobile (or Static): "Static
agents are associated with a
particularclientor
server"
[2]
and
have
no
ability
to
roam around a network.
Non-mobile
agents are
typically
"personal digital
assistants"like
those
described
in
[8]
or
like
the
Microsoft Office Assistant
that
helps
users withcreating
their
documents.
Being
non-mobile,
an
agent
doesn't have
to
be
concerned withmany
problems
that
arise
whendealing
with networks.
Non-mobile
agents
are
usually
notconcerned
withaccumulating
extra
"baggage"during
their
existencebecause
they
don't
need
to transport
that
"baggage"across
a
network.There
are
few security
concernsbecause
the
agent
isn't migrating
over
"unknown"networks
to
possibly
"unknown"environments,
etc.
The
largest
difficulty
for
non-mobile agents
is
being
able
to
access
remote resources.
In
order
for
a
non-mobile agentto
access
a remoteresource, there
must
be
a specific
remoteaccess
methodavailable
for
that
resource.
This
couldbecome
difficult
as
new
remote
resources
become
available with new remoteaccess
methodprotocols.
"If
the
agent canbe
serialized
(prepared
for
transfer
over a networkin
away
that
lets its
state
be
recovered)
andif it
migrates,
it is
a mobile agent.."[2]What
this
means
is
that
"an executing
mobile agentis
a
continuously executing
program,
interrupted
briefly
during
transport
between
a
seriesof
machines."[3]
"Mobile
agentsdo
nottransport
themselves"[3], instead
mobile agents
rely
on
agent
environment servers(AES)
to transport the
mobileagents across a
network.An
AES
provides an
environment,
in
whichan
agentcan
execute, that
is very
similar
to that
of
waterfor
a
fish.
Just
as
a
fish
cannotlive
outsideof
water,
an agent can
only
"live"within
anAES.
An AES
provides mobile agents witha means of
migrating from
one
server
to another,
access
to
resources,
anda
"guard
againstmobile agents
whichattempt
misuse"[3]oftheAES.
Mobile
agentshave
some
significant advantages anddisadvantages
over
the
area of process migration.
Some
of
these
goals are
reductionof
networktraffic, load
balancing,
fault
resilience,
asynchronous
interaction,
etc.Some
ofthe
mostimportant
disadvantages
or
difficulties
with mobile agents are multiple
platformexecution,
networksecurity,
security
of
the
agent on a remote
server,
security
of a server
from
remoteagents,
human
responsibility
for
agents'actions,
network
traffic
and
reliability,
resourcediscovery,
resource
usage,
and resource
control,
etc.
This
thesis
is primarily
concerned
with mobile software agents.From
nowon,
"agent"
will
refer
to
mobile agents unless otherwise specified.
Mobile
agents are an excellent
idea in
theory,
but in
order
for
them to
fulfill
their
potential,
certain questions
needto
be
answered
to
fully
realizethe
theory
of agents.
How
canan agent
have its
binary
image
andits
current statetransferred
from
one
computer
to
another?
Before
an
agent canmigrate,
"execution
mustbe
stopped
and all
local-resource-dependent
activities
have
to
be
completed."[10]
Once
this
is
complete,
most
systems
use"application
protocols
ontop
ofTCP
(Transmission Control
Protocol)
for
transport
of
agent
code
and
states.
"[10]
Some
systems use
Simple Mail Transfer Protocol
(SMTP),
HypterText Transfer
Protocol
(HTTP),
File Transfer Protocol
(FTP),
etc.
IBM developed its
ownAgent Transfer Protocol (ATP).[1
1]
How
can apiece
ofsoftware
be
transferred
from
one computer
to
anotherin
the
middle
ofits
execution?
The
typical
response
to this
question
is
to
createagents
that
are
event
driven
state
machines
that
can
only
migrate whenthey
have
released all
ofthe
local
resources andtheir
executionis currently
atthe
event
handling
procedure.[10]
How
can
an agent migrateamong
a
heterogeneous
set of computer
architectures?Most designers
are
using
someform
ofinterpreted language.
One
ofthe
favorite
interpreted languages is Java byte
code.
[10]
How
does
an agentknow
whereit
should
migrateto?
Most
current agent systems
require
that
a
userspecify
whichcomputers
the
agentshould migrate
to
and
in
what order.
[2]
In
orderto
intelligently
select
a
server,
agents
would need
to
perform remote resourcediscovery.
According
to
[10],
"resource
discovery
is
virtually
absentin
allcurrent
systems."
acquiring information
regarding
remote
hosts"in
order
to
decide if
a
remotehost
was acceptable
for
a new agent.
How
does
an agent
decide
whether a particular server
is
a safe
placefor
the
agentto
migrate
to?
At
the
current
time,
there
has
not
been
much
researchin
this
area
because
most
systems
require
the
user
to
predetermine
the
agent's
agenda(or
itinerary).
[2]
In
mostMA (multiple agent)
systems,
the
AES
is "assumed
to
be
trustworthy"
and
willperform operations
to
help
an
"agent
to
protectthe
privacy"
of
its
contents and results.
[10]
How
can an agent
carry
sensitive
information (such
as
electronicmoney)
in
such
a
way
that
during
migration,
or
whileresiding
on a remoteserver,
the
information
won'tbe
stolen
from
the
agent(or
modified)?This
canbe
accomplished with modernencryption
techniques.
[10]
The
major problem withthis
is
that
mostencryption algorithms are
very
processorintensive
and are slow.How does
a server
determine
whichagents
aresafe
and
should
be
allowedto
transfer to
itself?
Most
current
implementations
of agent serversdon't really
handle
this
at
all,
and
there
isn't
much needto
because
the
servers
provide agentaccess
to
very few
resources.How does
a
serverdetermine
whichresources
canbe
providedto
particularagents?
Sun Microsystems
has partially
answered
this
questionfor
mobileJava
objects
by
providing
programmers withthe
ability
to
implement
different
Resource Managers for
eachJava Virtual Machine
(JVM)
that
they
wishto
use.
[15]
The Resource Manager is
capable of course-grained controlover
the
resourcesthat
an
objectis
allowedaccess
to.
How
canagents
worktogether
in
groupsto
accomplishtasks?
There
are
many
researchers
currently working in
this
area.In
particular,
[12]
analyzedthe
idea
ofcloning
agents
in
orderto
distribute
tasks.
How
can a
userspecify
tasks
for
an
agentto
perform withouthaving
to
write
programs
in languages
such asC++
or
Java?
There
aresome
researchers
1.3
Trust
and
Security
in Multiple Agent
Systems
The ideas
of
trust
and
security
in MA
systems are
very
closely
related.[14]
refersto trust
as
being
a
"particular
level"of
"subjective
probability".
Trust is
uniqueto
an
individual
and
it has
various
levels.
Security, however,
is
not subjective.
Security
does
have
various
levels,
but
those
levels
can
be clearly defined.
Trust is
a
matter
of
confidence
in
someone's
or
something's
truthfulness,
accuracy, ability,
strength or character.
In
terms
of mobile agent
systems,
there
mustbe
trust
between
agents and agent servers.
Agents
needto trust
AES's
to
be
truthful
about
the
information
that
they
provide
to
agents,
and agents
needto
have
trust
in
an
AES's
ability
to
provide particular resources
to
the
agents.
Agents
also
needto
trust
otheragents.
If
multiple agents are
going
to
worktogether
on a
task,
they
all
needto trust
oneanother
to
a certain
degree.
The first item involved
withtrust
is
the
identification
of agents and servers.
In
order
for
anagent
to trust
aserver,
the
server
mustbe identified
as
a server with whichthe
agent
is familiar.
[10]
refersto
some
agent
systems
that
useglobally
uniqueidentifiers for
agents and servers.
In many
agentsystems,
when anagent requests access
to
a newserver,
the
server
performsa
"verification
ofthe
agent"[9]
to
make surethe
agent
is
trustworthy.
The
verificationprocess
may involve
looking
up
the
name of
the
agent
in
a
database
to
see what
level
of confidencethe
server should
have in
the
agent.There
are
security issues involved
withthe
identification
ofagents and
servers.There has
to
be
a method
ofidentifying
an
agent or serverin
such away
that the
agent
orserver cannot
be
animpostor. The
systemsdescribed
in
[3]
useagents
that
are
"digitally
signed
by
one or more partiesusing
one of
a number ofalgorithms,
suchas a public
key
signature
algorithm."
"Digital
signatures
canbe
usedto
verify
the
identity
of
the
mobileagent's
authorand
ofits
sender,
whereand
whenit
wassent,
andthat
it has
not
been
tampered
within
transit".
[3]
Once
the
identity
of
anagent or
serveris successfully
verified, there
is
another
problem.
"Authentication
credentialsdo
not guaranteethat
the
mobile
agent will
be
harmless,
or evenuseful."[3]
Just because
the
identity
ofan
agentis
safe,
there
is
no
guaranteethat
the
"digitally
signed
code
has
been
authored
by
competent
has
been
tested
on
the
presentcomputer, there
is
no
way
of
knowing
if its
softwarewill
cause
harm
to
its
newenvironment."
[3]
There
are
two
major concepts
that
are
involved
with
trust.
The first item
that trust
is
concerned
withis
whether or not an agent or server
is going
to
do
whatit is
supposedto
do. If
a server
is
supposed
to
permit
the
use of
five
semaphores,
but it only
permits an
agent
to
use
three,
then
the
server
isn't acting in
a
trustful
manner.
The
second
concernis
that
an agent and server aren't
going
to
act maliciously.
This
is
wheresecurity
playsa
major
role.Trust
is
the
amount of confidence
that
two
entities
have
in
one
anotherto
do
as expected.
Security
involves
possibly forceful
measures
to
make sure
that
both
the
agents and servers act non-maliciously.
Security
issues have been
studied
in
great
depth
and
many
mechanisms
have been developed
to
create secure
systems,
but
the
currenttechnologies
are
"lacking
the
complementary
tools
for managing
trust
effectively."
[14]
Trust
can
be developed in
multiple
ways.Some
ofthese
methods
willbe
presented
from
the
point of viewof an agent
trusting
an agentserver,
but
canbe
appliedto the
opposite situation
just
as well.The
easiest method
is
that
a
userinforms
an agent
as
to
whichservers
the
agent shouldtrust.
Another
method
is
that
anagent asks
otheragents
for
recommendationsas
is described in [13]. A
third
methodis
that
an agent
usesa
server andgains
alevel
oftrust
from
personal experience.The
second method
has
an
interesting
difference from
the
others.If
an agent
is requesting
recommendations
from
other
agents,
then the
agent musthave
alevel
of
trust
in
the
other agents.
That
trust
willcause a
different
valueof
trust to
be
placedin
the
recommended servers.This
implies
that
a poor recommendationfrom
a well-trusted agent couldbe
on par with avery
goodrecommendation
from
a
lowly
trusted
agent.The
other
two
methods of
developing
trust
don't involve
a middle
trust
value.Security
in
multiple agentsystems
has
three
mainconcerns.Agents
need
to
have
their
programs and
data
protectedfrom
malicious servers.Servers,
as
well,
needto
be
protected
from
malicious agents.Lastly,
agents
needto
be
protectedfrom
other agents.
The first
concerncan
be
remediedby having
agents
andtheir
data
encrypted and
digitally
signedin
sucha
way
that
when anagent
arrivesat a
newserver
it
can
verify
that
it
was nottampered
with.An
agent
canthen
be
verified againwhen
it
returns
to the
server while
it is executing
on
the
server.
A very
realistic problem
is
that
an
agentcan
be
easily
terminated
by
a
server,
and
there
is very
little
that
an agent can
do
aboutit.
The
other
two
concerns are
primarily focused
on mechanisms
built
into
the
AES.
An AES
can
protect
agents
from
one
another
by
placing
each ofthem
in
separate"sandboxes"
as
is done in Java Virtual Machines (JVM)[15].
This
is
the
preferredmethod of almost all multiple agent systems.
An AES
can
protectitself
by limiting
an
agent's
access
to
system resources.
Most
systems
have something like
a"reference
monitor"[3]
or a
"security
manager"[15]
that
provides
this
service.Another
method of
protecting
the
AES
and other agents
is
to
perform code
verificationbefore it is
allowed
to
execute on
the
AES. An
agent's
code canbe
checked
to
make sureit is free from illegal
instructions.
1.4
Resource Allocation
and
Usage in Multiple Agent
Systems
There
aretwo
mainconcerns
for
agents
regarding
resources.An Agent
wantsto
know
what
the
rulesfor
resourceaccess
are on a serverbefore
the
agent migratesto the
server.
Once
anagent arrives at a
newserver,
the
agentis
concerned withthe
methods
for accessing
particular
resources.Most
current agent systemshandle
the
situation of multipleservers
providing
different
resources orthey
don't specifically
mentionhow
they
handle
this
situation.In
systems such as
that
described in
[2],
the
servers
perform resourcelocation for
agents and
will create more
agents
if it is
possibleto
divide
atask
and sendagents
to
different
servers.
Most
mobile agent systems providevery limited
access
to
system
resources,
so
there
is
noneed
to
advertisethe
resources.Especially
withsystems
like
[11],
in
whichthe
agents
are
derived from Java
applets, the
JVM
providesaccess
to
a well-knownstandard set of
resources.In
more complicatedsystems,
it is foreseen
that
servers
willprovide
servicesfor many
types
of
agents and eachtype
of agent
will receiveaccess
to
a
different
set
and
quantity
of
resources.In
these
types
ofsystems,
it
will
be very
important for
agents
to
be
able
to
find
out
whatthe
rulesare
for
them
ondifferent
servers.
By knowing
the
rules,
agents can
better decide
whereto
migrate.The
conceptof
providing
and
limiting
resourceaccess
in
anMA
system
is
referred
to
as
"resource
very clearly discussed in
the
documentation
for
most modern agent
systems.There
are
many
types
ofcomputer resources
that
need
to
be
managed:
CPU
cycles,
disk
space,
memory,
network
access,
process
handles,
database
engines, printers,
etc.Different
types
of resources will require
different
methods of access.
CPU
cycles should not
requireany
specific method other
than the
protocols
to
migrate
to
a particular
server,
but
perhapsthere
could
be
a method of
requesting
more
CPU
cycles.
Disk
space
requiresopening
files in different
areas of
the
file
system.
There is
more
management requiredin
this
situation
because different
agents will
be
allowed access
to
different
regionsof
the
file
system and
they
willbe
allowed
varying
amounts
of
space onthe
disks.
Resource
management
consists of
many different
tasks
and
canthus
be very CPU intensive. This
may be
the
most
important
reason
why it is
notvery
wellhandled in
mostsystems,
but
as
computers
become
more
powerful,
this
problem
willhopefully
become less
of an
issue.
1.5 Conclusion
of
Introduction
Since
agents
are
a
new
technology,
there
are
still
many
questions
that
are
unanswered,
andthere
are
stillmany
usesof agents
yetto
be discovered. Multiple
agent
systems
have
to
deal
withthe
concerns of
trust,
security,
and
resourcemanagement.
[14]
discusses many
traps
and pitfalls
that
researchersand
designers
shouldbe wary
ofas
agents
grow out oftheir
infancy. One
of
the
greatest problems
is
one
that
has been
seenrepeatedly in
the
computerindustry
andit is described
as:"if
the
only
tool
youpossess
is
a
hammer,
then
everything looks like
anail."
This
implies
that
"there
is
adanger
ofbelieving
that
agents are
the
right solutionto
every
2
Description
of
the
Problem
2. 1 The Focus
of
the
Thesis
Currently,
there
are not
many
mobile agent systems
that
have
agents
using
much
intelligence
to
decide
on
servers
to
which
they
willmigrate.
There
aresome
agentsystems
that
require
the
human
userto
specify
the
exact servers
to
whichthe
agent willgo.
Other
systems allow a user
to
specify
the
particular resources
that the
agent needsto
acquire and
the
originating
server
willsend
the
agent
to the
appropriate
server(s)
or at
least
createa specific
itinerary
for
the
agent.
The
purpose
ofthis thesis
is
to
develop
an algorithm
that
will addintelligence
to
many
of
these
agent systems.
There
are concerns
withmany
ofthese
simple selectionprocesses.
Resources
are
servers
usually have varying availability
depending
on
the
other
processes
(or agents)
that
use
the
servers.Most
modern
operating
systems
limit
the
access
ofresources
to
specific users
orgroups;
it is
expectedto
have
the
samesort
ofsecurity (or
access
limitations)
imposed
onagents.
Not
all
resourceshave
the
same
importance
to the
completion
ofa
task
as other
resources.Most
currentsystems
just
assume
that
all neededresources are as
important
as each other.
They
alsoassume
that
if
a
server
has
the
needed resourcesat
all, then
it has
a sufficientquantity
of eachresource.
Most
systems also
assumethat there
is only
one set ofresources
that
any
particular agent
will
be interested
in;
those
resources areabsolutely necessary
to
performthe
agent's
task(s).
Many
agent
systemsdon't
concernthemselves
withissues
relatedto trust
between
serversand agents.
Many
of
the
assumptionsthat
the
otheragent systems
make are notconsidered
reasonable
any
more.This
thesis
attemptsto
propose analgorithm
that
agents
canuse
and
that
providesa
solutionto
many
ofthe
assumptions mentionedabove.
The
algorithm
being
proposed
is
meant
to
providea
basis
upon whichfurther
enhancements can
be
easily
made.The
algorithm provides a meansof
taking
into
accountthe
fact
that
resource
availability
varies overtime
among
servers.When
a
serverlimits
the
access of certain
resources
to
particularagents,
the
algorithm will usethis
information
in
the
decision
will
use, the
algorithm will consider
this
information.
Not
all agents
only
requirethe
same amount of each resource.
An
agent,
using
this algorithm,
willbe
able
to
specify
minimum
quantities
of each
resource
in
which
it is interested.
In
additionto
this
specification,
agents can provide a
listing
ofresources
that
canbe necessary for
the
task,
or
may just be desired in
order
to
act more
efficiently (or any
other reason).These
are
the
issues
to
which
the
proposed algorithm
in
this
thesis
will
attemptto
respond.2.2
Assumptions
Before
the
discussion
ofthe
solution
canbe
discussed,
this thesis
requires
certainassumptions.
It is hoped
that
this
solution
requires
less
limiting
assumptions
than
previous agent system solutions.
This
is
the
only way
that this
solution willhelp
advanceagent systems.
Agents
are assumed
to
require an agent
environment server(AES)
in
whichto
be
active.
An
agent cannot execute
its
code outside of anAES.
The
terms
"AES"and
"server"
will
be
usedinterchangeably
throughout this thesis.
Agents
mustbe
created ona
"home"
server.
Any
other
AES is
considered
to
be
a"foreign"
server.
An Agent is
expected
to
always
returnto
its home
server after
it has
completedits
giventasks.
It
is
assumed
that
agents
will not replicatethemselves
onforeign
servers
because
that
wouldcomplicate
the
concept of
the
"home"server.
An AES
canbe
compared
witha
fish
tank.
There is
notheoretical
limit
as
to
how
many AES may
exist on
a specific
computersystem.
Each AES
provides aseparate
environment
in
whichagents
can exist andjust because
multipleAES
canreside on
the
same computer system
doesn't
meanthat
they
should
be
consideredany
more connected
than
any
other set
ofAES.
As
agents
migrate arounda
networkthere
are
certain
items
that
anagent
is
expected
to
carry
withit. Agents
needto
be
identified
by
severalfactors
including
the
author
ofthe
agent,
the
user on whosebehalf
the
agent
is
acting,
the type
ofagent,
the
home
server.Agents
should also
carry
withthem
alist
of
previousservers
to
which
the
agent
visitedsince
it
was created.Each
of
these
items
should
be
encrypted
in
the
agent
so
that
it
cannotbe
modifiedby
otheragents
orservers.
These
items
will
help
an
AES
Assuming
that
agents can
getaccess
to
a
list
of active
AES's,
agents must ask
each
AES for
permission
to
migrate
to the
server
before
an agent
is
allowed
onit.
A
permission
request
should
include
items
that
identify
the agent,
as
described
in
the
previous paragraph.
The
agent should
probably
also
inform
the
server as
to the
agent's
current
size,
including
its
code and
its data.
System
administrators
willbe
responsible
for
determining
the
rulesthat
agents
must
follow
on
particular
servers.
It is
assumed
that
anadministrator
canspecify
different levels
of rules.
There
can
be
"global"rules
that
would
apply
to
all agents
that
use a particular server.
"Directed"rules can
apply
to
specific agents or groups
ofagents.
Some directed
rules can
apply
to
individual
agents,
and other
rules canbe
applied
to
a
group
ofagents as a whole.
One directed
rulemight
specify
that
noagents
belonging
to
a
particular
group
are allowed access
to
morethan
two
software
licenses. Another directed
rule might
declare
that
the
total
disk
space
being
usedby
allthe
agents
in
a specific
group
cannot
total
morethan ten
megabytes at
any
time.
A
globalrule might
be
that there
is
notallowed
to
be
more
than
fifteen
agents
occupying
the
server simultaneously.
In
additionto
rulesbeing
posted
by
servers,
the
servers
are
also
expected
to
provide agents
witha means of
finding
outthe
current
availability
ofvarious resources.
The
servers
only
needto
provideavailability information regarding
resources
to
which
the
particular agent
has
access
permission.This
information
shouldbe
updated at
least
as
often as agents
requestthe
information.
Just before
an agent
leaves
a
server,
the
server willpresent
the
agent
with asurvey
to
fill
out.
The survey
will allow an agentto
evaluatethe
services provided
by
the
server.It
is
expected
that
an agent
willevaluate
how
wellthe
server providedaccess
to
each of
the
resources
that the
agent used.However,
agents
do
nothave
to
evaluate all of
the
resources
that
they
used,
but
an agent cannot
evaluateany
resourcesthat
it did
not
useduring
the
course ofthe
current visit.The
reasonfor
an
agent's
evaluationof
eachresource
is left
to the
agent
to
decide,
so
there
willbe
no
laws
placed uponagents as
to
how
they
are
supposedto
evaluatethe
servers.
Agents
are
assumedto
be fair
and non-malicious.
When
an
agentevaluates a
server,
the
agentis
expectedto
givereasonable evaluations.
If
anAES
provides an
agent
server a
relatively
good evaluation.
On
the
other
hand,
servers are
assumedto
not
be
malicious as well.
An AES
willrespect all
the
agents
that
useits
services andtherefore
will not
lie, harm,
or steal
from
them.
Servers
willalso provide a
reasonable amountof
security for
the
agents.
Every
AES
will make sure
that
no agent
underits
protection canbe harmed
by
any
other agent or process
executing
on
the
same computer system.Although it is
nota
focus
of
this
thesis,
an
agentis
assumedto
be
ableto
communicated with other
agents
using
an agent communicationlanguage
(ACL)
suchas
Knowledge
Query
Management Language (KQML).
This
will allow agentsto
work3
Overview
of
the
Solution
In
order
for
agents
to
select a single server out of a
poolof
servers,
it is
necessary
to
investigate
the
types
ofinformation
that
an
agent would need
in
orderto
makean
educated
decision.
Following
the
description
of
agents,
from
the
Introduction,
an
agent'spurpose
is
to
perform
tasks
on computers.
In
order
to
do anything
ona
computer,
somecomputer resources need
to
be
accessed.
An
agent needs
to
be
aware ofthe
resourcesthat
it
needs
to
perform
its
tasks.
In
other
words,
it is very important for
an agent
to
know
what
it
needs
to
perform
its
tasks
before it
starts
to
do
them.
3. 1 Needs
and
Wants
There
are
two
majortypes
ofresources
that
an agent
will useto
performits
tasks.
The
first
type
is
resources
that
are
absolutely necessary in
orderto
performa
task.
The
other
type
is
resources
that
are
notnecessary,
but
wouldbe helpful
in performing
the task
at
hand. Each
ofthese
resources
is
important,
so
both
must
be
considered whendeciding
on a serverto
whichthe
agentshould
travel.
Perhaps
an agent
needsat
least 5MB
of
RAM
in
orderto
perform anoperation,
but if it had
accessto
at
least 15MB
ofdisk
space,
the
agent wouldbe
ableto
performthe
operation much moreefficiently.
Then
whenselecting
a
server on whichto
perform
this
operation,
both
ofthese
bits
of
information
shouldbe
considered.In
additionto
specifying
whethera
resourceis
neededor
wanted,
anagent
wouldprobably
wantto
give
the
resource somesort of
"importance
factor".
This factor
would allowthe
agentto
specify numerically how important
a
resourceis
to the
agent's
task.
Assume
that
an
agent needsto
perform someimage
manipulationalgorithms
onsome
very large images. The
agent
mightdecide
that
it is
moreimportant
to
have
a
lot
of
RAM
than
it is
to
have
avery fast
CPU;
if
the
computerhas
to
keep
swapping
the
image
to the
disk
drive,
then the
fast CPU
won'thelp
too
much.In
this scenario, the
agent would
want
to
consider aslightly
slowerCPU
in
orderto
have
moreaccessible
RAM.
This
3.2
Evaluations
No
matter
how fast
a computer
is
there
willstill
be
times
when a
computer cannotperform all of
its
tasks
in
the
amount of
time that
a user expects or
requires.In
real-timesystems,
a
processor
may
reach
the
point
where
no
more
tasks
canbe
scheduledaccording
to the
specifications of
the tasks.
On
a multi-user
non-real-timesystem,
it
is
very difficult
to
perform operations within an expected amount of
time.
A
usercan,
however,
maintain a
history
of when
the
resources were available.
Using
the
history
list,
a user might
be
able
to
estimate when a good
time
would
be
to
performa
task that
needsparticular resources.
In
a multi-mobile-agent
system,
it is impossible
to
know exactly
whena
resourcewill
be
available on a particular
computer.If
some
sort ofhistory
is
maintained(similar
to
that
whichis described above)
of
times
whenagents were able
to
get access
to
allof
the
resources
that
they
wereinterested
in,
then
an agent
mighthave
a muchbetter
chance
at
guessing
at
whether or notthe
necessary
resources
willbe
available at a
particularserver.
An idea for
keeping
ahistory
mightbe
that
when an agentis done performing its
task
on a computer system
(or any
time
afterit has
finished using
a particular
resource),
the
agent
can evaluatehow
wellthe
server provided
the
particularresources
to the
agent.
If
a server
provided allof
the
resources
that
it
told
the
agent
it
could
have,
then the
serverwould expect
to
get a good evaluationfor
that
resourceat
that time.
However,
if
anagent
had
to
waita
long
time
to
get
access
to
a
resource, the
agent mightmake
a
worse
evaluation.
Since
agents
are expectedto
be
somewhatautonomous
andintelligent,
it
should
be
expectedthat
different
agents
will evaluateservers
according
to
different
criteria.
This
evaluationpolicy is
a
lot like
a
democracy. If
there
are moreagents
whichgive
a
particularserver
good evaluationsthan
there
are
agentsgiving
the
server
bad
evaluations,
then
overallthe
server shouldhave
a good
rating.A
possibledistributed implementation
ofthis
concept wouldbe
to
have
the
evaluations
maintainedon
the
serverto
whichthey
apply.This
wouldmake
it very easy
for
an
agentto
be
able
to
find
the
evaluationsof a
particularserver,
and
it
would
greatly
reduce
the
amountof
baggage
that
an
agent wouldcarry
around withitself. Of
course,
it
modify
the
evaluations.
There
exist encryption
methods,
such as
publicand
privatekey
encryptions,
which would allow an agent
to
encrypt
its
evaluations
in
such
a
way
that
others will
be
able
to
read
them,
but if
anyone
tries
to
modify
them,
the
resulting data
would not make
any
sense.
It
would
probably be very
useful
if
each evaluationwas
time
stamped and was marked with some
information
which
woulduniquely
identify
the
agent
that
left
the
evaluation.
This
solution
has
an
inherent
problem
ofrequiring
an
initial
evaluationfor
eachresource on
newservers.
It
has
been
assumed
that
when a
new serverjoins
a
mobileagent
system,
the
system
administrator
willrequest
an
independent
party,
whois
responsible
for evaluating
new
servers,
to
evaluate
the
server.The independent party
willuse
eachof
the
resources on
a serverand
leave initial
evaluations.If
there
is
a
resourceon
a server
that
has
notbeen
evaluated
yet, the
server will returnan
evaluation valueof
0
to the
requester.This
places
the
responsibility
on
the
server's
administratorto
make
surethat the
server'sresources are evaluated.
This
also answers
the
questionof what
a serveris
supposedto
do
whenit
adds
a new resourceto
its list
of
services.Either
the
server
administrator
canhave
the
new resource evaluatedby
the
independent
party,
or
the
administrator will
take
a chancethat the
system willbe
used even with a poor evaluationfor
the
one
new resource.3.3 Risk
Different
mobileagents
have different
needs and goals.Sometimes
an
agent
might
be willing
to take
a
chanceand
try
a serverthat
has
worseevaluations
than
anotherserver,
but has
a
much greaterquantity
ofthe
resourcesthat
it
is interested in. The
agent
would
be
taking
a chancethat
the
serverhas bad
evaluationsfrom
the past,
but
that
it
willdo better
now.This
couldbe like going shopping
on
the
day
afterThanksgiving.
In
the
past,
it has
alwaysbeen
one
ofthe
busiest shopping days
of
the
year.Someone
might
take
a
chanceby
going shopping
and
hoping
that
many
otherpeople
willstay home
because
of
the
amountof
traffic
in
past years.In